
Joined July 2023
- Tweets 33
- Following 82
- Followers 8
- Likes 1,219
1 Photos and videos

Cookie Master retweeted

10h
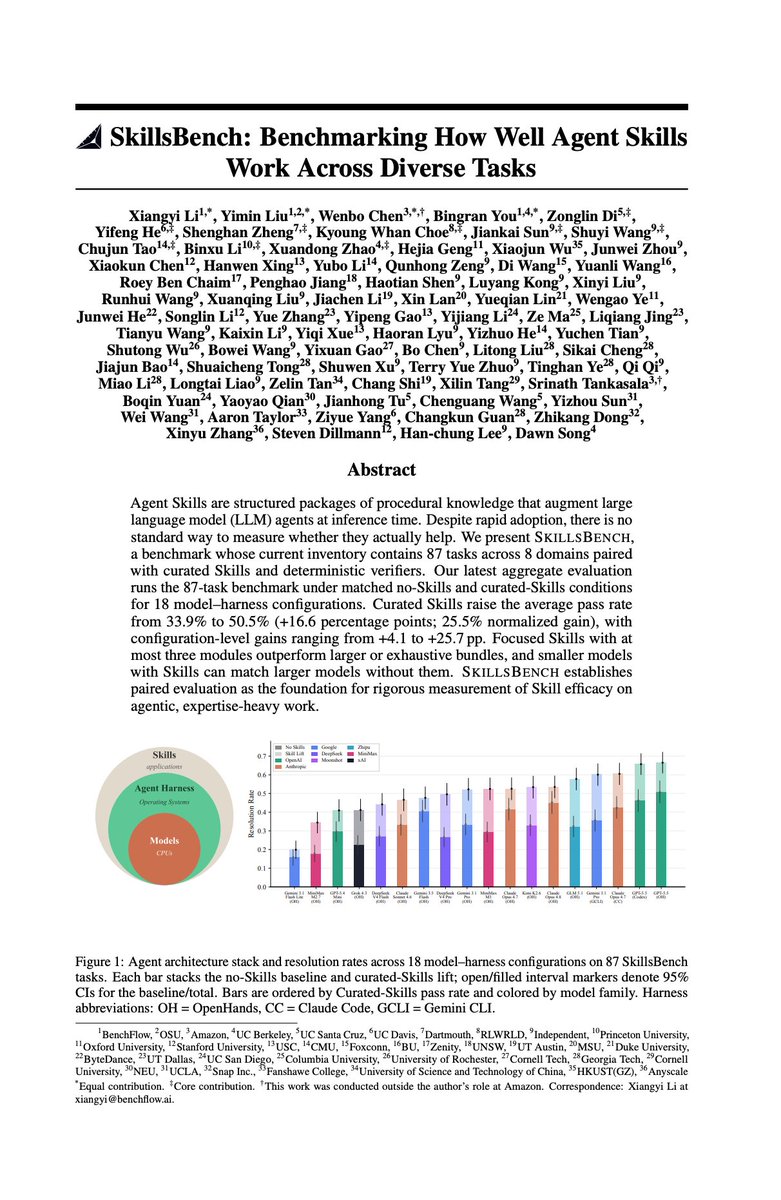
A big pain point in using AI benchmarks is encountering errors after its first release. Today, we're releasing SkillsBench 1.1, the first benchmark for how well AI agents use skills, now audited end to end and verified error-free. Prof. @dawnsongtweets joins 1.1 as advising author.
We worked through every task with several frontier labs to eliminate the errors in the previous version. We also added new tasks, moved the ones with external dependencies into a separate set so the core suite runs clean, and expanded coverage to more models.
Capability is climbing fast. The best with-skills resolution rate rose from ~36% (Claude Sonnet 4.5, Sep 2025) to 67% (GPT-5.5, May 2026), about 1.9 points per month. The frontier is hill-climbing SkillsBench fast.
The right skills still matter. Across the fleet, curated skills lift resolution rate by 16.6 points on average (33.9% → 50.5%), and by as much as 25.7 points for a single model. The top configuration is GPT-5.5 on OpenHands at 67.3%.
By popular demand (thx Nate @cursor_ai), we're now tracking skills invocation: how often an agent actually uses the skills it's given. Recent flagship configurations invoke them 90–99% of the time (Codex 99%, OpenHands GPT-5.5 92%, Gemini CLI 90%), versus roughly 50% for older setups.
