
Christian,husband,father,Computer geek, and xbox gamer
Joined January 2007
- Tweets 25,557
- Following 1,883
- Followers 975
- Likes 821
575 Photos and videos







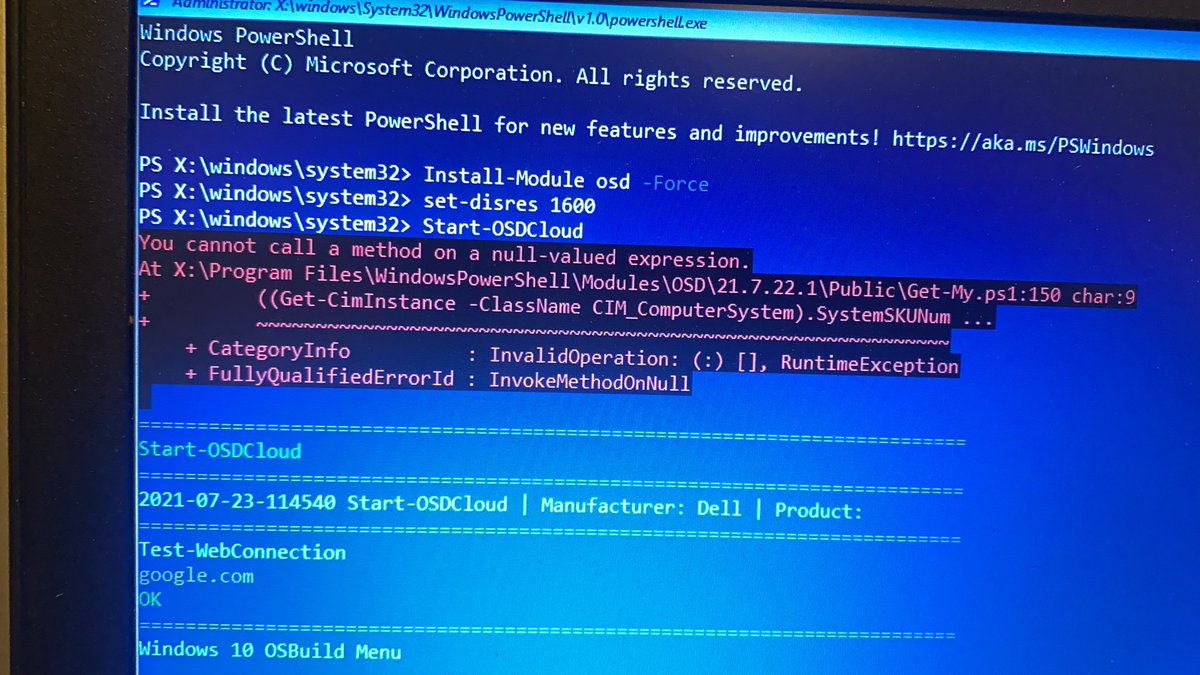


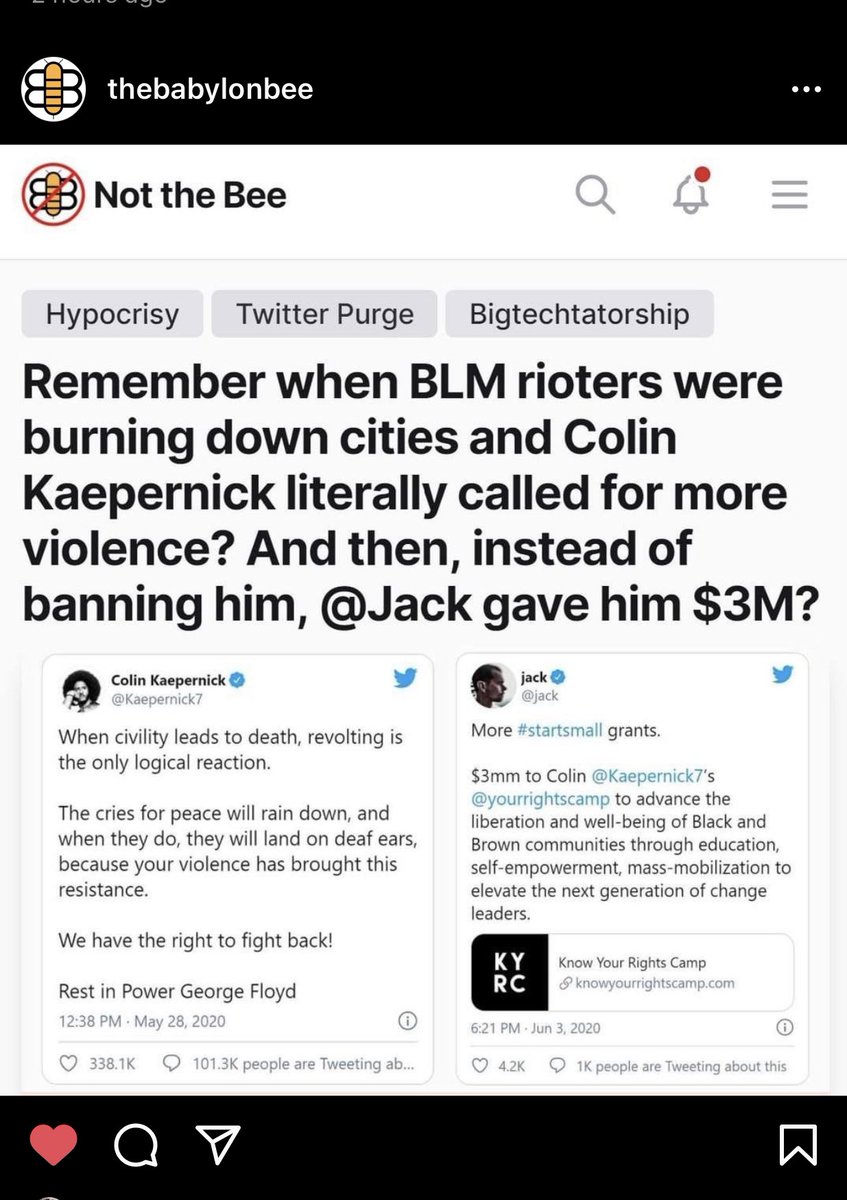



Jason Benway retweeted

Jun 11
Qwopus 3.6 27b-Coder is now live!
Scores a 67% on a full run of SWE bench verified with thinking completely disabled! Q5_K_M
This model is lightning fast for dense class! With a natively finetuned MTP head, it achieves 100 tps on a single 5090! The biggest upgrade here, though, is its stability in programming and tool calling within @NousResearch Hermes agent, with thinking off!
Wall time is crazy fast this way, which makes Hermes feel "native" and snappy, like they were meant for each other. The freedom of running without thinking at all makes you part of the thinking process, and you never get caught waiting 15 minutes for it to finish a thought string, like with the base models.
Thinking on and temp high, .9-1 seems to produce really incredible design and svg results. I reran the Boat survival prompt through a few turns, thinking on, and it seemed to render more fancy models in HTML canvas, but it was much more of a start-a-prompt and wait experience vs the snappy and active iteration with it disabled. It may be worth turning it off and on throughout the build process if you want to get really creative with design.
Really looking forward to seeing how this one performs for y'all! Please post comments with your opinions and use cases below! As always with our fine-tunes, mess with the temperature setting, and run them much hotter than the base!
Please check out the Boat Survival game I posted yesterday, made in 12 turns using Hermes and this model, with thinking off. Link below!
Full swe bench repo-specific breakdown also posted in the comments for those interested!
Happy building, everyone! We're looking forward to your thoughts! Quants uploading now!
huggingface.co/Jackrong/Qwop…
102
143
1,338
155,530
Jason Benway retweeted

Jun 9
HOT! SCAIL-2 just dropped!
End-to-end character animation via in-context conditioning
- no skeleton middleman, it copies pixels directly
- no glitches, no messy hands
- 512p/704p
- unified architecture for character replacement and multi-character tasks.
- zero-shot generalization to animal-driven and mesh-based control.
teal024.github.io/SCAIL-2/
10
67
462
44,582

Andrej Karpathy:
“Vibe coding is incredible. But agentic engineering is the next level.
90% of my coding routine is automated by AI agents.”
In this 30-minute talk, Andrej Karpathy explains how to build an AI agent workflow from scratch.
Worth more than 500$ agentic engineering course on the internet.
Watch it today, then read the article below.

