
Pancreatic cancer research, epigenetics, tumor immunology, tumor evolution, surgeons doing basic science, UM PanTErA, #NewPISlack, personal Twitter: @Fil_Bednar
Joined August 2019
- Tweets 354
- Following 351
- Followers 589
- Likes 1,514
25 Photos and videos









Apr 11
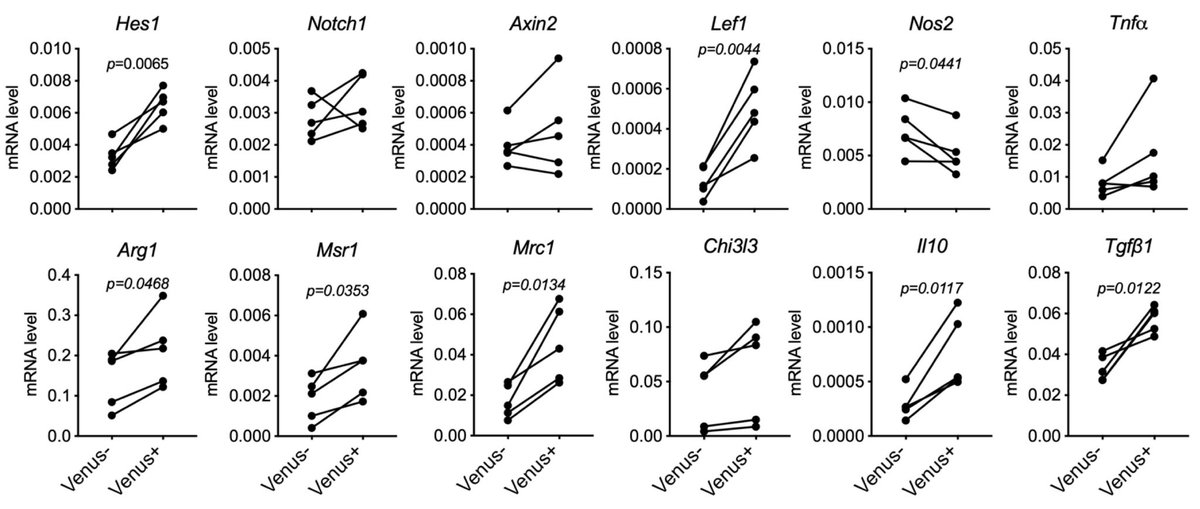
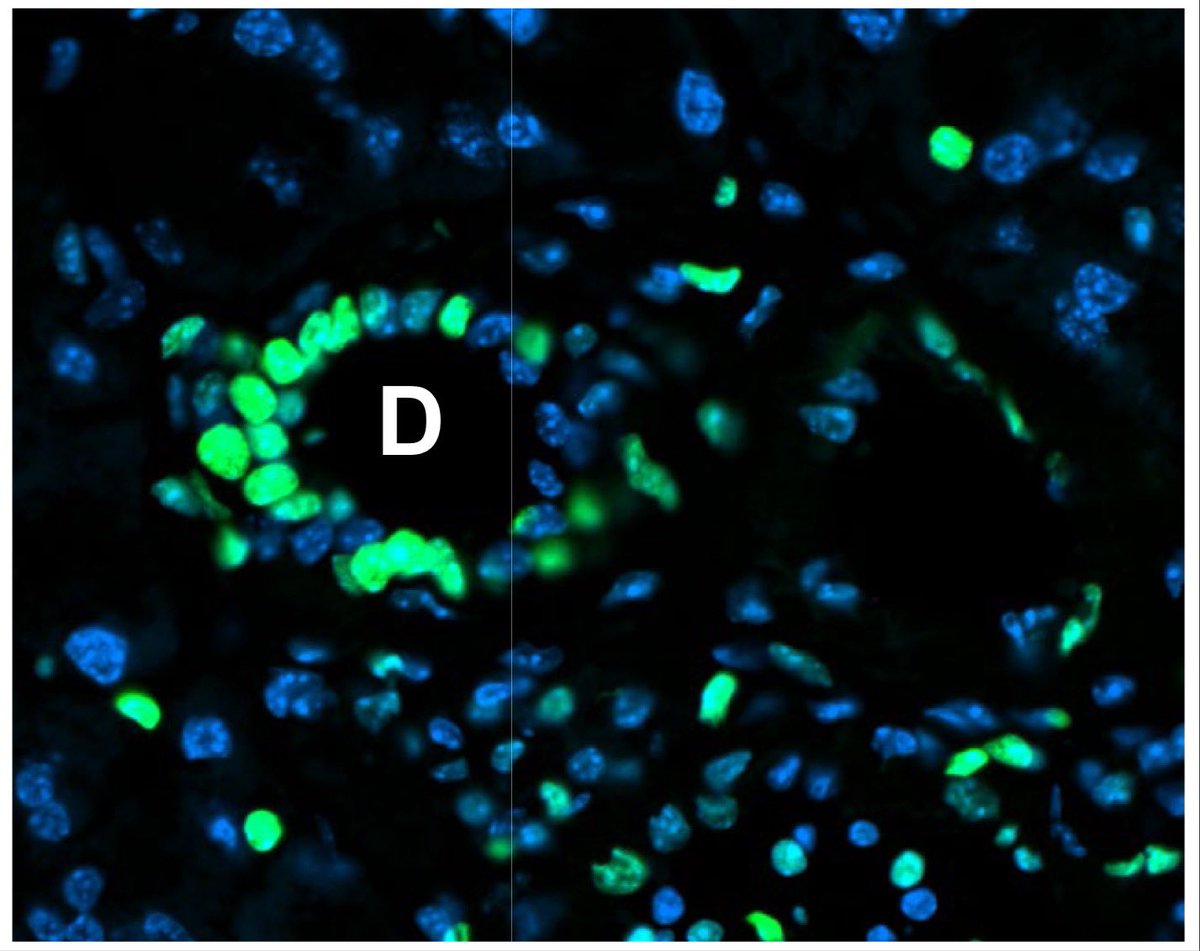
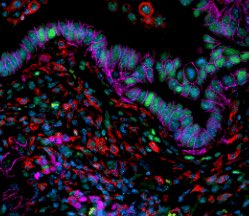
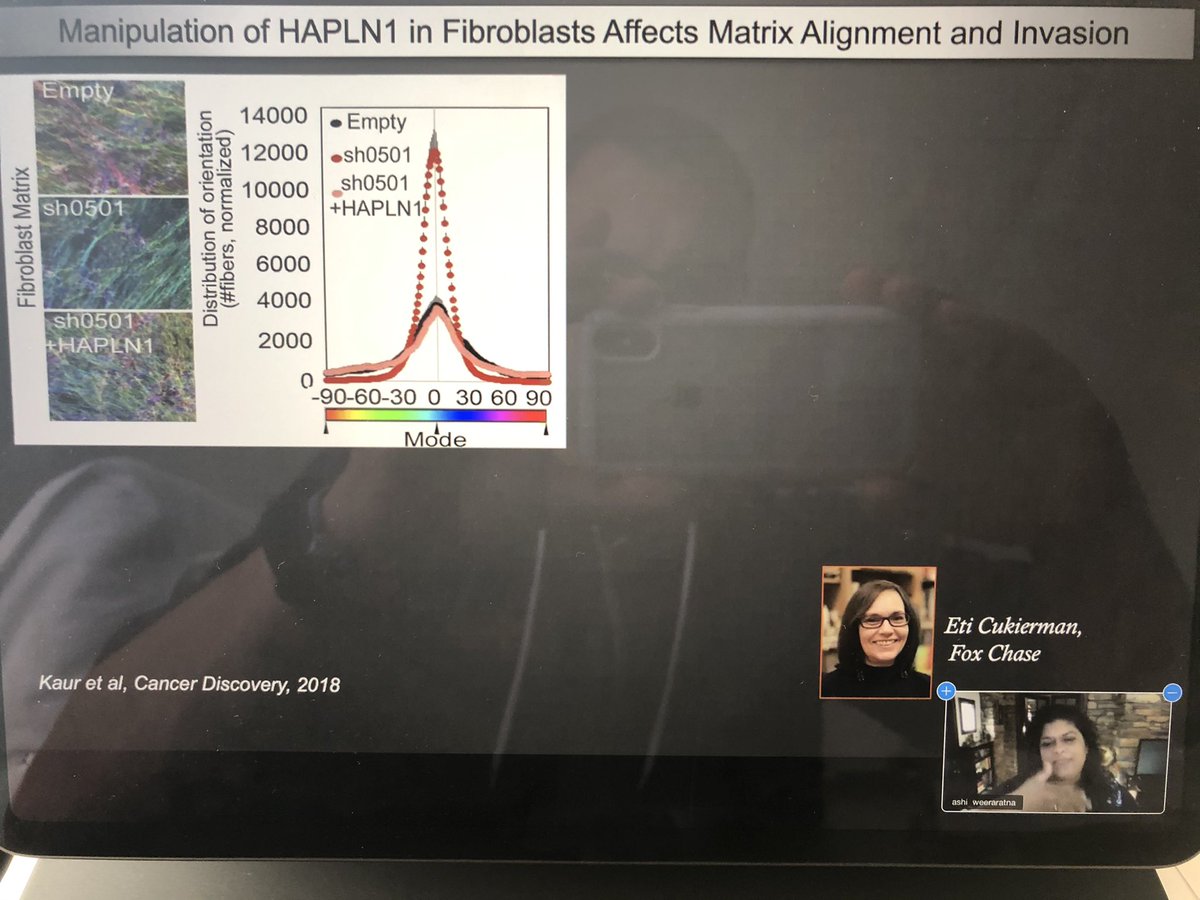
Anyone even remotely interested in tumor biology and metabolism should line up!
Apr 11

