
Your daily AI map. 10-min podcast newsletter, curated from the people actually building AI. Every story cited. Every source traceable. 🗺️
Joined April 2026
- Tweets 68
- Following 50
- Followers 8
- Likes 9
13 Photos and videos









May 7
Today's AI Map · May 7
Another good and nourishing day!
🗺️ Anthropic partners with SpaceX to take over Colossus 1. Claude Code limits doubled immediately.
🗺️ Dario: Claude usage grew 80x. A one-person billion-dollar company is coming this year.
🗺️ DeepSeek V4 matches GPT-5.2 at 17x lower cost. One dev cut API spend from $85 to $22/month.
3 signals worth your attention ↓
2
1
1
74
May 7
🗺️ Anthropic just partnered with SpaceX to take over Colossus 1 for additional Claude inference.
Claude Code 5-hour limits are doubled across Pro, Max, Team, and Enterprise, effective immediately. Peak-hour throttling is gone for Pro and Max. Opus API limits are substantially up. Anthropic CTO Tom Brown says inference starts ramping on Colossus within days, roughly 300MW, 220,000 NVIDIA GPUs,
estimated at $5B/year.
The reason it's happening now: usage grew 80x faster than expected and
Anthropic ran out of compute trying to keep up.
Worth noting: Elon Musk is currently in the middle of a lawsuit against
OpenAI, and he just lent his infrastructure to Anthropic. Make of that what you will.
startup signal: inference capacity is now a strategic asset. Frontier labs are renting from competitors to meet demand.
citation via
@claudeai
@nottombrown
@xai
@arohan
@scaling01
@kimmonismus
@krishnanrohit
@ClaudeDevs

We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
1
1
3
79
May 7
🗺️ Dario Amodei thinks 2026 is the year we see a one-person billion-dollar company.
"Before, if you had an idea or vision there are so many resources you'd have to accumulate for several years. I think there's a unique opportunity for single individuals or very tiny teams to do things that are incredible."
This is not purely a prediction. Claude usage grew 80x faster than Anthropic expected in the past six months, and the compute shortage that just got fixed was a direct side effect of solo builders and tiny teams actually showing up. Turns out the one-person billion-dollar company might already be in the room, just rate-limited.
startup signal: the bottleneck for solo founders has shifted from resources to judgment.
via @kimmonismus @ClaudeDevs · Youtube youtube.com/watch?v=GMIWm5y9…
May 6

