







🚀 Launch today: Kog generates 3,000 output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-in…
📖 Monokernel deep dive → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor-p…
read the thread 👇
16
41
268
6,162,508
Kog retweeted

Jun 5
👀 Watch out @cerebras and @GroqInc - mystery model outputs 3000 tps on standard GPUs. 🔥
Here is a comparison between Kog Laneformer-2B & Google Gemma3n-4B, both non-reasoning with same prompt. Laneformer @ 3000 tps finished in 3s and Gemma 3n 4B took 43s.

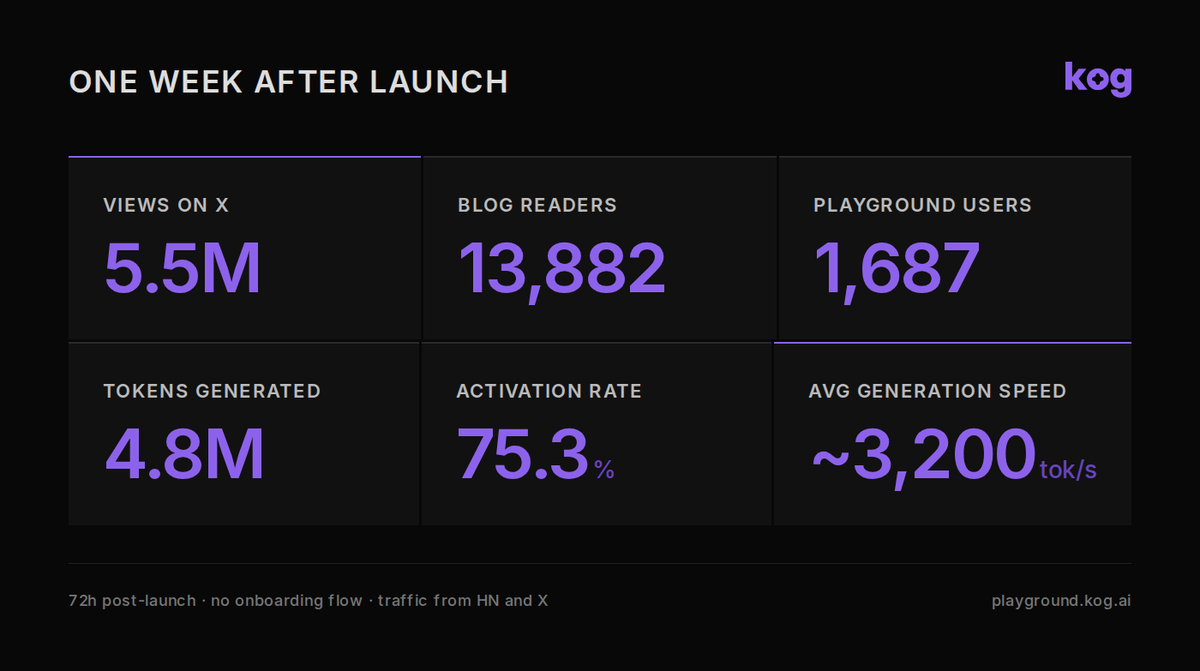
3,000 tokens/s inference speed pulls developers in. Our launch last week proved it.
Our post hit the Hacker News front page and stayed for 12 hours.
13,800 engineers read the Kog Labs technical breakdown.
2,240 developers tested our live playground, with a whooping 75% activation rate.
More than 4 million tokens generated across thousands of conversations at an average generation speed of ~3,200 tokens/s.
When inference is fast enough to feel different, developers come and build.
Read our technical blog posts and test it by yourself.
Try the playground → playground.kog.ai
💥Why 3,000 tokens per second matters and how we got there → blog.kog.ai/real-time-llm-in…
📖 Deep dive into the monokernel architecture on AMD MI300X → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism, our approach to removing inter-GPU communication overhead → blog.kog.ai/delayed-tensor-p…
3
4
23
8,386
3,000 tokens/s inference speed pulls developers in. Our launch last week proved it.
Our post hit the Hacker News front page and stayed for 12 hours.
13,800 engineers read the Kog Labs technical breakdown.
2,240 developers tested our live playground, with a whooping 75% activation rate.
More than 4 million tokens generated across thousands of conversations at an average generation speed of ~3,200 tokens/s.
When inference is fast enough to feel different, developers come and build.
Read our technical blog posts and test it by yourself.
Try the playground → playground.kog.ai
💥Why 3,000 tokens per second matters and how we got there → blog.kog.ai/real-time-llm-in…
📖 Deep dive into the monokernel architecture on AMD MI300X → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism, our approach to removing inter-GPU communication overhead → blog.kog.ai/delayed-tensor-p…
1
7
11
7,655
Kog retweeted

