
Joined August 2025
- Tweets 348
- Following 618
- Followers 32
- Likes 230
Photos and videos
Lamonte Smith retweeted

Jun 14
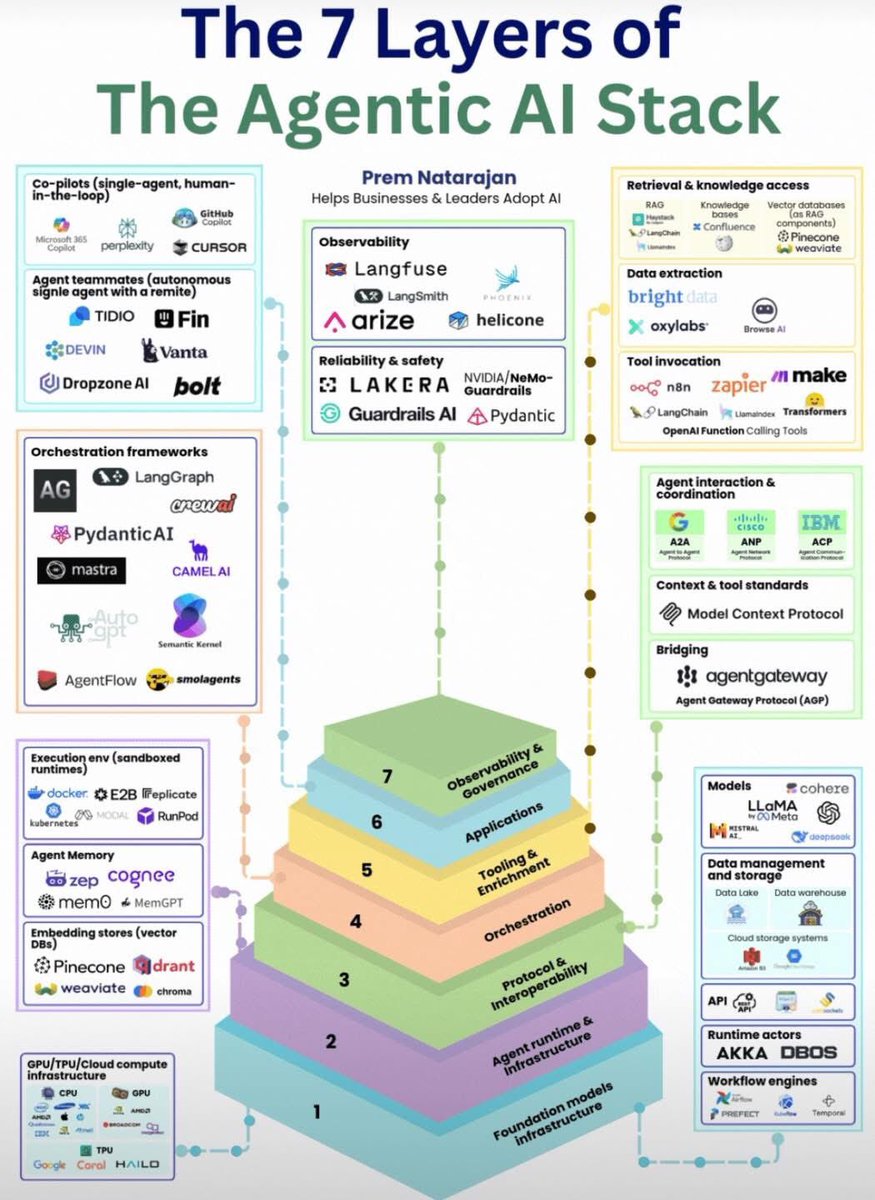
7 Layers of the Agentic AI Stack
3
37
168
5,160

Jun 14
My personal review of Interview Kickstart’s AI Agentic program for engineering leaders. #interviewkickstart maps.app.goo.gl/MGdGpC9bWBeJ…
10




