
Joined July 2011
- Tweets 10,005
- Following 1,960
- Followers 1,699
- Likes 11,495
1,426 Photos and videos















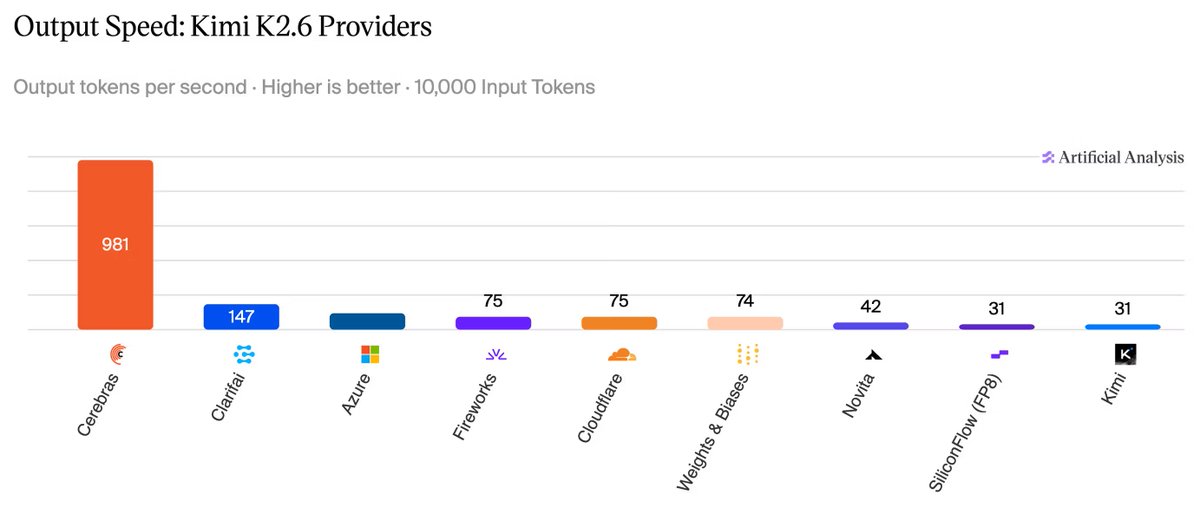
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
173
329
4,354
859,013
Jason ward retweeted

Apr 16
This is the first time I've ever seen an LLM operate a GUI as fast as a person, and it's surreal.
151
289
5,925
1,211,070
Cafe Compute went global this week 🌎 Two cities. Two continents. One big chip.
This week Cafe Compute hit San Francisco for @HumanXCo and London at @OpenAI's office for @aiDotEngineer Europe — fueling developers with coffee and the fastest AI on the planet.
Next stop: Miami for @aiDotEngineer Miami 🌴