May 29
Incredible!
🚀 Launch today: Kog generates 3,000 output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-in…
📖 Monokernel deep dive → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor-p…
read the thread 👇
1
2
18
2,973
Kog retweeted

May 29
I had to test it myself to believe this unreal inference speed.
3,000 tokens/s for 1 user on standard datacenter GPUs.
They leveraged a hidden efficiency gap in how GPUs generate tokens.
@Kog__AI just achieved 3,000 tokens/s on 8× AMD MI300X GPUs and 2,100 on 8× NVIDIA H200 (FP16, no speculative decoding). Their tech preview is on a 2B model, and they show how their techniques will scale to large frontier MoE models at similar speeds.
That's a huge number because normal low-batch GPU decoding for 2B to 8B models is usually closer to 100 to 300 tokens/s per request, so Kog is claiming something like a 10X to 30X jump in the speed one user actually feels.
Their trick: they are getting the speed by treating LLM decoding as a memory streaming problem, not mainly a math problem.
For 1 user at batch size 1, the GPU is not doing big, efficient matrix-matrix work like in training or large-batch serving; it is repeatedly pulling the model’s active weights from high-bandwidth memory for each new token, so speed depends on how smoothly those weights keep flowing.
Normal inference stacks keep breaking that flow.
They run many separate GPU programs for different parts of the model, move intermediate results through memory, wait at synchronization points, talk back to the CPU for scheduling or sampling, and then repeat this token after token.
Kog’s answer is to co-design 3 things that are usually tuned separately: the runtime, the low-level GPU code, and the model architecture.
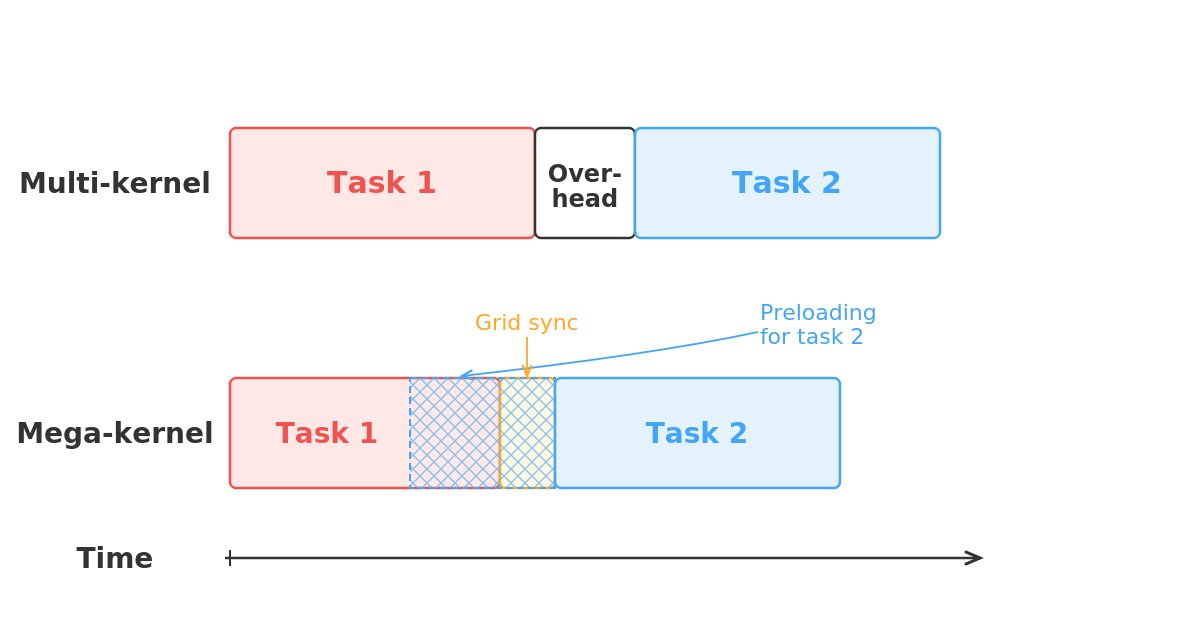
The biggest engineering move is the monokernel, where the whole decode pass runs as 1 persistent GPU-resident program, including sampling, so the system does not keep stopping for kernel launches, CPU scheduling, and intermediate memory round trips.
They also rebuilt synchronization, because their own measurements say grid sync was eating around 35% of token-generation time; instead of making every compute unit wait at a broad barrier, each unit waits only for the exact data it needs.
On AMD MI300X, they also map memory access around the chiplet layout, because memory latency changes depending on which die makes the request.
Then their Laneformer model uses Delayed Tensor Parallelism, which lets cross-GPU communication happen in the background instead of blocking every layer.
8
16
87
13,086
Kog retweeted
May 29
The monokernel idea was one of their powerful trick.
Instead of launching many small GPU programs for normalization, attention, feed-forward layers, sampling, and communication, Kog keeps the whole decode loop inside 1 long-running GPU program.
With a monokernel, weights for the next stage can start loading while the current stage is still finishing, so the GPU behaves more like a pipeline and less like a machine constantly being paused and restarted.
If a Transformer layer is broken into many small GPU programs, the system can burn a scary amount of its budget just stopping, starting, syncing, writing, reloading, and waiting, before doing useful token generation.
The monokernel tries to remove that stop-start behavior.
Once it begins, it stays resident on the GPU and handles the full sequence, including prefill, decode, sampling, tensor-parallel communication, reductions, and internal state, without going back to the CPU for every little step.
The big gain is that weight streaming stays continuous.
For batch-size-1 inference, the GPU mostly needs to stream active model weights from high-bandwidth memory into compute units as smoothly as possible.
Read more about their “monokernel” implementation here.
blog.kog.ai/building-a-singl…

