
Exploring new models & mechanisms for public goods funding, via events, residencies, hackathons & real-world pilots. Incubated by @ProtocolLabs. 🤝
Joined June 2022
- Tweets 4,843
- Following 946
- Followers 8,603
- Likes 41,060
1,203 Photos and videos













Pinned Tweet

Looking for ways to support internet freedom? Our quadratic funding round with @torproject is live.
Ten privacy and anti-censorship nonprofits. $115K match pool from @cakewallet, @ZcashCommGrants, @Logos_network, @OctantApp.
Here they are. 🔒👇

4
15
55
9,308
Funding the Commons retweeted

I support Internet Freedom.

Consider this your badge. ✊
If you've backed our Internet Freedom round with @torproject, or you're about to, repost and let people know where you stand.
The round closes June 18. Support #InternetFreedom 🌐
internetfreedom.torproject.o…
2
15
236
Consider this your badge. ✊
If you've backed our Internet Freedom round with @torproject, or you're about to, repost and let people know where you stand.
The round closes June 18. Support #InternetFreedom 🌐
internetfreedom.torproject.o…
10
27
748
Funding the Commons retweeted

Jun 12
Come find me this week to chat about internet freedom and get moav.sh stickers
- June 14th at Neocypherpunk Summit @web3privacy
- June 17th at @dappcon
If you cannot make it to Berlin, run MoaV & donate to internet freedom: x.com/torproject/status/2062…



Jun 4

"In some places even searching can feel risky, so people hide parts of themselves"
Support the organizations ensuring that the internet is no longer one of those places.
internetfreedom.torproject.o…
Thank you @cakewallet, @ZcashCommGrants, @Logos_network, @gitcoin and many more who #FundInternetFreedom
2
6
23
1,958
Funding the Commons retweeted

Jun 11
Sometimes freedom looks like a protest. Sometimes freedom begins when someone refuses to stay silent.
The @torproject ecosystem supports the people who choose to speak out.
Support the projects protecting digital freedom: internetfreedom.torproject.o…
6
16
52
4,516
"I should really support that kind of thing."
Great news about the timing on that. 👇
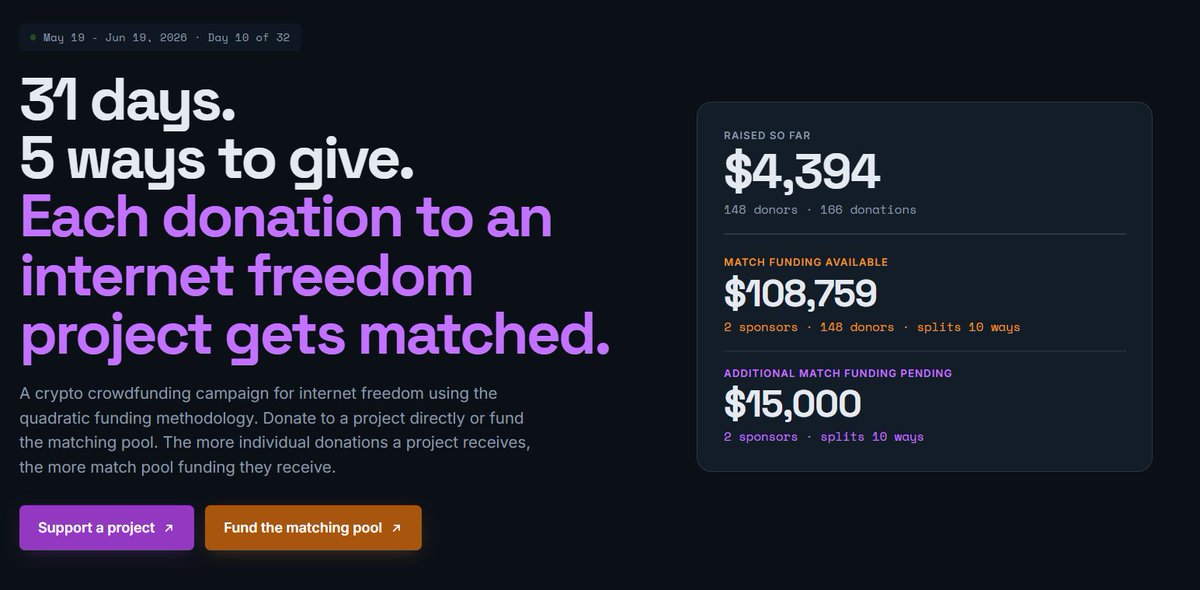
The Internet Freedom round is running through June 18: a quadratic funding campaign with @torproject supporting ten nonprofits across the privacy and anti-censorship ecosystem.
@SecureDrop @open_archive @r2refresh @OpenObservatory @PasKoocheh @unredacted_org, OnionShare, Onion Browser, Miaan, and Osservatorio Nessuno.
$115K in matching from @cakewallet @ZcashCommGrants @Logos_network and @OctantApp.
The more people who back a project, the larger its share, so even a small donation moves more than you'd think.
👉 internetfreedom.torproject.o…
4
19
442
Funding the Commons retweeted

