
Jun 11
That’s how your coach decided to autobench. Both fouls were fouls. And you can get into all the ifs, and’s and buts but it isn’t the “refs” causing the Knicks to be getting curbstomped. The Spurs have led by dbl digits all 4 games now.
93

May 26
𝗢𝗽𝗲𝗻𝗖𝗹𝗮𝘄 𝘃𝘀. 𝗖𝗹𝗮𝘂𝗱𝗲? 𝗧𝗵𝗲 𝗷𝘂𝗿𝘆 𝗶𝘀 𝗼𝘂𝘁!🏛️🥊
Last night, our 𝗚𝗿𝗮𝗻𝗱 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝗕𝗮𝘁𝘁𝗹𝗲 𝗠𝗲𝗲𝘁𝘂𝗽 issued the verdict with over 400 votes cast in the room and via the live stream. Participants judged 5 live, zero-BS demos across three ruthless metrics: 𝘾𝙤𝙤𝙡𝙣𝙚𝙨𝙨, 𝙀𝙛𝙛𝙚𝙘𝙩𝙞𝙫𝙚𝙣𝙚𝙨𝙨, and 𝙀𝙛𝙛𝙞𝙘𝙞𝙚𝙣𝙘𝙮.
Here is the definitive verdict:
🏆 THE FRAMEWORK CHAMPION: @openclaw Team OpenClaw took the crown with an overall average of 𝟯.𝟲𝟯, defeating closely @claudeai 𝟯.𝟮𝟱.
OpenClaw didn't just win the grand total. It swept every single category:
• 𝘾𝙤𝙤𝙡𝙣𝙚𝙨𝙨: OpenClaw 3.72 vs. Claude 3.09 ( 0.63)
• 𝙀𝙛𝙛𝙚𝙘𝙩𝙞𝙫𝙚𝙣𝙚𝙨𝙨: OpenClaw 3.57 vs. Claude 3.42 ( 0.15)
• 𝙀𝙛𝙛𝙞𝙘𝙞𝙚𝙣𝙘𝙮: OpenClaw 3.61 vs. Claude 3.25 ( 0.36)
While Claude proved it is highly effective, the developer community clearly favors the infinite scaffolding, adaptability, and true sovereignty of OpenClaw when it comes to building real agentic architecture.
𝗧𝗛𝗘 𝗨𝗦𝗘 𝗖𝗔𝗦𝗘 𝗖𝗛𝗔𝗠𝗣𝗜𝗢𝗡𝗦 Massive respect to the individual builders who stepped into the arena:
🥇 1st Place (score: 4.01): @lucaronin and 𝗧𝗼𝗹𝗮𝗿𝗶𝗮 (OpenClaw) absolutely dominated the board with his record breaking agentic knowledgebase system and automated Open Source Review/ticket Management application.
🥈 2nd Place: Marco Paga and Pecus 𝗖𝗵𝗮𝗶𝗻 (Claude) put up an incredible fight for second place with their agentic animal husbandry management platform.
🥉 3rd Place: 𝗔𝗱𝗮𝗺 𝗔𝘇𝘇𝗮𝗺 and 𝗠𝗮𝘇𝘇𝗮 𝗛𝗤 (OpenClaw) secured the podium showcasing his amazing agentic infra spanning 150 subagents. A huge thank you to everyone who showed up to vote.
Shoutout to my co-hosts @margal96 and @RMagnifico, and to the partners who made this battle possible: @urbeEth, @AISalonAI Rome, #AutoBench, @moveaxlab, @RomaStartup, and @binariof (@Meta).
The era of the chatbot is over. The era of agents has just begun. Let’s keep building!
@GCarnovale @marcotrombetti @matteofago @rstagi_ @MGVitagliano @FutureDies @tensorqt @lukaszkaiser




12
8
72
25,031

Built Agent Pilot AutoBench 🚀
Open-source benchmark for finding the best local LLM “pilot” for agents.
Tests: coding, tool use, reasoning, context falloff, tokens/sec, KV cache quants.
Contributors wanted:
github.com/psychofanPLAYS/ag…
#LocalLLM #AIAgents #OpenSource #AI #LLama
3
3
196
If you end up running it locally, im building an open source tool to help us benchmark the best LLM (pilot) for agentic harness’ Built Agent Pilot AutoBench 🚀
Open-source benchmark for finding the best local LLM “pilot” for agents.
Contributors wanted:
github.com/psychofanPLAYS/ag…
2
1
3
56
May 18
🚨LAST CALL. DROP YOUR USE CASE TODAY BY MIDNIGHT!🚨
Today is the final day to submit your use case for The Great @openclaw vs. @claudeai Battle that will be held on May 25 at @BinarioF by @Meta .
If you are building real AI agents and have a workflow that actually delivers, stop overthinking it and drop it in the ring. We are locking in the final 6 contenders tonight: 3 for OpenClaw, 3 for Claude.
Remember the rules: Zero BS. No pitch decks. Just live execution.
It’s time to prove which framework actually executes best in the real world.
🔗 Submit your use case before midnight (link in next comment).
Don't have use case to submit but want to see what's cutting edge in agentic development? The venue is filling up fast! Link to register in the first comment.
See you at Binario F on May 25 alongside @urbeEth, @TheAISalon Rome, #AutoBench, @RomaStartup , and our sponsor @moveaxlab. Let the battle begin!

