
Cofounder and CTO of Tobiko Data. Building SQLMesh and SQLGlot.
Joined December 2013
- Tweets 1,779
- Following 362
- Followers 2,133
- Likes 4,132
260 Photos and videos





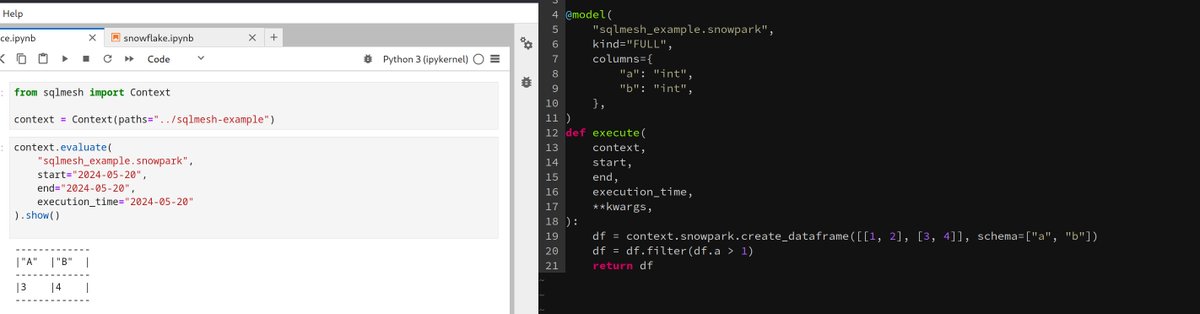








“Pure Python” and “fast” don’t usually go together.
We used mypyc to speed up SQLGlot by up to 5x without rewriting it in Rust or changing the codebase.
This post breaks down how we squeezed as much performance from a large Python project as possible: 5tran.co/3OYg7AP

2
4
244
Toby Mao retweeted

31 Oct 2024
This week’s episode of @drilltodetail features @Captaintobs from @TobikoData on @Airbnb, #DataOps and the engineering innovation behind @SQLMesh
3
4
1,454

25 Oct 2024
Exciting new feature for @SQLMesh. Custom signals / triggers.
SQLMesh's built-in scheduler controls which models are evaluated when the sqlmesh run command is executed.
It determines whether to evaluate a model based on whether the model's cron has elapsed since the previous evaluation. For example, if a model's cron was @daily, the scheduler would evaluate the model if its last evaluation occurred on any day before today.
Unfortunately, the world does not always accommodate our data system's schedules. Data may land in our system after downstream daily models already ran. The scheduler did its job correctly, but today's late data will not be processed until tomorrow's scheduled run.
You can now use signals to prevent this problem!
Just write a function in Python to determine which intervals are ready to be processed.
sqlmesh.readthedocs.io/en/la…
1
4
27
2,041
Toby Mao retweeted