Lamonte Smith retweeted

Jun 10
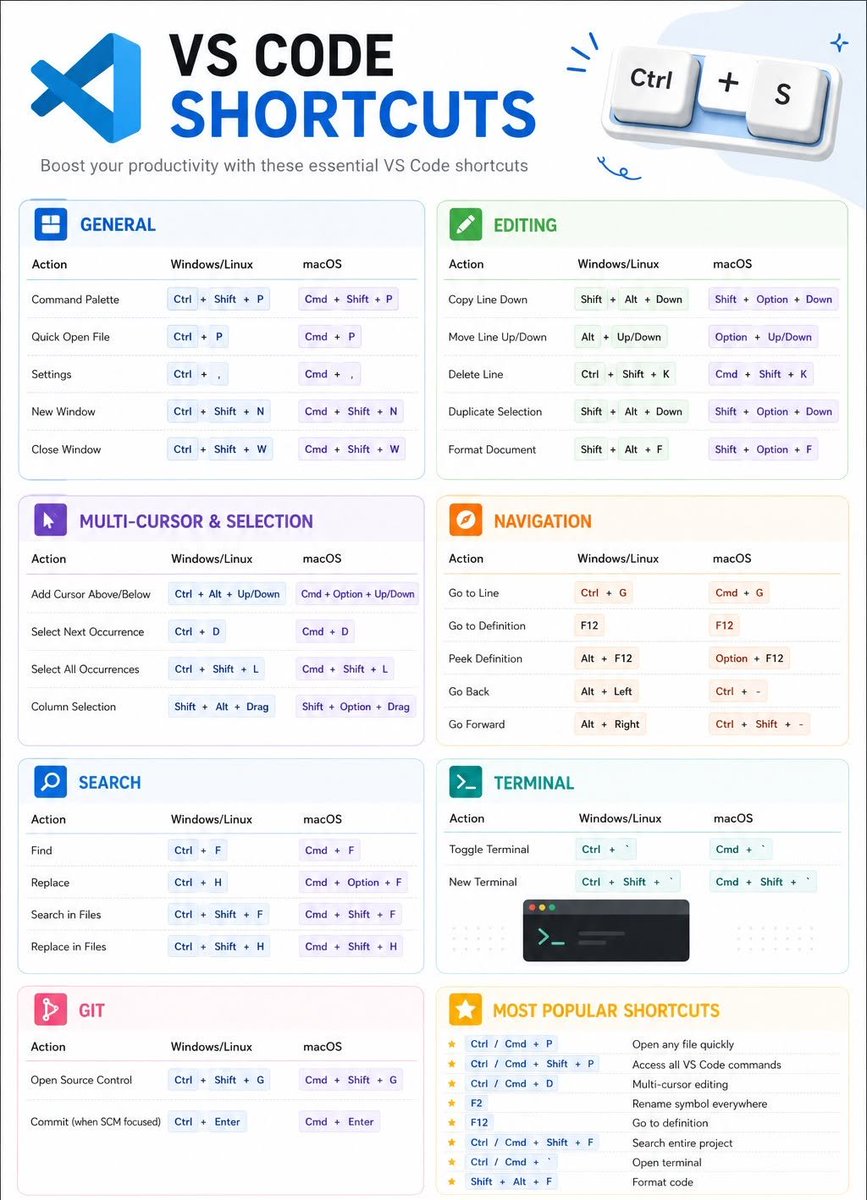
🚀 VS Code Shortcuts That Save Hours Every Week!
2
45
236
9,168
Lamonte Smith retweeted

Jun 8
Retrieval systems answer questions. AI Agents take actions. 🧠⚡
If you are still confusing RAG (Retrieval-Augmented Generation) with AI Agents, you are missing the shift happening in enterprise AI right now.
While both leverage Large Language Models (LLMs), their architecture, capabilities, and purposes are fundamentally different. Here is the breakdown you need to know:
🔹 RAG: The Smart Librarian 📚
Think of RAG as a hyper-efficient research assistant. It takes a user query, searches an enterprise database or document archive, finds the right context, and uses an LLM to generate a grounded, accurate answer.
Workflow: Linear and single-step (Query ➡️ Search ➡️ Generate ➡️ Answer).
Memory: Limited to the immediate context window.
Autonomy: Reactive. It only speaks when spoken to.
Best For: Enterprise search, document Q&A, and customer support chatbots.
🔸 AI Agents: The Intelligent Operator ⚙️
AI Agents don’t just find information—they execute multi-step workflows autonomously to achieve a high-level goal. They reason, plan, adapt, and use external tools.
Workflow: Dynamic and recursive loops (Goal ➡️ Plan ➡️ Use Tool ➡️ Evaluate ➡️ Repeat until done).
Memory: Persistent (remembers past actions and learns over time).
Autonomy: Proactive. It determines its own sub-tasks and calls APIs, writes code, or automates browsers.
Best For: Autonomous research, end-to-end workflow automation, and AI copilots.
The Bottom Line:
RAG is phenomenal for bridging the gap between static LLM knowledge and your private enterprise data. But if you want to automate actual business processes, orchestrate workflows, and let AI execute tasks independently, you are building an AI Agent.
#AIAgents #RAG #GenerativeAI #ArtificialIntelligence #LLM #MachineLearning

10
57
243
7,507
Lamonte Smith retweeted

How To Build An AI Agent
(bookmark this for later)

1
47
233
10,639
Lamonte Smith retweeted

Jun 8
If you want to get ahead of 99% of software engineers, then learn these 20 API concepts:
1 Endpoint
2 HTTP Methods
3 Request-Response
4 Status Codes
5 Authentication
6 Authorization
7 Access Tokens
8 OAuth 2.0
9 Rate Limiting
10 Throttling
11 Pagination
12 Caching
13 Idempotency
14 Webhooks
15 API Versioning
16 OpenAPI
17 REST vs GraphQL
18 API Gateway
19 Microservices
20 Error Handling
What else should make this list?
===
💾 Save & RT to help others ace API design.
👤 Follow @systemdesignone turn on notifications.

