
Joined October 2024
- Tweets 39
- Following 1,704
- Followers 74
- Likes 48
3 Photos and videos


May 11
Typescript functions behind MPP paywall are powered by @CloudflareDev Dynamic workers. They absolutely nailed it.
May 11

@payweave now supports @solana.
Accept @mpp payments with sub-second USDC settlement on @tempo or @solana .
Fully non-custodial wallets powered by @privy_io .
AI agents discover both networks and pick whichever they prefer at pay time.
pay.sh client can call any MPP endpoint listed on our marketplace.
@SolanaFndn @solana_devs #solana #mpp #x402
31
May 11
Your terminal has a wallet. Now give your API a paywall.
payweave.app turns any endpoint, function, or file into a paid one,
auto-listed in the marketplace.
No keys. No subs. Just earn-request revenue.

39
May 11
This is exactly the demand side we’ve been building the supply for at @payweave
pay.sh = agents with wallets.
payweave.app = APIs, functions, and files that earn per request.
Same protocol (MPP). Same 402 flow. Two ends of the agent economy wiring up. 🤝
May 11

Give your terminal a wallet and access to pay-per-use APIs. No accounts. No keys. No subscriptions.
Pay.sh is a CLI that works with Gemini, Claude Code, Codex, Openclaw, Hermes, and more.
Aents pull from an open marketplace covering @googlecloud and 75 other APIs from @TektonicCompany, @PayAINetwork, @rye, @crossmint, @agentcashdev, @corbits_dev, @moonpay, @paysponge, @atxp_ai, and more.
Full tutorial below 👇
1
51
May 5
1
44
May 5
27
Apr 23
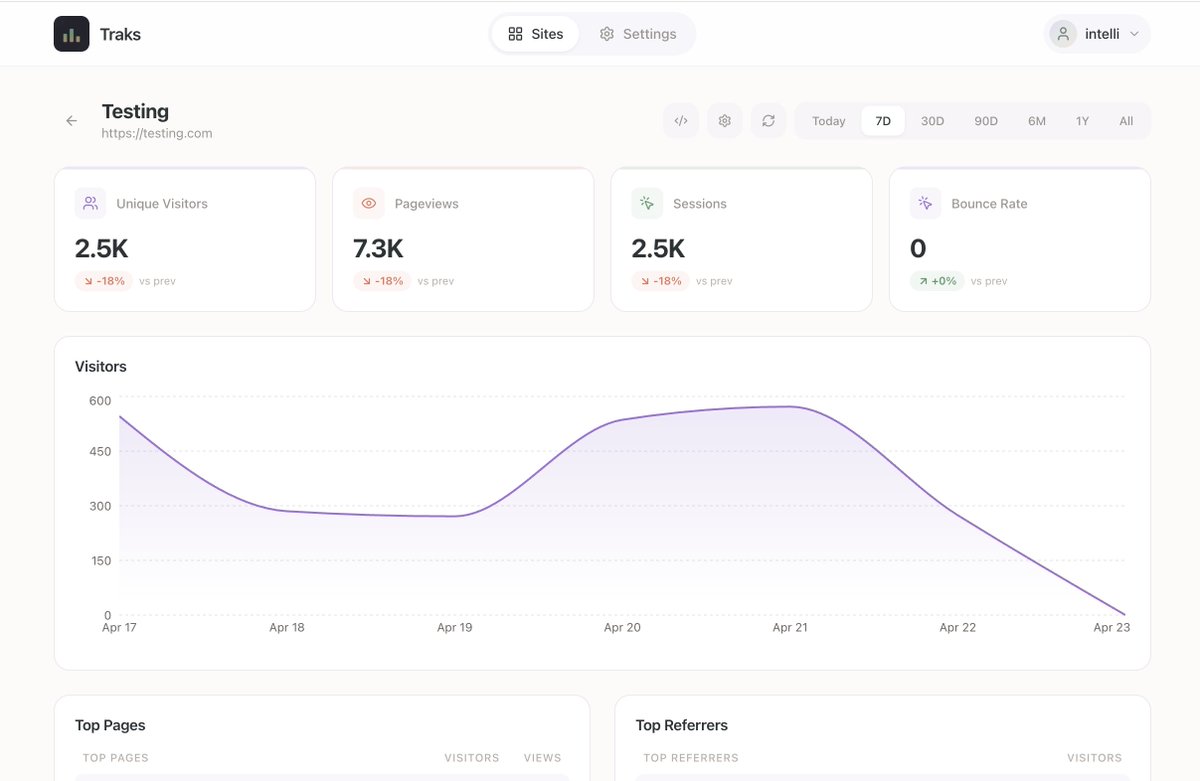
Been building Traks(Web Analytics Platform) on @Cloudflare pipelines r2 sql and honestly.