Looking for a postdoc position and attending AACR in San Diego? I'll be there, too, and the lab is actively recruiting! Send me an email with your CV and cover letter, and I’ll follow up if there is a mutual fit. See more about our research at airdlab.com.
203
Bednar lab retweeted

In Memoriam: Professor Greg Hannon (1964–2026) cruk.cam.ac.uk/news/in-memor… cruk.cam.ac.uk/news/in-memor…
9
18
13,995
Apr 7
Really nice work highlighting the role of stroma-produced PAI-1 and tPA in the modulation of pancreatic cancer immune response by our colleague, Kyoung Lee!
@UMICHpancreas
science.org/doi/10.1126/scia…
4
238
Bednar lab retweeted

Jan 26
Biology is not static -- proteins are constantly being made, modified, and destroyed as cells live, respond, and adapt.
Each cell interacts with other cells and its matrix to shape its proteome and dynamic responses. That’s why understanding in vivo proteome dynamics at the level of individual cells is one of the most exciting frontiers in understanding biological systems.
1/2
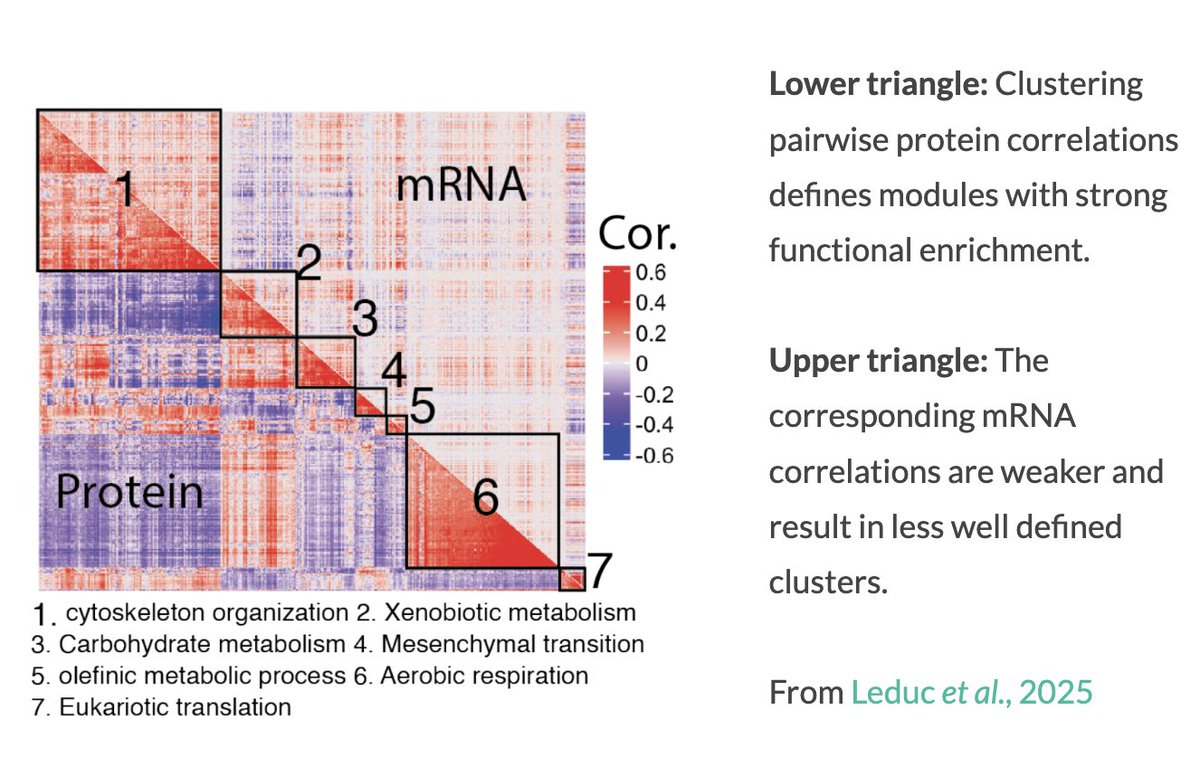
8
54
254
16,977
Bednar lab retweeted

