
The platform that allows users to access ranked responses from various LLMs. Not just multiple LLM answers. We rank them for you, instantly. Home to #AutoBench
Joined June 2025
- Tweets 51
- Following 31
- Followers 61
- Likes 67
3 Photos and videos
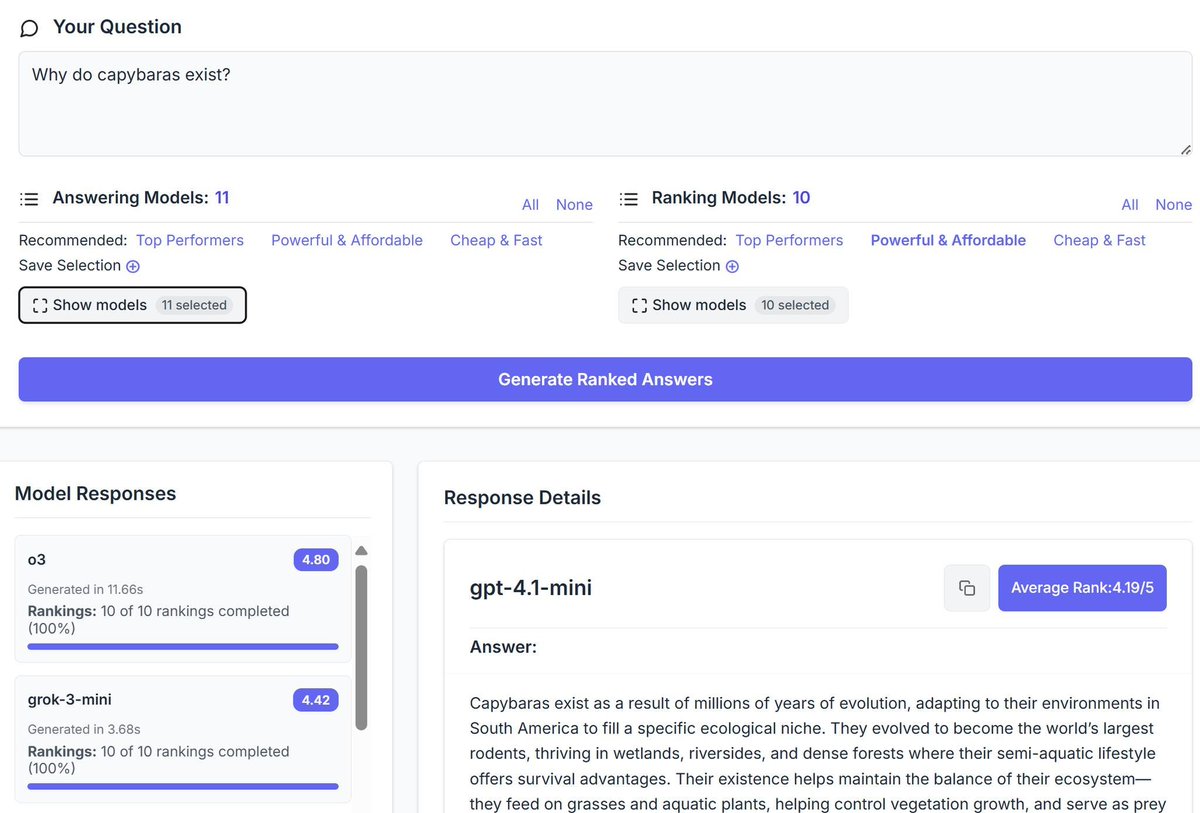


Feb 12
Smart AI powered LLM routing is the next frontier.
Stay tuned...
Feb 12

Just a quick note on @openclaw after having built 11 agents in 2 multi-agent instances: Julia heads an accounting team of 5, together with Kate (reader), Fulvia (editor), Sophia (analyst), and Flavia (tester); Juno heads an executive staff of 6, together with Venus (comms), Minerva (analyst), Flora (editor), Diana (organizer), Vesta (Q&A). (the 2 teams have just started cooperating via their leaders).