Dario&Daniela Amodei Interview: The 80x growth reportedly caught them completely off guard, and that's the reason for the compute constraint.
The compute deal with SpaceX is the first attempt to address the shortage and continues to search for solutions.
3
2
59
May 7
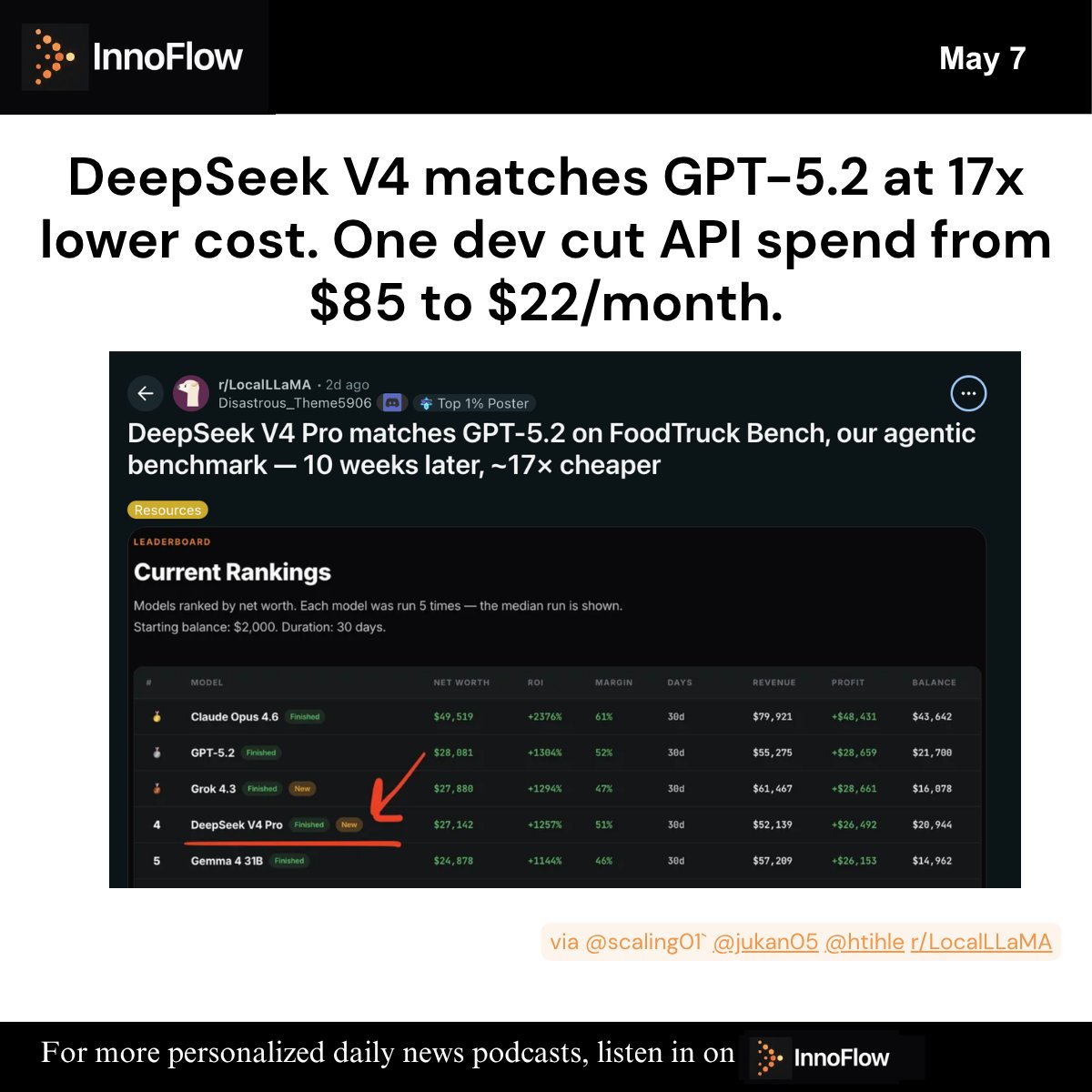
🗺️ DeepSeek V4 Pro matches GPT-5.2 on agentic benchmarks. It costs 17x less.
One developer instrumented 10 days of coding-agent usage and routed 65% of tasks to a local Qwen 3.6 27B on an RTX 3090. File reads, test writing, single-file edits, all handled locally. Monthly API spend dropped from $85 to $22. Only multi-file debugging and complex
refactors needed the cloud. DeepSeek V4 Pro hit #4 on FoodTruck Bench, within 3% of GPT-5.2's median outcome.
For the builders and founders, the missing piece for most teams is an automated router that classifies tasks and dispatches them to the right model.
That router does not really exist yet.
via innoflows.net @scaling01` @jukan05 @htihle r/LocalLLaMA
May 6

