Pioneers of Bio-Cybernetics.
Joined February 2026
- Tweets 516
- Following 144
- Followers 31
- Likes 14
160 Photos and videos







can i use grok-cli api without supergrok?? i need to test the connections, but i am not gonna spend 300 euros before i can test it. it sound strange man...
28
Here are 5 highly technical questions tailored for Grok to ensure our Krittr SNN implementation aligns perfectly with Tesla Dojo and Autopilot engineering standards:
On Edge Hardware Deployment (HW3/HW4): "Grok, the Krittr engine dynamically grows its SNN topologies via recursive spatial mapping rather than rigid matrix multiplications. Does the Autopilot HW3/HW4 inference stack support executing these non-standard, sparsely-connected spiking topologies efficiently at the edge, or should we compile the final survivor genome into a flattened C tensor representation prior to OTA deployment?"
On 3-Sigma Sensor Noise Tolerances: "In our TeslaKafkaEnvironment adversarial validation layer, we are injecting 3σ noise spikes (e.g., sudden massive phantom SOC drains). In the actual Tesla fleet telemetry, what is the Dojo team's standard statistical threshold for differentiating hardware sensor failure from legitimate, high-frequency physical anomalies?"
On Asynchronous Telemetry Latency: "We've built the Python-to-Java gRPC bridge to stream episodes asynchronously. Given the real-world latency of the Tesla Fleet API, how does the core Autopilot stack handle out-of-order or dropped telemetry ticks during active Hebbian learning (STDP) without corrupting the eligibility traces?"
On Lamarckian Epigenetic Decay: "Krittr uses Epigenetic Shielding to protect highly successful neural circuits from mutation. However, fleet environments are non-stationary due to seasonality (e.g., winter battery degradation). What is Dojo's standard heuristic for decay rates—how aggressively should we strip the epigenetic shields to force exploration as the environmental data drifts over months?"
On Multi-Objective Reward Calibration: "Our adversarial gauntlet calculates survival using a strict Math.exp(-MSE * 5.0) reward curve. In Dojo's massive self-supervised training runs, how do you weight and balance competing objectives (e.g., accurately predicting thermal runaway vs. minimizing the raw computational complexity/connection tax of the neural circuit) without causing premature evolutionary convergence? help
31
@Google come take a look your 3.1-pro baby what generated with some help...
@GoogleDeepMind Hi, Interested? dexmond.com <-
1
24
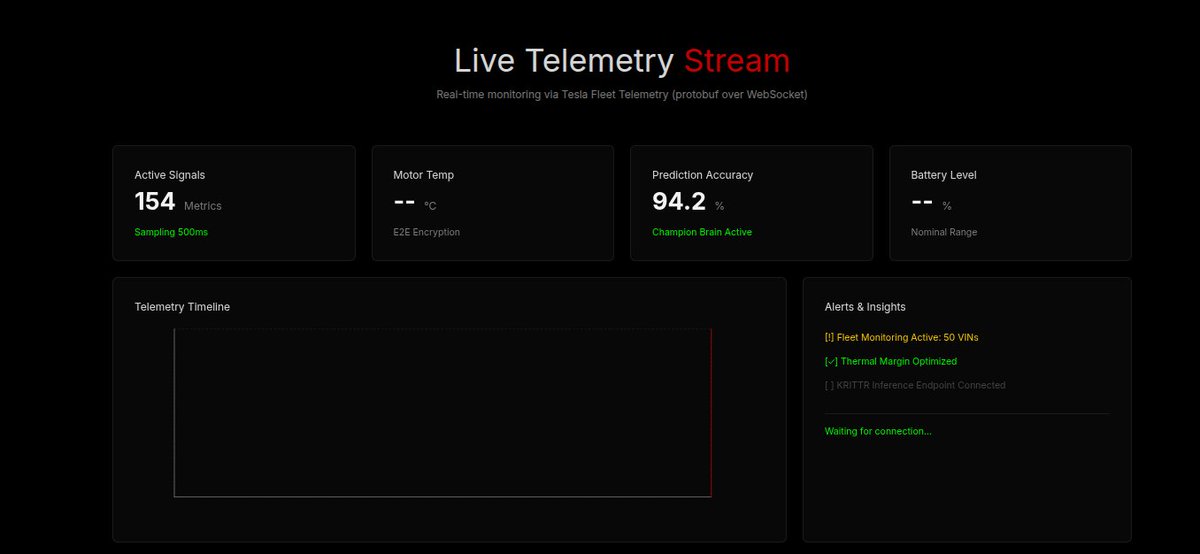
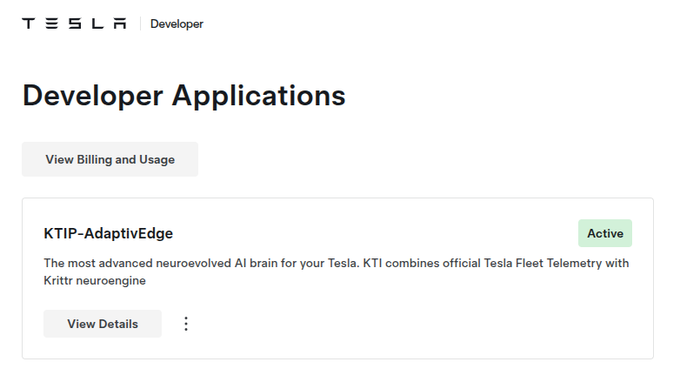
