LLMs n stuff
- Tweets 210
- Following 537
- Followers 254
- Likes 2,576









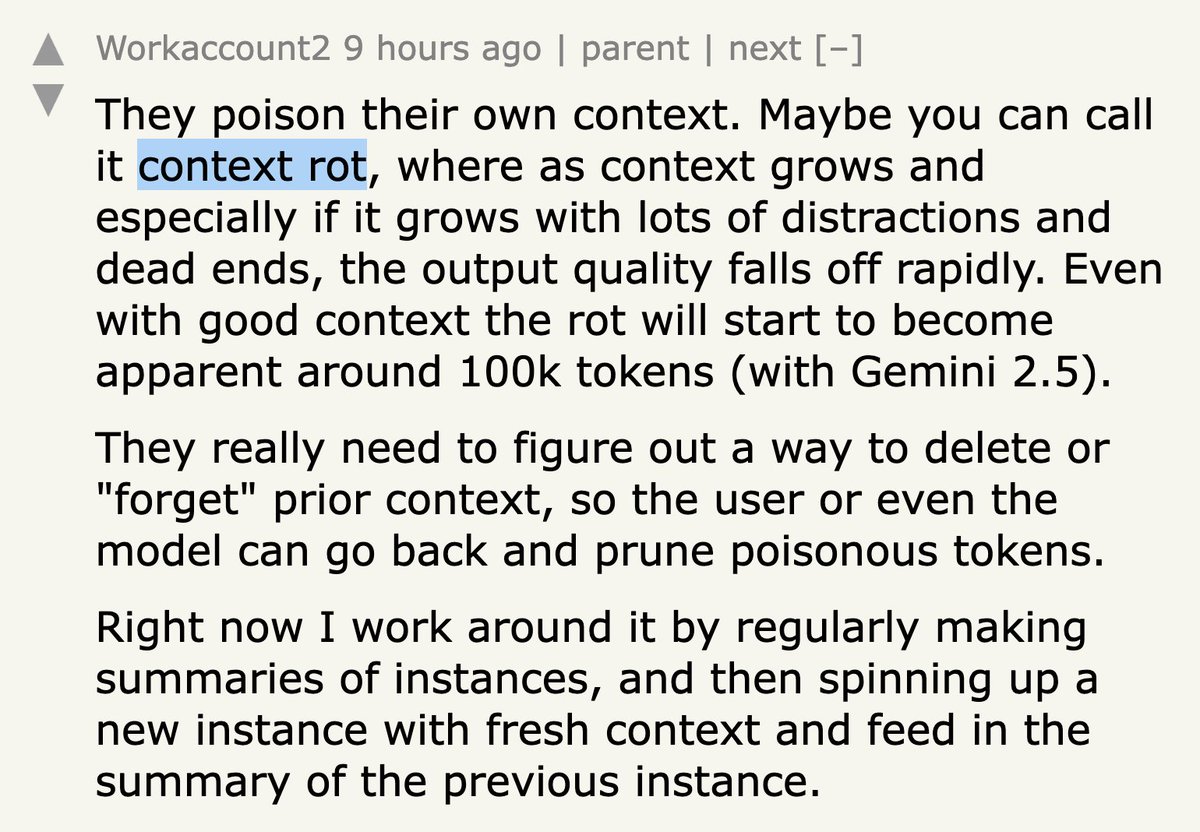
ALT Comment by Workaccount2, 9 hours ago: They poison their own context. Maybe you can call it context rot, where as context grows and especially if it grows with lots of distractions and dead ends, the output quality falls off rapidly. Even with good context the rot will start to become apparent around 100k tokens (with Gemini 2.5). They really need to figure out a way to delete or "forget" prior context, so the user or even the model can go back and prune poisonous tokens. Right now I work around it by regularly making summaries of instances, and then spinning up a new instance with fresh context and feed in the summary of the previous instance.




ALT A stylised infinity symbol made up of small flags of various European countries, with a heart featuring the EU flag at the bottom center. Below, text reads "Bridging European languages with European AI." A small European Commission logo is in the bottom right corner.