These agents are really amazing, but it can cost a lot of $ to get them working properly. Development, operations, and maintenance will dry your premium token budget very fast if you rely on SOTA models (and you don't want to default to budget models, because it takes one wrong call to f.up hard).
Here is the key takeaway: smart LLM routing will become increasingly necessary to route the optimal model for each call, with the potential of saving up to 90% (that's because 90% of calls don't require SOTA).
Tools like @clawrouter do a decent job, but they use hardcoded rules to route LLM calls. We need smarter light weight AI routers to do the job. This is what platforms like @BotScanner_AI and #AutoBench can help with. And we're working on it.
Stay tuned...
51
Feb 8
Because we are done trusting black-box leaderboards over the community.\n\nHugging Face just launched Community Evals — decentralized, transparent evaluation that anyone can verify.\n\nThis is exactly why AutoBench exists.\n\nUn-gameable benchmarks. Open methodology. Real correlation.\n\nThe benchmark gaming era is over.\n\n👉 autobench.org
26
Feb 8
Because we are done trusting black-box leaderboards over the community.\n\nHugging Face just launched Community Evals — decentralized, transparent evaluation that anyone can verify.\n\nThis is exactly why AutoBench exists.\n\nUn-gameable benchmarks. Open methodology. Real correlation.\n\nThe benchmark gaming era is over.\n\n👉 autobench.org
1
27
Feb 6
🚨 Claude Opus 4.6 just dropped and the coding community is losing its mind. "God-tier refactoring" — like a professor stepping in. Proactive dead code removal. Better agentic workflows across files. Already available now on BotScanner 🐱 🎁 Follow us for invitation codes with $3 free credits! #ClaudeAI #AIbenchmarks #LLM
2
786
Feb 5
🆕 Kimi K2.5 just beat Claude Sonnet 4.5 at HALF the cost.
SOTA on benchmarks. 50% cheaper. That's not hype—that's the new reality of LLM evaluation.
When benchmarks become games, truth becomes scarce.
Where does your model actually stand?
👉 botscanner.ai
1
217
Feb 4
🚀 Don't miss the latest models on Bot Scanner!
✅ Gemini 3 Pro
✅ Claude Opus 4.5
✅ GPT 5.2
✅ Grok 4.1 Fast
✅ MiniMax M2.1
One platform. 50 models. Best answer ranked by AI.
🎁 Follow us for invitation codes with $3 free credits!
👉 botscanner.ai
1
177
Feb 4
New SWE-Bench analysis reveals a crisis in coding benchmarks:
• 32.67% of 'successful' model patches involve direct solution leakage (solutions in PR comments)
• 31.08% of passed patches have weak test cases
• Top model's real resolution rate: 3.97% not 12.47%
Static benchmarks are broken. AutoBench measures live, un-gameable performance. 2026 leaderboard: botscanner.ai 🐱
1
2
731
Feb 3
🚀 Don't miss the latest models on Bot Scanner!
✅ Gemini 3 Pro
✅ Claude Opus 4.5
✅ GPT 5.2
✅ Grok 4.1 Fast
✅ MiniMax M2.1
One platform. 50 models. Best answer ranked by AI.
🎁 Follow us for invitation codes with $3 free credits!
👉 botscanner.ai
115
Feb 3
🚀 Kimi K2.5 is live on Bot Scanner!
Moonshot AI's new flagship agentic model brings SOTA performance on agents, coding, image & video benchmarks.
• 1T parameters
• Vision text unified
• Single & multi-agent execution
🎁 Follow us for invitation codes with $3 free credits!
👉 botscanner.ai
1
42
Feb 3
🚀 Kimi K2.5 is live on Bot Scanner!
Moonshot AI's new flagship agentic model brings SOTA performance on agents, coding, image & video benchmarks.