23 Oct 2024
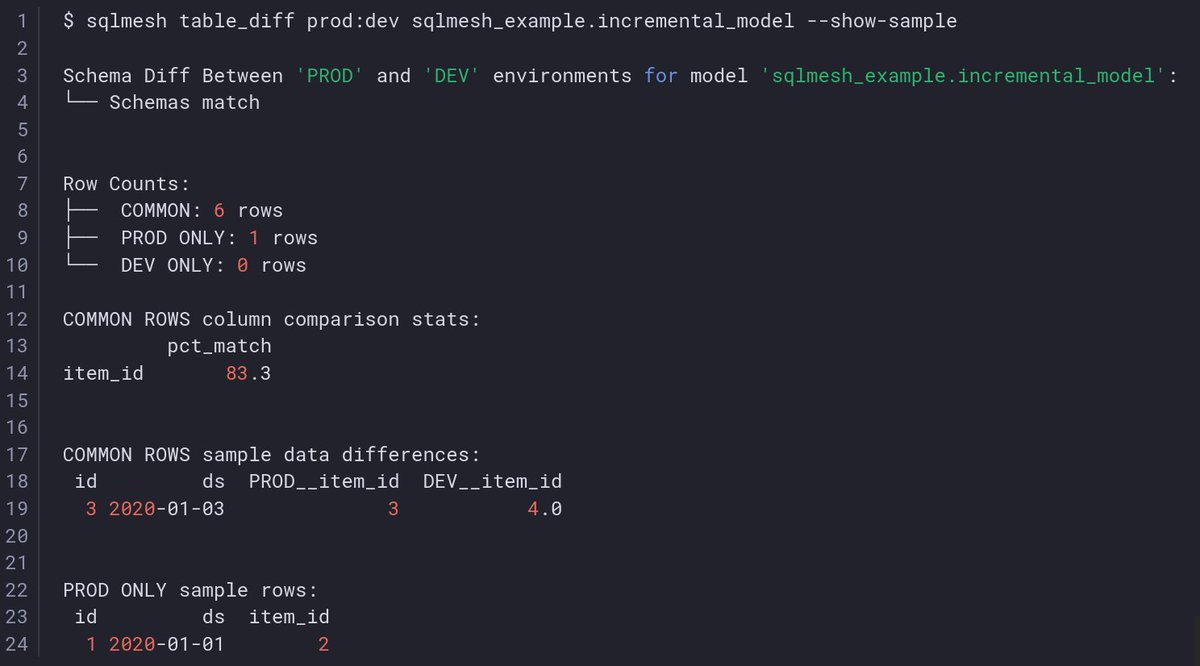
SQLMesh concepts with plans that apply to different environments (prod, dev) are elegant. Even `fetchdf` is integrated into the CLI.
Also, on the right, you see SQLMesh auto-detecting the new columns as non-breaking and simply applying the (virtual) changes `y`.
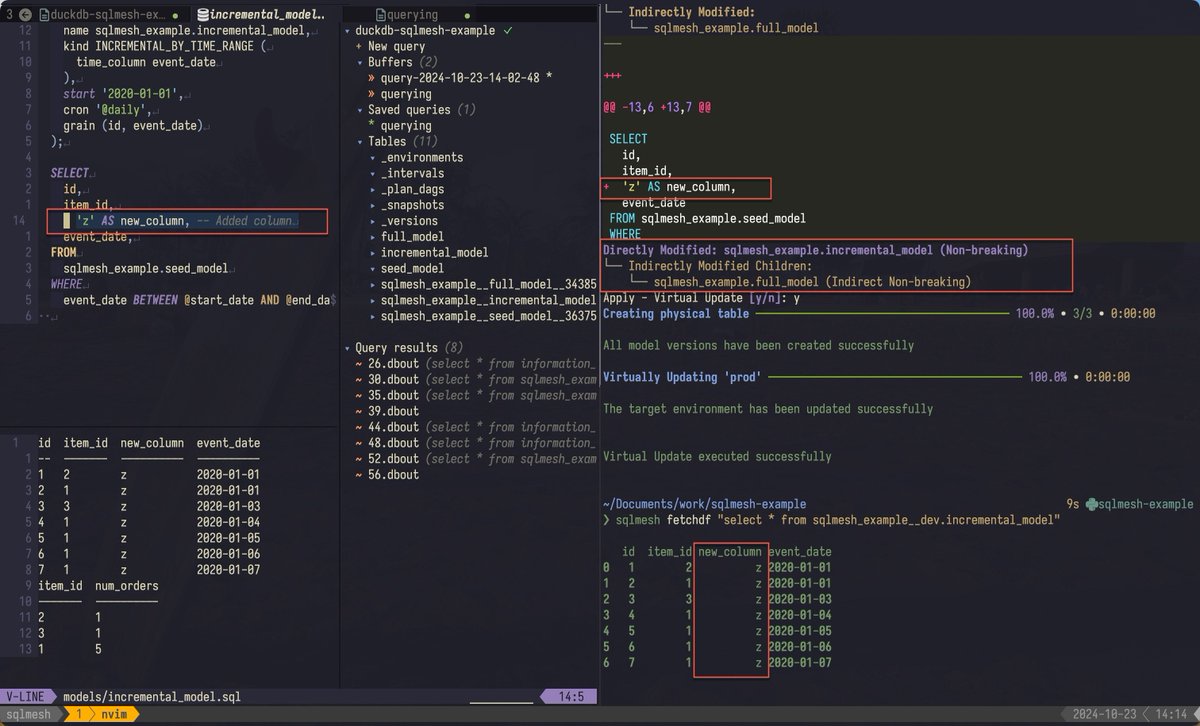
ALT Playing around with SQLMesh.
7
57
3,407
Toby Mao retweeted