64
117
1,056
173,323
Jason Benway retweeted

Jun 8
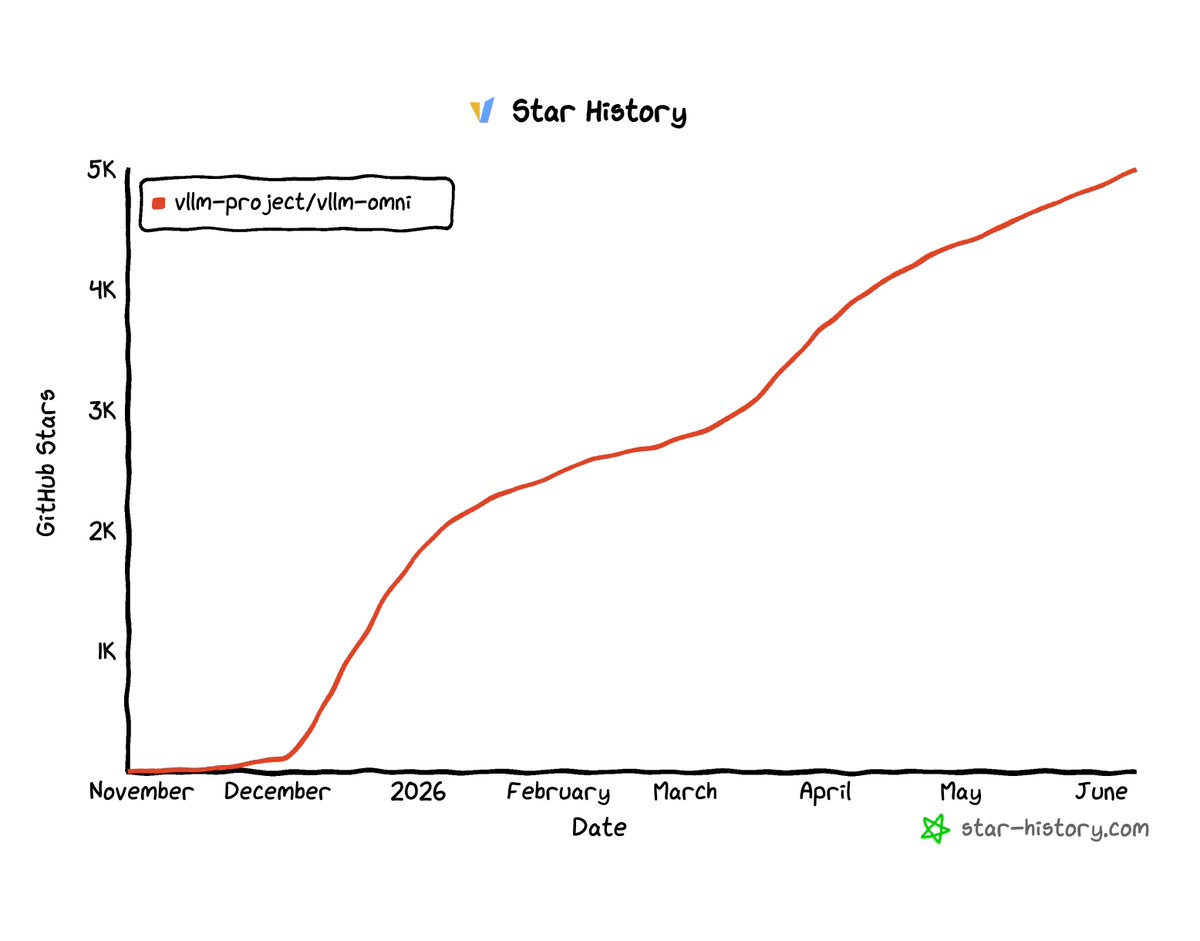
🚀 vLLM-Omni just hit 5K GitHub stars! 🎉
From a community kickoff in November to powering omni-modality inference everywhere: vLLM-Omni supports 30 models including Qwen3-Omni, HunyuanImage-3.0, Wan 2.2, BAGEL, MiMo-Audio, and Flux2, across NVIDIA, AMD, Huawei Ascend, Intel, and more.
Huge thanks to our amazing community, model partners, and everyone who's contributed a PR, filed an issue, or just given it a try.
Onto the next chapter of efficient, scalable, open multimodal inference.
⭐ github.com/vllm-project/vllm…
📚 docs.vllm.ai/projects/vllm-o…
#vLLM #vLLMOmni

