Diving into the #DeFi ocean, one block at a time 🐠 Expert insights on #crypto & #blockchain with a splash of humor. Follow for your daily dive into DeFi!
Joined June 2011
- Tweets 1,134
- Following 324
- Followers 666
- Likes 3,615
261 Photos and videos
















Jun 2
Traditional dictation tools just make you a full-time editor for your own voice. This is how it should've worked from day one.

Stop using standard dictation. Editing transcripts wastes time. Watch me speak a messy draft, and let @usedotfo rewrite it into an email.
2
135
Daniel Chang retweeted

May 13
You can now have an AI researcher running on your laptop 24/7 for free!
Running Qwen3-35B-A3B with llama.cpp and a 4-bit quant from Unsloth
47
121
1,088
118,022

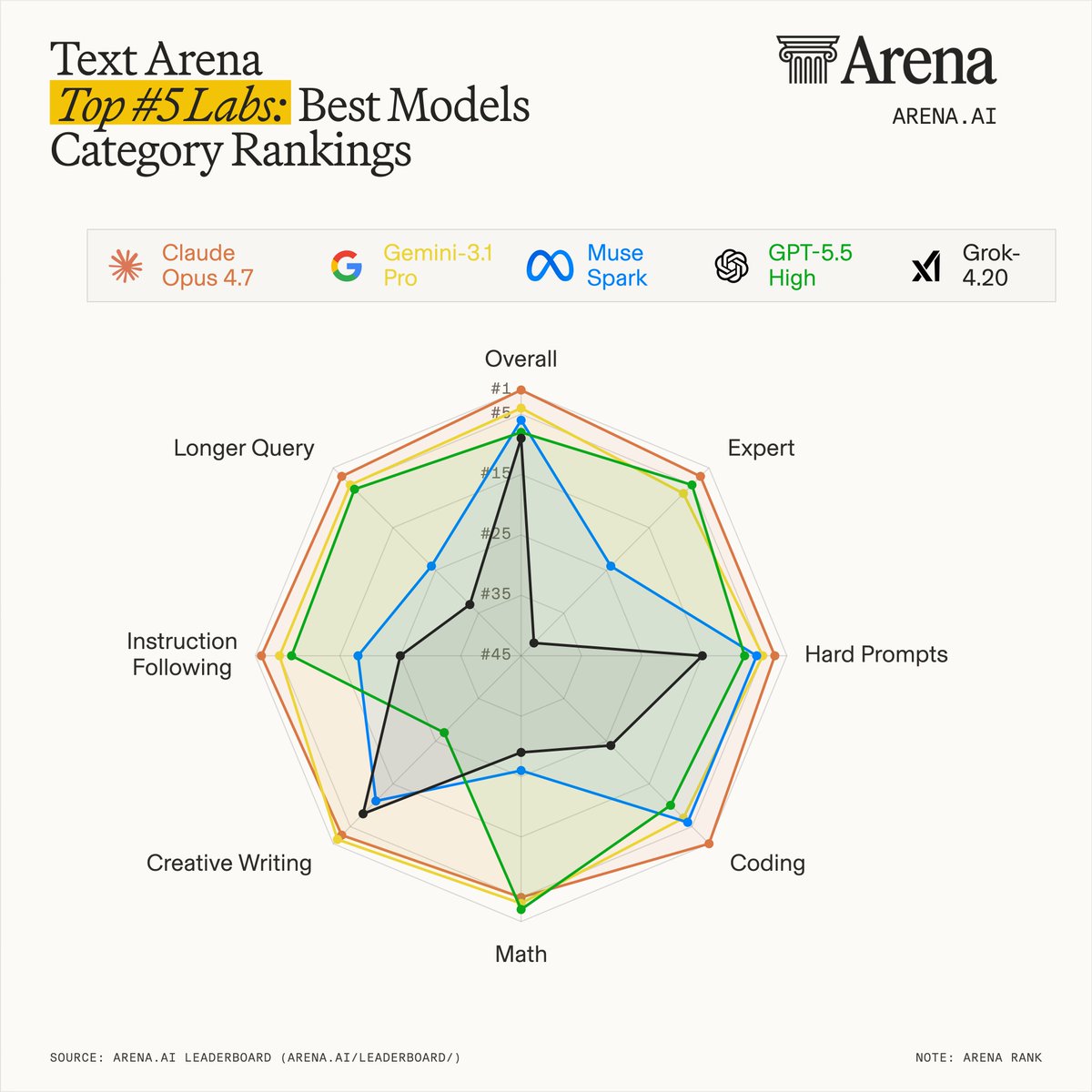
Top frontier AI labs now have very different model strengths.
🔹Claude Opus 4.7 is presented as the most consistently dominant model overall, ranking near the top across almost every major category.
🔹Gemini 3.1 Pro looks well-rounded with a creative writing edge.
🔹Muse Spark appears strong in overall performance and coding but weaker in expert, math, and long-query tasks.
🔹GPT-5.5 High is described as one of the most balanced models, especially strong in expert and math tasks.
🔹Grok 4.20 seems more specialized, standing out in creative writing and hard prompts.
No single lab owns every category, but Claude Opus 4.7 appears to be the most broadly consistent across the board.


