
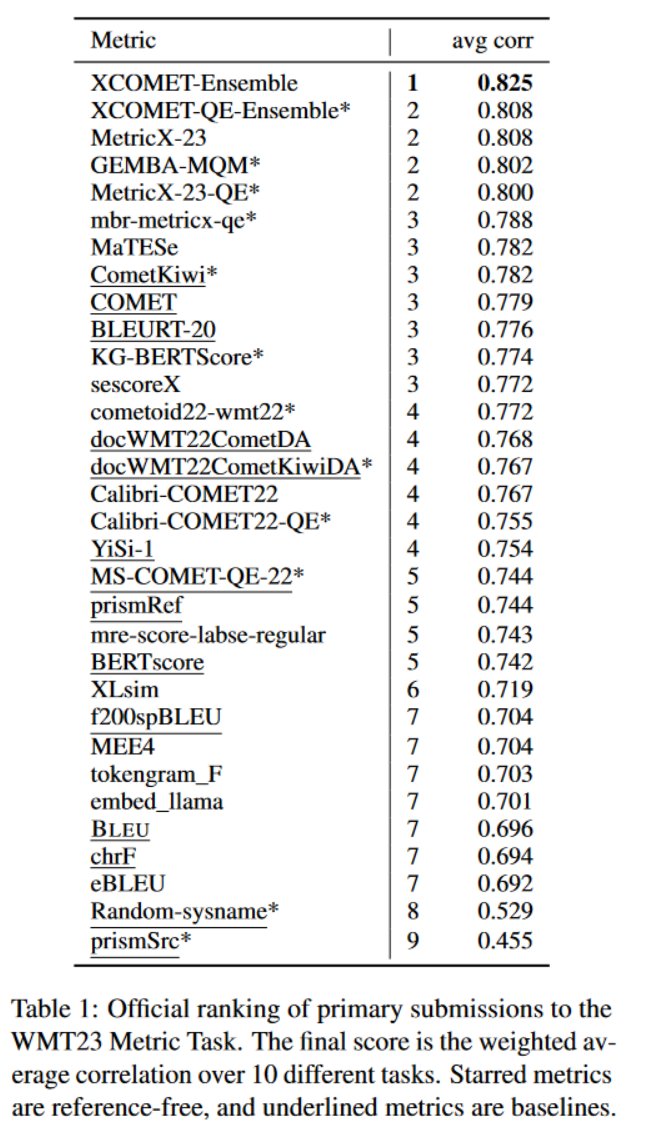
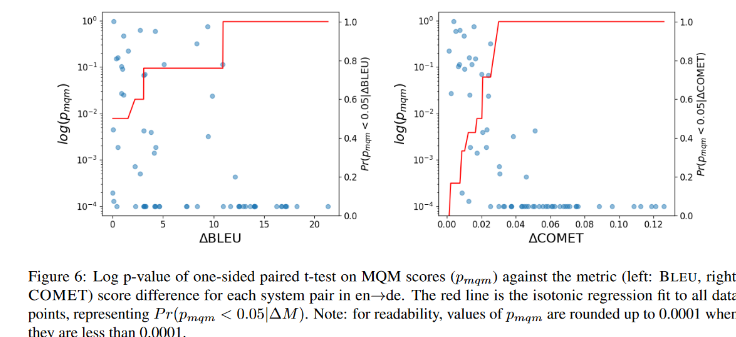
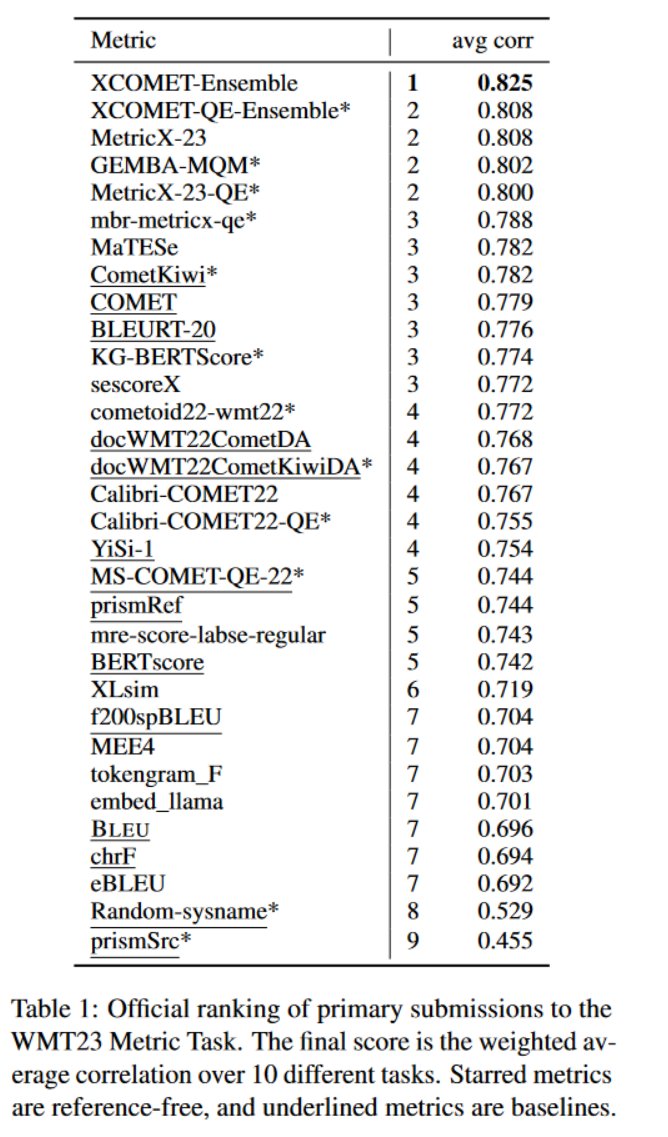
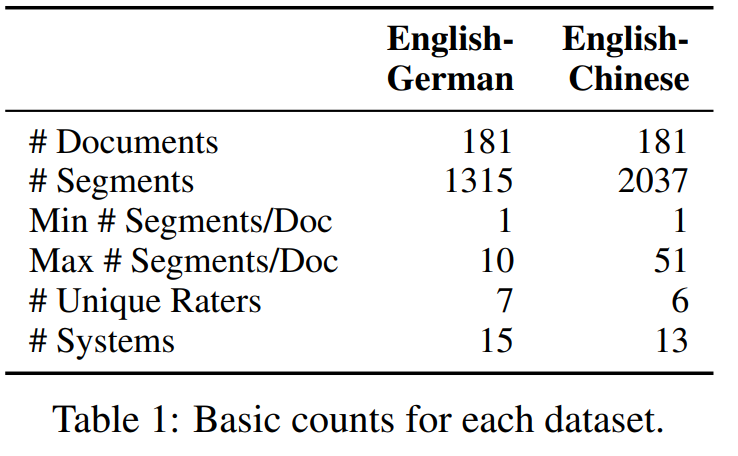
Head of Google Translate Research
Joined April 2012
- Tweets 316
- Following 211
- Followers 1,254
- Likes 1,012
28 Photos and videos