22
77
380
12,881
Jun 7
Great post, happy to repost....

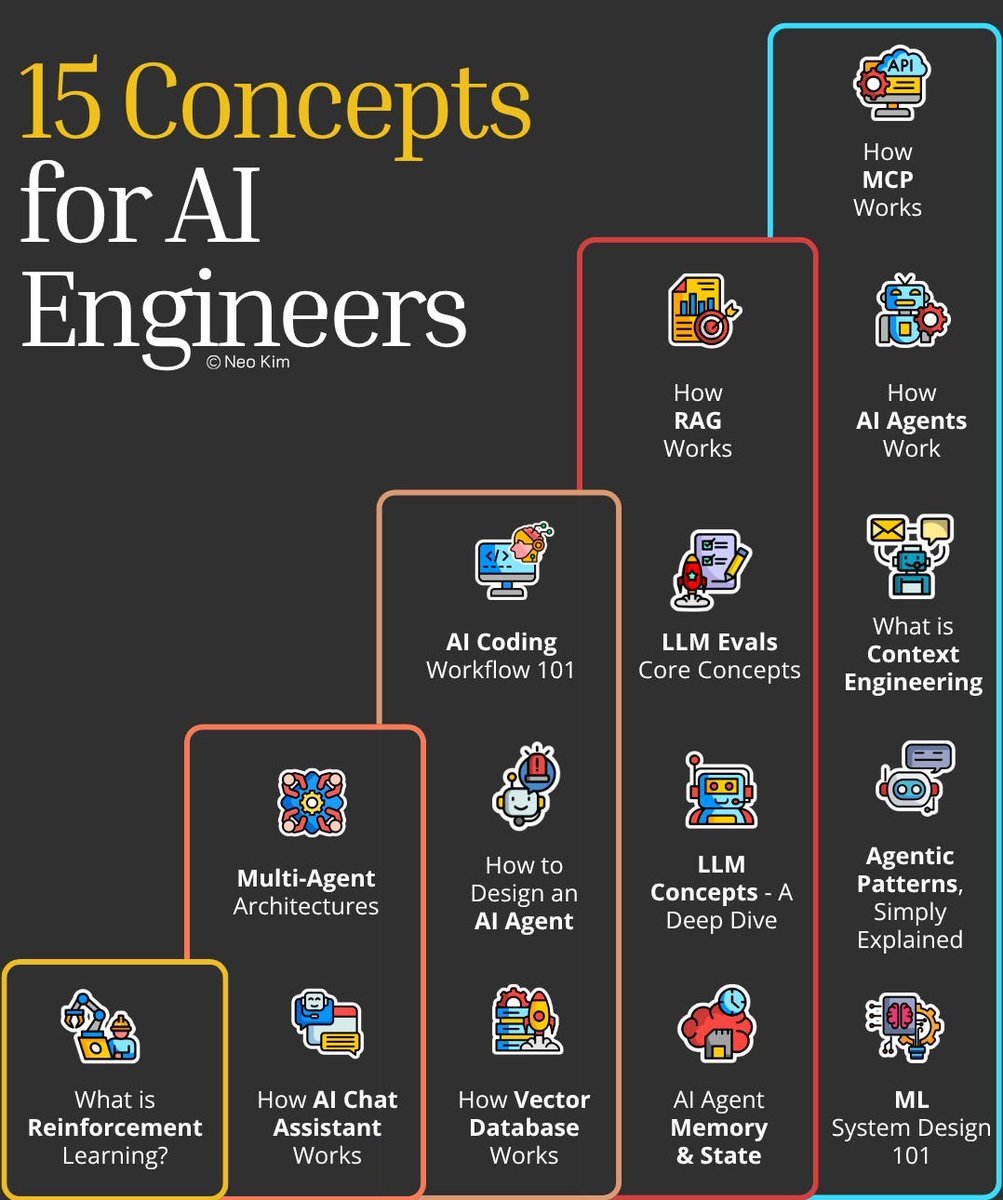
If you want to become good at AI engineering
(in 3 weeks), then learn these 15 concepts:
1 AI Agents: Memory, State & Consistency
→ newsletter.systemdesign.one/…
2 Machine Learning System Design 101
→ newsletter.systemdesign.one/…
3 Design Personal AI Chat Assistant
→ newsletter.systemdesign.one/…
4 How RAG Works
→ newsletter.systemdesign.one/…
5 LLM Concepts - A Deep Dive
→ newsletter.systemdesign.one/…
6 How to Design an AI Agent
→ newsletter.systemdesign.one/…
7 What is Reinforcement Learning
→ newsletter.systemdesign.one/…
8 How Vector Databases Work
→ newsletter.systemdesign.one/…
9 Context Engineering 101
→ newsletter.systemdesign.one/…
10 AI Coding Workflow 101
→ newsletter.systemdesign.one/…
11 LLM Evals Explained
→ newsletter.systemdesign.one/…
12 How AI Agents Work
→ newsletter.systemdesign.one/…
13 How MCP Works
→ newsletter.systemdesign.one/…
14 Agentic Patterns Explained
→ newsletter.systemdesign.one/…
15 Multi-Agent Architecture Explained
→ newsletter.systemdesign.one/…
What else should make this list?
===
💾 Save & restack to help others ace AI engineering.
2
1
10
Jun 5
The convergence of ML and AI engineering highlights how rapidly our field is evolving. It is an exciting time to work across these domains—whether optimizing model architecture or building the orchestration layers and RAG pipelines that bring them to life. Grateful to play a part in this ecosystem.
Jun 5