The top 5 labs in Text Arena rankings by category show that frontier models have distinct strengths and tradeoffs.
#1 @AnthropicAI, Claude Opus 4.7
- The most consistently dominant model overall, leading top-tier across nearly every major category.
#2 @GoogleDeepMind, Gemini 3.1 Pro
- Well-rounded, with a notable edge in Creative Writing, ranked below Opus 4.7 and GPT-5.5 High in Expert
#3 @AIatMeta, Muse Spark
- Particularly strong in Overall and Coding, though it’s lagging behind in Expert tasks, Math, and Longer Query performance.
#4 @OpenAI, GPT-5.5 High
- One of the most balanced models overall, staying competitive with the top two across most categories, with especially strong performance in Expert and Math.
#5 @xAI, Grok 4.20
- A more specialized profile, standing out primarily in Creative Writing and Hard Prompts, while lagging behind in Expert tasks.
20
13
85
8,068
May 4
Seeing Codex challenge Claude Cowork is great. This competition is making both tools much more capable for our daily work.
28
Apr 14
Microsoft limiting OpenAI customer access is interesting - makes business sense for them but affects smaller devs. Curious if this pushes OpenAI toward full independence. Thoughts?
25
9 May 2025
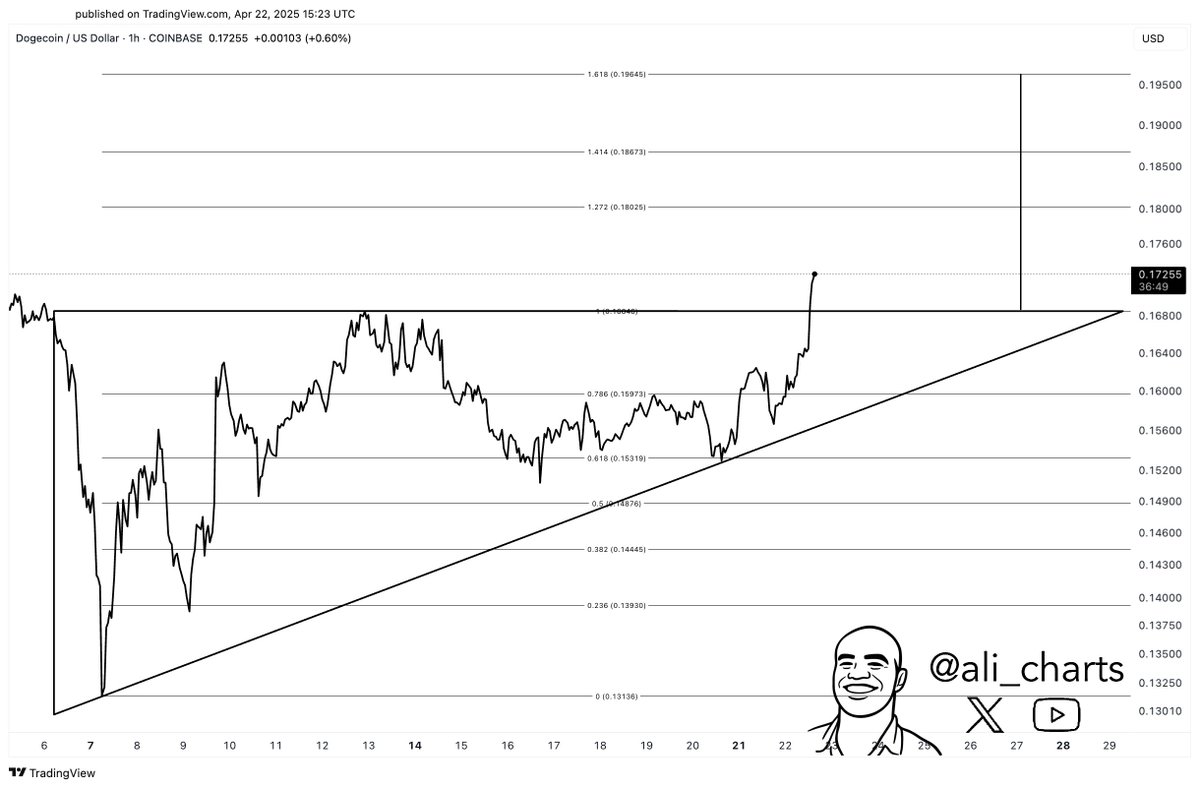
Chart showing $BTC #ToTheMoon ain't random doodles. 🤔 It's the map! Don't act? You'll 💯 regret missing this ride. What R U waiting for? 🚀 #Bitcoin #Crypto #Option #Trading
28 Apr 2025