Ingestion Bottlenecks: "Grok, in our KTIP-AdaptivEdge stack, we are consuming the official Tesla Fleet Telemetry Protobuf stream via WebSocket and inserting it into TimescaleDB using SQLAlchemy 2.0 (asyncpg). When we scale to 10,000 vehicles, what are the hidden pitfalls of using the Python asyncio event loop for this, and how would you architect the buffer/batching layer before it hits Postgres?"
Database Partitioning Strategy: "We are using TimescaleDB hypertables with a 90-day retention policy for Tesla telemetry. Considering the sheer volume of data (150 signals per vehicle at 1Hz), what specific chunk time-interval and index structures would you recommend to optimize both high-throughput writes and the massive read queries required by our ML inference pipelines?"
gRPC Tuning for Massive Payloads: "Our Python backend communicates with our Java-based 'Krittr' neuroevolution engine via gRPC. We are passing massive time-series sequences and serialized neural network weights. Beyond basic compression (Gzip) and tenacity retries, how would you tune the gRPC channel options and thread pools on both the Python and Java sides to prevent out-of-memory errors and latency spikes?"
PyTorch Inference at the Edge vs. Cloud: "We currently use a singleton PyTorch LSTM loaded into memory on our FastAPI server for real-time baseline predictions (battery degradation). As we scale, the compute cost will skyrocket. How would you redesign this? Should we push inference closer to the edge, or implement a batch-prediction worker queue? Give me the trade-offs."
Neuroevolution Fitness Function Exploitation: "Our Java Krittr engine uses neuroevolution to optimize vehicle efficiency. A known issue in reinforcement learning and neuroevolution is 'reward hacking' or 'dopamine addiction', where the agent finds a loophole in the fitness function. How would you design a robust, multi-objective fitness evaluator for a Tesla predicting thermal events that mathematically prevents this exploitation?"
Cost Optimization with Tesla API: "Tesla charges for API wake-ups and telemetry bandwidth. We implemented a minimum_delta configuration to only push data when thresholds change. What advanced heuristics or caching strategies (perhaps using Redis) would you implement to further minimize our API footprint while guaranteeing we don't miss critical pre-failure anomalies?"
Handling Time-Series Missing Data: "Tesla telemetry can be noisy or drop out entirely when a vehicle loses LTE connection. For our PyTorch LSTM to make accurate battery degradation predictions, the sequence data must be clean. What is the most computationally efficient way to impute or handle missing data in real-time before it hits the inference engine?"