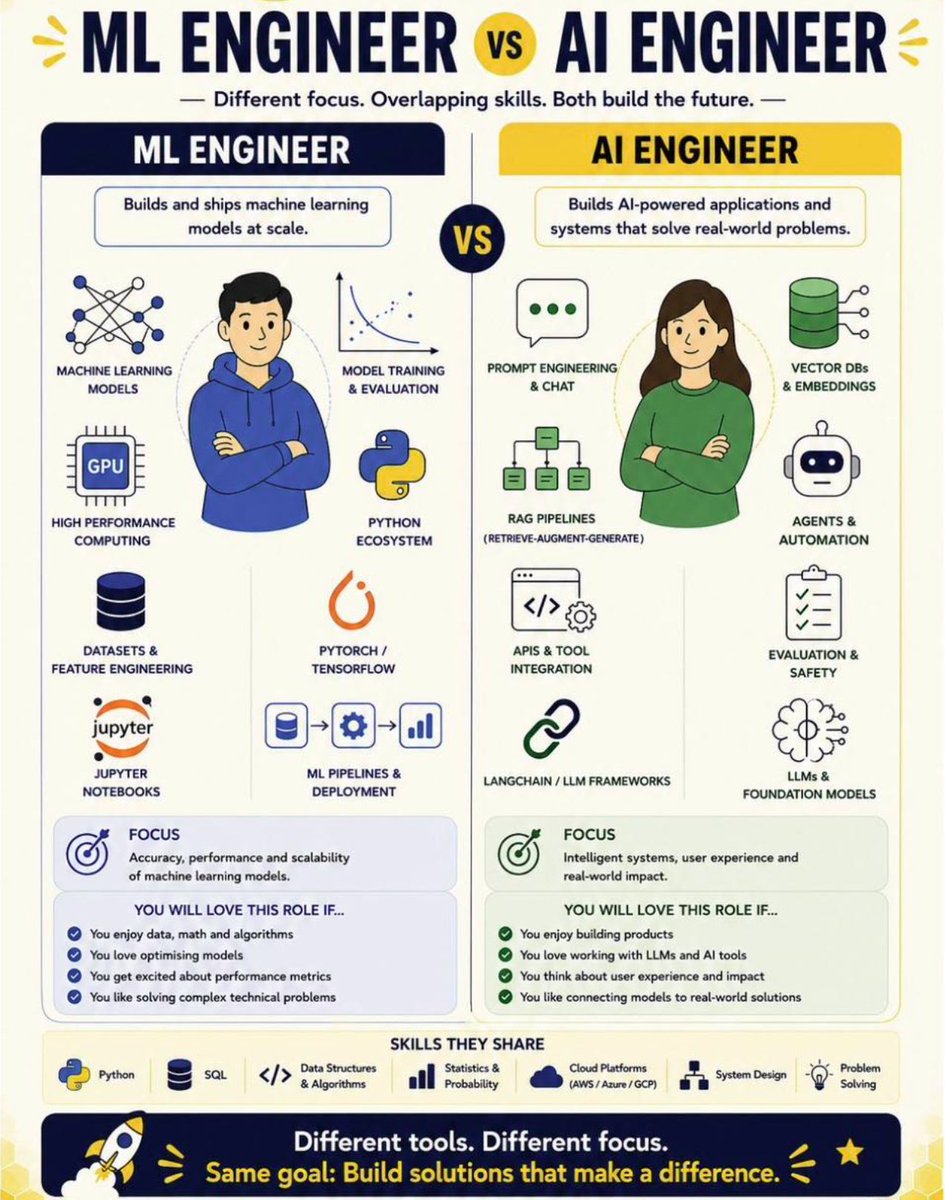
Two of the most confused job titles in tech right now.
ML Engineer. AI Engineer.
People use them interchangeably in job posts, interviews and LinkedIn bios. They are not the same role.
Here is the clearest breakdown I have seen.
An ML Engineer builds and ships machine learning models at scale. The focus is accuracy, performance and scalability. If you love data, math, algorithms and optimising models this is your role.
An AI Engineer builds AI-powered applications and systems that solve real world problems. The focus is intelligent systems, user experience and real world impact. If you love building products, working with LLMs and connecting models to real solutions this is your role.
The skills overlap significantly. Python, SQL, cloud platforms, statistics. Both roles need these.
But the day to day work, the mindset and the problems you solve are fundamentally different.
Save this. Share it with anyone who is trying to figure out which path to take.
♻️ Repost to help someone who is confused about which role to apply for.
#DataScience #MachineLearning #AI #MLEngineer #AIEngineer #DataScientist #LearnAI
1
9
Lamonte Smith retweeted
Git is essential for version control, collaboration, branching, debugging, and managing code efficiently. Understanding commonly used commands helps developers track changes, work in teams, maintain clean repositories, and streamline workflows. #Git #GitHub #Programming #SoftwareEngineering #DevOps