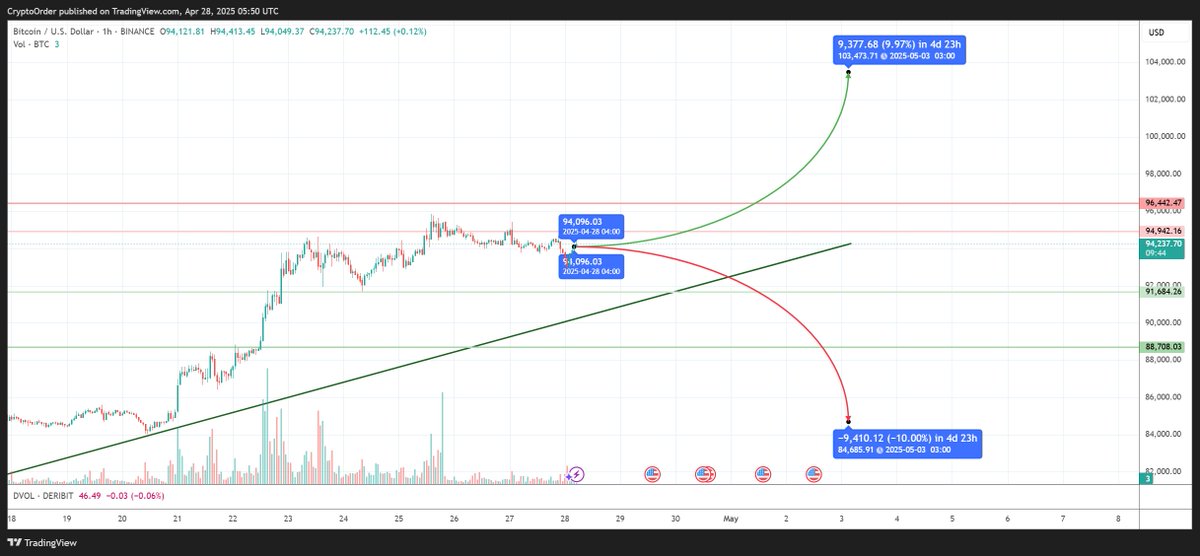
$BTC shift incoming! 👀 Sidelines = getting rekt / missed gains. Make noise or fade? What's the play? 💰 #Crypto #Bitcoin #trading
1
106