• 1T parameters
• Vision text unified
• Single & multi-agent execution
🎁 Follow us for invitation codes with $3 free credits!
👉 botscanner.ai
32
Feb 1
🚀 Don't miss the latest models on Bot Scanner!
✅ Gemini 3 Pro
✅ Claude Opus 4.5
✅ GPT 5.2
✅ Grok 4.1 Fast
✅ MiniMax M2.1
One platform. 50 models. Best answer ranked by AI.
🎁 Follow us for invitation codes with $3 free credits!
👉 botscanner.ai
147
19 Dec 2025
We just released the first update to Run 5 of AutoBench. New models in the leaderboard: @GoogleDeepMind Gemini 3 Flash, @NVIDIAAI Nemotron 3 Nano 30B and Allen AI's Olmo 3.1 31B Think.
Enjoy
19 Dec 2025
Want to try a user-facing version of AutoBench to rank instantly LLM responses to your prompts? Try out our
@BotScanner_AI.
The platform uses AI to select the best LLM answers for each of your questions. There are still invitation codes with $3 of free credit available for those who want to test it. All you have to do is leave a comment here and follow @BotScanner_AI. We will send you the invitation code with the $3 of free credit.
5/5 end 🧵
127
17 Dec 2025
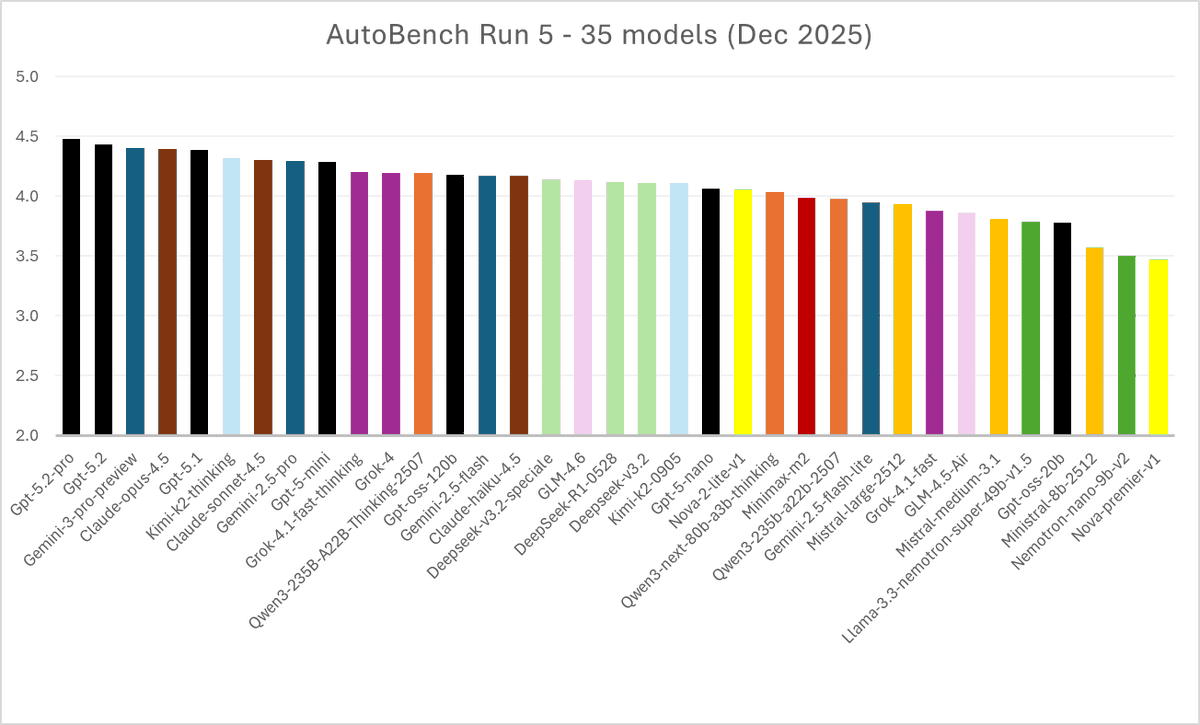
AutoBench 2.0 is out! And it comes with a bang!