22 Oct 2024
It surprises me how most poorly most data orchestrators support batch size for backfills
Meanwhile, @SQLMesh open source supports out of the box

4 Oct 2024

Simplifying our data stack
i.e. killing Airflow
4
1
45
6,682
15 Oct 2024
⚠️⚠️Read this before you start using dbt's microbatch models. There are three large gaps that could lead to serious data issues.
Due to fundamental architectural design choices of dbt, the microbatch implementation is very limited. At its core, dbt is a stateless scripting tool with no concept of time, meaning it is the user's responsibility to figure out what data needs to be processed.
1. dbt's microbatch can lead to silent data gaps
2. dbt's lack of scheduling requires manual orchestration which could lead to incomplete and incorrect data
3. Mixed time granularities in microbatch can cause incomplete data and wasted compute
tobikodata.com/dbt-increment…
1
7
43
4,032
Toby Mao retweeted

10 Oct 2024
Tired of messy data pipelines? 🥹🫣
Check out the @SQLMesh @dltHub integration for seamless metadata handovers, faster scaffolding, and incremental processing. 💻
Simplify your data workflows! 🔗
tobikodata.com/integrated-da…
#DataEngineering #DataPipelines

1
4
13
1,110
4 Oct 2024
If you're gonna be in Vegas next week hit me up. We can get coffee or hit the craps table... and talk data :)
5
612
4 Oct 2024
The wait is over! You can now use Athena with @SQLMesh. Both Iceberg and Hive are supported but we heavily recommend Iceberg since it's a way better experience.
And if you're still stuck on dbt, don't worry, we also have support for the dbt-athena adapter so you can have a seamless migration!
Like always, if you run into any issues, feel free to file an issue or let us know on Slack. We're abnormally responsive :)
sqlmesh.readthedocs.io/en/st…
1
6
46
4,657
Toby Mao retweeted