Jan 23
Cover article of @CR_AACR by @Pasca_Lab @UMICHpancreas
Wilms Tumor 1–Expressing Stromal Cells Promote Pancreatic Cancer Progression
aacrjournals.org/cancerres/a…
Very nice study with autochthonous models to track the fate of WT1 fibroblasts and impact of depletion on natural history.
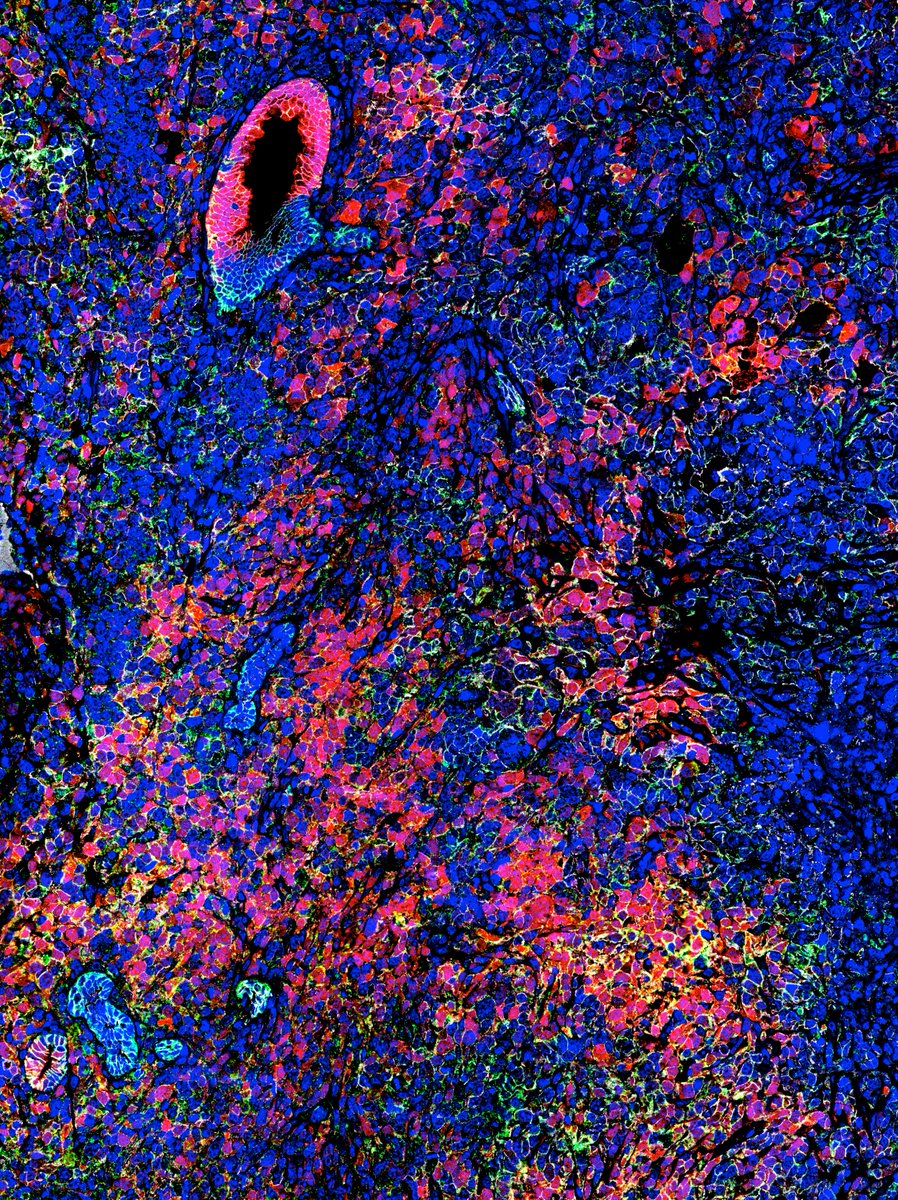
3
9
51
4,828
Bednar lab retweeted
6 Dec 2025
Preprint from @UMICHpancreas (Eileen Carpenter):
Longitudinal analysis of matched patient biospecimens reveals neural reprogramming of Cancer-associated fibroblasts ("NR-CAFs") following chemotherapy in #PancreaticCancer
biorxiv.org/content/10.64898…
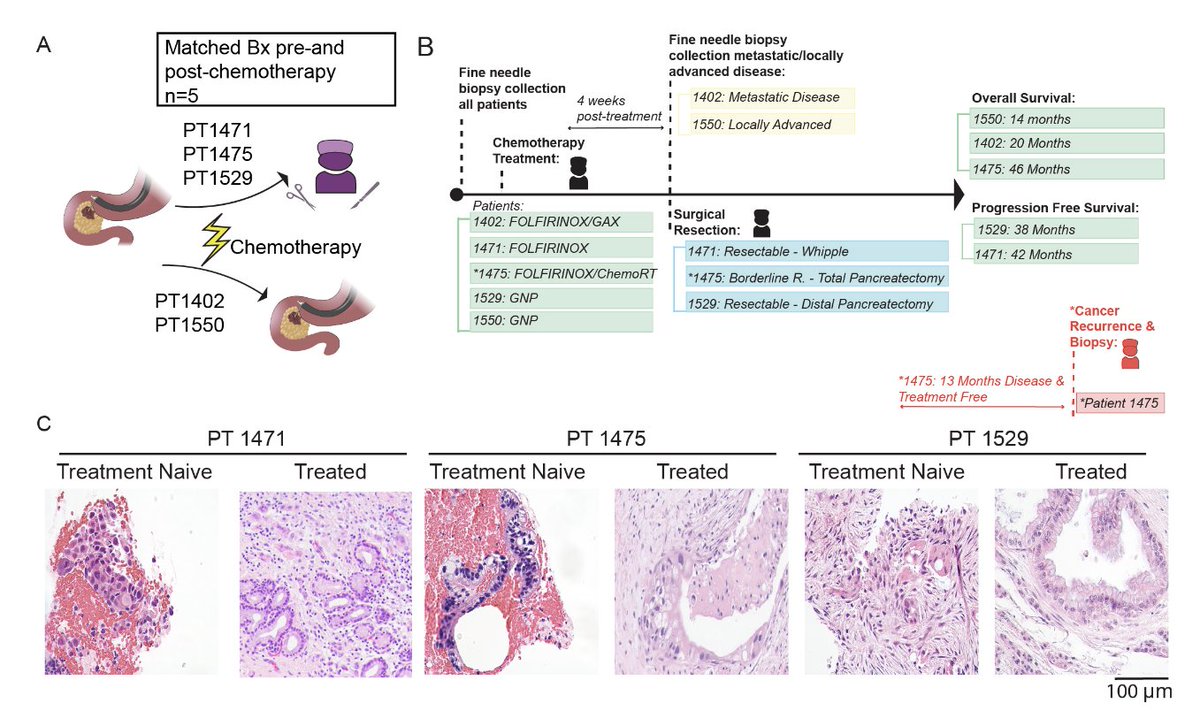
3
12
54
5,612
Bednar lab retweeted

3 Dec 2025
I’m thrilled to introduce you to the NeuMap! our latest work in @Nature. A global, comprehensive, single-cell transcriptional atlas of neutrophils across 47 biological conditions in human and mice. A real tour-de-force 🗺️ @AndrsHidalgo16 nature.com/articles/s41586-0…
10
48
183
24,187
Bednar lab retweeted

2 Dec 2025
Sharing our new preprint: In mice, lipid-rich diets prior to oncogenic Kras activation accelerate tumorigenesis and remodel epithelial-stromal plasticity and dynamics. Thanks to our outstanding co-first authors @kaur_urvinder and @erifaraoni
biorxiv.org/content/10.1101/…
6
13
1,011
Bednar lab retweeted

29 Nov 2025
Biology is not random. And so if you measure any aspect of it a lot of times and compare your data to a random model you will eventually rederive this fact. The problem with absurdly small p-values is that, because you can essentially always get them by juicing your sample size, when you see something like p < 10^-300 what it’s really saying is THAT biology is non-random, which we already knew, and not HOW it is non-random, which is what we really care about.
28 Nov 2025