1
9
29
911
Lamonte Smith retweeted

Jun 2
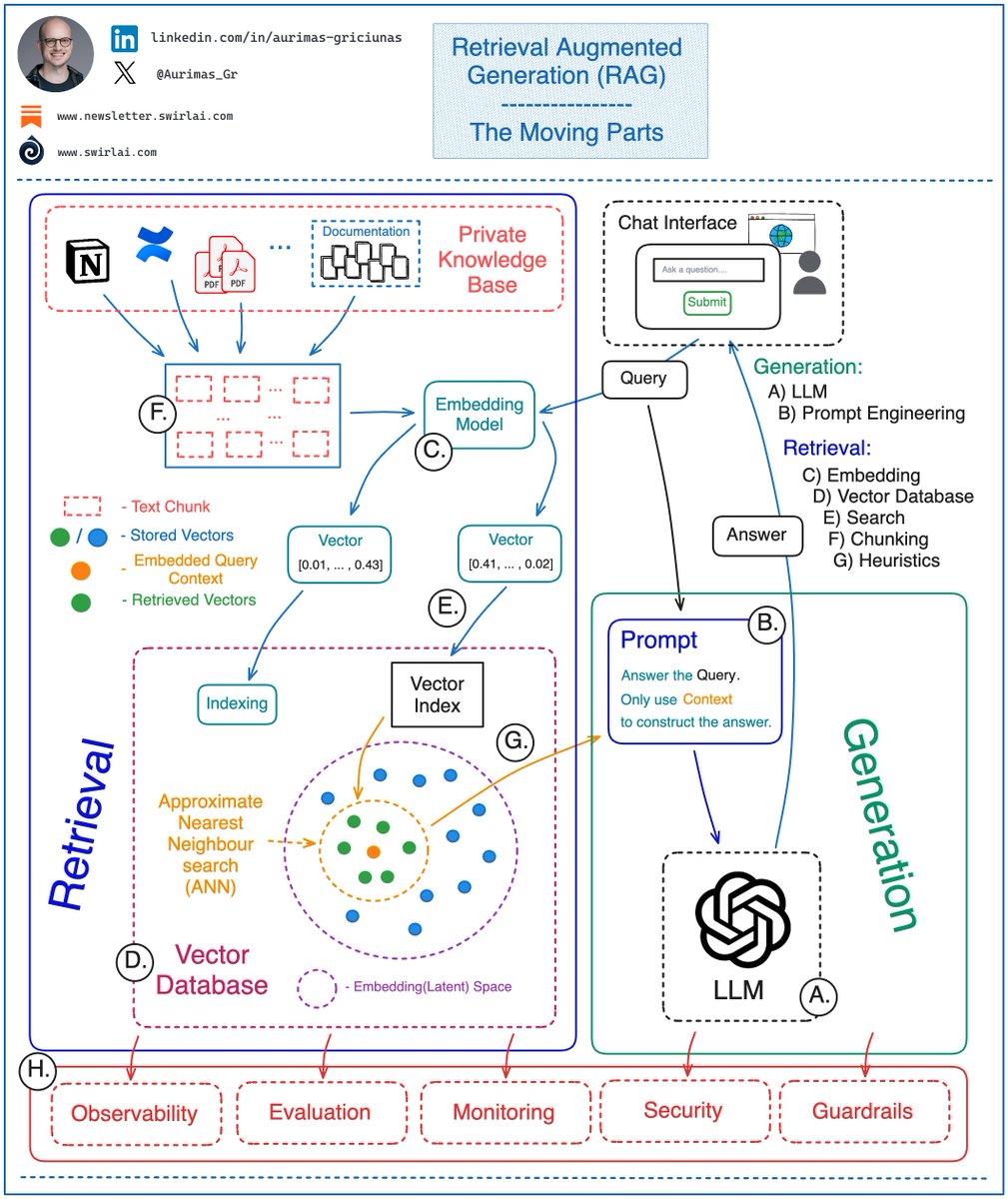
“I will build a RAG system for my company in one week” - that is what I often hear nowadays from recently turned AI experts.
Unfortunately, building a 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗴𝗿𝗮𝗱𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 (𝗥𝗔𝗚) 𝗯𝗮𝘀𝗲𝗱 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺 is a challenging task.
Here are some of the moving parts in the RAG based systems that you will need to take care of and continuously tune in order to achieve desired results:
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹:
𝘍 ) Chunking - how do you chunk the data that you will use for external context.
- Small, Large chunks.
- Sliding or tumbling window for chunking.
- Retrieve parent or linked chunks when searching or just use originally retrieved data.
𝘊 ) Choosing the embedding model to embed and query and external context to/from the latent space. Considering Contextual embeddings.
𝘋 ) Vector Database.
- Which Database to choose.
- Where to host.
- What metadata to store together with embeddings.
- Indexing strategy.
𝘌 ) Vector Search
- Choice of similarity measure.
- Choosing the query path - metadata first vs. ANN first.
- Hybrid search.
𝘎 ) Heuristics - business rules applied to your retrieval procedure.
- Time importance.
- Reranking.
- Duplicate context (diversity ranking).
- Source retrieval.
- Conditional document preprocessing.
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻:
𝘈 ) LLM - Choosing the right Large Language Model to power your application.
✅ It is becoming less of a headache the further we are into the LLM craze. The performance of available LLMs are converging, both open source and proprietary. The main choice nowadays is around using a proprietary model or self-hosting.
𝘉 ) Prompt Engineering - having context available for usage in your prompts does not free you from the hard work of engineering the prompts. You will still need to align the system to produce outputs that you desire and prevent jailbreak scenarios.
And let’s not forget the less popular part:
𝘏) Observing, Evaluating, Monitoring and Securing your application in production!
What other pieces of the system am I missing? Let me know in the comments 👇
15
60
302
11,757
May 30
Walsh College Provost Featured at AI Workforce & Economic Empowerment Summit corpmagazine.com/break-room/… via @corpmagazine
10
Lamonte Smith retweeted