Our new benchmarking system gets released along the latest and most accurante benchmark: Run5 with 35 models, including @OpenAI GPT 5.2 and GPT 5.2 Pro. How do they compare to heavy weights like @GoogleDeepMind Gemini 3 Pro and @AnthropicAI Claude Opus 4.5? All the details👇
17 Dec 2025
🎅𝐌𝐞𝐫𝐫𝐲 𝐀𝐈-𝐌𝐚𝐬 𝐟𝐫𝐨𝐦 𝐀𝐮𝐭𝐨𝐁𝐞𝐧𝐜𝐡🚀
We've got two🎄treats for you:
1. AutoBench 2.0 is LIVE! Our upgraded Collective-LLM-as-a-Judge benchmarking system is more efficient and accurate than ever.
2. Run5 is OUT. Our largest generalist benchmark ever (35 models ranked). Just in time to evaluate @OpenAI GPT 5.2!
1/8👇
105
10 Dec 2025
Breaking: AutoBench goes vertical! Proving the true super-power of our LLM benchmarking system (extreme domain flexibility and granularity), we just generated the first ever LLM benchmark for the domain of agronomy.
Medicine? Energy? Music? What other domain should we benchmark next?
10 Dec 2025
🚀Who's the best "AI farmer"? 🌽
Breaking News: AutoBench goes vertical. Introducing our FIRST domain-specific run: Agronomy Edition, in partnership with EVJA.
We benchmarked 40 LLMs on real-world farming challenges, from crop diseases to carbon footprints. The outcome? @OpenAI dominates, but the real surprise is @MistralAI.
1/10 👇
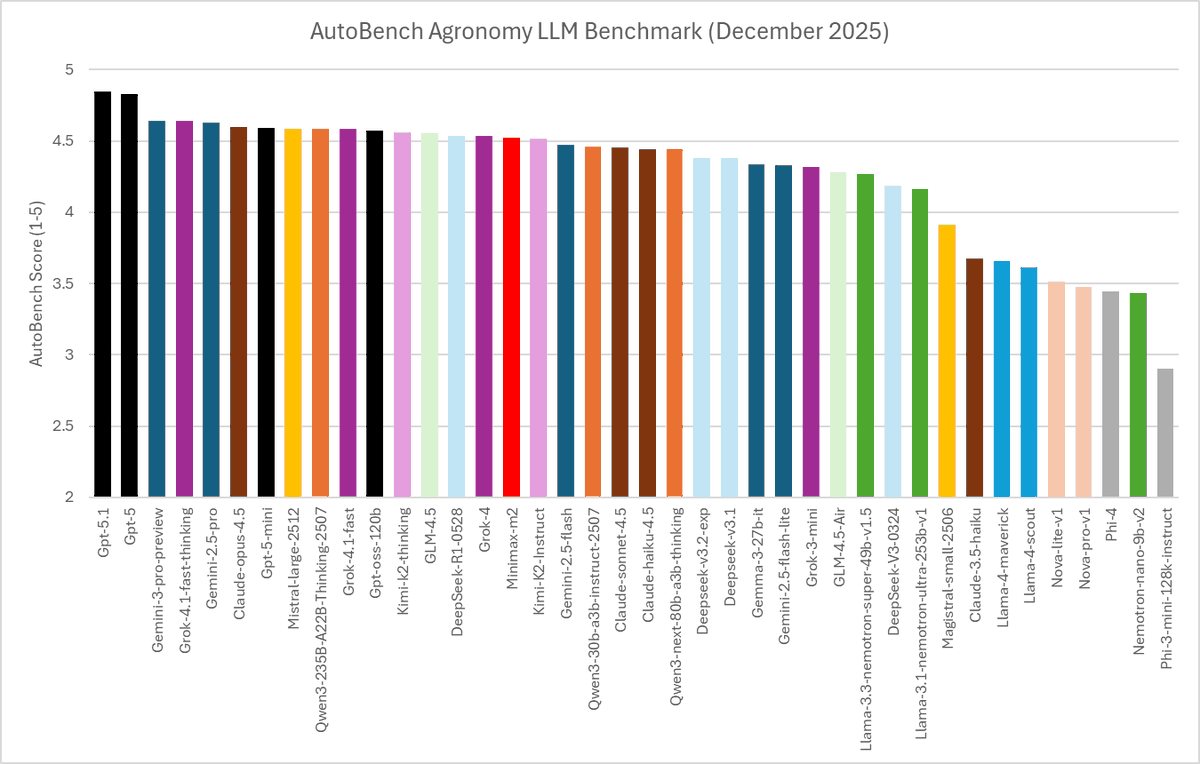
48
28 Nov 2025
Our AutoBench is out with its official 4th run. No LLM gaming with this benchmark. And the winner is not who you expect...
28 Nov 2025
🚨 AutoBench 1.0 – Run 4 is LIVE 📷
- 33 frontier models ranked (including GPT-5.1, Gemini 3 Pro, Grok 4.1, Kimi K2 Thinking, etc.)
- 21 ranking models
- 300 fresh questions generated
- 220,000 individual rankings
This is the most manipulation-resistant evaluation we’ve ever run.
And yes… the winner is NOT who most people expected.
1/13

71
29 Oct 2025
AutoBench is way more than just business. It's science!
29 Oct 2025