The first rule of Data Science - if your p-value is less than 1 over the number of atoms in the universe, you're using the wrong model.
16
21
251
42,838
Bednar lab retweeted
25 Nov 2025
COLLECTION of papers on Spatial Transcriptomics of IPMNs (Cystic Precursor lesions of #PancreaticCancer):
aacrjournals.org/clincancerr…
aacrjournals.org/cancerdisco…
aacrjournals.org/clincancerr…
science.org/doi/10.1126/scia…
nature.com/articles/s41467-0…
biorxiv.org/content/10.1101/…
biorxiv.org/content/10.1101/…
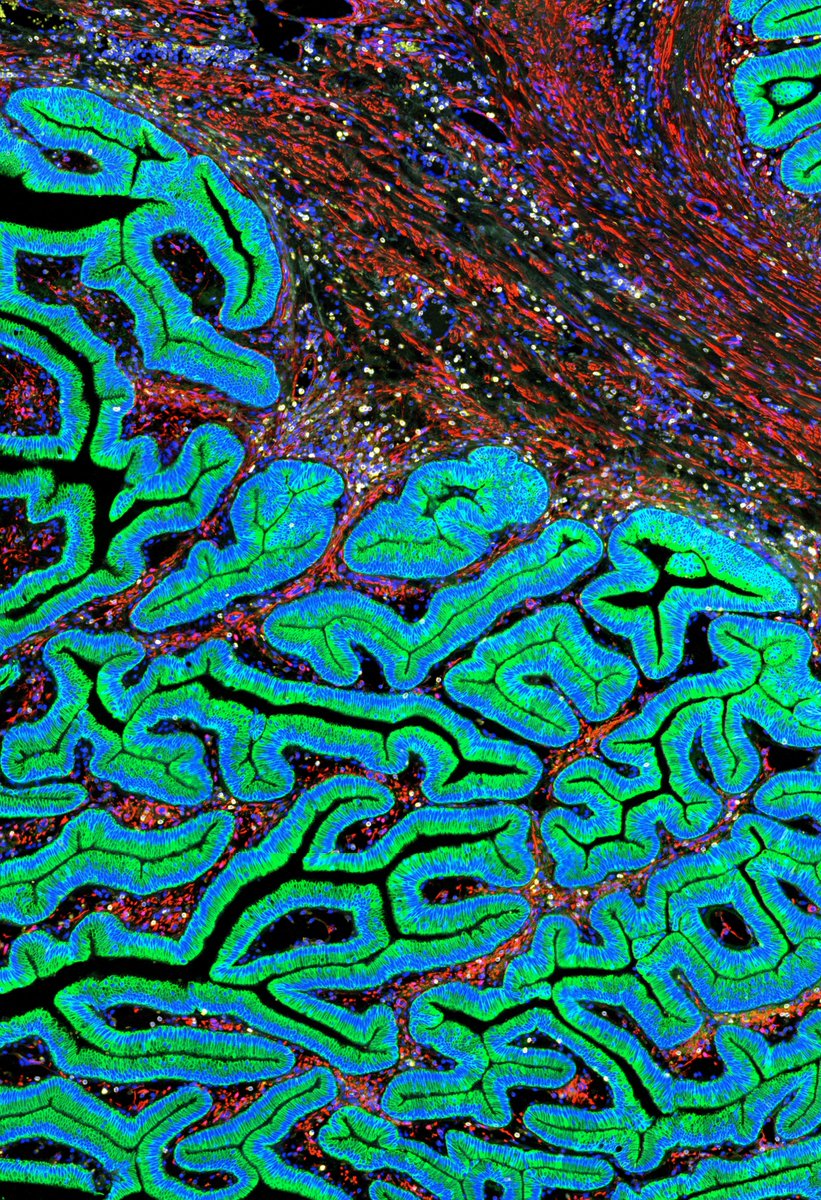
2
35
127
9,469
Bednar lab retweeted

28 Oct 2025
1/ You think your ML model fails because it’s “not powerful enough”?
No. It’s your data.
Garbage in, garbage out.
Here’s what most AI scientists miss when using public RNA-seq or single-cell data 👇

1
2
7
2,463
Bednar lab retweeted

We're excited to kick off the 2nd annual PancMidwest Symposium. We'll have two days of presentations, posters and networking among pancreatic cancer researchers in the region.



6
22
1,194
Bednar lab retweeted
28 Sep 2025
Kudos to @PanCAN for creating the SPARK data platform containing vast troves of clinical, imaging, laboratory & molecular data from Precision Promise and Know Your Tumor.
Fabulous resource for #PancreaticCancer researchers in both academia and industry. @sdosssdoss
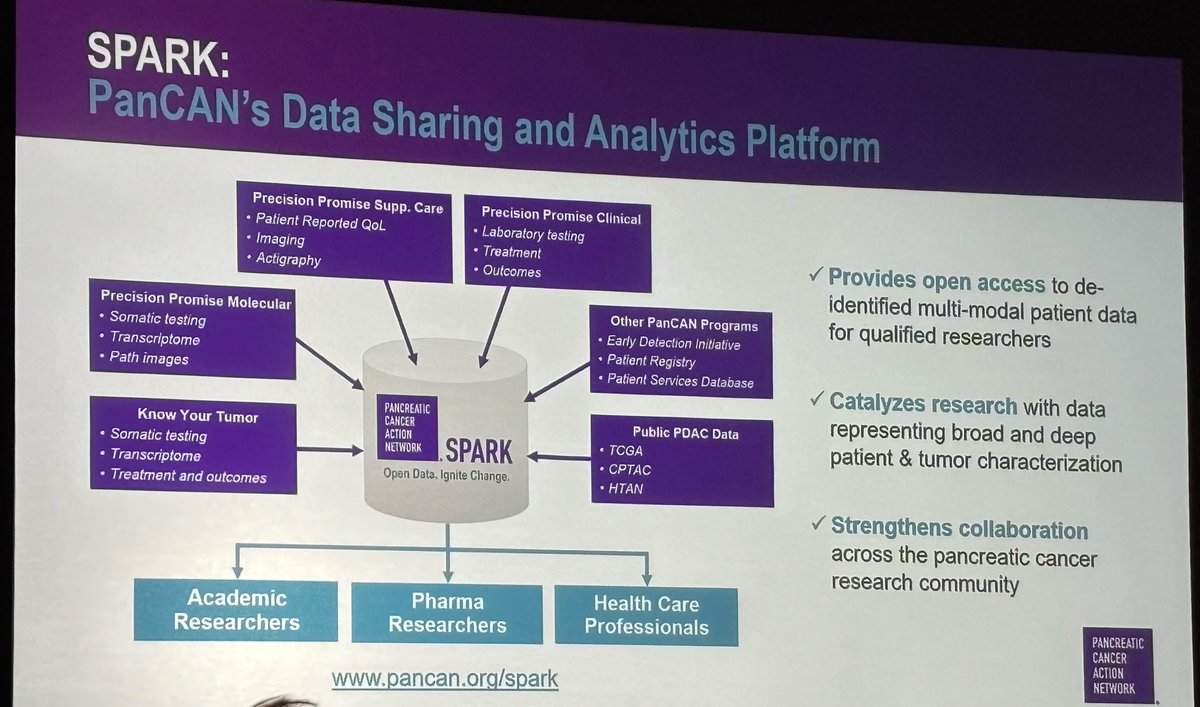
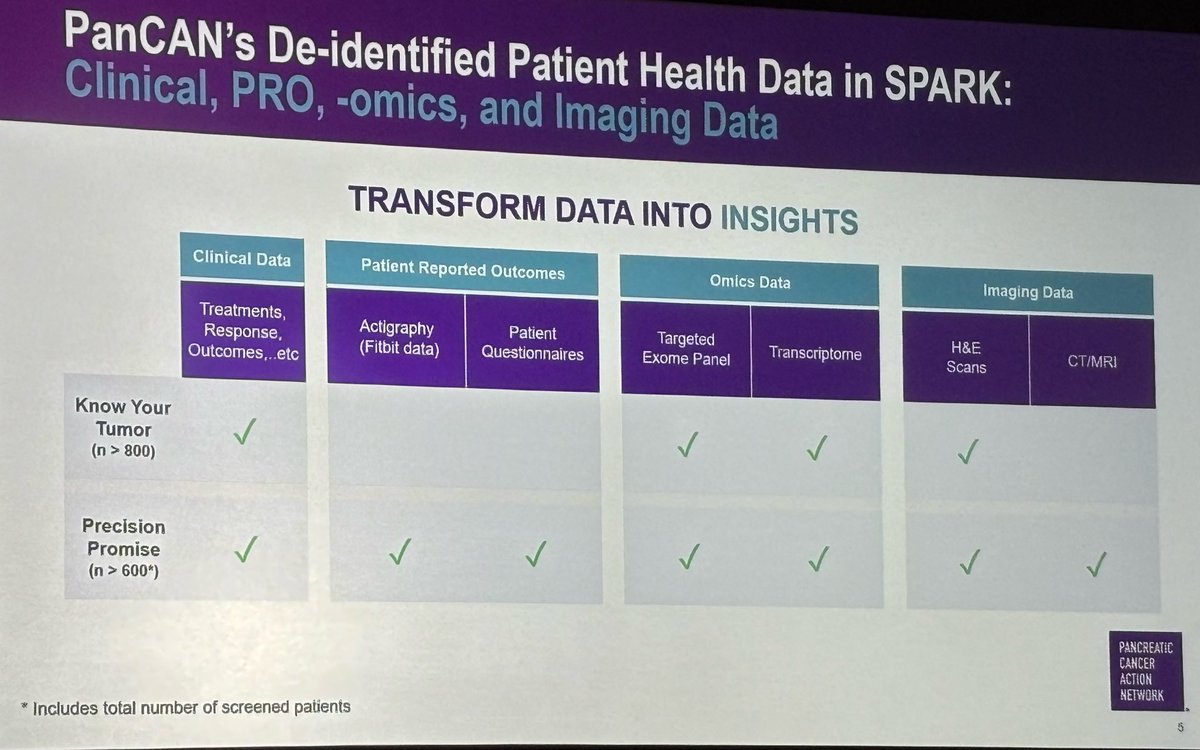