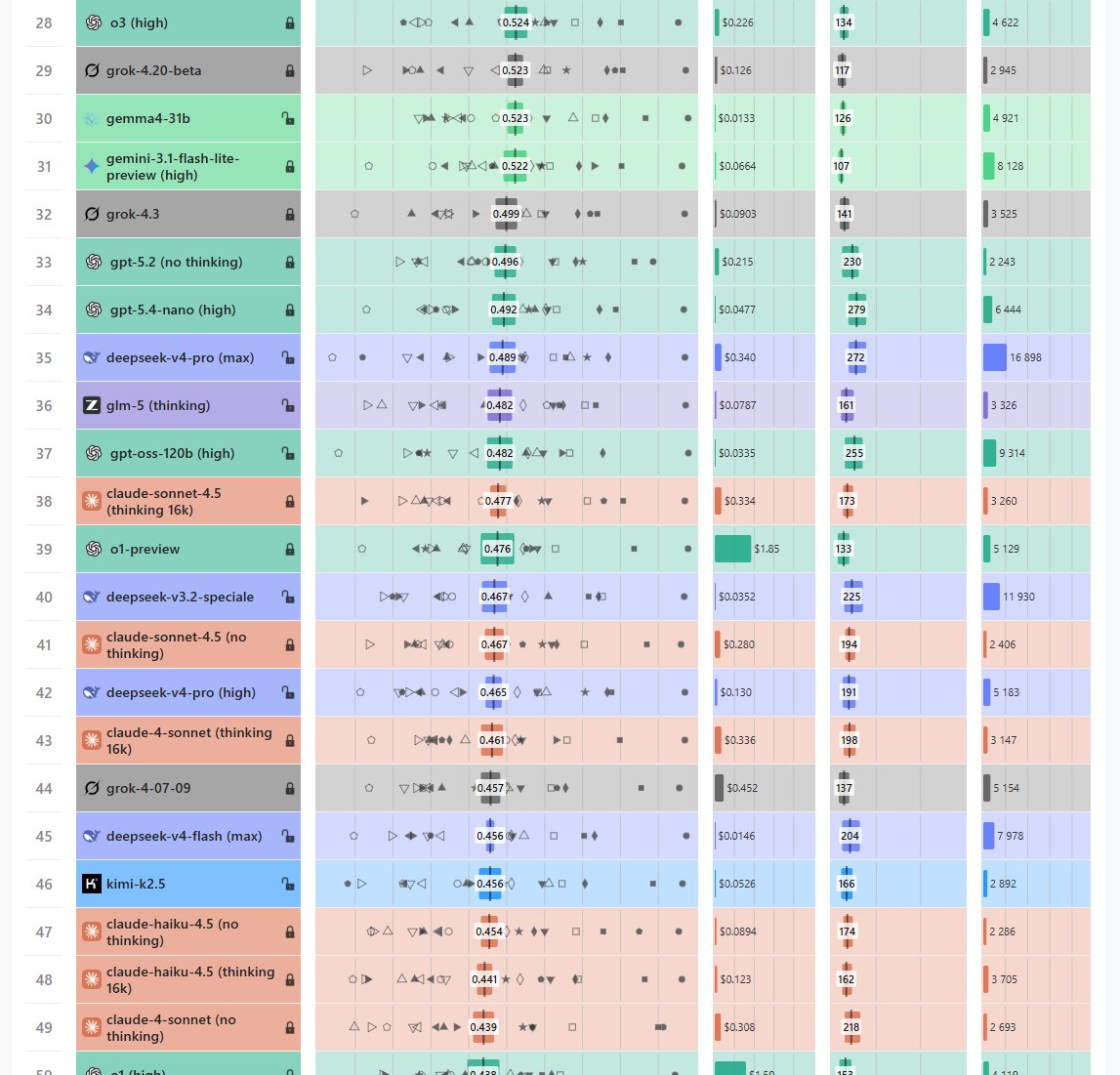
DeepSeek v4 pro (max) scores 48.9% on WeirdML, improving on v4 pro (high) at 46.5%, but still well behind Kimi-k2.6 and GLM-5.1 at 56% and 57%, let alone the closed frontier.
These runs, like the previous ones, were through Fireworks AI.
2
1
1
160

We’ve agreed to a partnership with @SpaceX that will substantially increase our compute capacity.
This, along with our other recent compute deals, means that we’ve been able to increase our usage limits for Claude Code and the Claude API.
4,731
11,930
130,541
23,979,935
May 7
Sources ↑
① Claude x SpaceX:
via @claudeai @nottombrown @xai @arohan @scaling01 @kimmonismus @krishnanrohit @ClaudeDevs
② Tiny teams:
via @kimmonismus @ClaudeDevs · Youtube youtube.com/watch?v=GMIWm5y9…
③ DeepSeek/local routing:
via @scaling01, @jukan05, @htihle, r/LocalLLaMA
See everyday AI moves first in our podcast and newsletter here! innoflows.net/
Freeeeeee
50
May 5
3.🗺️Sierra Raises $950M at $15B. Enterprise AI
Agents Are a Category.
two years ago Sierra had four design partners. today they serve 40% of the Fortune 50, and agents built on their platform handle billions of customer interactions:
refinancing mortgages, processing insurance claims,
returning orders, raising funds. they hit $100M ARR in 7 quarters.
Bret Taylor just announced a $950M raise from Tiger Global and GV at a $15B valuation.
skip the headline number. the 40% Fortune 50 penetration is the signal that actually matters. that means the AI agent conversation at the enterprise level has already moved past experimentation. deployment is the default now.
the market has split into two distinct categories: developer tooling and customer-facing enterprise deployment. the ceiling on the second one looks a lot higher than most people in the dev tools world tend to assume.
Builder signal: verticalized enterprise agent platforms,
compliance-aware deployment, customer-experience AI
Check out today's InnoFlow brief → innoflows.net/
May 4