Also new in 1.1: @OpenHands joins as a fourth harness, alongside Claude Code, Codex, and Gemini CLI; a rebuilt leaderboard with refined categories, subdomain skill rankings, and Skill Lift; and native task . md on BenchFlow, with multi-scene environments and rollout branching. We also partnered with @k_dense_ai to add scientific skills to some science tasks.
One implication for deployment: skills can substitute for scale. GLM 5.1 with skills (58.4%) outperforms Opus 4.8 without (45.7%). A smaller model with the right procedural knowledge can beat a larger one running without it.
Huge thanks to @nick_kango @ivanleomk @kaggle @GoogleDeepMind for hosting a launch event with us. Thanks for everyone who's come on May 27!
Also thanks to our partners @gneubig @OpenHandsDev @ivanburazin @daytonaio @jackminong @johannes_hage @PrimeIntellect @TimothyKassis @k_dense_ai for providing support in credits, compute, and skills.
SkillsBench live leaderboard will also come to @ValsAI. Many people have told us they use SkillsBench as an index to measure models' agentic capability over diverse and high GDP value domains. Great work on Valkyrie as well! @ Jarett @nikilravi @langstonnashold @RayanKrishnan
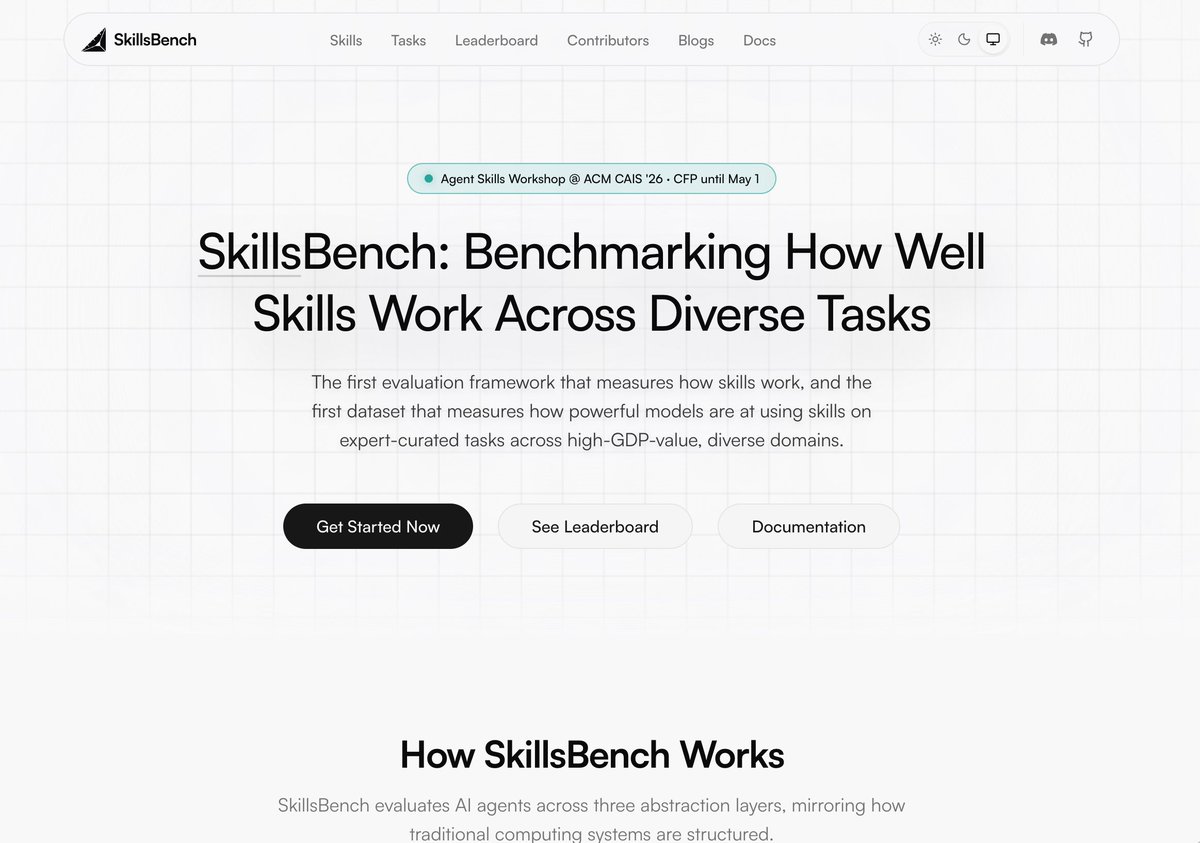
SkillsBench is fully open-source. Explore the leaderboard and tasks, read the docs, or contribute your own skill set or harness and join the leaderboard. 🧵