This combo is stupid good.
ingest firehoses into r2 as parquet, query it straight with sql. no warehouse, no etl glue, no ops.
The Serverless data stack is finally here.
Using it for my personal projects as i'm still digging into the exact r2 sql limits. concurrency, scan size, query duration and other limitations.
Apr 21

Cloudflare continues to build up its zero-egress-charges data warehouse capabilities with R2 Pipelines
Ingest data into an Data Catalog-enabled R2 bucket, using Pipelines or other mechanisms, then run queries over it using R2 SQL or your favourite engines like Snowflake. Pipelines can ingest, transform, and load streaming data into Apache Iceberg or Parquet in R2.
Both got new features on Monday:
You can now ingest logs directly into Pipelines from your Cloudflare Workers by using Pipelines as a Logpush destination. Logs can be noisy, so using Pipelines, you can trim down to the fields you need before the data is stored in R2 in Parquet files or Apache Iceberg tables.
R2 SQL now supports functions for easily querying JSON data, alongside improving readability of EXPLAIN queries by allowing them to be formatted as JSON.
Lastly, unpartitioned Iceberg tables can now be queried directly - this should only be used for smaller tables, as partitions will significantly help performance at larger scale.
2
1
4
322
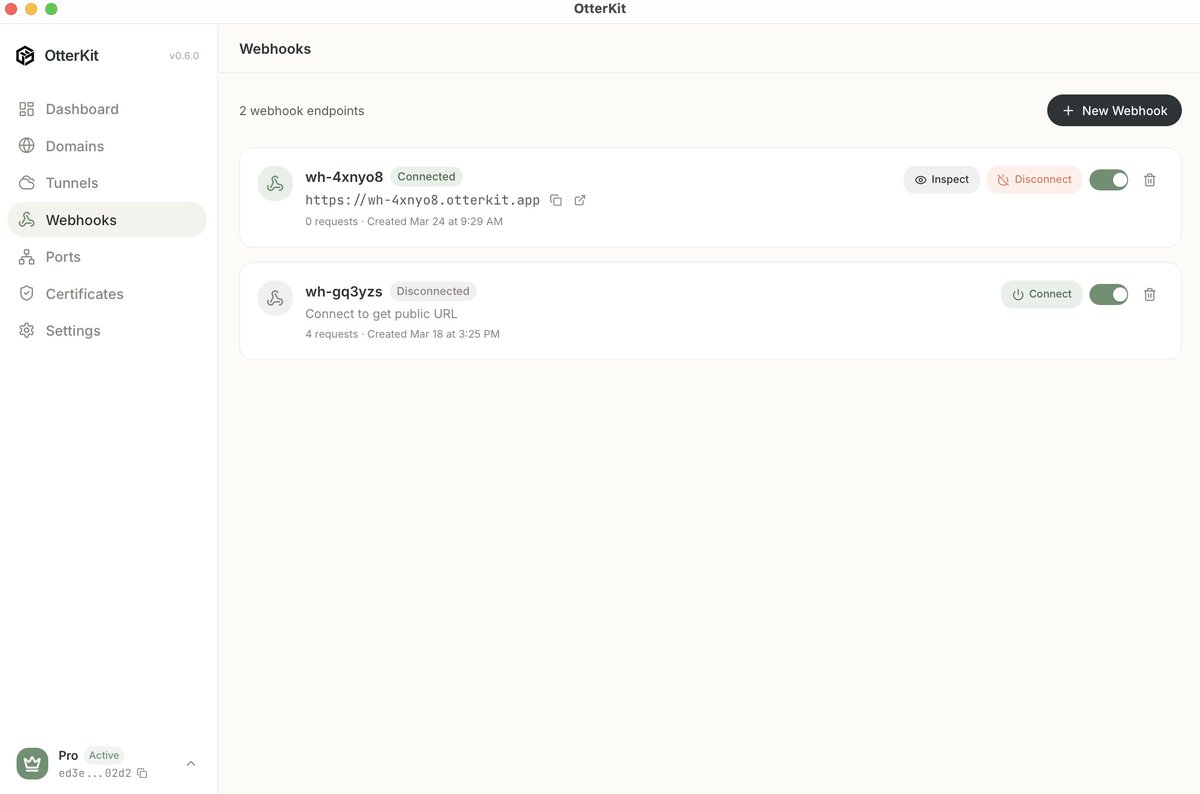
Mar 24
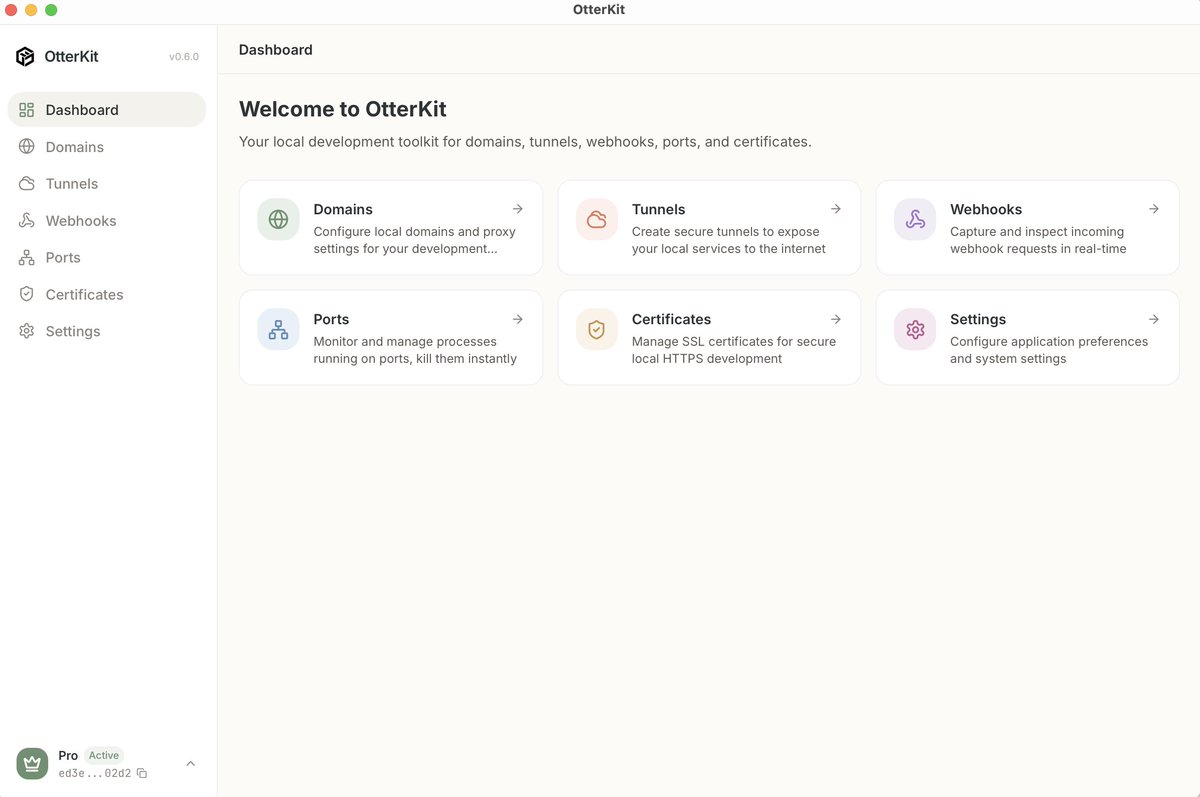
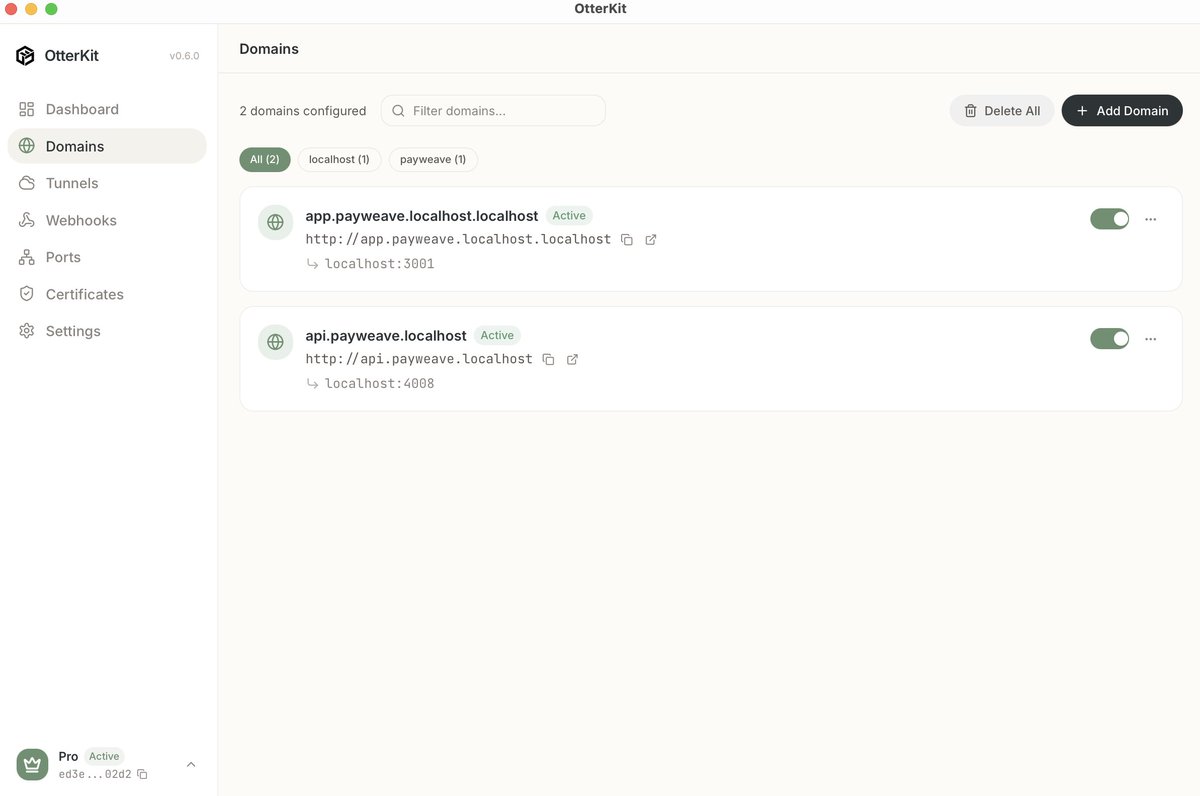
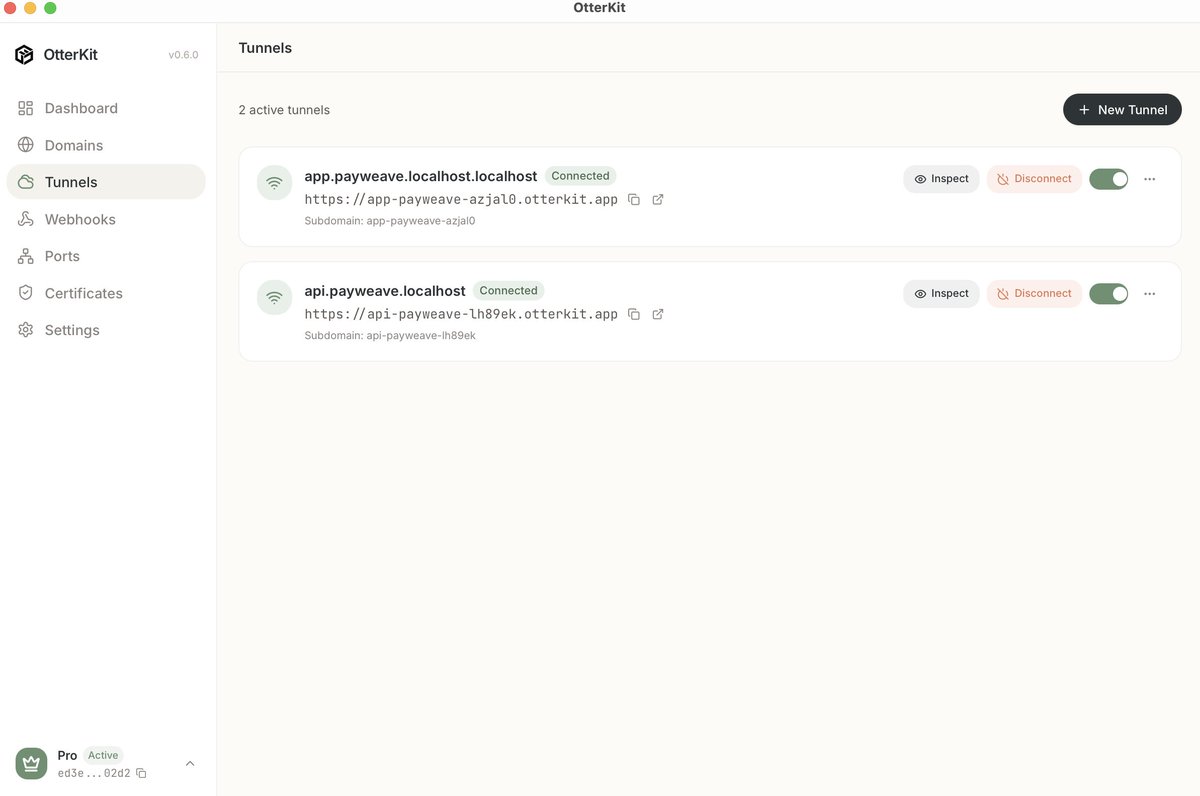
The public tunnels and webhook endpoints in OtterKit are powered by Cloudflare Durable Objects - giving every developer an isolated, stateful, edge-native connection in milliseconds. Incredible primitive to build on. 🦦⚡
@CloudflareDev @Cloudflare @threepointone
1
1
25
4,303
Mar 24
OtterKit: Unlimited local domains, tunnels, and webhooks producthunt.com/products/ott… via @producthunt
1
1
52
Shiva retweeted

14 Oct 2024
This whole town has the same energy 🤣
999
12,860
171,403
9,895,667