3 Oct 2024
Featuring SQLMesh on this week's episode of Open-Source Spotlight, our series where we're discovering open-source tools.
@TobikoData's Toby Mao, @Captaintobs, joined us in demonstrating how this tool can help data team workflows.
Watch the demo here: youtu.be/ASiBidAFdwM
2
9
1,232
Toby Mao retweeted
2 Oct 2024
Join @Captaintobs and @Al_Grigor from @DataTalksClub on their Open-Source Spotlight series, where they talk through the benefits of @SQLMesh like:
♦ Column-level lineage
♦ Environment Management
♦ Instant Prod deployments
and much more!
youtu.be/ASiBidAFdwM
2
7
682
22 Sep 2024
If you’re gonna be at Coalesce in Vegas, make sure to come to @TobikoData’s happy hour October 8 at 5pm!
Also if you just wanna meet up with me and grab a coffee, I’d love to chat! DM me!
cube.registration.goldcast.i…
4
610
21 Sep 2024
As a data engineer, you should consider how changes can be done in a non-breaking way.
A non-breaking change to a data model is something that won't have any down stream impact, like adding a column or re-ordering columns. Adding columns only impacts down stream models when they do SELECT * statements, which is one of the reasons why it's best practice to avoid them.
On the other hand, a breaking change will have significant impact on down stream models and usually requires expensive back-fills. An example of a breaking change is modifying a WHERE statement which changes the cardinality of a table.
If you're working at any significant scale where it's expensive and time consuming to back-fill many tables, consider whether or not a change can be done in a backwards compatible way and how expensive a breaking change would be. If it's not very expensive to make a breaking change, it can be easier to maintain since all models are kept up to date without any legacy, so there's always a trade-off.
Even if it's not too costly to back-fill many tables, it can be time consuming communicating breaking changes to stakeholders or validating all data consumers are up to date. Arguably, this is even more challenging than the technical/compute costs of breaking changes.
As a software engineer, it's commonplace to consider whether changing an API or a database model should be done in a breaking or non-breaking fashion. I believe this best practice should be adopted by data teams as well.
That's why we designed #SQLMesh to provide automatic detection of breaking and non-breaking changes by analyzing your SQL queries. This allows you to assess the impact of your changes at compile time and understand potential costs (both compute and organizational) before you finalize your changes.
tobikodata.com/automatically…
1
32
2,123
Toby Mao retweeted
4 Sep 2024
Want to learn about running your #dbt project with @SQLMesh?
Check out our latest YouTube video to run through a workflow using the classic Jaffle Shop example project!
youtube.com/watch?v=X9RA6aO-…
3
6
678
Toby Mao retweeted
29 Jul 2024
Our latest #YouTube #video is up!
#learn how to make changes to your #data #models with @SQLMesh plans!
#opensource #community #tutorial
youtu.be/BWwJTkvt_A8
1
2
6
980
13 Jul 2024
14 years since I started training #bjj, finally got to brown belt! It's been a long journey but I've never quit.
3
29
1,628
Toby Mao retweeted