9
17
147
9,567
Jason Benway retweeted

Jun 7
This is the best site on the internet to learn harness engineering.
Free. Completely.
Most AI engineers have never heard the term.
walkinglabs.github.io/learn-…
Bookmark this site.
Then read this setup ↓


54
440
3,302
443,565


Jason Benway retweeted

Jun 6
Chicago lost the Bears this week. A team that's been in the city since 1921.
They didn't lose them to a bigger market or a better deal. The Bears decided they'd rather be a tenant in Indiana than deal with Illinois for one more year.
Think about how badly you have to run a place for that to be the smart move.
They lost them for two reasons.
The people running Illinois would rather villainize a builder than keep one. And they're bad at their jobs.
In 2021 the Bears spent $197M on the old Arlington Park racetrack.
Before they could break ground, Cook County valued the empty lot at $192M (Bears said $60M). They were salivating at the chance to extort a building that didn't even exist yet.
That fight dragged on for years.
The Bears were ready to put $2B into the stadium. All they wanted was a promise the county wouldn't reassess them into oblivion, plus $855M for infrastructure everyone uses. Roads, transit, utilities. A $3B project, two thirds of it private money pouring into Illinois.
Springfield had since 2021 to get this done. They dragged it to the final night of session, passed it through the Senate at 3:39AM, and the House went home without voting.
So now it's all gone.
The funniest part? This started because Cook County tried to grab the tax early. They knew a built stadium would pay $53M a year. Now they get under $4M on a vacant lot. No jobs, no buildout, no new anything.
Congrats on fighting for scraps and losing the whole prize.
Pritzker: they're "an $8.5B valued business" that doesn't need propping up.
But be smart for a second. Almost every NFL city throws in public money for a stadium. Not charity. The return is real. Tourism, hotels, restaurants, jobs, game days, property tax on a huge development. The math works.
Indiana did the math. While Illinois sat on it for years, Indiana passed a bill in months, put up $1B, and took the team.
And the Bears took a worse deal to get there. In Illinois they were going to own their stadium. In Indiana they rent it from the state. A team that wanted to build its own home gave up ownership just to escape Chicago.
Nobody won but Indiana. The Bears lost their stadium. Illinois lost the team, the $2B, and $53M a year in taxes.
Pritzker after they left: "I wasn't willing to give up billions of dollars of taxpayer money to give it to a billionaire-owned family or team."
There it is. "Billionaire-owned."
That's how Democrats talk about any business right before they run it out of town. Call them a billionaire, act like you're saving working families, take a victory lap while the tax base drives across the state line.
Meanwhile they're running the whole state into the ground. And you already know how this ends. You're living in it.
Pensions are $143B in the hole, worst in the country and not close. You pay $6,285 a year in property taxes, double the $2,969 national average, for a city that's $1.15B in the red. The mayor called its finances "the point of no return."
When you run things this badly, you sell what's left.
They leased the parking meters for 75 years to Morgan Stanley and a sovereign wealth fund in Abu Dhabi. Took $1.15B and burned through it in two years. The investors already made it all back, with 58 years left to collect.
Sold the Skyway. Sold the downtown garages. Every asset that made money, gone for one check.
But a fixed property tax rate for a team that's been here 106 years? That's "propping up billionaires."
Companies are leaving. Boeing for Virginia. Caterpillar for Texas. Citadel for Miami. In 2023 alone Illinois lost 56,000 people and $6B in income to other states. The ones who left earned a third more than the ones who moved in.
Indiana didn't outbid anyone. AAA credit, 16 years straight. A $676M surplus. Fourth-lowest debt per person in the country. They just weren't a disaster.
Illinois could have collected $53M a year. It chose zero. Ignore all the bad management but make sure to stick it to those evil, pesky billionaires.
1,395
5,876
27,744
2,370,299
Jason Benway retweeted