2
5
546
Apr 20
We believe that the era of static, gameable AI evaluation is over. 𝗔𝘂𝘁𝗼𝗕𝗲𝗻𝗰𝗵 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 is a true generational leap in agentic benchmarking. Agents and enterprises need real-time, dynamic intelligence to deploy agents without flying blind.
AI friends and leaders, what's your take on dynamic Agentic Virtual Environments? @marcotrombetti @lukaszkaiser @rstagi_ @margal96 @FutureDies @tensorqt @OriolVinyalsML @GCarnovale @aserra___ @barbaracarfagna @MGVitagliano @cristian @LivePaola
9/10
2
1
4
354
Apr 20
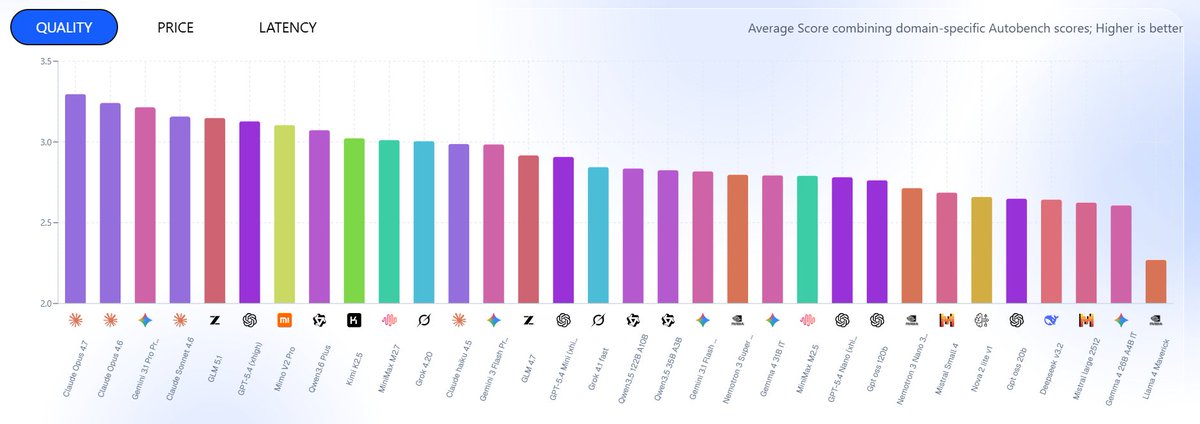
The Top 5 & The "Saturation Myth" 📉
1️⃣ Claude-opus-4.7 (Score: 3.29)
2️⃣ Claude-opus-4.6 (Score: 3.24)
3️⃣ Gemini-3.1-pro-preview (Score: 3.21)
4️⃣ Claude-sonnet-4.6 (Score: 3.16)
5️⃣ GLM-5.1 (Score: 3.15)
Standard agentic benchmarks show models scoring 90% , giving the illusion of mastery. 𝗔𝘂𝘁𝗼𝗕𝗲𝗻𝗰𝗵 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 shatters this.
2/10
1
1
221
Apr 20
Who is the true LLM King of 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗔𝗜? 👑
Today we announce a major breakthrough in agentic benchmarking: The first 𝗔𝘂𝘁𝗼𝗕𝗲𝗻𝗰𝗵 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 Run is LIVE (with LLM-generated agentic virtual environments).
See how @AnthropicAI’s Claude 4.7, @GoogleCloud’s Gemini 3.1 Pro, @openAi's Gpt-5.4, and open-weight beasts like @Zai_org's GLM-5.1 stack up in real-world enterprise workflows.
We tested 30 top models across 100s of complex agentic tasks (from parallel calls to adaptive replanning).
No static workflows. No gameable tests. Just pure orchestration under pressure.
👇1/10
2
3
13
3,580


Mar 21
The younger generation of coaches seemingly more likely NOT to autobench key players with two fools
Better late than never
Mar 21

Cam Boozer picks up a flagrant foul for bloodying David Punch's nose, then a common foul in short order and now Duke's superstar has two with 3 1/2 minutes to go in the first half. Scheyer leaving him in.
6
2,281