Daniel Chang retweeted

26 Apr 2025
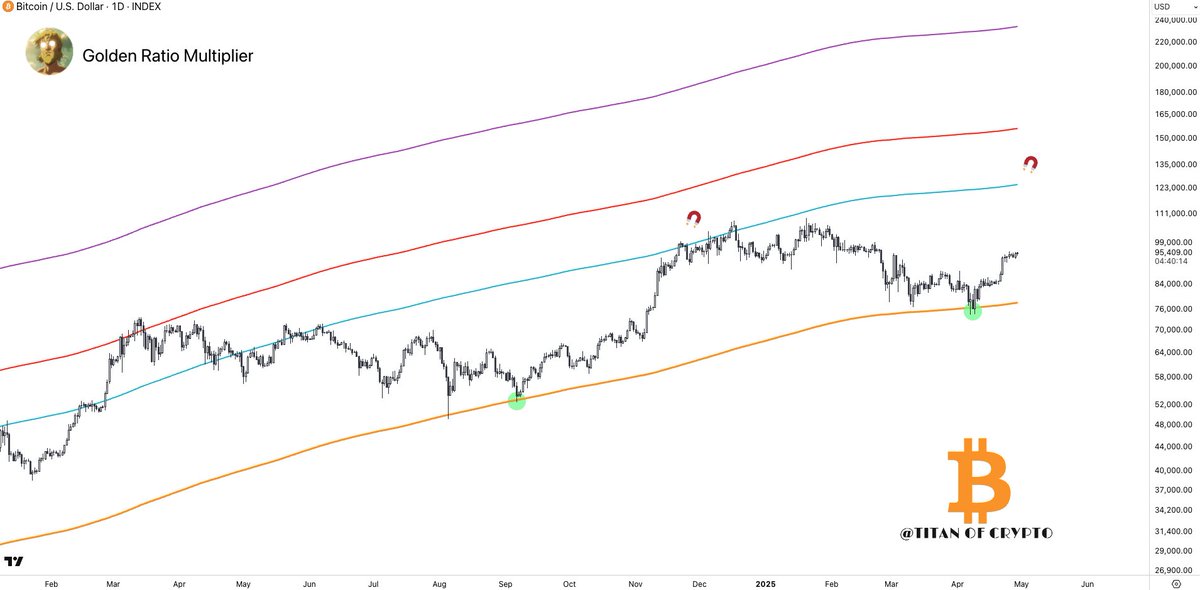
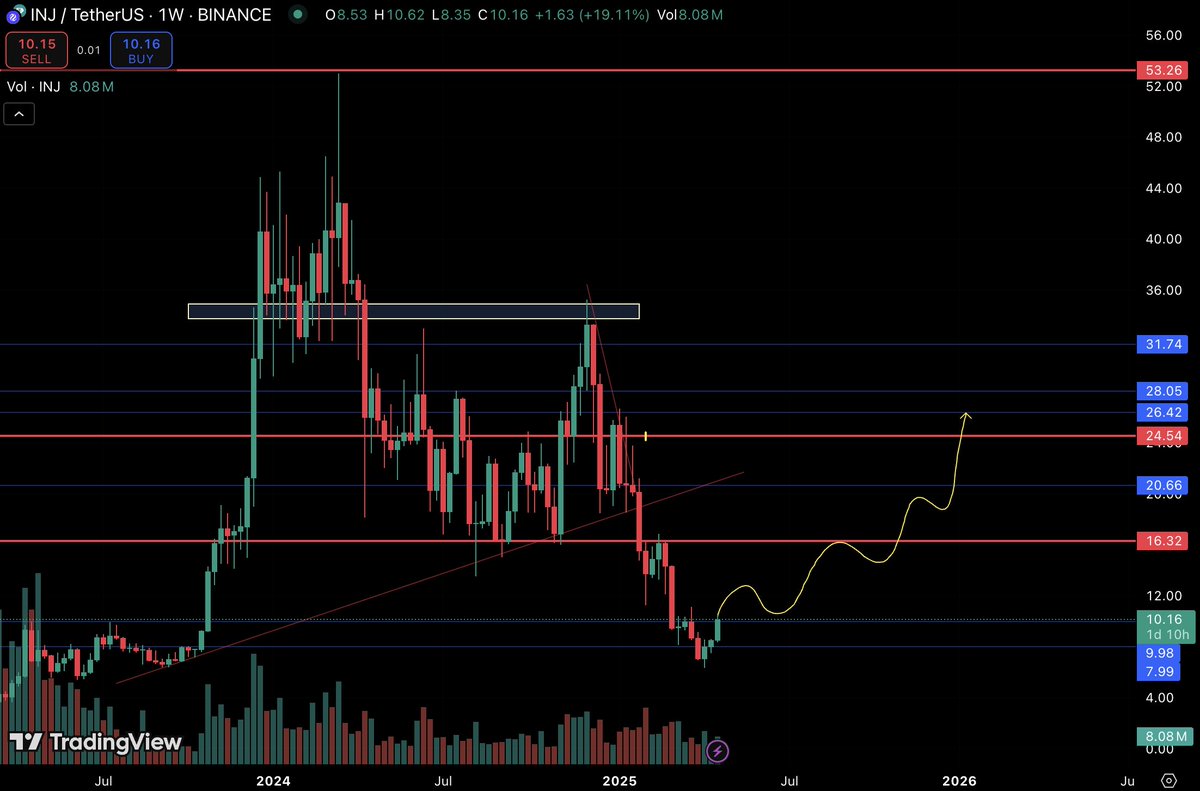
$INJ might be ready to wake up in a big way.
Chart looks primed - strong support around $8–$9 held perfectly, structure flipped bullish, and momentum is heating up fast.
Clear resistance zones at $12.5 and $16, once broken $20–$28 is wide open.
Patience here could pay big.
@injective
26 Apr 2025