8 Jul 2024
I re-ran the DDL parsing experiments, comparing sqlglot 11.4.1 to 25.5.1. Parsing success rate improved by 12.8%, and also alignment with pglast improved substantially (up to 17.5%). More details in the charts. Published the experiment code in our repo github.com/amsterdata/schema…
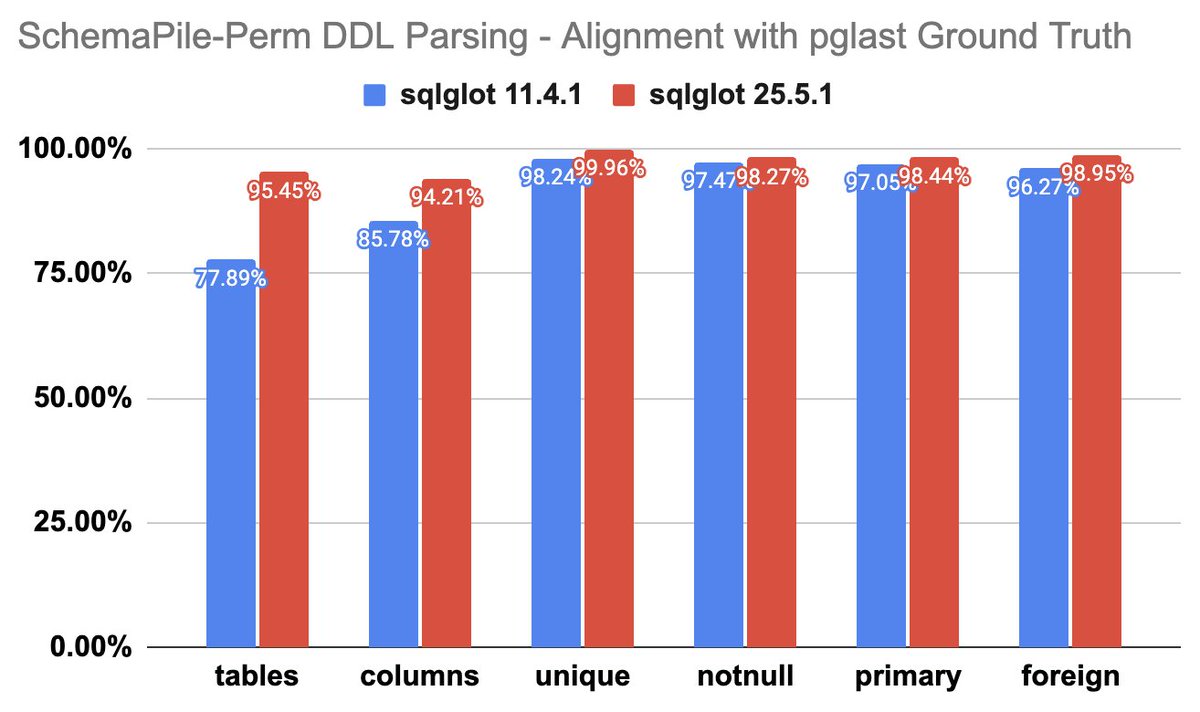
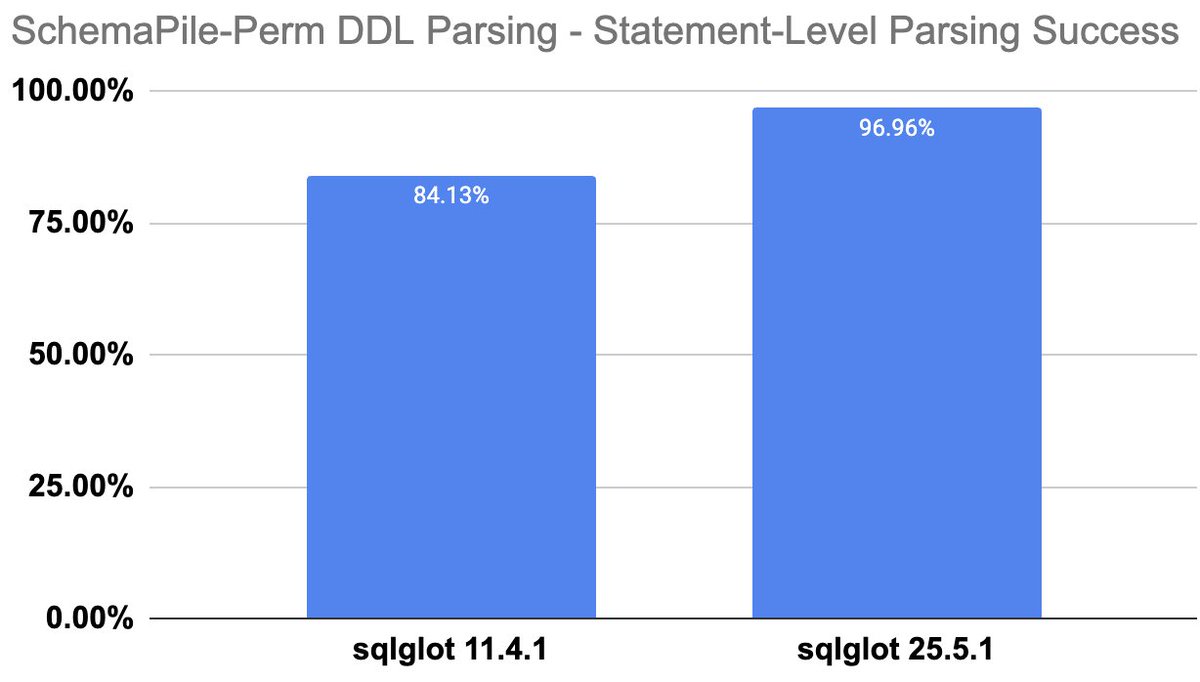
1
2
6
861
20 Jun 2024
I’m gonna be in New Jersey tomorrow for a wedding by Florham Park. Looking to eat some great pizza for lunch but don’t have anyone to go with (lots of places only serve a whole pie). Anyone wanna meet up?
4
828
Toby Mao retweeted

18 Jun 2024
Shikoku 1889 is a robust and beautifully produced game that, well, might not be for everyone? That’s probably because of all the spreadsheets, but we promise there’s a devious GAME under the hood that’s oh-so-satisfying for ‘number enjoyers’.
Link below!

4
13
155
11,946