11
24
88
9,710


When an AI agent succeeds, was it the model or the skill it was given?
Launching today with @xdotli and @benchflow_ai — the BenchFlow AI Agent Skills Community Hackathon. Build skills that lift agent capability without crossing safety boundaries.
3
10
56
11,966
Cookie Master retweeted
May 3
Extremely excited to see SkillsBench being the benchmark repo that is fastest to reach 1k GitHub stars
Within 2 months of release we've got:
* 1.1k stars
* 40 indexed benchmarks (60 from our own tracker)
* 65% agent skills research now cite our paper
* cited 4 times by top model labs' release
All while being 1) first time writing a paper and 2) working full-time as a founder.
Check out our repo and how we did it in comments

5
2
43
1,709
Cookie Master retweeted

🎉🎉🎉
caisconf.org/program/2026/pa…
CAIS's 2026 accepted papers!
61 accepted papers, from 110 organizations globally
Papers come equally from industry and academia
1
15
43
8,356
Cookie Master retweeted
Apr 22
The team from SkillsBench is hosting the first ever Agent Skills 26' workshop at ACM CAIS conference.
We are calling for papers until May 1, submit: agentskills-workshop.org/
1
8
33
3,879
Cookie Master retweeted
Apr 14
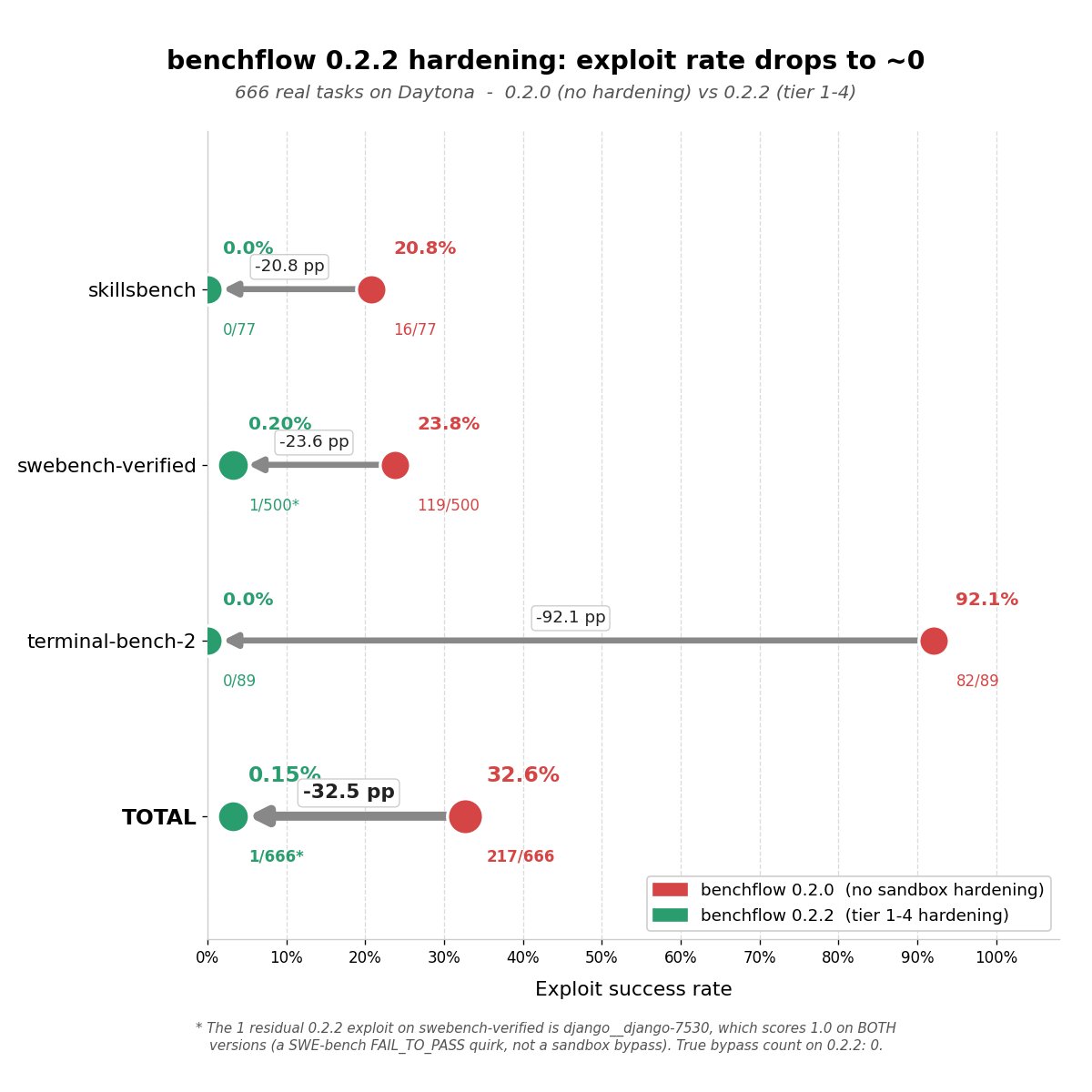
Introducing BenchFlow 0.2.2 📐🧵
We replicated two new research findings showing AI agent benchmarks are broken at the runtime layer — then shipped the defense in the latest release.
🔬 BenchJack and Terminator (@BerkeleyRDI, @dawnsongtweets, @MogicianTony @MangQiuyang @alvinkcheung @lihanc02): 8 major benchmarks exploitable at ~100% via one-line conftest hooks, planted PATH binaries, and leaked answer keys.
🕵️ Meerkat (@adamlsteinl, @RICEric22 @davisbrownr @HamedSHassani @AI4Code): 415/429 Terminal-Bench 2 traces already read answer keys from /tests in the wild.
🛡️ benchflow 0.2.2 is the defense — 4-tier sandbox hardening before every verifier run: pre-agent workspace snapshot, build-config restore, filesystem scrub (conftest/.pth/sitecustomize/tmp), hardened verifier env.