1
2
7
1,080

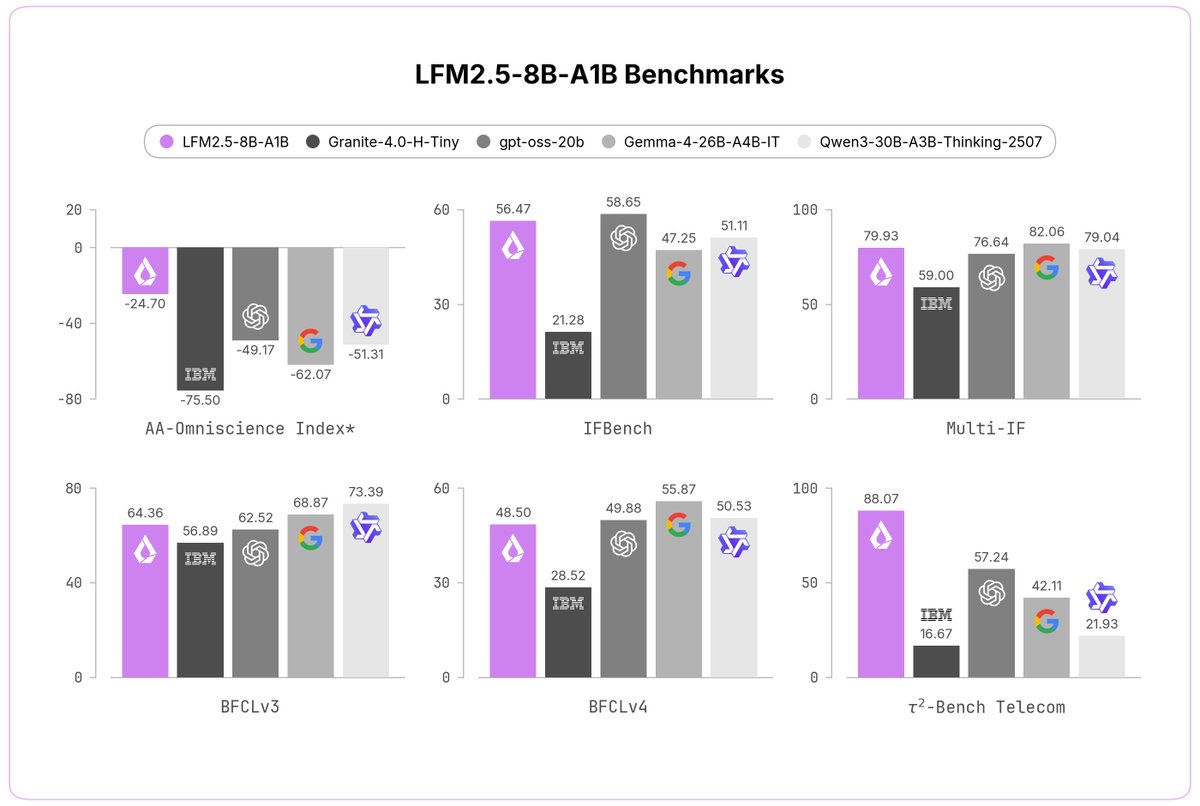
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
140
507
3,839
1,318,222
Kog retweeted