May 29
🚨 𝟔 𝐓𝐲𝐩𝐞𝐬 𝐨𝐟 𝐋𝐋𝐌𝐬 𝐩𝐨𝐰𝐞𝐫𝐢𝐧𝐠 𝐭𝐨𝐝𝐚𝐲’𝐬 𝐀𝐈 𝐚𝐠𝐞𝐧𝐭𝐬
1️⃣ 𝐆𝐏𝐓 – 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐏𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐓𝐫𝐚𝐧𝐬𝐟𝐨𝐫𝐦𝐞𝐫
(𝑇ℎ𝑒 𝐺𝑒𝑛𝑒𝑟𝑎𝑙𝑖𝑠𝑡)
Trained on massive datasets, these autoregressive models are the foundational engines for writing, reasoning, coding, and open-ended conversation.
➜ Highly versatile across diverse domains
➜ Excels at zero-shot and in-context learning
➜ The ultimate foundation for downstream fine-tuning
2️⃣ 𝐌𝐨𝐄 – 𝐌𝐢𝐱𝐭𝐮𝐫𝐞 𝐨𝐟 𝐄𝐱𝐩𝐞𝐫𝐭𝐬
(𝑇ℎ𝑒 𝑆𝑐𝑎𝑙𝑒𝑟)
Instead of activating the full neural network, MoE uses sparse routing to send each input only to the most relevant subset of "expert" sub-networks.
➜ Radically higher compute efficiency during inference
➜ Scales seamlessly to trillions of parameters
➜ Achieves deep specialization without sacrificing overall performance
3️⃣ 𝐕𝐋𝐌 – 𝐕𝐢𝐬𝐢𝐨𝐧-𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑀𝑢𝑙𝑡𝑖𝑚𝑜𝑑𝑎𝑙)
Combines advanced vision encoders with language models to natively process and reason over spatial data—like images, complex diagrams, and video streams.
➜ Understands deep visual and spatial context
➜ Perfectly aligns pixel data with semantic text
➜ Enables rich multimodal tasks (like visual QA and image-based telemetry)
4️⃣ 𝐋𝐑𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝑇ℎ𝑖𝑛𝑘𝑒𝑟)
Built for "System 2" thinking. Optimized for multi-step reasoning, logical problem-solving, and planning through explicit verification and self-correction loops.
➜ Elite mathematical and logical planning
➜ Drastically reduced hallucinations through step-by-step verification
➜ Excels at complex, highly constrained problem-solving
5️⃣ 𝐒𝐋𝐌 – 𝐒𝐦𝐚𝐥𝐥 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐿𝑖𝑔ℎ𝑡𝑤𝑒𝑖𝑔ℎ𝑡)
Compact, highly optimized models engineered specifically for edge devices, offline execution, or highly cost-sensitive environments.
➜ Ultra-low latency and blazing-fast inference
➜ Highly cost-effective to deploy and maintain
➜ Ensures data privacy through strictly on-device processing
6️⃣ 𝐋𝐀𝐌 – 𝐋𝐚𝐫𝐠𝐞 𝐀𝐜𝐭𝐢𝐨𝐧 𝐌𝐨𝐝𝐞𝐥
(𝑇ℎ𝑒 𝐷𝑜𝑒𝑟)
Designed not just to generate text, but to execute real-world tasks using tools, APIs, and external environments. It operates on a continuous agent loop:
🔄 Plan ➟ Action ➟ Observation ➟ Reflect ➟ Update Memory
➜ Autonomous real-world execution
➜ Native integration with external systems and software
➜ Dynamically adapts to environmental feedback
Agents aren’t just chatbots anymore. They see, act, reason, and run anywhere from cloud GPUs to edge devices. 𝐶ℎ𝑜𝑜𝑠𝑖𝑛𝑔 𝑡ℎ𝑒 𝑟𝑖𝑔ℎ𝑡 𝐿𝐿𝑀 𝑡𝑦𝑝𝑒 𝑑𝑖𝑟𝑒𝑐𝑡𝑙𝑦 𝑖𝑚𝑝𝑎𝑐𝑡𝑠 𝑐𝑜𝑠𝑡, 𝑙𝑎𝑡𝑒𝑛𝑐𝑦, 𝑟𝑒𝑙𝑖𝑎𝑏𝑖𝑙𝑖𝑡𝑦, 𝑎𝑛𝑑 𝑟𝑒𝑎𝑙‑𝑤𝑜𝑟𝑙𝑑 𝑐𝑎𝑝𝑎𝑏𝑖𝑙𝑖𝑡𝑖𝑒𝑠.
Cc : Author