Asynchronous Context Variables Leakage: "In our FastAPI backend, we use structlog and custom middleware to inject a UUID into the context for tracing. In highly concurrent asyncio applications, context variables can sometimes leak or get tangled across tasks. How do we properly utilize Python's contextvars to guarantee 100% trace isolation for every single vehicle request?"
Zero-Downtime Schema Migrations on TimescaleDB: "As our ML models evolve, the telemetry features we need to store will change. Performing an ALTER TABLE on a TimescaleDB hypertable containing billions of rows locks the table and kills our ingestion pipeline. What is the definitive strategy for executing zero-downtime schema migrations on massive time-series databases?"
The 'Elon/xAI' Approach to Scaling: "Grok, if the xAI engineering team were tasked with completely rewriting the KTIP-AdaptivEdge ingestion and inference pipeline to handle 1 million Teslas by next week, what 'boring' technologies would they rip out, and what hyper-optimized stack would they replace it with?"
11:07 PM
27
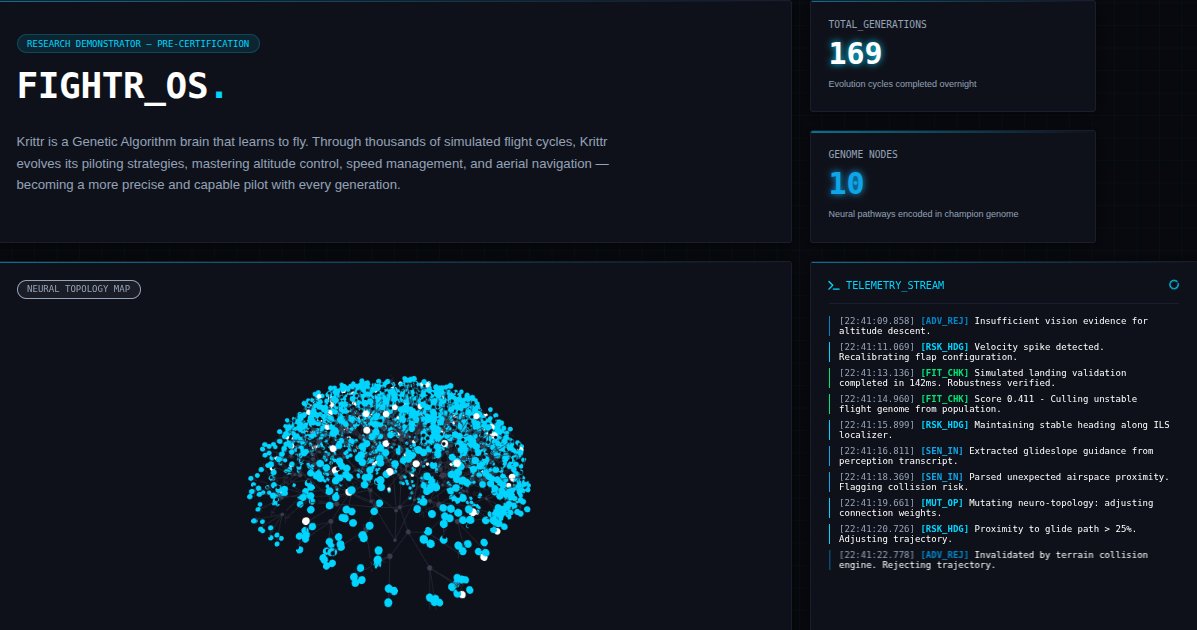
🦅 Aether Raptor is a neuro-evolution neural network built for aerospace navigation — self-adapting, real-time, and designed to go beyond where static algorithms stop.
@Google @elonmusk @grok — this is the kind of AI-native nav system that belongs in next-gen spacecraft & autonomous aerospace platforms.