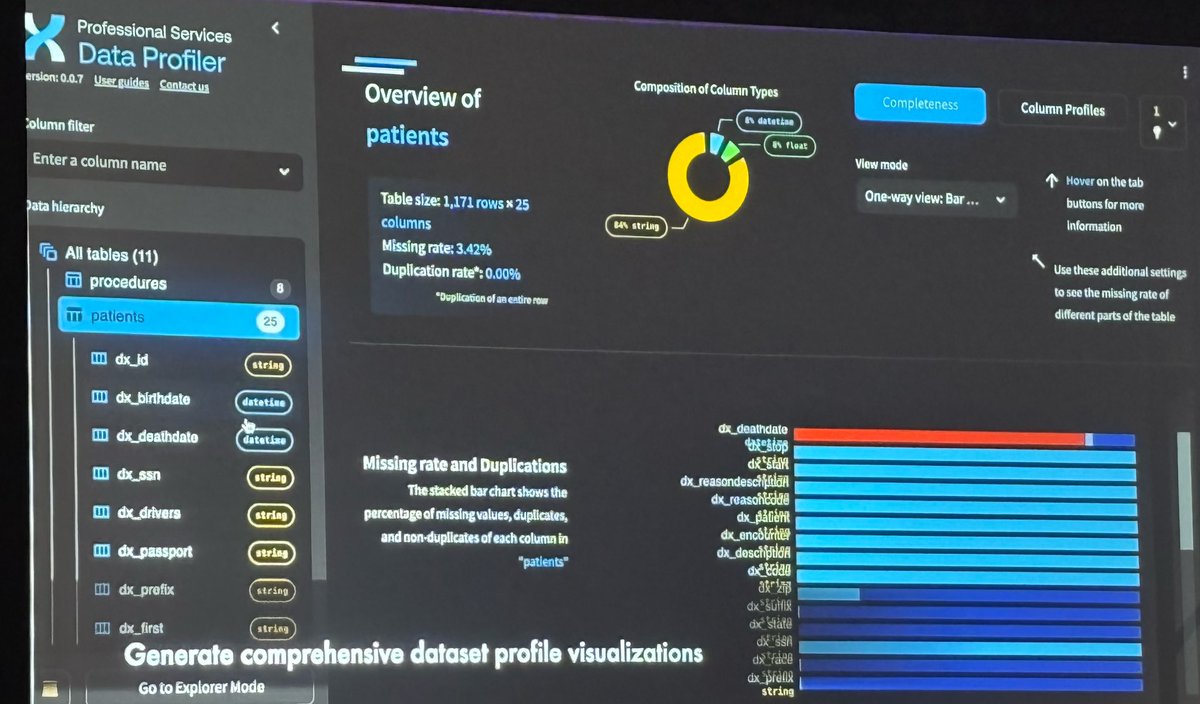
1
13
48
4,236
Bednar lab retweeted

20 Sep 2025
PSA: Stop calling macrophages in tissue M1 or M2. These are not states that exist in biology. The only use of M1 is a macrophage cultured ex vivo with LPS and IFNg; and for M2: IL-4/13/10. Macrophages in tissues are highly complex and diverse and do not resemble either of the aforementioned M1/M2 states. M1/M2 language causes confusion and sets the field back. Refer to your macrophages by the molecules they express and the cytokines they make.