Pinned Tweet

Jan 15
This release represents a huge team effort. So proud of this team! It's a joy to work alongside such brilliant people, and I can't wait to see how the research community uses @TranslateGemma in the future!
#AI #Gemma3

🗣 Introducing TranslateGemma, our new collection of open translation models built on Gemma 3.
The model is available in 4B, 12B, and 27B parameter sizes, and furthers communication across languages, no matter what device you own. blog.google/innovation-and-a…
2
3
15
2,209
Markus Freitag retweeted

Jan 22
🎓Completed a PhD on Machine Translation, multilingual, or cross-lingual NLP?
Nominate a standout thesis (or your own!) for the AMTA Best Thesis Award. Winner gets $1000, an invited talk at #AMTA2026 & more.
🗓️ Deadline: 15 May 2026
ℹ️Info: amtaweb.org/amta-2026-first-…
#MT #NLP #PhD
4
21
2,034
Markus Freitag retweeted

Jan 15
Announcing TranslateGemma, a new collection of open translation models built on Gemma 3. Learn more 👇
TranslateGemma outperforms models twice its size, has been trained and evaluated on 55 language pairs to ensure high-quality performance, and uses a specialized two-stage fine-tuning process that distills the knowledge of Gemini models into an open architecture.

7
22
244
23,562
Markus Freitag retweeted

29 Oct 2025
Check out TowerVision, a multilingual multicultural VLM powered by the @sardine_lab_it. Great work led by @Guilherme_PT1 and @psanfernandes! Bonus: TowerVideo, kudos to @Saul_Santos1997!
29 Oct 2025

This project is the result of an amazing collaboration between researchers:
Authored by: @Guilherme_PT1 @psanfernandes @Saul_Santos1997 @SonalSannigrahi @ManosZaranis @nunonmg @amin_farajian @PierreColombo6 @gneubig @andre_t_martins
1
12
874
Markus Freitag retweeted

26 Aug 2025
Every month, people use Google to translate around 1 trillion words. Today, we’re introducing a new AI-powered live translation experience in the Google Translate app, plus a new beta feature to help you practice new languages. Rolling out now on iOS Android.
262
587
6,118
579,165
27 Jul 2025
Our Google Translate team is bringing a strong presence to #ACL2025 in Vienna this week! 🇦🇹 My group is excited to present several of our latest papers. 👇 Don't miss them!
1
5
53
3,256
27 Jul 2025
@_danieldeutsch @yixiao_song @ebriakou @caswell_isaac @marafinkels Rebecca Galor @JurikJuraska @gezakovacs Alison Lui @RicardoRei7 @jasonriesa @shrutirij @prk_riley @esalesk Firas Trabelsi Stephanie Winkler @BZhangGo @mykocyigit @ColinCherry Jiaming Luo @lilyhzhang Hamid Dadkhahi
1
3
413
Markus Freitag retweeted

16 May 2025
MT metrics excel at evaluating sentence translations, but struggle with complex texts
We introduce *TREQA* a framework to assess how translations preserve key info by using LLMs to generate & answer questions about them
arxiv.org/abs/2504.07583
(co-lead @swetaagrawal20)
1/15

2
12
38
5,345
Markus Freitag retweeted

16 Apr 2025
.@Google and @imperialcollege researchers argue that translation quality can’t be captured 🛑 by a single metric and propose evaluating #AI #translation systems 🤖 on an accuracy-naturalness plane.
#xl8 #t9n #Google @GoogleAI @markuseful
slator.com/google-calls-for-…
5
9
475
Markus Freitag retweeted

19 Feb 2025
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goog…

3
12
35
4,187
Markus Freitag retweeted

19 Feb 2025
🚨New machine translation dataset alert! 🚨We expanded the language coverage of WMT24 from 9 to 55 en->xx language pairs by collecting new reference translations for 46 languages in a dataset called WMT24
Paper: arxiv.org/abs/2502.12404v1
Data: huggingface.co/datasets/goog…

3
24
88
6,836
19 Feb 2025
Two new datasets from Google Translate targeting high and low resource languages!
WMT24 : 46 new en->xx languages to WMT24, bringing the total to 55
SMOL: 6M tokens for 115 very low-resource languages
WMT24 : huggingface.co/datasets/goog…
SMOL: huggingface.co/datasets/goog…
2
24
83
15,622
19 Feb 2025
19 Feb 2025

🚨New machine translation dataset alert! 🚨We expanded the language coverage of WMT24 from 9 to 55 en->xx language pairs by collecting new reference translations for 46 languages in a dataset called WMT24
Paper: arxiv.org/abs/2502.12404v1
Data: huggingface.co/datasets/goog…
1
1
421
19 Feb 2025
19 Feb 2025

😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goog…
258
7 Feb 2025
Highly recommend everyone to read Yusuf's work on data contanimation! He trained almost 90 models investigating how different types of contanimation affect test set scores! Very insigthful paper.
6 Feb 2025

Thrilled to share our latest findings on data contamination, from my internship at @Google! We trained almost 90 Models on 1B and 8B scales with various contamination types using machine translation as our task and analyze the impact of contamination.
arxiv.org/abs/2501.18771
1
9
633