6
6
31
5,664
Jason ward retweeted

Mar 26
What is disaggregated inference?
What does it do?
When does matter?
Who is it built for?
What Is Disaggregated Inference?
In the AI world: “Training” is how AI is made. “Inference” is how AI is used.
“Inference disaggregation” is a technique to divide and conquer inference compute.
Disaggregation separates inference into two stages: prompt processing, called “prefill,” and output generation, called “decode.”
Prefill - where the model processes your prompt. This is the part you type into ChatGPT, for example.
Decode - where the model generates new tokens one at a time to create the response that you read. This is the answer you get back from GPT.
Why Disaggregation Matters
These two stages have very different computational characteristics.
Prefill is natively parallel and requires little memory bandwidth.
Decode is inherently serial, and memory bandwidth intensive.
Prefill can be done quickly while decode accounts for the majority of time between hitting send and getting your full answer. This is because decode is a sequential process, each output token (word) must be generated before the next can begin.
Because the stages are so different, there's an opportunity to specialize, that is, to divide and conquer.
Rather than 1 processor doing both jobs, you can use 2 different processors, each with an architecture suited to its task. The result of this specialization is higher throughput and lower power consumption.
The Tradeoff
In computer architecture, there is no free lunch. The cost of specialization is lost flexibility.
Deploying separate hardware for prefill and decode locks in the ratio between them.
For example, out of every 100 racks, you might allocate 30 to prefill and 70 to decode. That ratio is fixed at deployment time.
When you can predict key workload characteristics, input/output ratio, KV cache size, cache hit rate, specialization delivers exceptional value. But it's fragile.
If workload characteristics shift, you end up with the wrong balance of prefill and decode hardware.
The result: stranded capacity, lower utilization, higher power draw, and higher costs.
The challenge of course, is that hardware deployments are meant to last for five or six years.
And that data centers are physically configured for the hardware deployed. Change is expensive.
When you can’t predict workload characteristics with high accuracy, then specialization through disaggregation will cost more and consume more power.
Who Benefits, Who Doesn't
Hyperscalers, who have fleets of different processors and who can move workloads across their fleet, will easily overcome the lack of flexibility in disaggregated solutions.
And they will benefit enormously from it. If the workload changes, they can direct that traffic to different processors in their massive fleets.
However, for enterprises and neoclouds, who have long depreciation schedules, and are locked into a specific vendor’s processor architecture, the rapidly changing AI landscape will be real challenge for disaggregated solutions.
The Bottom Line
If you know your workload well and are confident it won't change much, or if you have a large pool of diverse hardware to absorb shifts, disaggregation is a good choice.
If you can't predict your traffic or lack a flexible hardware fleet, a more general-purpose approach that handles prefill and decode on the same hardware is probably the safer bet.
Final thoughts
Disaggregated inference is still a new technology. I'm often asked what percentage of AI data centers will be built this way.
The honest answer is that no one knows yet. The battle between specialized solutions and more general ones are always interesting and difficult to predict.
But overall, with AI inference growing so quickly, I expect disaggregation will add to, rather than replace, the way we do inference today.
23
103
1,164
655,571
Jason ward retweeted
Mar 24
At GTC, we saw the crumbling of one of @nvidia most enduring moats.
It was a perception moat.
It was the perception that GPUs were all you need for AI.
Nvidia paid $20 billion for Groq. Acknowledging that for fast inference, the GPU alone couldn’t get the job done.
Nvidia’s newly announced inference solution requiring 5 distinct systems, comprised of CPUs, GPUs and LPUs, makes it clear that the GPU isn’t enough for fast inference, and put a stake through the heart of the notion that all you need for AI is the GPU.
What happened?
👍 Agentic coding took off.
👍 The market for chat is limited by the number of internet users.
👍 But coding tools are different. They are billed by the token and developers are using more all the time.
👍 Coding agents need fast inference - speed, measured by tokens per second per user.
👍 When inference is fast, developers are more productive, they ship faster, which in turn, generates more revenue.
Nvidia said in the keynote: “Fast tokens are smart tokens and valuable tokens.”
I will add the corollary. Slow tokens are not so smart tokens, and not so valuable.
Cerebras is the fastest inference hardware in the world.
16
12
103
10,063
Jason ward retweeted
Mar 17
NVIDIA's biggest GTC announcement was a $20 billion bet on the same problem we solved 6 years ago.
Their next-gen inference chip - not available yet - has 140x less memory bandwidth than @cerebras.
To run a single 2 trillion parameter model, you need 2,000 Groq chips.
On Cerebras, that's just over 20 wafers.
Even paired with GPUs, Groq maxes out at ~1,000 tokens per second.
We run at thousands of tokens per second today.
And every day. In production now.
Why?
When you connect 2,000 chips together, every interconnect has latency. Every cable has overhead.
It doesn't matter what your memory bandwidth is on paper if you're bottlenecked by the wiring between thousands of tiny chips.
We solved this with wafer scale.
One integrated system. Little interconnect tax.
Jensen told the world that fast inference is where the value is.
He’s right - it’s why the world’s leading AI companies and hyperscalers are choosing Cerebras.

73
71
745
157,075
Jason ward retweeted
Mar 17
GPUs are slow at AI inference because they hit the memory wall. Cerebras pioneered the SRAM based AI accelerator because GPUs were memory bandwidth constrained.
Let me explain.
There are two types of memory. Memory that can store a lot, but is slow.
And memory that is fast, but can’t store much per square milimeter of silicon.
The former is called DRAM (or HBM) and the latter is SRAM.
Graphics Processing Units use HBM.
In fact, graphics was the perfect use case for HBM.
It required a lot of data stored. But didn’t need it moved very often.
This is why graphics processing units use HBM.
But AI inference has different characteristics than graphics.
It moves data constantly from memory to compute.
To generate each token, it needs to move all of the weights from memory to compute. And for the next token, it needs to do it again. For every single token in the answer. Because HBM is slow, moving data is time consuming.
The GPU is waiting for data to get to it.
It sits idle. Pulling power.
Doing no work.
Cerebras chose to use SRAM so we could move data from memory to compute faster. Not a little bit faster but more than 2,600 times faster than NVIDIA Blackwell GPUs. As a result, we can generate tokens faster 15 times faster. This is why we are the fastest in the world.
But what about the weakness of SRAM? QSurely there is a tradeoff. SRAM can’t store very much data per square millimeter. This is why Cerebras went to wafer scale.
By building a chip the size of a dinner plate, a chip that is 58 times larger than the largest GPU, Cerebras could stuff it to the gills with SRAM. We couldn’t make SRAM store more data per square millimeter, but we could provide more square millimeters by building a bigger chip.
If you build a solution with little chips and try to use SRAM you need to link thousands of them together to support a larger model. There simply isn’t enough room on the little chips for lots of SRAM and lots of compute cores.
Thousdands of little chips connected together with cables, is slower and more power hungry than if all that traffic stayed on a big chip, or even several big chips.
And since communication between chips is slow, and communication on chip is fast, lots of little chips is slower at inference as well.
31
31
368
36,386