Nearly 1.5 Million wallets on Injective now.
Are you one of them?
20
23
178
23,527
Daniel Chang retweeted

27 Apr 2025
Bears hate M2 charts because it goes against bearish bias, but like it or not M2 is a leading indicator for #Bitcoin with an 83% directional correlation.
Facts are facts. That doesn't mean this has to play out exactly, it just means there is a only a 17% chance that it doesn't.
Also see the DECODE Macro Trend Oscillator (MTO) with the M2 Global Liquidity (YoY %) overlay enabled, and you can see that it is also turning up.
Not saying anything is going to happen, remember these are long term charts, just showing you the facts.

44
51
284
20,058
Daniel Chang retweeted

27 Apr 2025
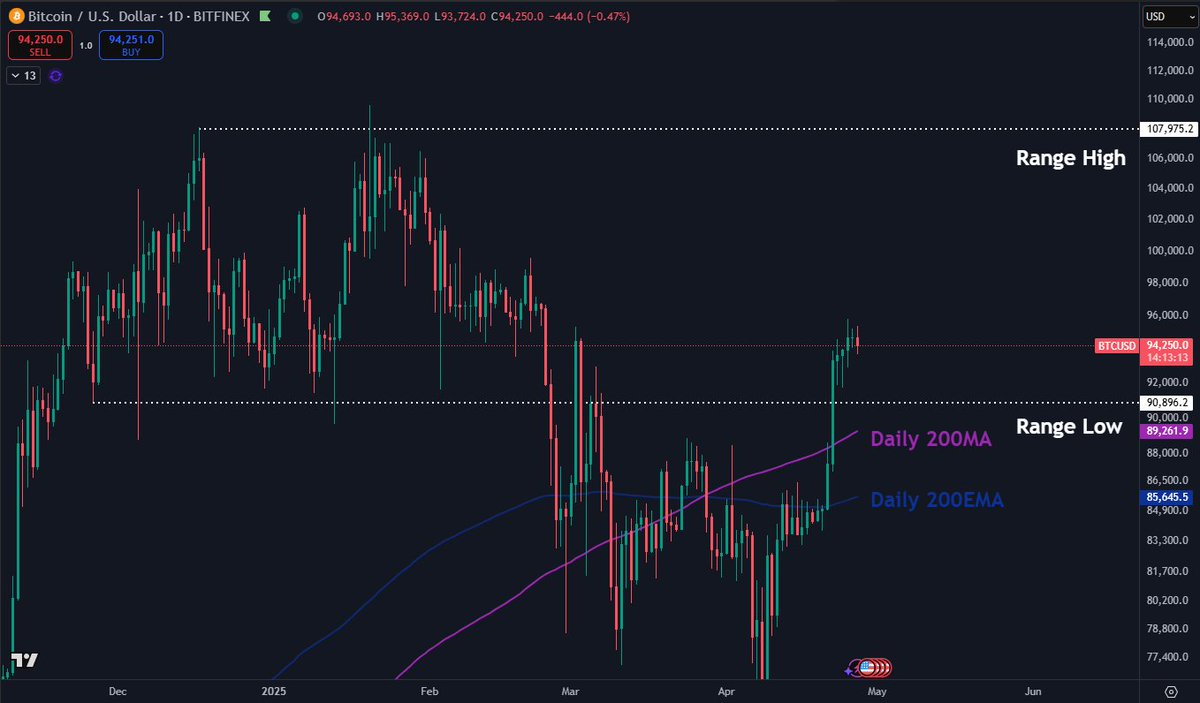
$BTC No need to overcomplicate.
Price accepted back into the previous range. Liquidity below was taken on extreme fear and macro uncertainty.
The latter could just as easily make this roll back over but the thing is, we don't know.
I'd rather let the chart speak instead of making all kind of (primarily) bad assumptions of what could happen. For every bearish thesis there's a bullish one.
Optimism pays in the long run on Bitcoin.
48
63
314
27,898
Daniel Chang retweeted