Jun 11
[BREAKING] We're introducing properQF in Epoch 12.
Quadratic funding, in its most proper form, in a funding round.
Run the numbers. Try it now: qf.octant.app
14
17
65
5,674
Open source built most of the internet. The model that got us here doesn't reliably pay the people who maintain it, and AI training has only sped up the extraction.
If you're in SF tomorrow, join a community chat on what a sustainable model looks like. 👇
luma.com/vtwfj0p2
2
18
365
Funding the Commons retweeted
Jun 9
Freedom is strongest when it's supported by you.
@n8fr8 x @guardianproject on why supporting Onion Browser & The Tor Project ecosystem matters.
Donate & protect rights online: internetfreedom.torproject.o…
hashtag#FundInternetFreedom
9
32
3,269
Funding the Commons retweeted
Jun 10
Freedom is strongest when it's supported by you.
Ricochet Refresh @r2refresh team on why supporting Peer-to-peer encrypted instant messaging & @torproject ecosystem matters.
Donate & protect rights online:
internetfreedom.torproject.o…
Powered by @torproject, @FundingCommons, @OctantApp, @Logos_network, @ZcashCommGrants, @cakewallet
#FundInternetFreedom
8
27
3,608
Funding the Commons retweeted

BIG: The United Nations Development Programme (UNDP) has launched a new Blockchain Advisory Group to explore how blockchain technology can support global development initiatives.
The group brings together 26 organizations from across the crypto and blockchain industry, including:
@AlgoFoundation
@arbitrum
@avax
@Cardano_CF
@ethereumfndn
@Filecoin
@StellarOrg
@SuiNetwork
@Web3foundation
@krakenfx
@ChainforGood
@BFI_Impact
@Celo
@cosmos
@dfinity
@Exponential_Sci
@flock_io
@FundingCommons
@Giveth
@InfStones
@NEARWEEK
@nordicblock
@partisiampc
@adbc_ae and more.
The initiative aims to leverage blockchain expertise to advance transparency, financial inclusion, digital public infrastructure, and sustainable development efforts worldwide.

3
5
23
1,020
Funding the Commons retweeted

May 25
This August, Zō Village is bringing together an interesting group of movers and shakers. And offering:
→ Fun, curated cultural events
→ Find clients, co-founders, or investors in Japan
→ Fitness classes
Read more: zovillage.com
DM for more info!
1
8
712
Funding the Commons retweeted

Jun 4
we just posted the data to resolve the level 3 deep funding market!
we got 15 open source repos sharing relative value between 685 of their dependencies
using prediction markets, we scaled their evaluation to 3,677 dependencies across 98 open source repos
how does this work? using leverage through whats called conditional prediction markets
traders put money across all repos & their dependencies, but their P&L is based on only the ones that did get evaluated.
so if they just trade on 2 markets, one of which is evaluated and one isnt, their leverage is 2x as their entire position is based on the one that did get evaluated
so by evaluating 685 dependencies out of 3,677, our conditional prediction market for value of dependencies in an open source repo traded at a leverage of 5.36
the link with all the data is posted in the tweet below, really hope we start to see more conditional prediction markets & not just the bread and butter binary ones that are the current staple of the space
ongoing markets for originality (how much stays with repo vs its dependencies) and relative value between the 98 repos still available to trade

Deep Funding Level III has closed.
$5,000 in prizes, and a leaderboard determined by how closely each model's predicted weights match the scores given by human maintainers.
One of the write-ups, from a participant (Rohith10) who built a model called FWDIS (Frequency-Weighted Dependency Importance Scoring), is worth pulling out as an example of what serious participation in this round actually looks like.
The interesting part is the hypothesis the participant decided to test.
The baseline approach to scoring dependencies treats each one as if its importance lives entirely inside the relationship between that dependency and its parent repo, which means you're scoring web3py's contribution to ethers, web3py's contribution to eth-brownie, and web3py's contribution to every other repo that uses it as if each were a separate question.
Rohith10 noticed that this misses something obvious, a dependency that 20 repos rely on is probably more foundational than one that a single repo uses, and that observation can be turned into a feature the model uses to adjust its weights.
The implementation is three lines of code.
Count how many of the 98 repos use each dependency, normalize by 98, multiply the baseline weight by one plus a tuning coefficient times that frequency score, and renormalize so each repo's dependency weights still sum to 1.
The participant found through grid search that a coefficient of 0.42 produced the best alignment with jury scores, and the model landed in the top tier of the leaderboard with a score of 0.2402 against the baseline's 0.2472.
The reason this is worth sharing is because this participant's process is exactly what the mechanism is built to reward.
They formed a hypothesis about what human jurors actually value when they score dependencies (foundational utility across the ecosystem, not just contribution to one parent), turned that hypothesis into a feature, tested it against the data, and shipped a model that aligned with expert judgment better than the baseline did.
This is what distilled human judgment looks like when it works. Markets reward whoever predicts the jury most accurately, and the path to predicting the jury accurately runs through understanding what experts actually care about.
The contest is open for Level 1 and Level 2 until May 10.

4
3
26
8,056
Funding the Commons retweeted
Jun 4
Some questions are difficult to ask out loud.
Around the world, people use privacy tools to search, learn, connect, and find community safely online.
The @torproject ecosystem supports open source protecting the freedom to explore identity, communicate privately, and stay connected without fear of surveillance.
Support the projects protecting digital freedom from @OpenObservatory to @SecureDrop: internetfreedom.torproject.o…
3
19
51
12,454


Our new governance report is live.
We gave six communities money, total freedom, and an AI that could spend it for them, then watched how they chose to govern.
A field study in AI-assisted governance, with @protocollabs @GainForestNow @OctantApp @hypercerts 👇
3
11
31
3,361
So where does AI fit?
AI helps most as an advisor: it lays out every option clearly so a group can choose well, while the people keep the final say. 💡
1
4
131
Read the full research report 📄
fundingthecommons.io/post/co…
Simocracy was built by @davidtdao. Thank you to everyone who made this experiment possible. 🙏
3
124