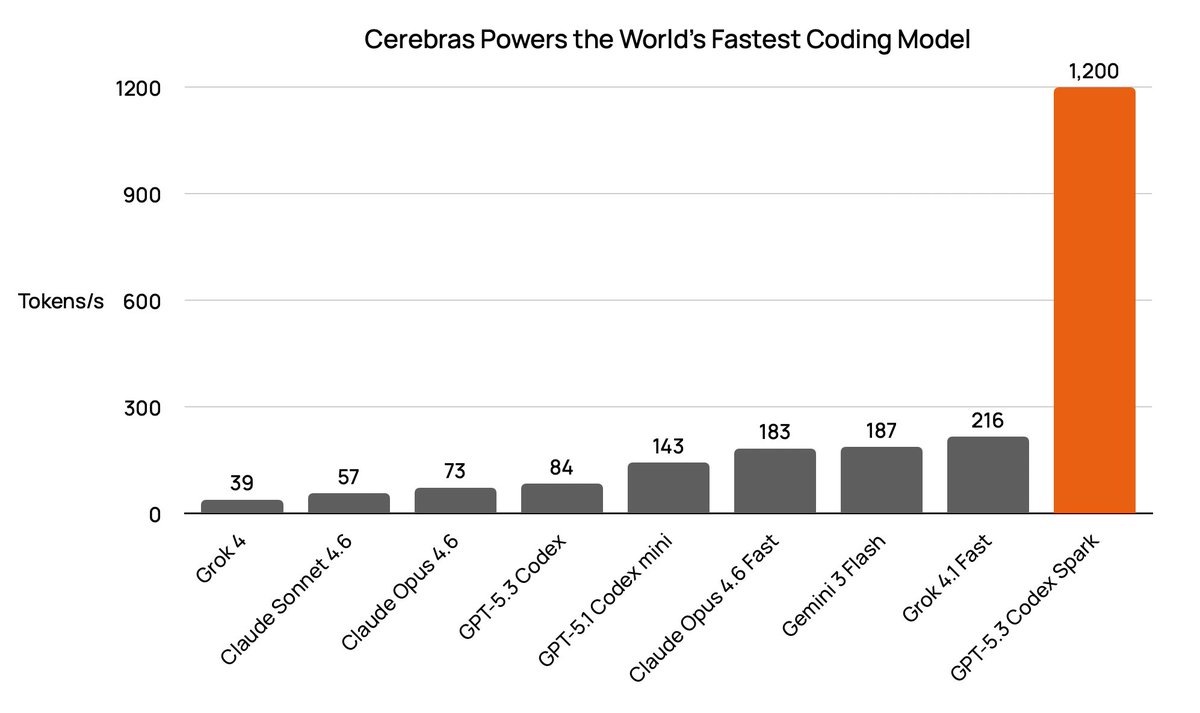
Our coding workflows were designed to accommodate slow inference. @OpenAI's Codex Spark powered by @cerebras changes the game.
Here's how we make the most out of 1,200 tokens per second, with @MilksandMatcha.
11
14
108
13,380
gpt-oss-120b is one of the most-used models on Cerebras Inference.
We sat down with @ml_angelopoulos from @arena and @SarahChieng to break down its strengths, weaknesses, and where it's outperforming. Here's what he's seeing.
9
8
109
13,082
Jason ward retweeted
Feb 25
Love the smell of power plant construction in the morning.
It’s the smell of AI.
Little is better than the sight of giant gas turbines being installed.
A 300MW power plant under construction.
Hundreds of jobs for the local community.
And 100MW of power for a new data center.

2
3
36
2,793

Feb 18

OpenAI may have just paid $10B to acquire OpenClaw
@lexfridman asked @steipete how much money he was getting offered and this was his answer…
Community note
Steinberger talks about the Cerebras deal, which the author misleadingly uses to imply open claw was acquired for $10B.
However, Steinberger only talks about how combining the tech will have advantages - he doesn’t imply the acquisitions are of similar size.
x.com/JoshKale/statu…
128
Jason ward retweeted
Feb 12
Just one month after announcing our partnership with @OpenAI, we’re launching our first model together: OpenAI Codex-Spark, powered by @cerebras.
Codex-Spark is built for real-time software development.
In coding, responsiveness is the product.
It is not a nice to have.
Codex-Spark is optimized for targeted code edits, logic revisions, and frontend iteration. It gives developers near-instant feedback so they can stay in flow.
Powered by the Cerebras Wafer-Scale Engine, it runs at over 1,000 tokens/s. That speed fundamentally changes the experience.
We did not build this to win a benchmark.
We built it so developers could move faster.
I’m proud of how quickly the OpenAI and Cerebras teams have brought this to life.
This is what fast execution looks like - deep engineering collaboration, rapid iteration, and shipping real products developers can use today.
We are just getting started.
When inference is fast, entirely new markets open up.
We plan to lead that shift with our partners at OpenAI.

79
114
1,811
174,373
Jason ward retweeted

5 Oct 2024
This was the golden era of football 😍 x.com/NalaThokozane/status/1…
188
2,896
21,308
1,339,007



Jason ward retweeted

30 Mar 2024
Never forget one of the swaggiest putts of all-time 💯
119
1,522
21,556
1,487,846