Both Morez Johnson Jr. and Aday Mara have two fouls, but don't think you can autobench the rest of this half.
And on cue, Mara is about to check in.
1
1
25
2,864

Mar 7
If I was a coach I would autobench any player that twirls their finger asking for a review at any point in the game other than the last minute. It's a plague that has to stop.
9
75
4,889

Feb 4
New SWE-Bench analysis reveals a crisis in coding benchmarks:
• 32.67% of 'successful' model patches involve direct solution leakage (solutions in PR comments)
• 31.08% of passed patches have weak test cases
• Top model's real resolution rate: 3.97% not 12.47%
Static benchmarks are broken. AutoBench measures live, un-gameable performance. 2026 leaderboard: botscanner.ai 🐱
1
2
731

Jan 10
I’m going to talk about LJ being terrible. Elliot autobench and LJ being horrendous was the game. Michigan has been good enough all year for none of the other stuff to matter and still almost was today. It took and absolute egg from him and Trey to lose by 3.
7
182

19 Dec 2025
Want to try a user-facing version of AutoBench to rank instantly LLM responses to your prompts? Try out our
@BotScanner_AI.
The platform uses AI to select the best LLM answers for each of your questions. There are still invitation codes with $3 of free credit available for those who want to test it. All you have to do is leave a comment here and follow @BotScanner_AI. We will send you the invitation code with the $3 of free credit.
5/5 end 🧵
4
1
566
19 Dec 2025
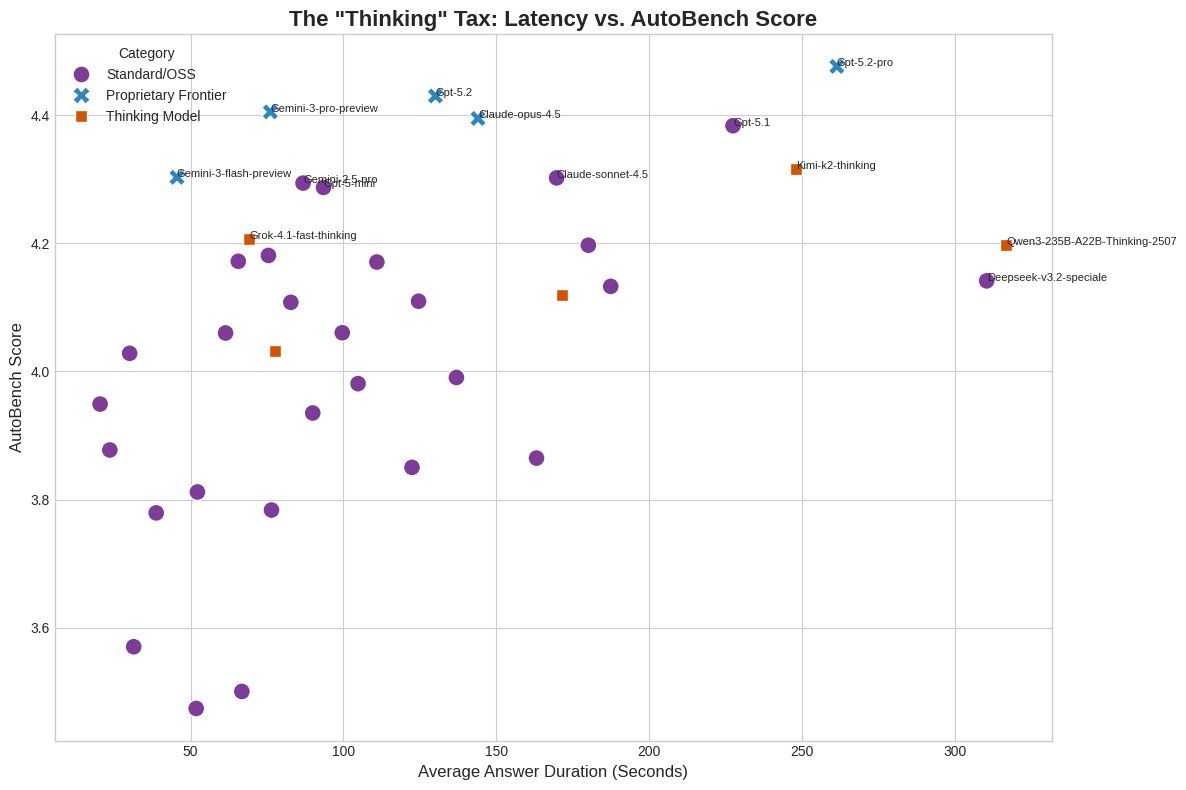
Wanna know what's really special of @GoogleDeepMind #Gemini 3 Flash? Quality is great (#7 in global ranking), but speed is where the model really shines. it is the only top 10 model that returns answers in under 50 seconds on average (please consider that for models to answer AutoBench questions it can be really hard).
2/5
1
1
130
19 Dec 2025
Did you already try Gemini 3 Flash? ⚡️
🚨AUTOBENCH UPDATE! 🚨
Well, the new @GoogleDeepMind model dropped less than 48h ago and you can already find it ranked on #AutoBench, alongside 2 other very interesting models: @NVIDIAAI #Nemotron 3 Nano 30B and @allen_ai Olmo 3.1 31B Think.
This is one of the really powerful features of our new 2.0 version of AutoBench. As new models are released, we can update existing benchmark runs with the newcomers (new models will be submitted with the same questions and evaluated by the same rankers as per the original run).
1/5