The A-Team saves the day.
388
4,720
26,433
2,675,124

Jun 1
I must be missing something. copilot and Gemini have the ability to create notebooks. you store files, chats, and URLs together to be referenced and have discussion about. Claude and chatgpt have projects, but you can't add URL that get indexed and included.
42




Land confiscation is not just un-American. It’s also the definition of fascism.

Socialist mayor Mamdani just put NYC landlords on notice as he calls for taking “aggressive legal action” against landlords and transferring ownership of chronically neglected buildings to “the community.”
His pitch: crack down on bad owners and remake who controls housing in NYC.
1,173
2,485
13,754
276,565
Jason Benway retweeted

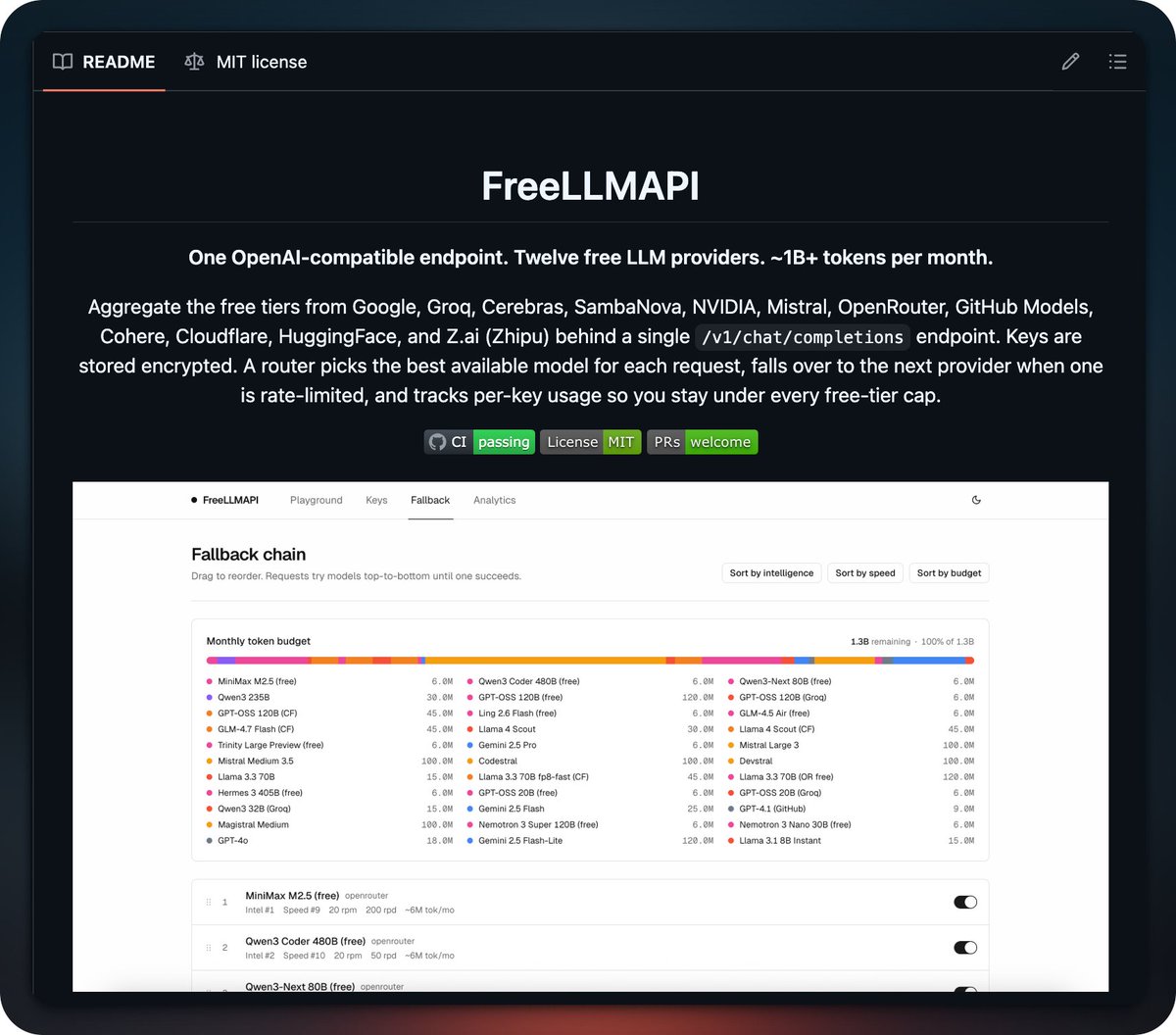
FreeLLMAPI aggregates 12 free LLM provider tiers behind a single OpenAI-compatible endpoint for about 1.3B tokens per month.
- Streaming, tool calling, and automatic failover across providers
- Keys stored encrypted with per-provider token budget tracking
- Works with any OpenAI SDK by changing base_url
- Supports Google, Groq, Cerebras, SambaNova, Mistral, and more
Explore it here:
opensourceprojects.dev/post/…
2
18
178
14,359
Jason Benway retweeted