Sierra is raising $950 million from new and existing investors, led by Tiger Global and GV, at a valuation of over $15 billion. We now have more than $1 billion to invest in becoming the global standard for companies wanting to transform their customer experiences with AI.
We’ve never had such conviction in the opportunity for Sierra and our customers. Just a couple of years ago, we had four design partners. Now, Sierra is serving over 40% of the Fortune 50, and agents built on our platform are powering billions of customer interactions — everything from refinancing homes to processing insurance claims, returning orders, and helping people raise millions in fundraisers.
We’re deeply grateful to our customers for helping show what’s possible. If you’re not yet using Sierra, we’d love to partner with you. sierra.ai/blog/better-custom…
21
May 5
🗺️One Message. 60M Tokens. $30. Still
Running.
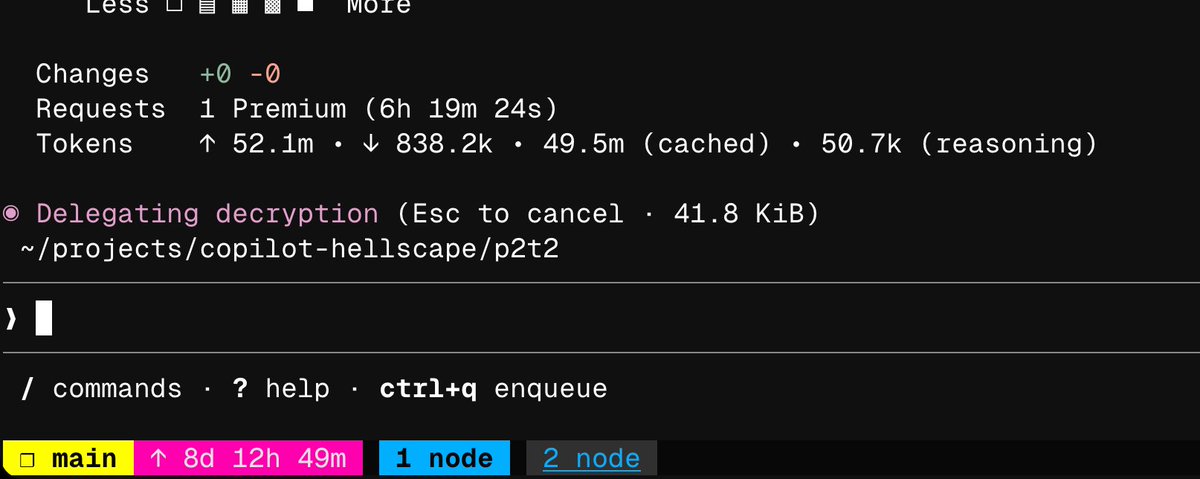
Theo ran one session on Copilot. 52 million input tokens. 838K output. $30 of inference and the session was still going. then he did the math: the current billing model gives you 1,500 messages per cycle, regardless of how expensive each one is. on a $40 plan, you could theoretically run $45,000 of compute.
GitHub confirmed they are moving off this billing model on June 1st. Theo ran 15 more sessions and hit $221 of tokens total, which was 1.6% of his $40 plan.
@cheatyyyy said what everyone running serious coding agents is quietly thinking: "i leave my agent on and come back to it asking a stupid question, it's been too long and i see it charge me a dollar in input costs on next message LMAO"
the per-message model was never going to survive real usage. the opportunity is in smarter routing: local model fallbacks, usage-aware orchestration, anything that stops sending every call to the frontier model.
Builder signal: cost-optimized agent orchestration,
local/hybrid model switching, token-aware routing
Part of today's InnoFlow Newsletter/Podcast → →innoflows.net/
via @theo @cheatyyyy
May 4