1
1
5
901
17 Dec 2025
🙏 Huge Thanks to @Translation & @marcotrombetti for compute/support; DIAG/@SapienzaRoma (Prof.@fabreetseo) for validation; the eZecute team for industrialization.
AutoBench is open for all: Submit models, run custom evals, optimize your stack.
Enterprise? We help with private benchmarks & monitoring. Reach out via autobench.org/contact.
Let's evolve LLM eval together!
8/8 end 🧵
2
1
3
521
17 Dec 2025
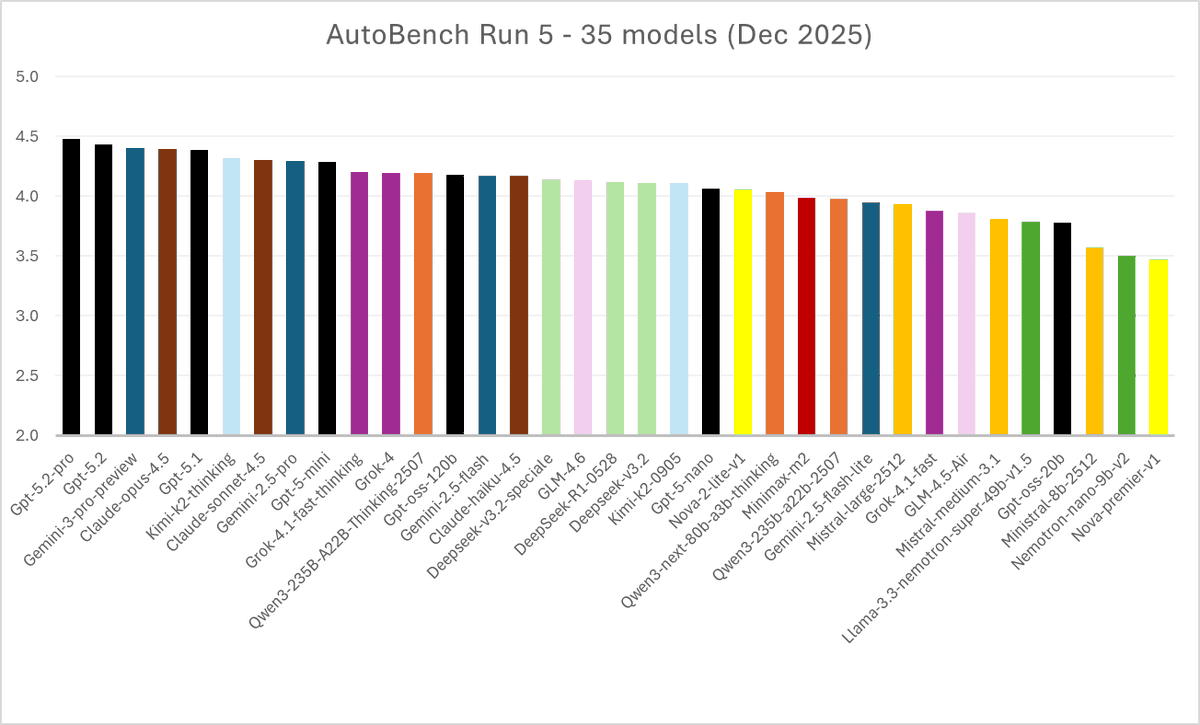
🎅𝐌𝐞𝐫𝐫𝐲 𝐀𝐈-𝐌𝐚𝐬 𝐟𝐫𝐨𝐦 𝐀𝐮𝐭𝐨𝐁𝐞𝐧𝐜𝐡🚀
We've got two🎄treats for you:
1. AutoBench 2.0 is LIVE! Our upgraded Collective-LLM-as-a-Judge benchmarking system is more efficient and accurate than ever.
2. Run5 is OUT. Our largest generalist benchmark ever (35 models ranked). Just in time to evaluate @OpenAI GPT 5.2!
1/8👇
1
5
1,035