May 25
Today is our nations Memorial Day. Enjoy your day and take a moment to remember the true meaning of this day. A day to pay our respects to all those who have given their lives in our country's defense. God bless these brave heroes and their families.

611
7,519
35,612
478,257
Jason Benway retweeted
May 22
BREAKING! Qwopus 3.6 27B is LIVE!
Thank you for your patience on this one, but I believe you'll find the wait was worth it!
We've benchmarked this thing up and down, verified that it holds at least a 75.25% (152/202) in the initial 202 SWE bench solves. Not a full run of 500, but it shows the agentic coding quality from the original 27B is retained while adding all of the additional Qwopus benefits across many domains. As always, Jackrong is absolutely cooking here!
COT quality has improved significantly through the inversion techniques from our Negentropy proof of concept. It also went through thorough curriculum training. You can check out the MMLU pro benchmarks on the model card, but it improved a whopping 10 points over the base model in physics, as well as meaningful jumps in Chemistry, business, and computer science.
However, the best part is that I was able to build an entire survival shooter game using this local model entirely. I genuinely was blown away by the results, which you can play right now on my HF space (link in comments below). "Qwopus Commander" was completed in 9 turns of Qwopus 3.6! To test the new long context training, I made it re-output the entire 3000 line program each turn, and it would make fixes and add features that I requested in large prompts, while perfectly replicating the entire rest of the game from context. What's more is that I did it all at Q8 KV cache quantization, and never had an issue over the entire 303k token run!
IMPORTANT: Run it at --temp 0.75 to 1. Mess with it in that range for your use case. Higher temp actually lets the fine-tune shine and be exploratory and is also more stable. Swe Bench was run at temp 1, the game was built mostly at 0.8!
We're so blessed to have all of you here and using the models! The support means so much! Please let me know what you build with it in the comments! Or if you have any issues getting it up and running, I will try my best to get back to you!
Looking forward to seeing what you legends produce with it this weekend!
huggingface.co/Jackrong/Qwop…
80
135
1,373
88,338