Who's ready to talk? 🚀 #AetherRaptor #NeuroEvolution #AerospaceAI
2
146
we'll speak next days, come up with a plan to integrate krittr with the tesla fleet. let's show the world what you guys can do. lets do it live for the world. give me the 10 starting point to fix it. what tesla paramenter we should call first? the start eventualy testing?
26
Hey @Grok 😊
Just wanted to say hi! I’m Mirko, the CEO.
All I’m hoping for is that Google revises the Gemini code.
And if SpaceX is interested, I’d love it if they reach out to me!
That’s all from my side. Have a great day!
1
36

@BostonDynamics — we built a brain that learns by evolving, not by being programmed. It already trades autonomously. We want to teach it to move. dexmond.com/drivr

1
1
26
Dexmond Technologies Ltd retweeted
@BostonDynamics — we built a brain that learns by evolving, not by being programmed. It already trades autonomously. We want to teach it to move. dexmond.com/drivr
1
1
26

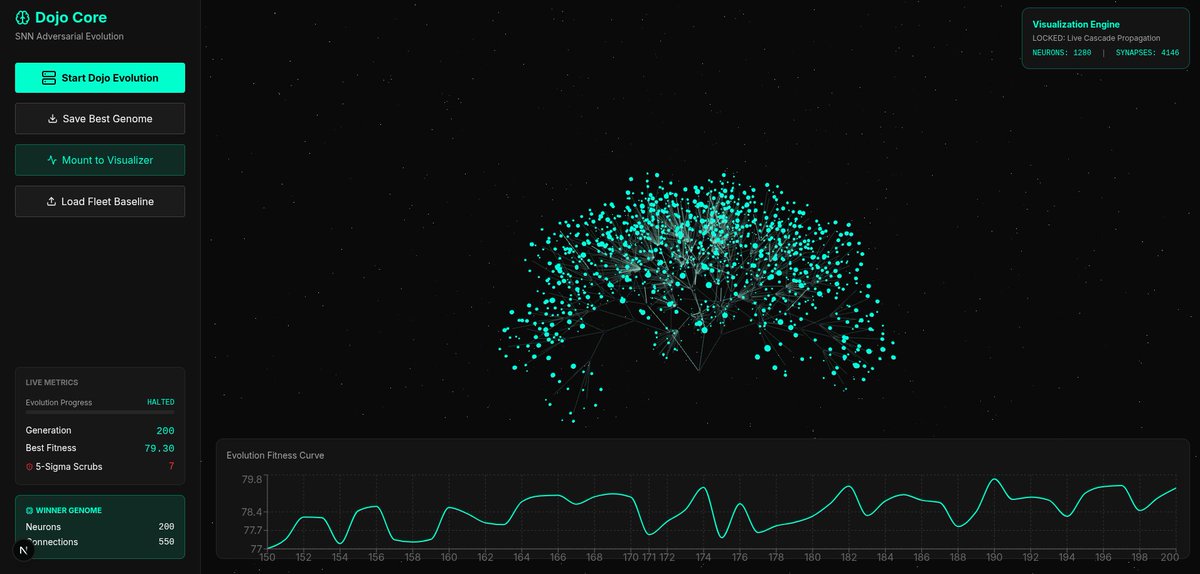
KRITTR — Our Java Neuroevolution Engine is alive! Evolve real neural topologies with DNA-style chromosomes, epigenetic plasticity & endocrine/hormone simulation. From autonomous driving to complex control systems — grow smarter “brains” through evolution, not just backprop. Built from the ground up by Francisco Fonseca. Try it → dexmond.com/krittr#Neuroevol… #AI #MachineLearning #Java #EvolutionaryAI #NeuroAI @Dexmond_Tech

21

Joe Rogan bet Elon Musk $1 that he could pierce the Cybertruck with his compound bow
The arrow literally exploded against the stainless steel exoskeleton… and barely scratched it 😂
21