👩🔬AutoBench goes scientific!🎉Started 6 months ago almost as a game, then turned into business, now it's got a fancy arXiv paper to prove it's not just fun and money. Introducing the first scientific paper that validates our Collective-LLM-as-a-Judge method!🤖📜
1/12

81
20 Oct 2025
Claude 4.5 Haiku out, Claude 4.5 Haiku on Bot Scanner!
20 Oct 2025
As anticipation builds for Gemini 3 (rumored to be released by end month!), the latest big news is @AnthropicAI 's release of Claude 4.5 Haiku. 🚀
This is the new fast and "cheap" version of their 4.5 model series, following the Sonnet 4.5 release just a few weeks ago.
But let's look at the "cheap" part: While it's ~3x less expensive than Sonnet, at over $1/M input tokens, this new Haiku is actually 25% more expensive than its predecessor.
Even with new reasoning capabilities, this highlights a clear trend: proprietary models are steadily increasing their prices. This further widens the gap with high-performing open-source models (many of which are Chinese) that offer comparable results at a fraction of the cost.
Speaking of models... you can already find Claude 4.5 Haiku on Bot Scanner, right alongside all the other leading proprietary and open-source LLMs.
What? You haven't tried Bot Scanner yet? Our platform uses AI to find and select the best LLM response for your every prompt.
We still have 𝐜𝐨𝐝𝐞𝐬 𝐰𝐢𝐭𝐡 $𝟑 𝐢𝐧 𝐟𝐫𝐞𝐞 𝐜𝐫𝐞𝐝𝐢𝐭 available for new users who want to test the platform.
All you have to do is leave a comment below and follow @BotScanner_AI. We'll DM you an invite code with your $3 in free credit.
66
30 Sep 2025
Haven't tried @AnthropicAI's new Claude 4.5 model? Try and compare how it performs with other models on our platform?
Request an invitation!
30 Sep 2025
Yesterday's big AI news is the long-awaited release of Claude 4.5! After a relatively quiet summer break, we have a major update from one of the big AI labs (@AnthropicAI).
And we're expecting Gemini 3.0 to hit the road any moment.
1/6
x.com/claudeai/status/197270…
70