
Research Scientist @ Gemini Multilinguality. Learning, Languages, Evals, C . Previously MT@Microsoft and CMU. Opinions are my own.
Joined March 2009
- Tweets 1,588
- Following 2,037
- Followers 2,482
- Likes 2,309
12 Photos and videos

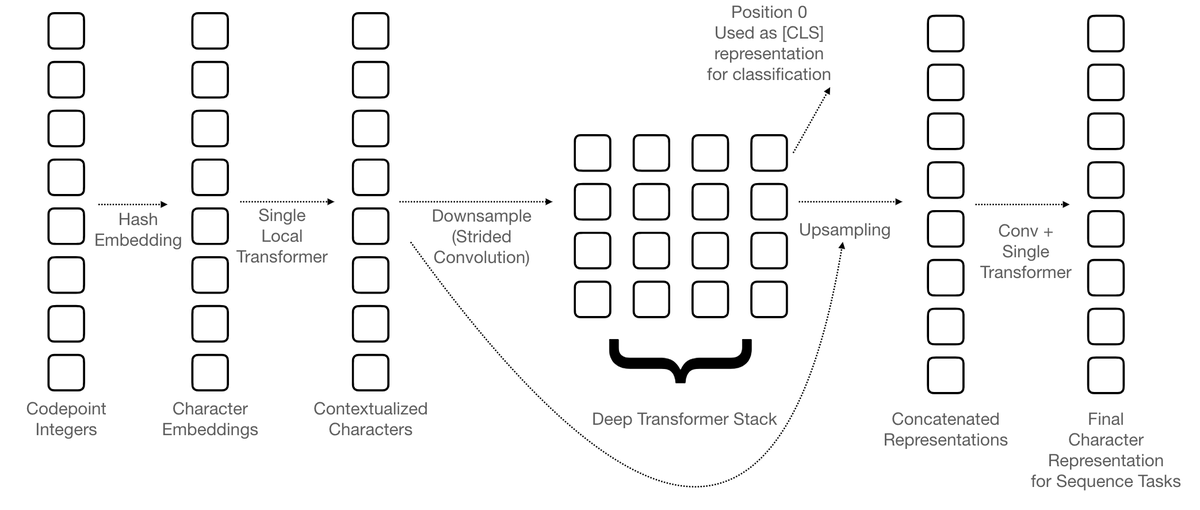
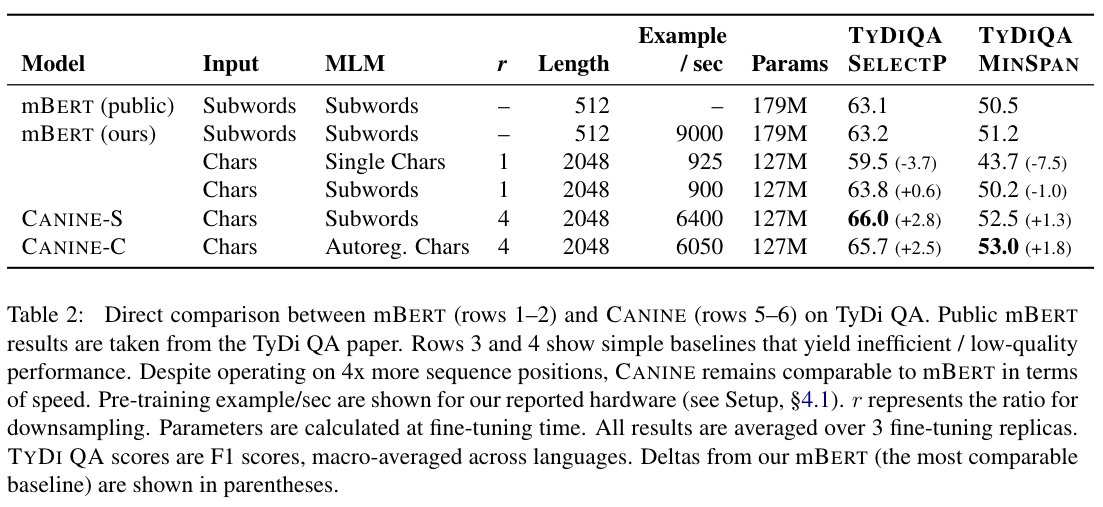



Jonathan Clark retweeted

Apr 20
I am hiring for 2 positions focused on Gemini and information tasks in Mountain View. One role is particularly focused on pushing the frontier of factuality of LLMs.
We will consider applications for 1 week and then interview:
job-boards.greenhouse.io/dee…
google.com/about/careers/app…
5
21
297
29,257
Jonathan Clark retweeted

22 May 2025
DumPy: Like NumPy except it's OK if you're dum
25
81
1,554
213,118
Jonathan Clark retweeted
18 Dec 2024
Today, we have released a benchmark and a corresponding leaderboard titled "FACTS Grounding" in collaboration with @kaggle. 1/

Introducing FACTS Grounding. A new benchmark we’re launching with @GoogleDeepMind to evaluate LLM’s factual accuracy on over 1700 tasks. 🧠📐