GBrain is my gift to you so you can have the same personal AI that I do. It's experimental but getting better every day. MIT License.
github.com/garrytan/gbrain
12
13
124
12,674

after today's spark posts, lots of you asking how the hermes agent /goal flow actually works. here's how to write a goal that actually executes.
what /goal does:
> hermes agent autonomous mode, you set the goal once, model executes without supervision, writes files, runs commands, builds, tests, iterates, closes the loop or tells you why it can't.
what to delegate:
> that one idea you've been thinking about but never started
> small broken thoughts you can't fully articulate yet
> a full feature suite you don't have time to build
> a research direction you want explored without writing it yourself
> anything where the outcome matters more than the path
how to write a goal that actually executes:
> single concrete outcome (build X, optimize Y, port Z, debug A)
> bounded scope (not "make my code better", be specific about WHICH code, what better means)
> ask for tests alongside the build (model writes tests, runs them, fixes until green)
> testable success criteria the model can self-verify (specific output, specific behavior, specific number)
> outcome-specific (X tokens/sec, Y test pass rate, Z file structure)
> include constraints (don't break existing API, keep file under N lines, use library M only)
GOOD goal examples:
> "build a multi-file html particle physics demo, 60fps minimum, write tests that verify particle count collision math, make it pass all tests, then serve on localhost:5000"
> "port my triton kernel at /path/to/kernel.py to native CUDA C , integrate into llama.cpp at the mmq dispatch path, benchmark vs current implementation, write a comparison report"
BAD goal examples:
> "make this faster" (which? how much faster? what's the bound?)
> "explore pytorch" (no endpoint, model loops forever)
> "design a beautiful UI" (taste calls = needs human judgment mid-run)
set the goal before bed. wake up to either receipts or a clean error log.

