
Applied scientist at @amazonscience Barcelona, Catalonia. Made at @la_upc & @columbia. Promoting @dlbcnai. Opinions my own.
Joined July 2012
- Tweets 6,463
- Following 1,792
- Followers 3,011
- Likes 16,513
1,165 Photos and videos
















X and @elonmusk have failed into promoting the values of democracy and human rights. Time to leave this platform.
We learned a lot here, thanks to those who made it possible.
Find me on LinkedIn and Bluesky.

La #UPC deixa de publicar a X per mantenir la seva comunicació en entorns que garanteixin la qualitat i la veracitat de la informació.
Una decisió que ha pres per consens el #ConsellGovernUPC, el 19 de febrer.
🔗upc.edu/ca/sala-de-premsa/no…

562
Xavi Giró retweeted

1
4
12
790
Xavi Giró retweeted

Jun 10
Everyone, please join Project Tapestry
thealliance.ai/projects/tape…
45
163
1,117
431,458
Xavi Giró retweeted

Jun 10
Local models can't benefit from batch parallelism as easily, but you can still parallelise over the token axis. So here's an open text diffusion model! >1000 tokens/sec for accelerated tokenmaxxing, yay!🫨
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
4
15
154
12,748
Xavi Giró retweeted

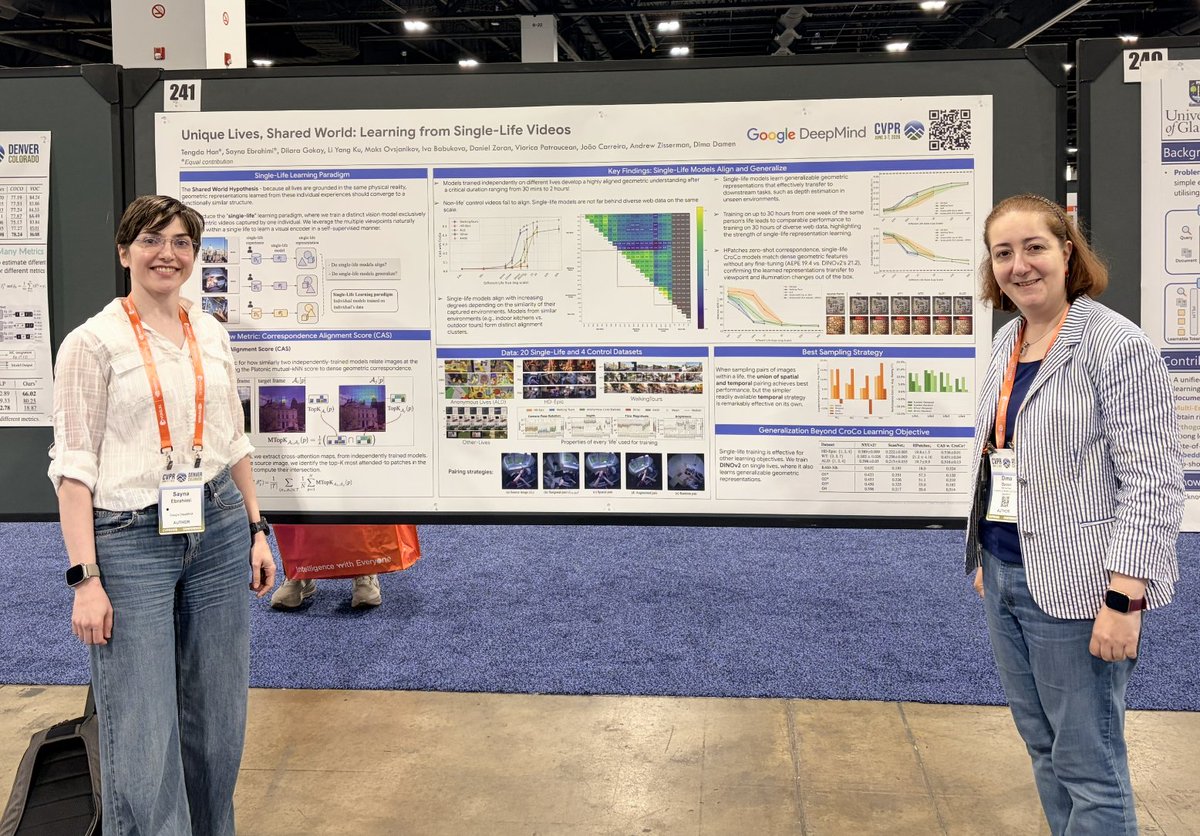
Poster is up #241!
Join us at Session 4 from 4:30pm (June 6) @CVPR #CVPR2026 for our @GoogleDeepMind paper
"Unique Lives, Shared World"... Learning from Single-Life Videos.
We introduce a new learning paradigm - only from the experiences of ONE person
@SaynaEbrahimi @TengdaHan
2
61
3,342
Xavi Giró retweeted