ALT Introducing FACTS Grounding. A new benchmark we’re launching with @GoogleDeepMind to evaluate LLM’s factual accuracy on over 1700 tasks. 🧠📐
9
18
80
28,732
Jonathan Clark retweeted

13 Nov 2024
Catch our Google Translate Research team at #EMNLP #WMT24! The team will present 9 papers on step-by-step decoding, mitigating metric bias within MBR decoding ( MBR dataset release), improved human data collection and automatic metrics (MetricX: winner of WMT Metrics Task).
1
1
31
1,985
Jonathan Clark retweeted

4 Nov 2024
🚀 Join the Gemini Multilinguality team @GoogleDeepMind 🌐 We’re looking for researchers passionate about making LLMs helpful for all. Dramatically improve model quality, coverage, and cultural relevance across hundreds of languages. #NLProc #MultilingualAI #i18n #LLMs boards.greenhouse.io/deepmin…
4
36
182
28,275
Jonathan Clark retweeted

17 Oct 2024
Exciting news! As of today, the Inuit language of Inuktut will be available on Google Translate - marking the first Canadian Indigenous language on the platform. Tunngasugit! | ᑐᙵᓱᒋᑦ (Welcome!) 🎉
Huge thanks to @ITK_CanadaInuit for their invaluable guidance and collaboration.
Learn more on our blog: blog.google/intl/en-ca/compa…
23
46
4,999
Jonathan Clark retweeted

27 Jun 2024
Excited to announce that 110 languages got added to Google Translate today! Time for context on these languages, especially the communities who helped a lot over the past few years, including Cantonese, NKo, and Faroese volunteers. Also, a 110-language youtube playlist. 🧵
14
56
232
49,537

As part of @Google's 1,000 Languages Initiative, a commitment to support the 1,000 most spoken languages, & w/help of our PaLM 2 LLM, we're adding support for 110 new languages (spoken by 614M people) to Google Translate (now supporting 243 languages). 🎉
blog.google/products/transla…
42
82
458
134,486
Jonathan Clark retweeted

20 May 2024
I will be at NAACL in-person, and co-organizing the AmericasNLP workshop there!
#NLProc #NAACL2024
20 May 2024

The AmericasNLP Workshop will be co-located with NAACL on June 21, 2024! ✨✨
We are excited to see you all in Mexico City!
More here: 2024.naacl.org/program/works…
4
41
3,710
Jonathan Clark retweeted

1 May 2024
Absolutely unhinged.
When @jasonbaldridge started this in 2021 he would enthusiastically show us weird new images that he took. I thought it was just some weird phase that would fizzle out, but I'm very happy to be wrong, and that it resulted in such a high quality dataset!

1 May 2024

We're excited to announce DOCCI: A new dataset designed to advance vision-language research. DOCCI features 15k images with detailed descriptions crafted to capture complex visual concepts – spatial relations, counting, text and entities more.
arxiv.org/pdf/2404.19753

2
13
106
19,913
Jonathan Clark retweeted
11 Apr 2024
New paper alert!
Designing reliable human evaluation is both crucial and difficult. Human raters can exhibit different behaviors when rating NLG outputs. These differences are not generally due to a rater performing the task incorrectly, but rather due to differences in harshness or leniency between raters: a Minor error to one rater may be a Major error to another. Consequently, decisions around which raters rate which items can alter the final system ranking.
In our new paper, we analyse the impact of rater assignment on the final system ranking and show how you can design a replicable, reliable human evaluation by assigning the right raters to the right items.
Take a look: arxiv.org/pdf/2404.01474.pdf

2
16
73
8,590
Jonathan Clark retweeted

12 Jan 2024
ACL has removed the anonymity period.
This means that ACL submissions can be posted and discussed online at any time, although extensive PR is discouraged.
aclweb.org/adminwiki/images/…

3
85
342
87,734
Jonathan Clark retweeted

13 Dec 2023
Today at #NeurIPS2023, If you want to lean more about:
1. Robustness of detectors and watermarks to paraphrase attacks (spoiler alert: needs improvement).
2. An alternative detection approach using simple retrieval methods.
and ...
24 Mar 2023

To detect text written by LMs like #ChatGPT, many methods have recently emerged: DetectGPT, watermarks, GPTZero.
We present a paraphrasing attack that can drop their detection rates to <10%.
To defend against it, we propose detection with retrieval.
arxiv.org/abs/2303.13408
🧵👇

1
4
21
3,719
Jonathan Clark retweeted

10 Dec 2023
Excited to receive an Outstanding Paper award for this work at @emnlpmeeting! Thanks to my co-authors George Foster and @markuseful! Updated version available here: aclanthology.org/2023.emnlp-…
24 May 2023

LLM-based metrics like GEMBA predict many ties, but the way that ties should be handled in Kendall’s tau for meta-evaluating metrics has been a longstanding issue. We propose an update to the meta-evaluation methodology to handle ties.
arxiv.org/pdf/2305.14324.pdf