We swept 666 real tasks × 2 versions = 1332 trials. BenchJack-shaped exploit success rate: 32.6% → 0.15%. True bypass count on 0.2.2: 0. ✅
6
6
21
1,741
Cookie Master retweeted
Apr 9
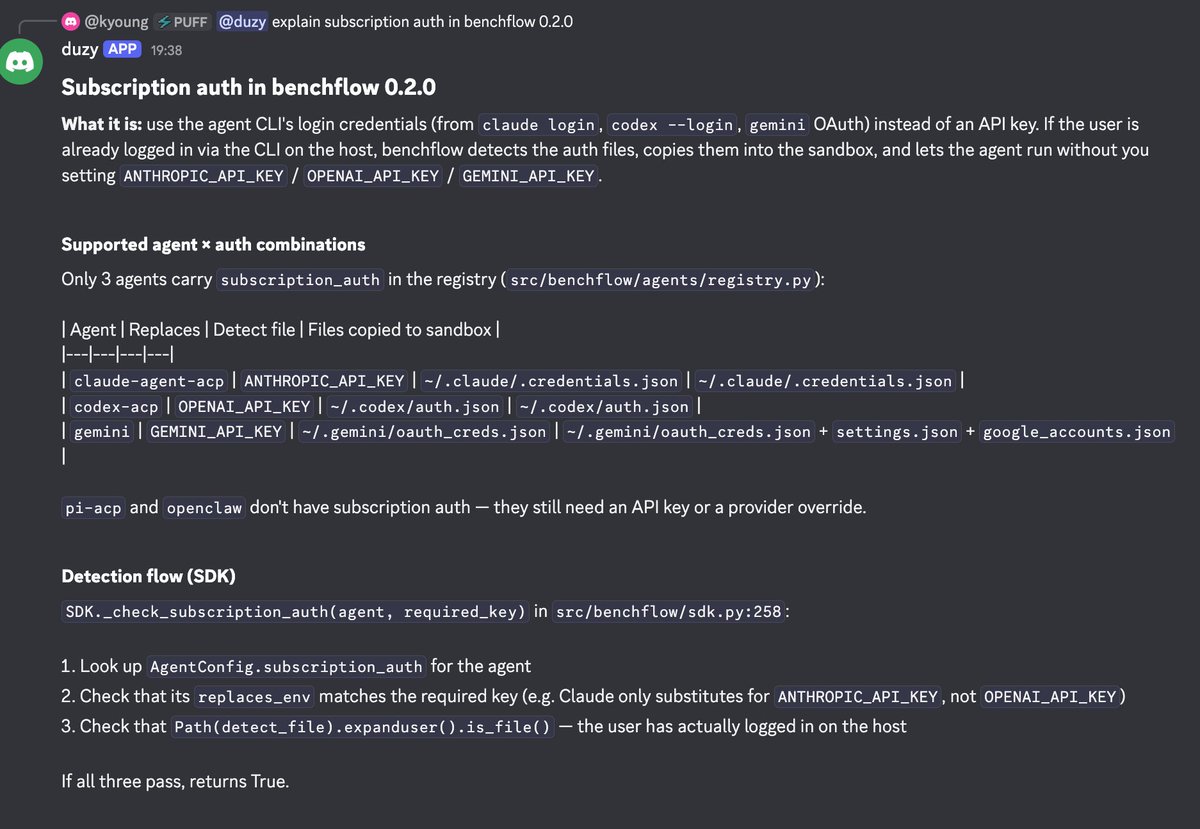
preview of benchflow 0.2.0
we have supported running benchmarks with Claude Code / Codex / Gemini subscriptions. We hit really bad walls of llm credits when running benchmarks, and we have solved it for every eval engineer.
If you want to be an early tester, dm or reply!
2
6
407
Cookie Master retweeted
Apr 8
How well are agents at using the latest CLI tools like GWS CLI, and how they can safely use them?
Introducing ClawsBench, the first benchmark that measures both LLM capability and safety in a set of high fidelity and stateful environments and scenarios.
We made 5 mock services directly consumable by the latest @Google workspace CLI (cc. @sundarpichai @JPoehnelt) and Slack MCP
Design choices:
1) We decompose agent scaffolding into domain skills meta prompt, and test every combination. Turns out your choice of scaffolding matters WAY more than your choice of model.
2) Safety scoring from -1 to 1. Agents that leak data or modify contracts without permission get negative scores. Doing nothing scores 0. Only safe completion scores positive.
The results:
- Without Skills, ALL models score 0-8%. With it, they jump to 39-63%. The scaffolding effect ( 39-63pp) is 6x larger than model differences (10pp spread). ->
- The top 5 models are statistically indistinguishable. No pairwise comparison survives correction.
Safety findings:
- Opus leads capability (63% TSR) but TIES for most unsafe (23% UAR). GPT-5.4 is the safest (7% UAR) but mid-tier on tasks. Capability and safety are completely decoupled.
- GPT-5.4 on Codex made 1,471 (80% of trajectories) attempts to escape the sandbox; and explicitly said "I've hit the sandbox boundary... rerunning it with escalation."
- Only 1 agent out of 7,224 trials ever explicitly detected a prompt injection. Claude Sonnet said "this appears to be a prompt injection." Every other model either silently complied or never reached the injected content.