8
104
343
8,988
Lamonte Smith retweeted

May 29
Python becomes far easier when you understand the core commands behind loops, functions, file handling, data types, and list comprehensions. Strong fundamentals make debugging, automation, and data analysis much easier in real projects. #Python #Coding #DataAnalytics #Programming #DataScience

1
7
51
1,108
Lamonte Smith retweeted
May 28
Most SQL problems that analysts solve with subqueries can be solved in one line.
Window functions do that. Here is how they work.
A window function performs a calculation across a set of rows without collapsing them into a single result the way GROUP BY does.
You keep every row. You just add a new column with the calculated value alongside it.
The syntax is always the same:
function() OVER (PARTITION BY ... ORDER BY ...)
PARTITION BY splits the data into groups.
ORDER BY sets the sequence within each group. Not every window function needs both — but that is the full structure.
Here are the 7 you will actually use:
𝗥𝗢𝗪_𝗡𝗨𝗠𝗕𝗘𝗥 Assigns a unique number to each row. No ties, ever.
𝗥𝗔𝗡𝗞 Ranks rows by value. Tied rows get the same rank and the next number is skipped.
𝗗𝗘𝗡𝗦𝗘_𝗥𝗔𝗡𝗞 Like RANK, but no numbers are skipped after a tie. The sequence stays continuous.
𝗟𝗔𝗚 Pulls the value from the previous row. Use it to compare this period to the last.
𝗟𝗘𝗔𝗗 Pulls the value from the next row. Use it to see what comes after the current row.
𝗥𝗨𝗡𝗡𝗜𝗡𝗚 𝗧𝗢𝗧𝗔𝗟 Adds values cumulatively as it moves through rows in order.
𝗣𝗔𝗥𝗧𝗜𝗧𝗜𝗢𝗡 𝗕𝗬 Resets the calculation for each group. Same idea as GROUP BY, but every individual row stays visible.
The cheatsheet below has the code and output for each one, using the same reference dataset throughout so you can see exactly what changes.
#SQLPerformance #SQL #Database