May 30
I followed up on two misconduct cases at top ML conferences.
TLDR; academic dishonesty pays 😓
Bans (especially cross-venue bans) are non-existent and hard to enforce [1/3]

7
16
215
45,680
Xavi Giró retweeted

May 28
📢 New @heyjasper release ! 📢
MONET 🌸 : An Apache2.0 deduped and recaptioned dataset of 105M samples unlocking reproducible text-to-image research.
Nano T2I 🖌️ : A codebase to train your own T2I model
🤗 @huggingface: huggingface.co/datasets/jasp…
💻: github.com/gojasper/nano-t2i
Very excited about this new release, pushing the boundaries of open and reproducible T2I research.
Congrats to the team!
Benjamin Aubin Gonzalo Quintana @onurxtasar @UlaLaParis @_jeev2 @dh7net @clipdropapp @heyjasperai
9
33
116
45,195
Xavi Giró retweeted

May 27
Announcing the #AmazonResearchAwards fall 2025 recipients:
🔍 68 researchers
🏫 49 universities
🌏 11 countries
Each gains access to 800 Amazon public datasets and AWS AI/ML tools. Meet the cohort: amzn.to/4uaFNZC
5
13
19,230

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
May 27

Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
154
639
5,765
742,098
Xavi Giró retweeted

May 22
This is the way
AI to solve environmental challenges and ensure a safe and prosperous future for our children. Congratulations and thanks @cusp_ai team 👏🙏
May 21

Today @cusp_ai and @KemiraGroup announce a milestone in AI-driven materials discovery.
We have used generative AI to design new materials targeting PFAS removal from drinking and process water at trace concentrations.
3
3
35
8,429
Xavi Giró retweeted

Mar 26
After @Pinterest @Airbnb @NotionHQ @cursor_ai, today it’s @eoghan @intercom publicly sharing that they’re finding it better, cheaper, faster to use and train open models themselves rather than use APIs for many tasks.
And hundreds of other companies are doing the same without sharing.
Ultimately, I believe the majority of AI workflows will be in-house based on open-source (vs API). It took much more time than we anticipated but it’s happening now!

79
185
1,663
405,271

Xavi Giró retweeted

The #3DV2026 Keynote and Award Talk recordings are officially live! 🎥🍿
Revisit all the fantastic presentations from our insightful speakers and keep the 3D vision inspiration going!
See the links below⬇️