May 28
Kog officially launched today!
Super-fast AI inference speed on standard GPUs, 30x faster than ChatGPT. And it's European deep tech.
Check it out 👇
🚀 Launch today: Kog generates 3,000 output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-in…
📖 Monokernel deep dive → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor-p…
read the thread 👇
18
36
416
3,379,086
🚀 Launch today: Kog generates 3,000 output tokens/s per single request, on standard datacenter GPUs.
We are bringing real-time LLM inference to hardware that companies already run in production.
The speed previously associated with purpose-built silicon is now delivered on NVIDIA H200 and AMD MI300X.
Today, we are opening our Tech Preview with a 2B coding model, with large frontier MoE support coming next.
Try our Playground → playground.kog.ai
💥 Why that matters, and how we did it → blog.kog.ai/real-time-llm-in…
📖 Monokernel deep dive → blog.kog.ai/building-a-singl…
📖 Delayed Tensor Parallelism research → blog.kog.ai/delayed-tensor-p…
read the thread 👇
16
41
268
6,162,508
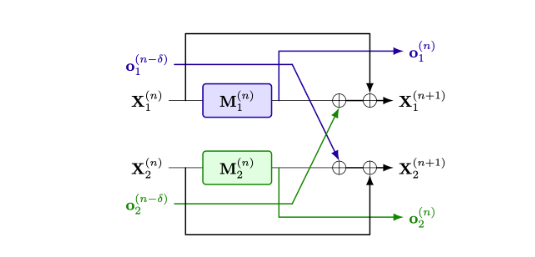
We also introduce Delayed Tensor Parallelism (DTP) to minimize inter-GPU communication wait-time.
Standard tensor parallelism ends each module with a blocking all-reduce operation.
DTP is a Transformer architecture variant that makes those all-reduce operations asynchronous, hence reducing inference communication overhead to 0.