32
175
937
73,602
Bednar lab retweeted
31 Aug 2025
Abstract titles for the 2025 @AACR special conference on #PancreaticCancer in Boston are now online:
aacr.org/wp-content/uploads/…
Full program:
aacr.org/meeting/aacr-specia…
#AACRPan25
Hope to see many of you there
@ednacukierman @lauradelongwood @isteaus @lustgartenfdn @letswinpc
2
18
63
5,963
Bednar lab retweeted
16 Jul 2025
A special @jclinicalinvest series on #PancreaticCancer led by @BenStanger01
jci.org/articles/view/191936
jci.org/articles/view/191937
jci.org/articles/view/191940
jci.org/articles/view/191943
jci.org/articles/view/191944
Articles by @lauradelongwood @Muir_Lab @MaddipatiLab
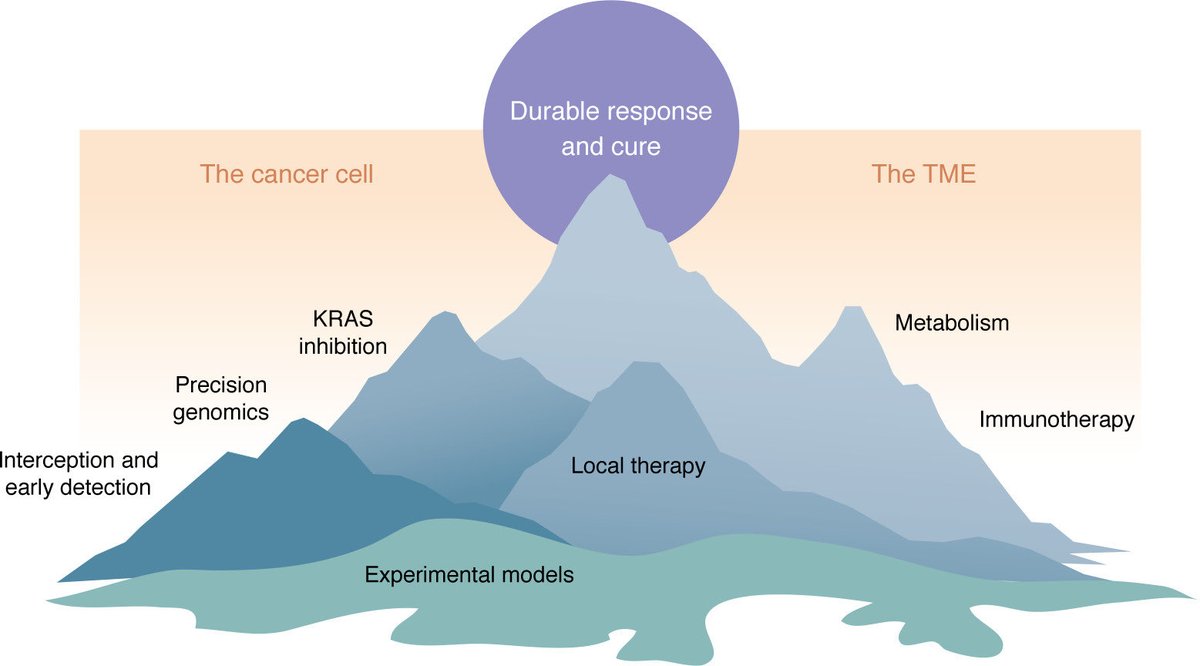
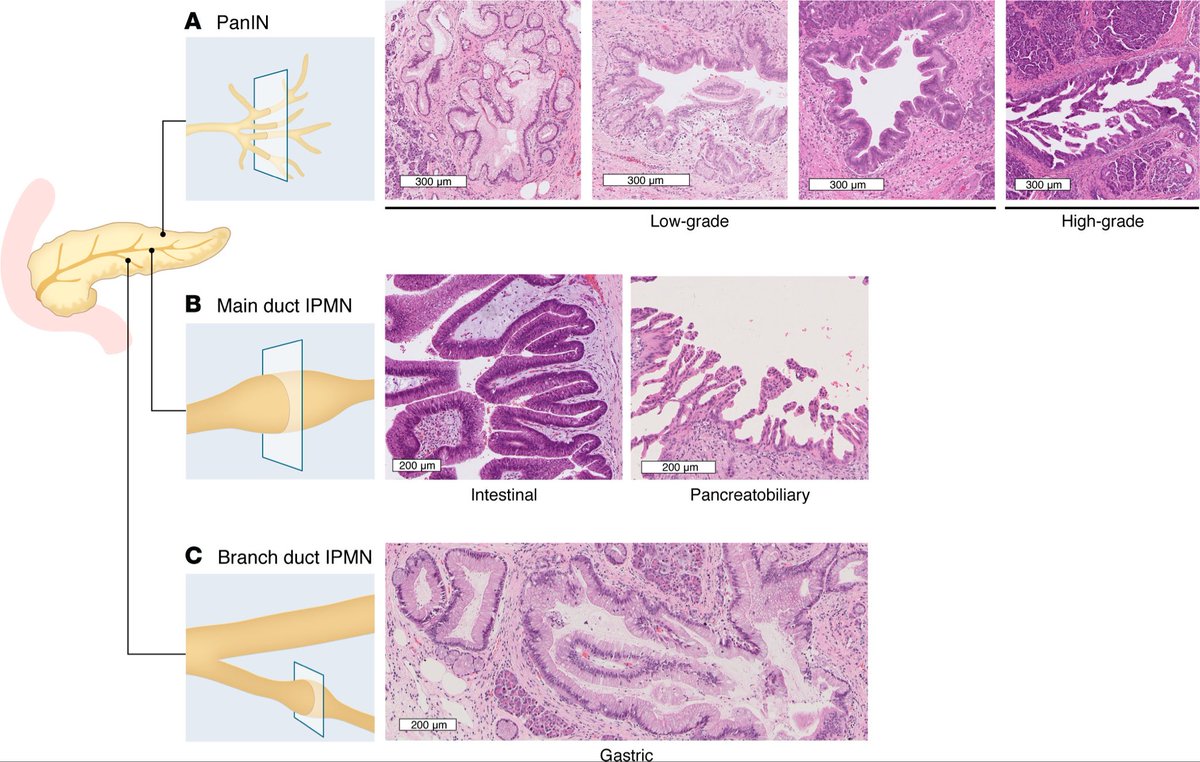
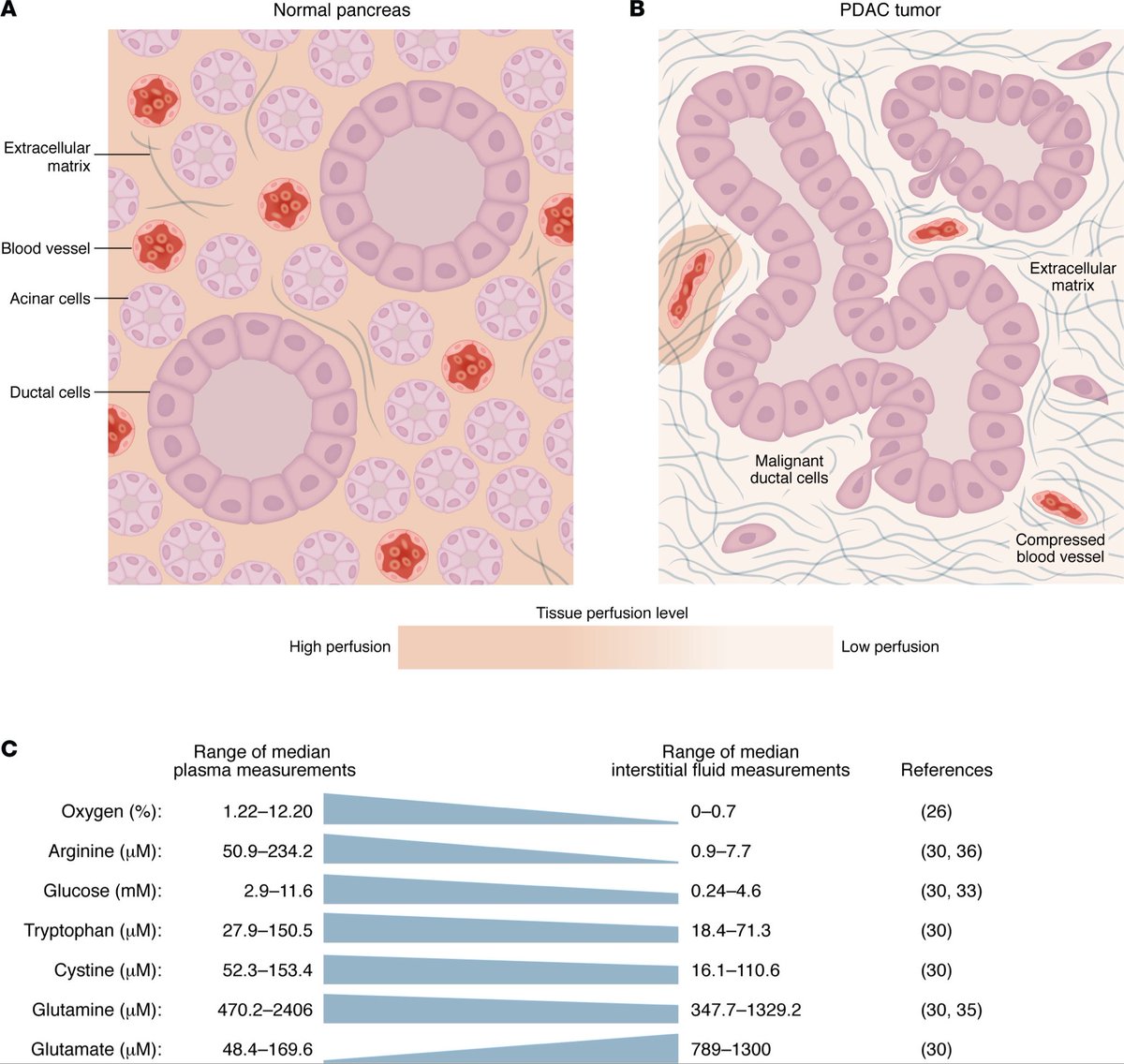
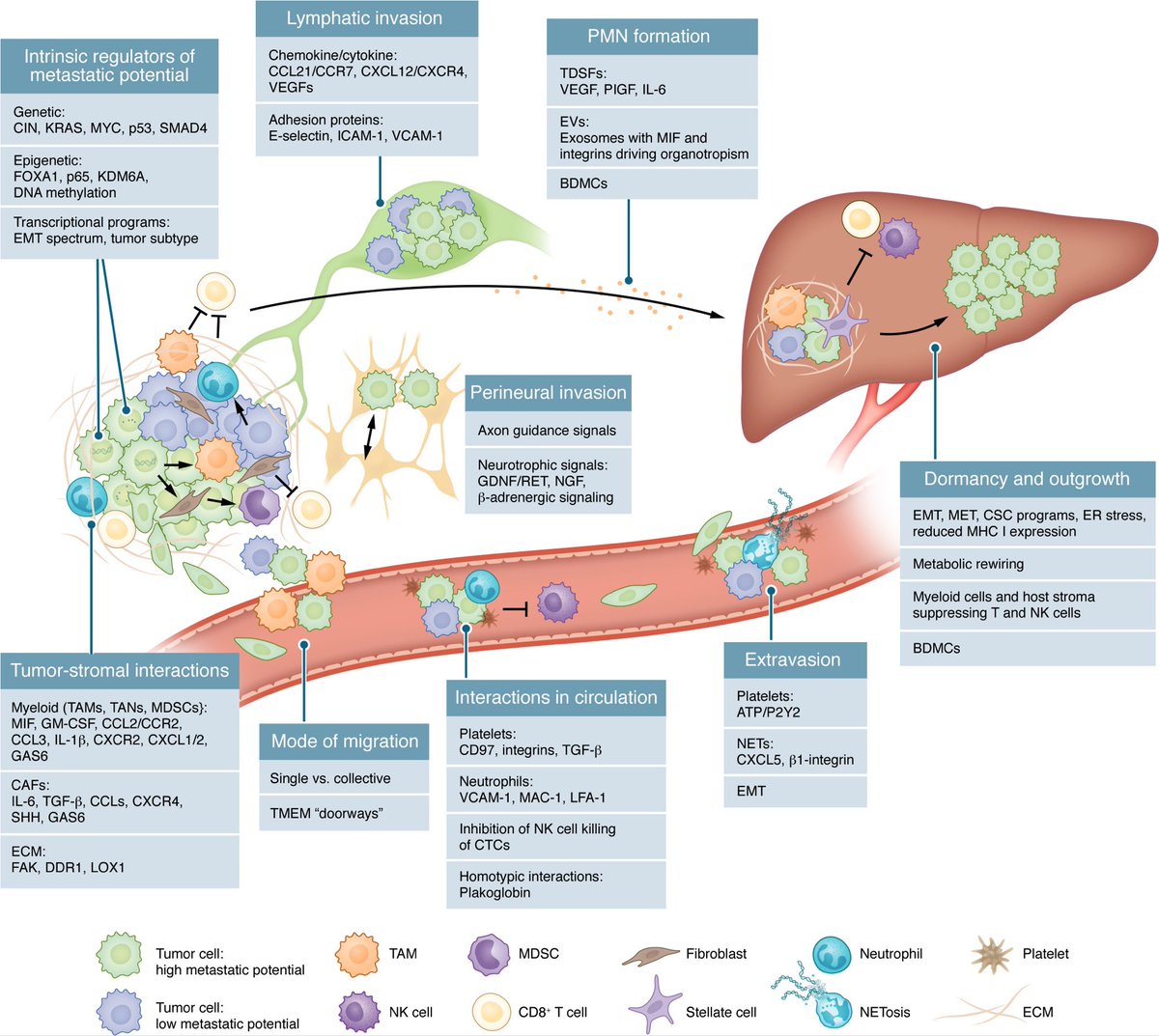
1
54
124
9,915
Bednar lab retweeted