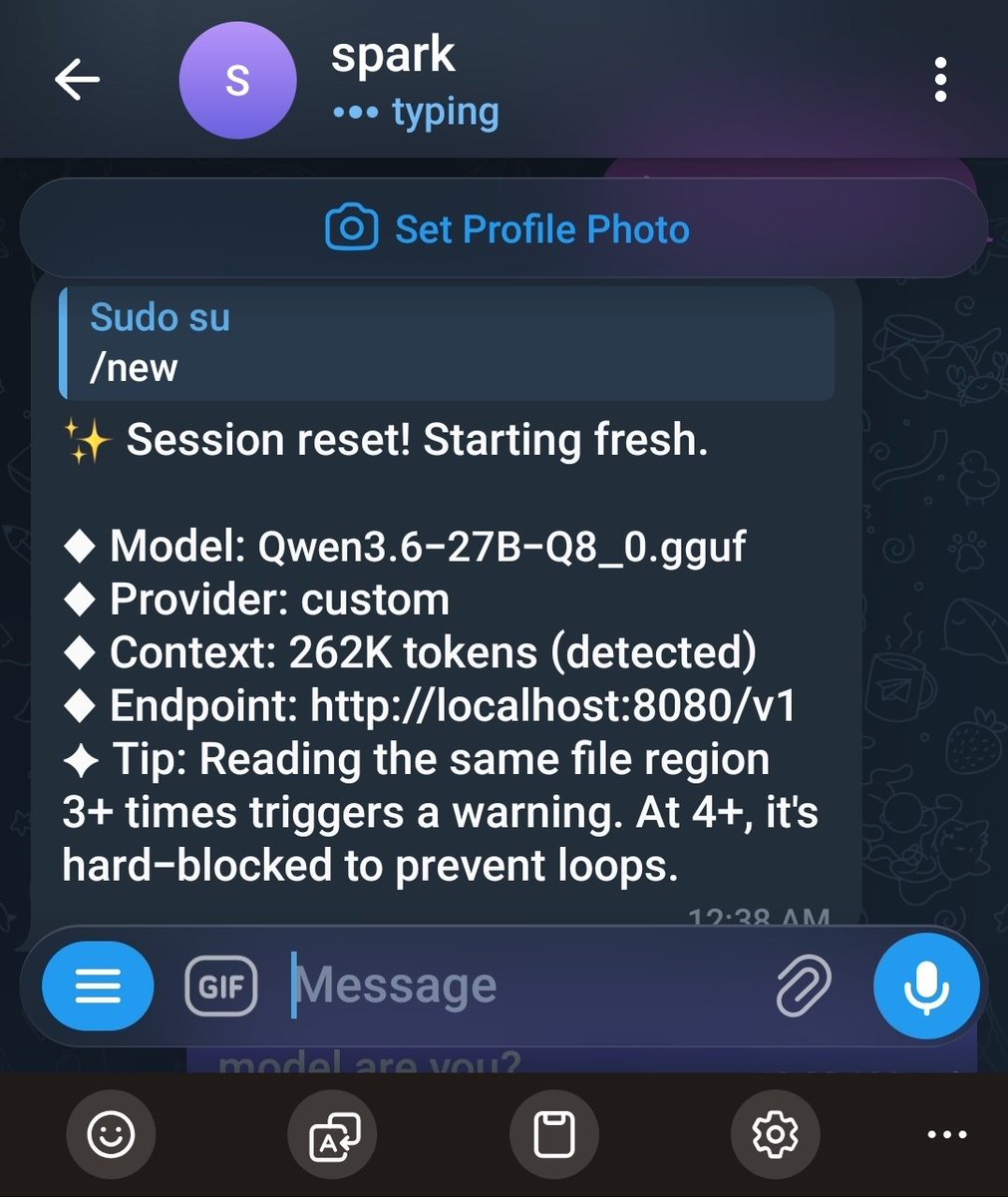
i named my dgx spark "spark." it runs hermes agent /goal overnight.
brain is qwen 3.6 27B Q8, 262K context, i set a goal before bed and wake up to results. no rate limits. no token costs. just local inference grinding while i sleep. this thing never stops.
26
61
813
98,328
May 5
Who's tried the agentic upgrade to co-pilot for Outlook? Have you found it useful or beneficial compared to what was there before? It does seem to give better answers but it still seems very limited #mscopilot #outlook
20
Jason Benway retweeted

Apr 27
It’s not just about baseball or good sportsmanship on the field.
This is about something much deeper — it’s about being a decent, kind human being who does the right thing.
129
1,048
14,950
3,401,948
Jason Benway retweeted

Apr 27
10 free websites that feel like cheat codes for life.
You used to pay for half of these. Bookmark them before you forget.
1. Photopea
A free Photoshop that runs inside your browser. Opens PSD files.
Site → photopea.com
2. TinyWow
100 free tools in one place. No signup. No watermarks.
Site → tinywow.com
3. Cobalt. tools
Paste any video link. Get the video. No ads. No tracking.
Site → cobalt.tools
4. Remove .bg
Removes the background from any photo in five seconds.
Site → remove.bg
5. Hemingway Editor
Paste your writing. It highlights everything weak, wordy, and unclear.
Site → hemingwayapp.com
6. WolframAlpha
Solves any math or science problem and shows the steps.
Site → wolframalpha.com
7. Squoosh
A free image compressor built by Google. Shrinks photos to a fraction of their size with no quality loss.
Site → squoosh.app
8. Internet Archive
Free access to 35 million books, films, and the entire history of the web.
Site → archive.org
9. Crash Course
Full college-level courses on history, science, philosophy, and economics. 100% free on YouTube.
Site → thecrashcourse.com
10. Excalidraw
A free whiteboard for diagrams, flowcharts, and wireframes that actually look professional.
Site → excalidraw.com
Here's the wildest part:
If you replaced these with paid alternatives, you would spend $200 to $500 every single month.
All of them. Free. Forever. No accounts. No subscriptions.
The internet has secret rooms most people never enter.
These 10 are the doors.
Save this before you forget.
100% free. Forever.
19
256
1,076
53,306