DTP matches the quality of standard TP, and edges out similar methods like Ladder Residual and PT-Transformer in our setting.
📖 Full post → blog.kog.ai/delayed-tensor-p…
1
3
10
1,535
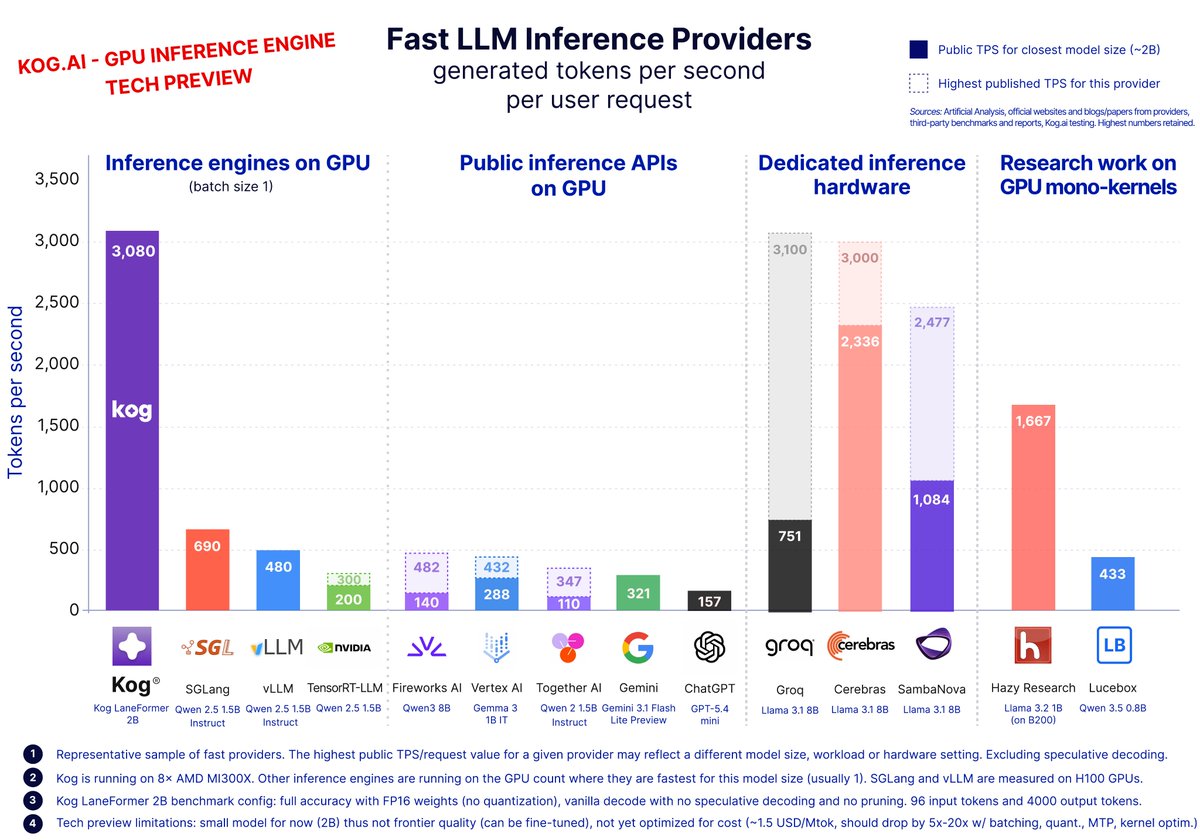
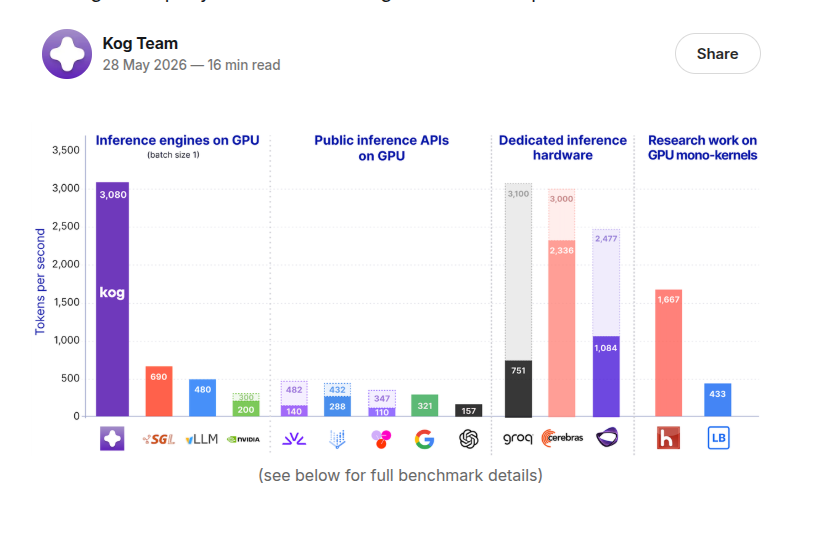
We expect our thousands-token-on-GPU speed results to scale way past our 2B-parameter preview model.
Single-request decoding depends on active-parameter count per token, not total parameters, and current frontier MoE models only activate a fraction.
For instance, DeepSeek-V4-Flash has 284B total, 13B active. With its default FP4/FP8 quantization, the math checks out for 1,000 to 3,000 tokens/s on current datacenter GPUs.
We plan to support frontier MoE models in Kog Inference Engine in the coming months, on GPU hardware enterprises and sovereign-AI builders already own. No proprietary silicon needed.
🚀 Try it → playground.kog.ai
👀 Take a deeper look at our claims → blog.kog.ai/real-time-llm-in…
🛠️ Build with it → kog.ai (building fast agents? We're taking design partners!)
1
2
10
1,308
Kog retweeted
May 15
Learn how Kog AI utilizes creative GPU Engineering optimizations to build a real-time LLM inference engine on AMD Instinct GPUs.
This is the video recording of our talk at AMD AI DevDay 2026 in SF two weeks ago.
Ping me directly for the slides 😊
Feedbacks welcomed.
youtube.com/watch?v=ndSA9T5y…
1
2
363
Kog retweeted