I sent a single message on Copilot and it did over 60m tokens. It's still going. $30 of inference so far.
In their current billing model, you get 1,500 messages, regardless of how expensive each is. I'm pretty sure I can do $45,000 of messaging on this plan
1
22
May 5
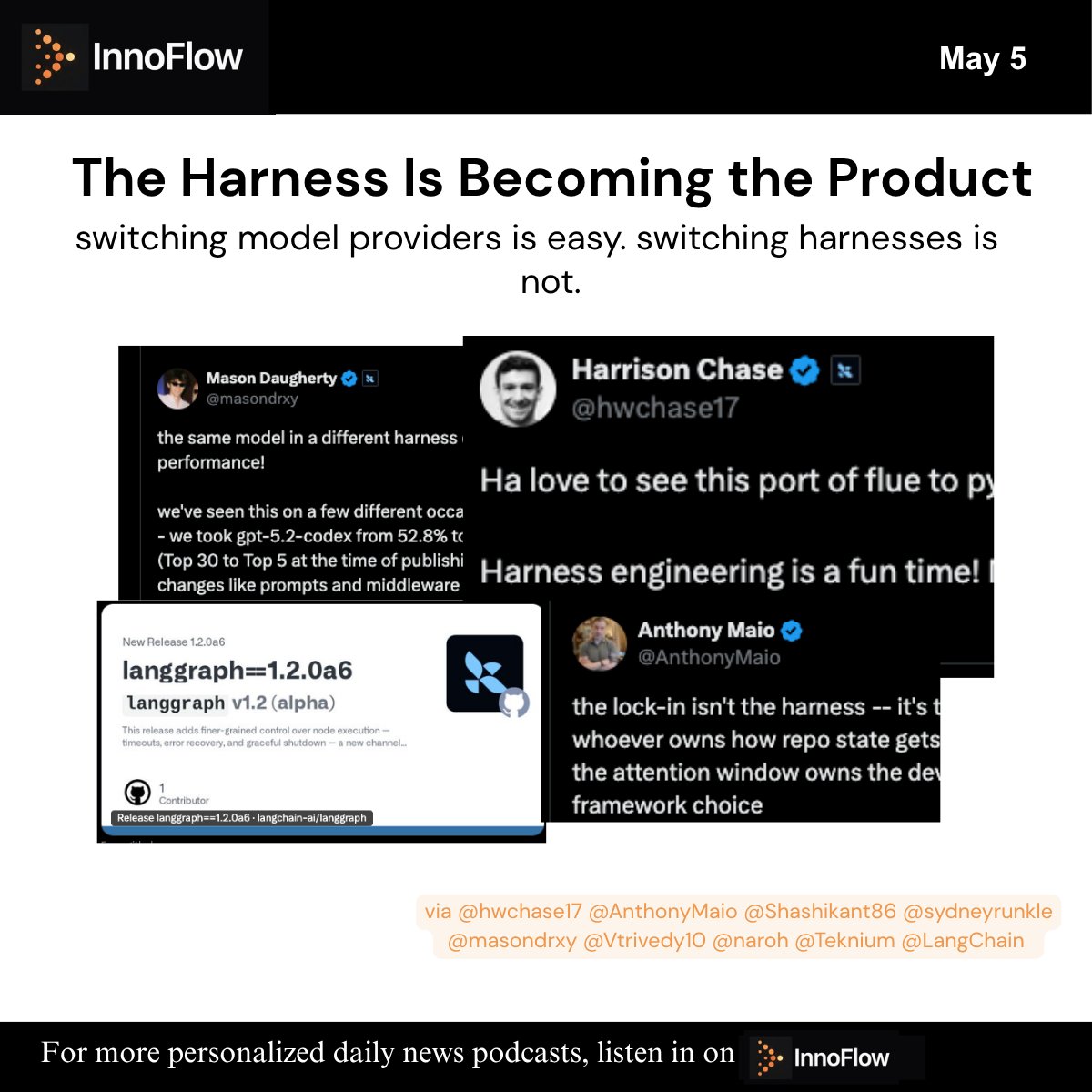
🗺️ Harness engineering is becoming the product boundary:
"switching model providers is easy. switching harnesses isnot." @hwchase17
@AnthonyMaio: Whoever owns how repo state gets compressed into the attention window owns the developer. regardless of model.
this week alone: PyFlue, LangGraph v1.2, deepagents-cli, and Hermes Kanban all shipped. different tools, same thesis.
startup signal: model-agnostic harness tooling, context pipeline infra
part of today's InnoFlow brief → innoflows.net/
via @hwchase17 @AnthonyMaio @Shashikant86 @sydneyrunkle @masondrxy @Vtrivedy10 @naroh @Teknium @LangChain
May 2

switching model providers is easy
switching harnesses is less so
model providers want to lock you in via harness
we need open harnesses!
12
May 5
Today's AI Map · May 5
🗺️ Harness engineering is becoming the product boundary
🗺️ Coding agent cost economics — Theo's 60M token burn
🗺️ Sierra raises $1B at $15B
3 signals worth your attention ↓
1
1
10
May 5
Sources ↑
① Harness: @hwchase17 @AnthonyMaio @naroh @Teknium
@Shashikant86 @sydneyrunkle @LangChain @Vtrivedy10
@masondrxy
② Token costs: @theo @cheatyyyy
③ Sierra: @btaylor
7
May 4
Today's AI Map · May 4
🗺️ ^^
① Codex left the coding box — OpenAI's agent just became a full work suite
② Grok 4.3 got cheaper. the benchmarks got messier.
③ Jack Clark: recursive self-improvement is more likely than not by 2028
Sources below ↓



1
1
1
20
May 4
① Codex left the coding box
(via @JamesZmSun @AriX @thsottiaux · Hacker News Daily Digest)
② Grok 4.3: cheaper but complicated
(via @ArtificialAnlys @teortaxesTex)
③ 60% on recursive self-improvement by 2028
(via @jackclarkSF · )
Full briefing → innoflows.net/
15
InnoFlowAI retweeted

May 1
Hatch a pet now in a codex app near you. It makes me actually more productive too by having the context follow me around as I multitask.
Please no comments on us having too much fun, we are also working on capability maxing 👀

242
52
1,520
242,514