23 Apr 2025
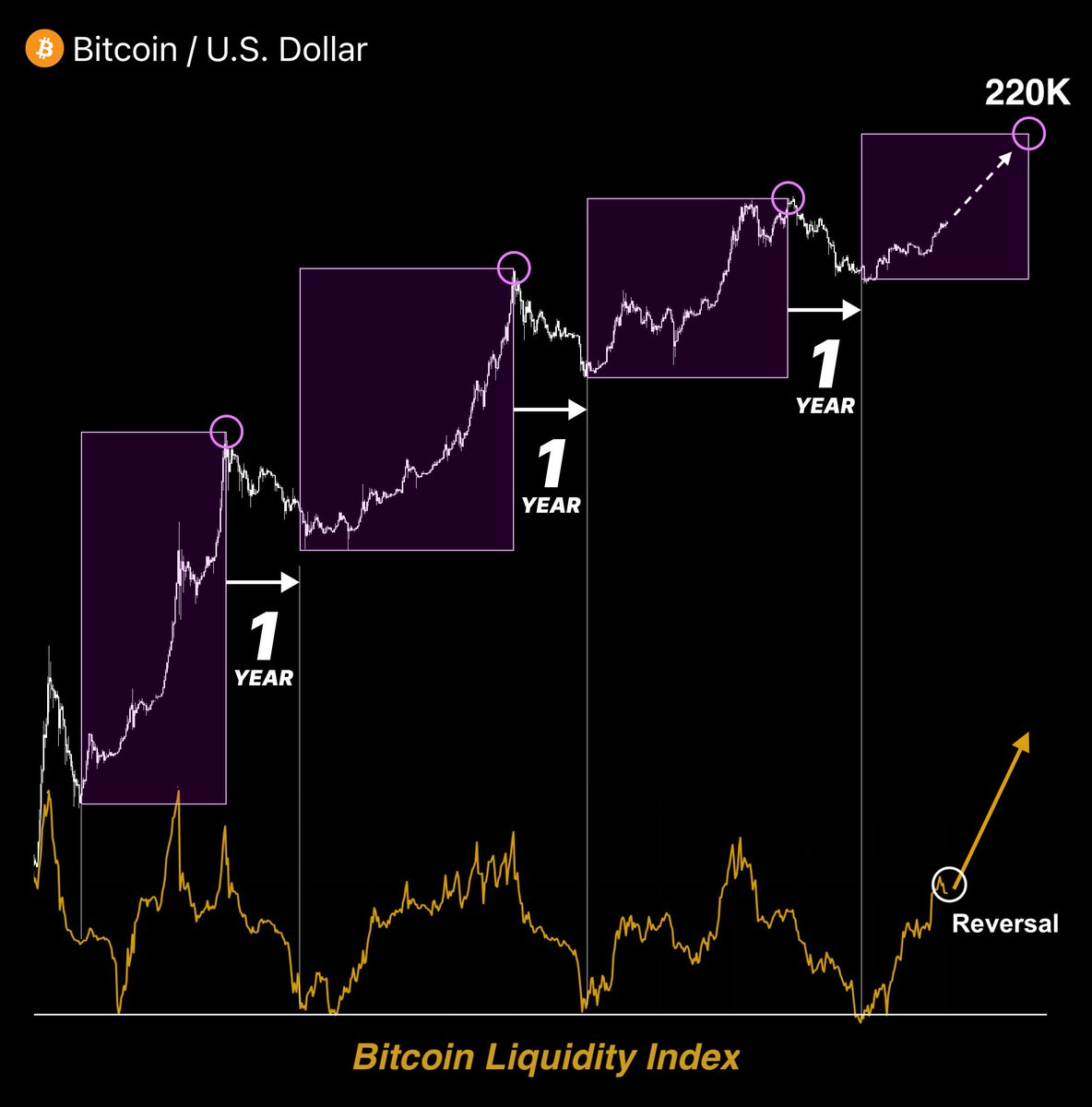
The next Bull Run starts on April 25 🔥
The $BTC Liquidity Index just broke out for the first time in 3 years.
Every $100 invested today will turn into $10,000 this summer.
Here’s my list of 10 coins with 100x upside potential 👇🧵
72
145
527
53,383
Daniel Chang retweeted