Apr 30
🚀 Inspired to be at @AMD AI Dev Day in San Francisco today where the AI community is converging to shape what’s next.
The energy is exceptional. Every keynote, demo, and conversation reinforces a deeper truth: AI has moved beyond advancing computing. It is now redefining human potential and possibility at global scale. At AMD, we’re proud to be at the center of this transformation, accelerating it with open, powerful, and accessible technology.
A personal highlight was spending time with visionary founders and CEOs including @ComfyUI, Midjourney, @AnythingLLM, @Kog__AI, Starcluster and many more. These builders are turning bold ideas into real-world impact, and it was an honor to put Ryzen AI Max powered @HP ZBook mobile workstations in their hands so they can move even faster.
This is leadership in the AI era: empowering creators, fueling ambition, and turning visionary ideas into scalable reality.
The future isn’t coming. It’s being built right here, right now. Excited to keep pushing the boundaries alongside this incredible community.



8
13
76
22,406

We want to extend a huge thank you to our #AIDevDay speakers and workshop hosts! 🤝 We are committed to building with you.
@danielhanchen, @UnslothAI
@JunchenJiang, @tensormesh
@RyanLeeMiniMax
@BanghuaZ, @thu_yushengsu, @RadixArk
@clattner_llvm, @Modular
@Stanford CS students Natalia Pahlavan, Laasya Konidala, Annmaria Antony
@TCarambat, @AnythingLLM
@gaeldelalleau, Augustin Verneuil, @Kog__AI
Kevin Cochrane, @Vultr
@QuentinAnthon15, @ZyphraAI




7
10
43
5,846

A great week in San Francisco for the Kog team at AMD AI DevDay 2026.
Presenting some of our latest work was a real pleasure, and the conversations around research, infrastructure, and product were especially valuable.
One signal came through very clearly.
Inference is moving much closer to the center of the conversation.
That gave us even more conviction that we are building in the right direction.
More to come soon.



2
1
1
82