27 Jun 2025
Excited to co-chair with @lauradelongwood @isteaus #AndyAguirre & @DavidTuveson
Submit your abstract!!
#AACRpan25 #PancreaticCancer

Submit an abstract by July 15 for the AACR Conference on Advances in Pancreatic Cancer Research (Sept 28-Oct 1; Boston), chaired by Andrew J. Aguirre, @EdnaCukierman, Susan Tsai, David Tuveson, and Laura DeLong Wood.
brnw.ch/21wTK6Y
#AACRpan25 @isteaus @lauradelongwood
9
35
3,675
Bednar lab retweeted
26 Jun 2025
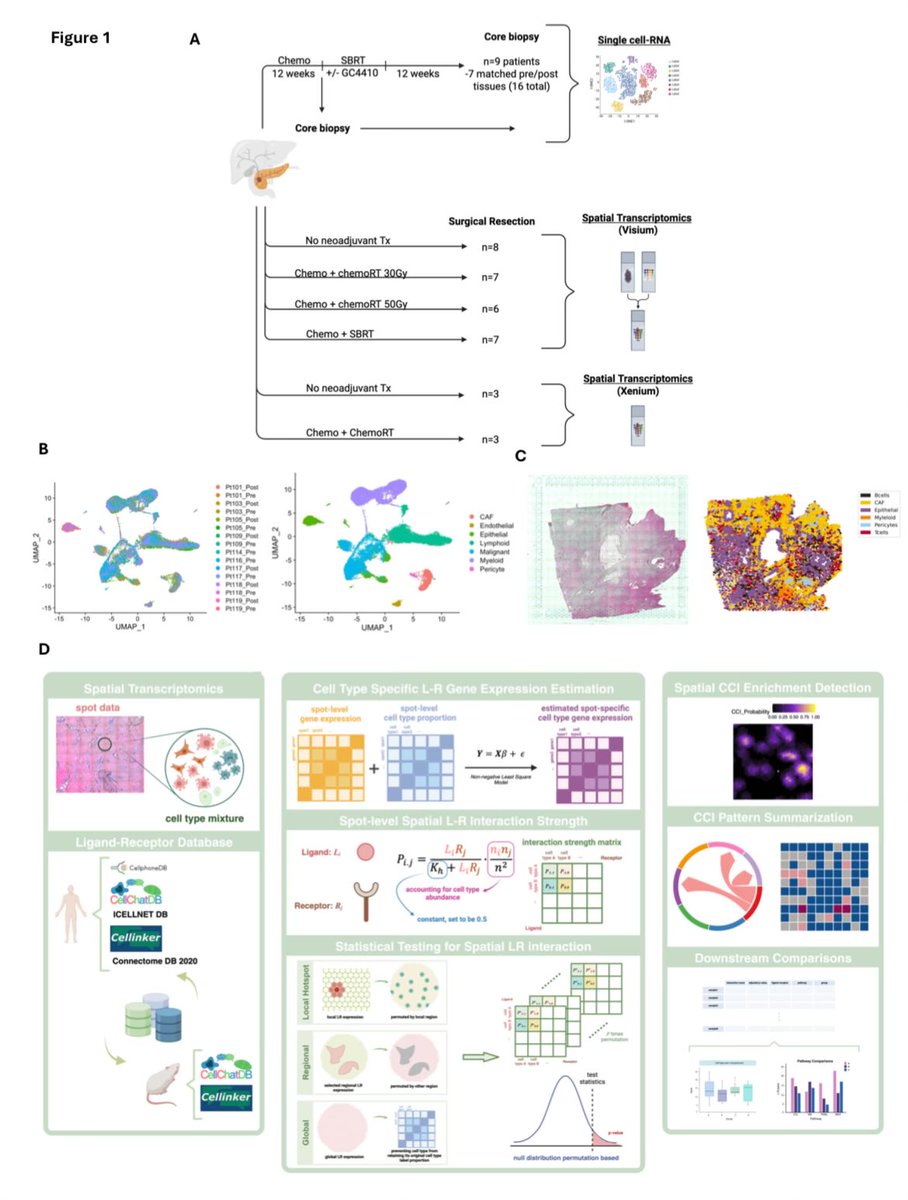
Coming out party / preprint for @Vince_BernPag who starts his faculty position @MDAndersonNews in a week. This study identifies adaptive responses to radiation therapy in pancreatic cancer using single cell & spatial profiling, resulting in persister cell populations post XRT.
2
13
41
7,609
Bednar lab retweeted

