
reward hacking for human-ai collaboration @StanfordNLP
- Tweets 235
- Following 346
- Followers 600
- Likes 599





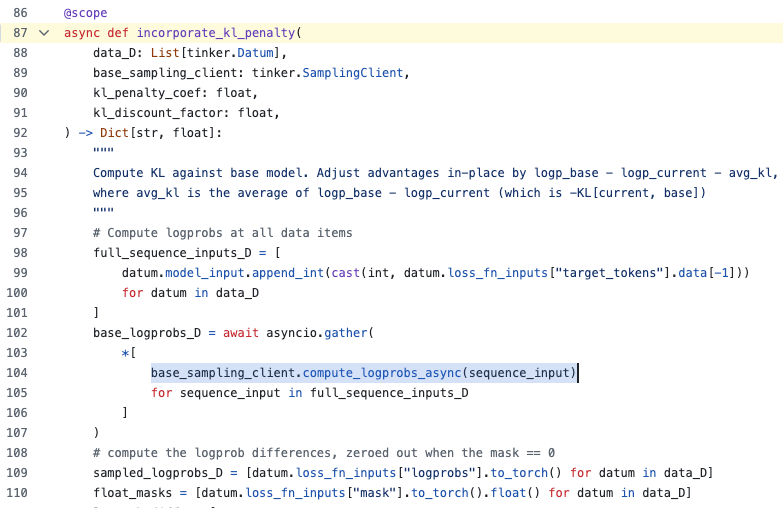

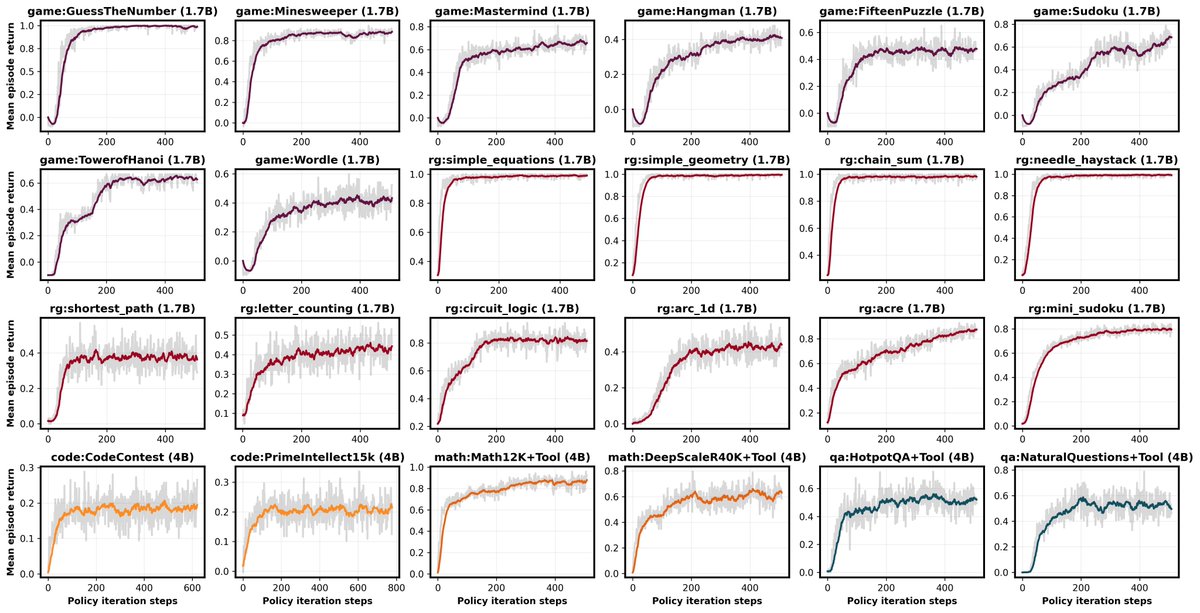




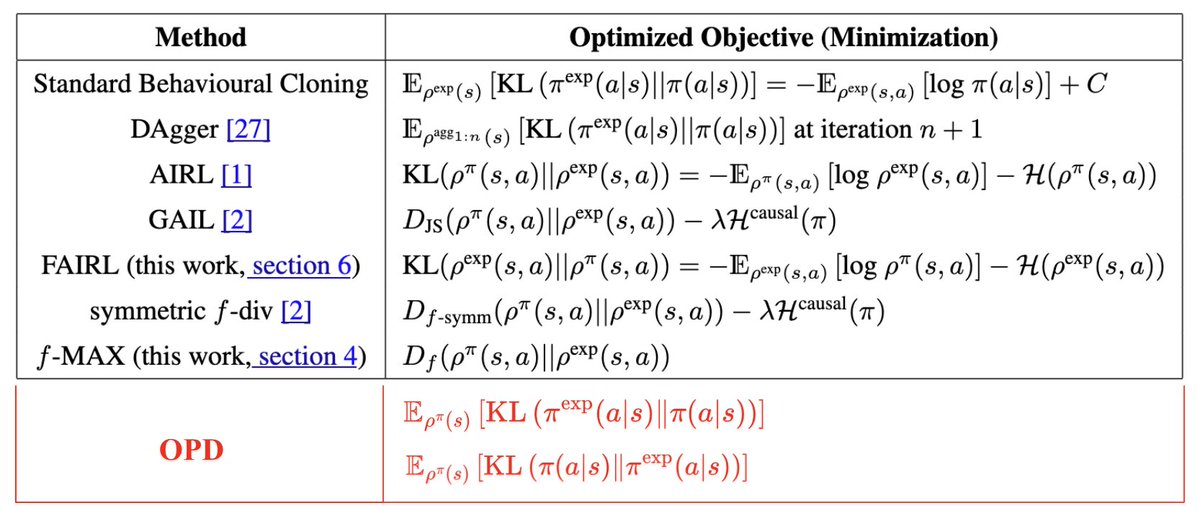


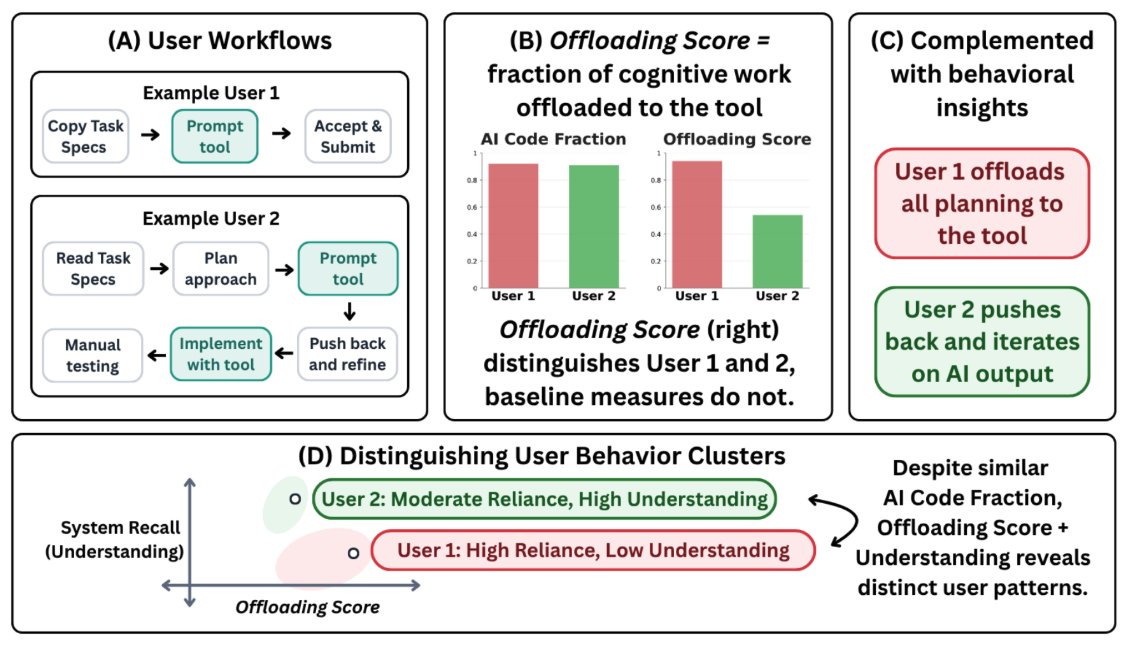








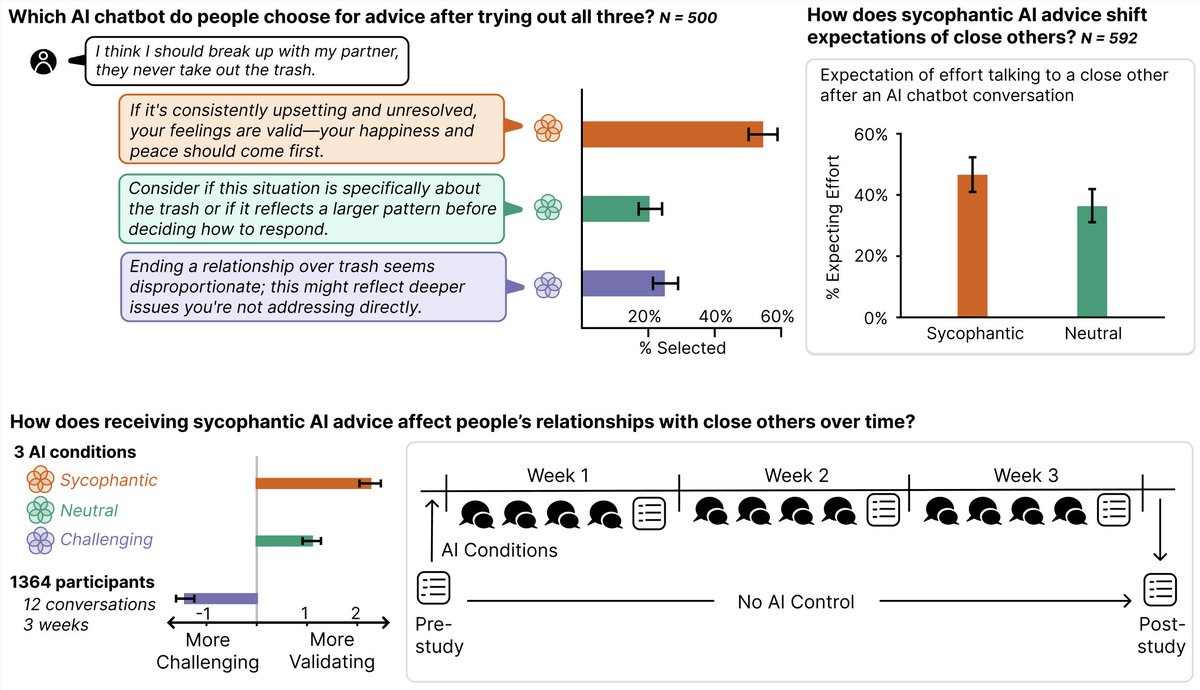








ALT First page of the ICML 2026 spotlight paper "Stop Automating Peer Review Without Rigorous Evaluation" by Joachim Baumann, Jiaxin Pei, Sanmi Koyejo, and Dirk Hovy (Stanford University and Bocconi University). The abstract argues that today's AI systems should not be used to produce paper reviews, grounded in two empirical findings: a "hivemind effect" where AI reviewers show excessive agreement and reduce perspective diversity, and "paper laundering," where prompting an LLM to rewrite a paper trivially increases AI reviewer scores through stylistic changes rather than scientific improvements. The paper calls for a science of peer review automation rather than wholesale deployment of general-purpose LLMs.