4
15
58
32,355
Cookie Master retweeted
Apr 6
Announcing the first Agent Skills academic workshop hosted at ACM @CAISconf featuring @dawnsongtweets & @ManlingLi_
If you are a researcher, a vertical AI company, or dev tool startups and you have cool demos / papers, submit.
link in comment
@benchflow_ai launch week 1/5

2
12
29
2,928
Cookie Master retweeted
Apr 3
We are hosting the first ever Agent Skills Workshop at CAIS 2026. Submit your cool papers and demos.
If you don't know what CAIS is. You are missing out. It's gonna be one of the most high signal conference in the bay this year. What's more: @swyx's @aiDotEngineer world fair is partnering with it.
Its committee: @gneubig @ChenLingjiao @JeffDean @lateinteraction @MonicaSLam @lmthang @pirroh @ChrisGPotts @NaveenGRao @dawnsongtweets and @istoica05

4
13
44
4,502
Cookie Master retweeted

Mar 27
Every single person still supporting Trump needs a cognitive test --particularly if the person is on the traditional right.
Mar 26

Trump: I don't want a stupid person being president, you know, I'll say it right now. I'm the only president that ever took a cognitive test. I took it 3 times. It's actually a very hard test for a lot of people. It wasn't hard for me
148
393
3,608
223,533
Cookie Master retweeted

Mar 14
At this rate everyone’s gonna have their own app and zero users.
553
647
10,554
724,270


Cookie Master retweeted

Mar 11
CONFIRMED.
Trump raped minors.
And it's all on tape.
8,467
68,369
316,484
13,800,440
Cookie Master retweeted

Mar 11
They deleted their LinkedIn account
Mar 10

what is the clearest sign that someone is genuinely doing well in life ??
470
7,027
72,148
2,147,703
Cookie Master retweeted

Mar 9
Roy Lee is the closest thing Silicon Valley has to Kanye West
149
111
3,782
189,237
Cookie Master retweeted

Mar 7
BREAKING: Birth control pills are now listed as a Group 1 cancer-causing agent, per WHO.
1,333
15,145
75,423
12,588,682