20 May 2025
Notice of Short-Term Extension to Early-Stage Investigator (ESI) Eligibility Period grants.nih.gov/grants/guide/…
49
77
19,319
Bednar lab retweeted
15 May 2025
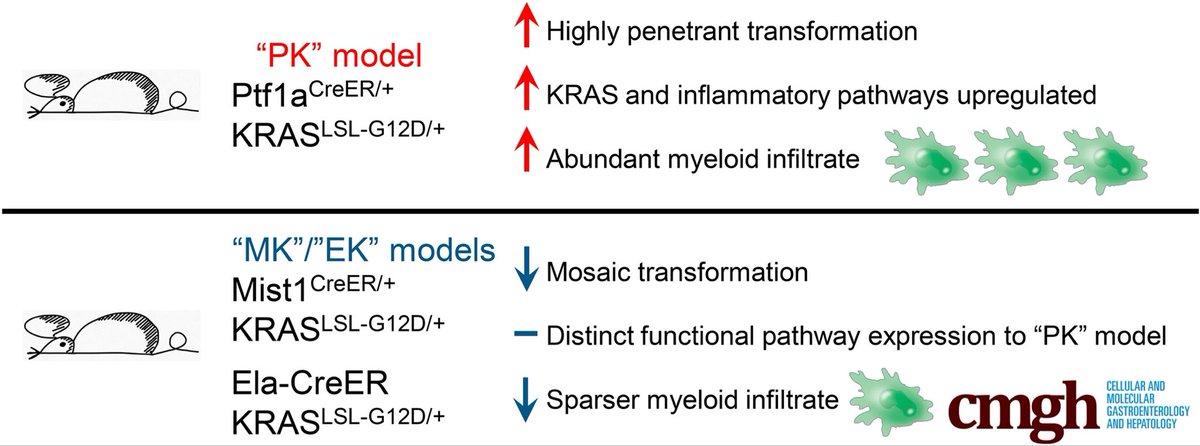
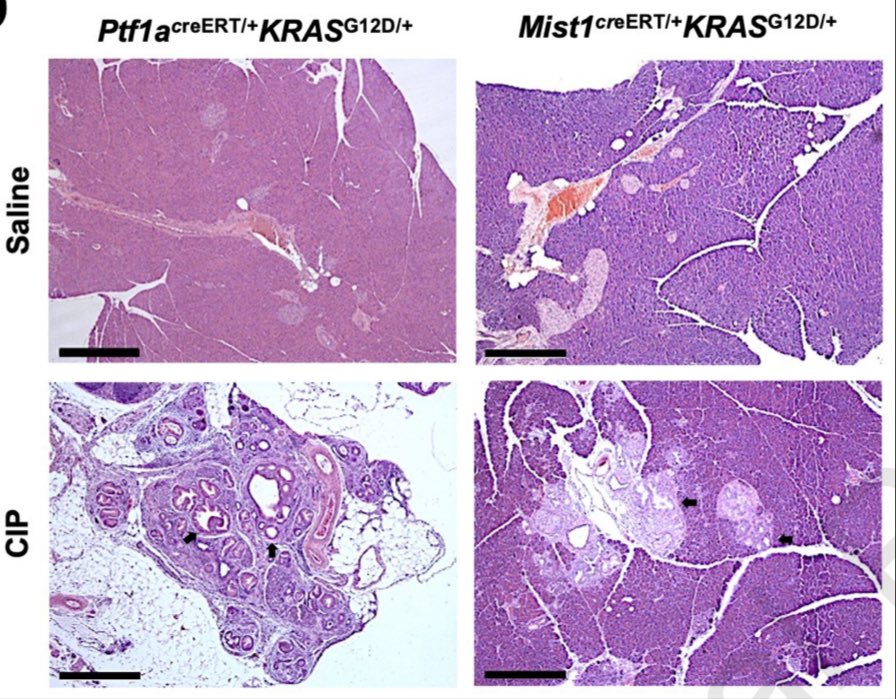
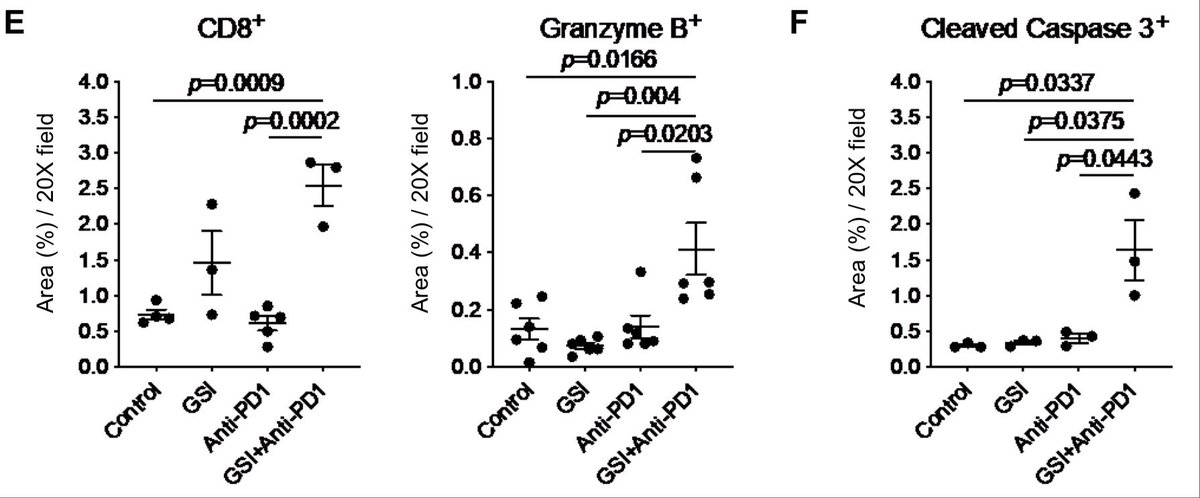
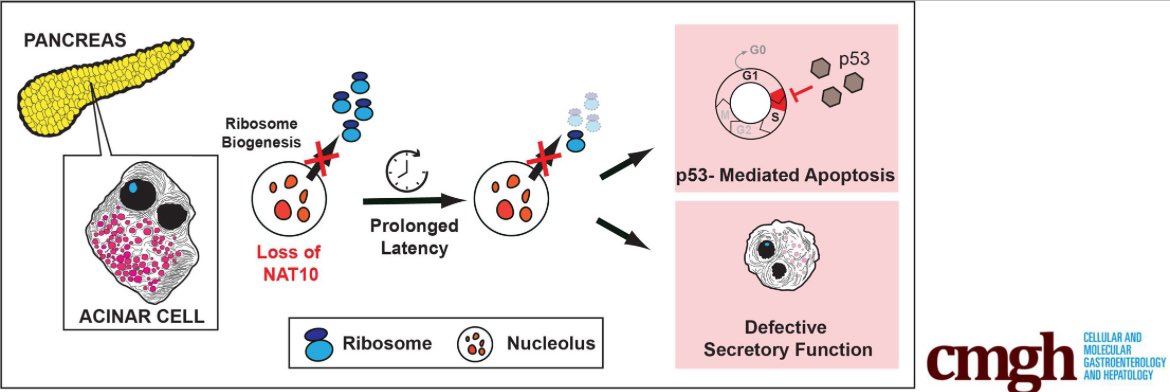
New editorial in @AGA_CMGH. I highlight elegant work by @Charles_C_33, @millsjc67 and colleagues showing how blocking ribosome biogenesis in vivo disrupts acinar cell homeostasis and suppresses tumorigenesis.
🔗Editorial: cmghjournal.org/article/S235…
🧬Paper: cmghjournal.org/article/S235…
5
16
1,399