1
17
119
11,516
Xavi Giró retweeted

Mar 25
LeWorldModel: Yann LeCuns Radical Simplification of World Models Just Made Physics-Aware AI Practical
In the race for artificial general intelligence, two paths have emerged. One is the familiar scale everything route: bigger LLMs trained on ever-larger text corpora. The other, championed for years by Yann LeCun, is building world models: compact systems that learn the underlying physics of reality directly from raw sensory data (pixels) so AI can plan, predict, and act in the physical world like a robot or self-driving car actually would.
Until now, the second path has been frustratingly difficult. Joint-Embedding Predictive Architectures (JEPAs) - LeCuns elegant framework for learning predictive representations without reconstructing every pixel - kept collapsing during training. Researchers had to resort to a laundry list of hacks: multi-term loss functions (up to six hyperparameters), frozen pre-trained encoders, stop-gradients, exponential moving averages, and other duct-tape tricks just to keep the model from mapping every input to the same useless output.
LeCuns team (Mila, NYU, Samsung SAIL, and Brown University) dropped a bombshell:
LeWorldModel (LeWM) - the first JEPA that trains stably end-to-end from raw pixels using only two loss terms. No more house-of-cards engineering. Just a clean, simple recipe that works on a single GPU in a few hours with only 15 million parameters.
The Core Breakthrough: SIGReg Saves the Day
LeWorldModels secret weapon is a new regularizer called SIGReg (for spherical isotropic Gaussian regularizer). It enforces a simple Gaussian distribution on the latent embeddings.
This single term prevents representation collapse without any of the previous heuristics.
The training objective now has just two parts:
1. Next-embedding prediction loss - the model predicts what the next latent state should be.
2. SIGReg - keeps the latent space well-behaved and diverse.
Thats it. Hyperparameters drop from six to one. Training becomes stable, reproducible, and dramatically cheaper.
The model learns directly from raw video frames (no pre-trained vision encoders needed) and produces a compact latent world model that can be used for fast planning.
Impressive Results on Real Benchmarks
Despite its tiny size, LeWorldModel punches way above its weight:
- Trains on a single GPU in a few hours.
- Plans actions up to 48 times faster than foundation-model-based world models.
- Uses roughly 200 times fewer tokens than alternatives.
- Matches or beats far larger models on diverse 2D and 3D control tasks (e.g., manipulation, navigation).
- Its latent space encodes meaningful physical quantities (position, velocity, etc.) - proven by direct probing.
- It reliably detects physically implausible surprise events, showing genuine causal understanding.
Crucially, adding a decoder and reconstruction loss hurts performance on downstream control tasks. The pure JEPA objective already captures everything needed for planning - extra visual details just get in the way.
Project website: le-wm.github.io/
Official code: github.com/lucas-maes/le-wm
Why This Matters for the Future of AI
LeCun has been saying since 2022 that world models (not next-token predictors) are the key to real intelligence. Critics always pointed to the training instability. LeWorldModel removes that objection with elegant simplicity.
This is a philosophical reset: AI can learn physics the way babies do - by watching the world unfold - without needing supercomputers or endless text.
The implications for robotics, autonomous vehicles, and embodied agents are enormous. Suddenly, building a physically grounded planner is something a researcher (or even a hobbyist) can do on consumer hardware.
1 of 2

26
132
663
69,687
Xavi Giró retweeted
Mar 25
📣 Amazon Research Awards spring 2026 call for proposals is now open for submissions. Successful applicants will receive unrestricted funds, AWS promotional credits, and training resources. Deadline for submissions is May 6. amzn.to/4c3GH3Z

2
19
2,821
Humanity well-being 2030s ?
aiforpeaceworkshop.github.io
Jan 30

Decade in which each subfield of AI went from not being for real to being for real:
Search: 1960s
Machine learning: 1990s
Vision: 2010s
NLP: 2020s
Reasoning, planning, robotics, etc.: TBD
181



Xavi Giró retweeted

Jan 16
In an effort to better understand VLMs, we found that they are fragile in surprising ways. Just changing the color of pointing markers (red circle → blue circle) can completely change the results! :
Jan 14

🌟NEW PAPER🌟
Do you know that changing a visual marker from red to blue can completely reorder VLM leaderboards? In our most recent work, we explore the fragility of visually prompted benchmarks. lisadunlap.github.io/vpbench…

4
9
105
15,492
Xavi Giró retweeted

✨ Kind reminder! The ELLIS Unit Barcelona is hosting its fourth Scientific Seminar.
Join us for the Scientific Seminar on January 28th with a talk by Prof. @PascalMettes on "Hyperbolic Deep Learning".
Don't miss out ➡️ellisbarcelona.eu/ellis-unit…

3
6
341