23 Apr 2025
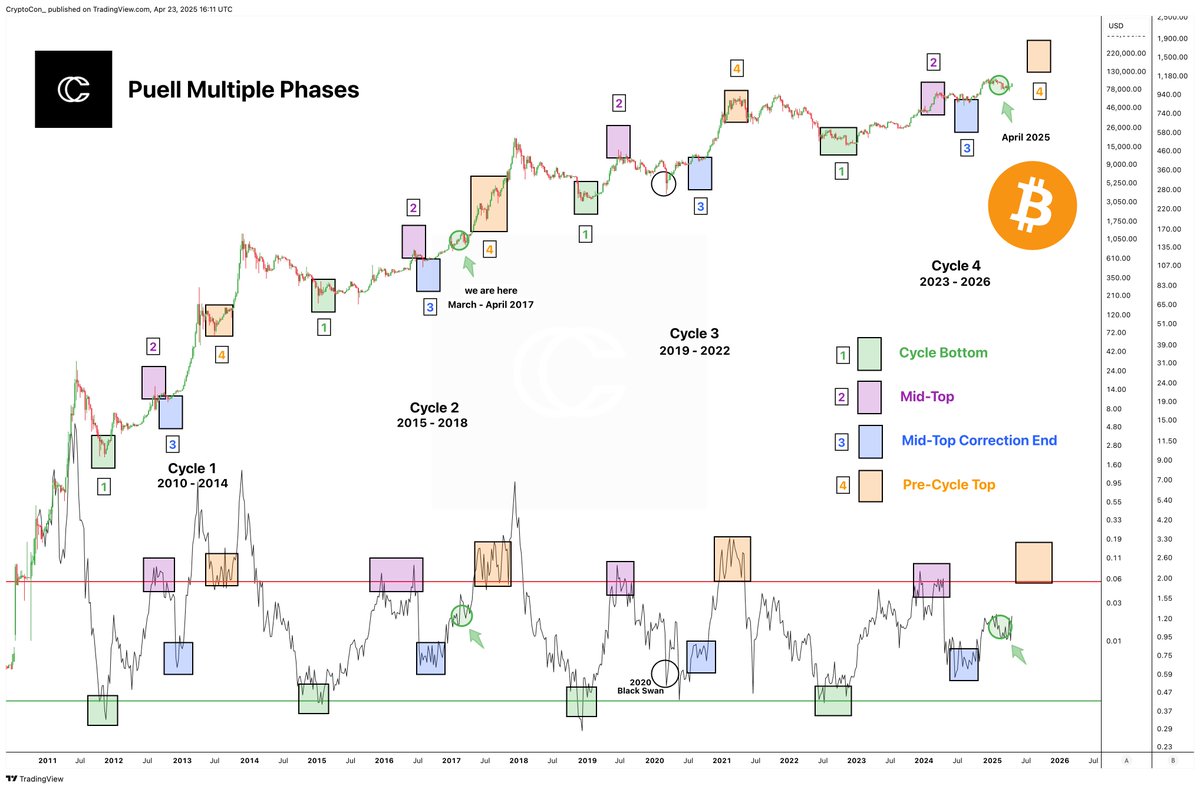
There's something clearly missing from this Bitcoin cycle...
It's the entire bull market parabola!
The perfect phases from Puell Multiple continue with no cycle top phase in sight.
I have a feeling the people who fully convinced you that a bear market and a recession were coming next are going to suddenly hope you forget that ever happened.
And most people will forget, just as they have when they've been told this at every local low this cycle.
Do you see why it is so difficult to make it from beginning to end?
42
155
836
39,694