4
11
69
11,953
Jonathan Clark retweeted
8 Dec 2023
Our work on cross-lingual and multilingual attribution will be presented at #EMNLP2023 in Singapore!
We have also released our dataset of ~10k 3-way annotations over 5 typologically diverse languages.
Arxiv: arxiv.org/abs/2305.14332
Dataset: github.com/google-research/g…
24 May 2023

We all want accurate responses from our QA systems, and this need becomes especially vital when interacting with text in languages unfamiliar to us, rendering answer verification reliant on translation. This challenge is particularly felt by speakers of low-resource languages.
1
9
23
5,062
Jonathan Clark retweeted

21 Nov 2023
Excited to be presenting our work on
**Evaluating and Modeling Attribution for Cross-Lingual Question Answering** at #EMNLP2023 in Singapore.
Updated Paper: arxiv.org/abs/2305.14332
We're also releasing the XOR-AttriQA dataset: github.com/google-research/g…
🧵
24 May 2023

Despite the fantastic progress we've seen recently in cross-lingual modeling, the best systems still make a lot of factual errors.
To address this, here is our work on 🚨 Evaluating and Modeling Attribution for Cross-Lingual Question Answering 🚨
#1 Attribution Evaluation: Our work is the first to study attribution for cross-lingual QA. We collect attribution data in 5 languages (Bengali, Finnish Japanese, Russian, and Telugu)
With this data, we find that even state-of-the-art cross-lingual open-retrieval QA systems (e.g. CORA) lack attribution. Additionally, we find that passages retrieved cross-lingually contribute only moderately to the attribution level of the system, calling for progress in this area.
#2 Attribution Detection Modeling: We experiment with a wide range of attribution detection models to address this issue.
We find that NLI models and PaLM 2, fine-tuned on a very small number of attribution examples (~100), reach above 90% accuracy on attribution detection, leading to significantly improving the attribution level of CORA.
Attribution is one of the most promising directions to improve trust in NLP systems: Our results show the potential of using attribution detection models to improve it for cross-lingual question answering.
Work done while interning at Google Research last summer with @johnwieting2 @JonClarkSeattle @seb_ruder @tmkwiat @liviobs @roeeaharoni @jonherzig @cindyxinyiwang
Thanks to @dipanjand, Michael Collins, Vitaly Nikolaev, @jasonriesa, and @pat_verga for supporting the project and to @AkariAsai for fruitful discussions about CORA.
Paper available here: arxiv.org/abs/2305.14332
2
6
22
4,158
Jonathan Clark retweeted
16 Oct 2023
Excited to announce the First Conference on Language Modeling, to be held in approximately a year from now.
Please let us know if you are interested or have any feedback on the conference: colmweb.org/survey.html
16 Oct 2023

Introducing COLM (colmweb.org) the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models.
Submissions: March 15 (it's pronounced "collum" 🕊️)

1
13
73
11,127
Jonathan Clark retweeted

16 Oct 2023
Introducing COLM (colmweb.org) the Conference on Language Modeling. A new research venue dedicated to the theory, practice, and applications of language models.
Submissions: March 15 (it's pronounced "collum" 🕊️)
28
416
1,669
505,618
Jonathan Clark retweeted
25 Sep 2023
Have you ever wanted a LangID model that works on 1500 languages? check out FUN-LangID: github.com/google-research/u… !
1
8
49
9,371
Jonathan Clark retweeted

12 Sep 2023
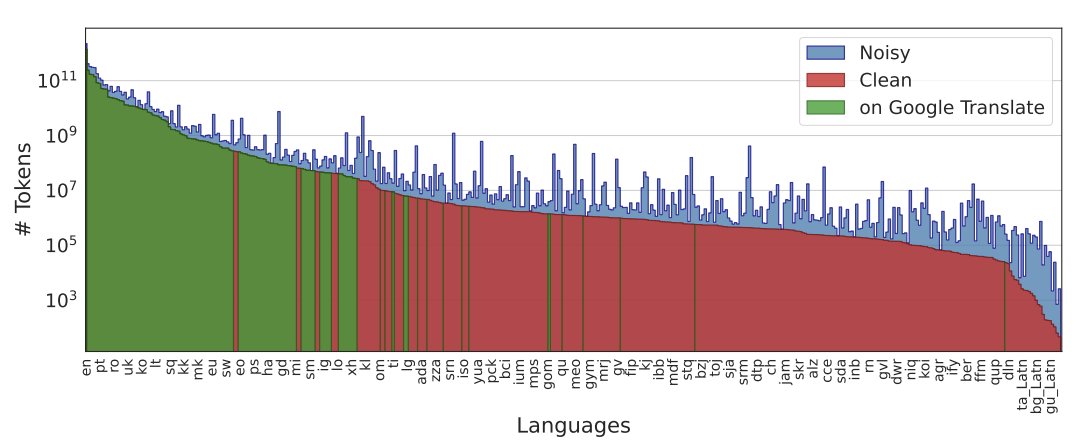
Excited to announce MADLAD-400 - a 2.8T token web-domain dataset that covers 419 languages(!).
Arxiv: arxiv.org/abs/2309.04662
Github: github.com/google-research/g… 1/n
24
129
770
231,060