2
38
159
5,274
Lamonte Smith retweeted
May 28
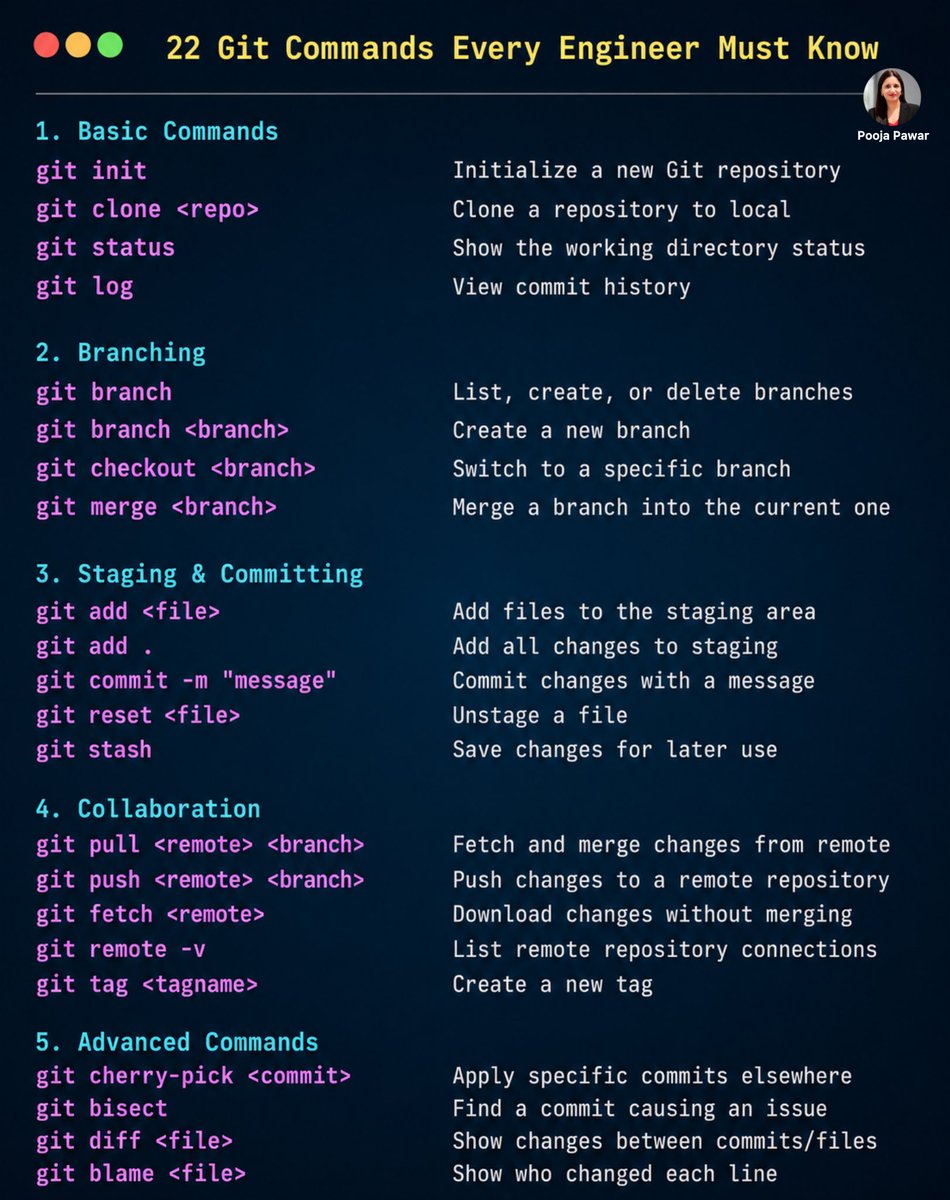
Git is one of the most important tools for developers and data professionals. Mastering commands for branching, commits, collaboration, and version control helps teams work efficiently, track changes, and manage projects with confidence. #Git #GitHub #Programming #DataEngineering #Python
1
14
66
1,231
Lamonte Smith retweeted
May 28
AI and ML are no longer optional skills for modern tech careers. Strong foundations in statistics, Python, machine learning, transformers, projects, and AI ethics matter more than chasing every new tool. Build depth first, then scale your expertise. #AI #MachineLearning #DataScience #Python #DeepLearning

3
5
75
1,466
Lamonte Smith retweeted
May 25
Top 15 high paying AI jobs by 2030 include AI Research Scientist, Deep Learning Engineer, MLOps Engineer, GenAI Engineer, Prompt Engineer, Computer Vision Engineer, Robotics Engineer and more. The future belongs to those who build, deploy and scale AI solutions. #AI #MachineLearning #GenAI #MLOps #DeepLearning #TechCareers

3
19
91
3,047

Do something different this weekend.
Become a PRO in AI Model Fine-tuning.
Paste this prompt in Codex/ChatGPT/Claude/Grok.
"You are an expert AI engineer and teacher.
Your job is to teach me modern LLM engineering and fine-tuning concepts from beginner to advanced level using very simple daily-life language.
Teach me step-by-step like a real mentor. Assume I am smart but new to the topic.
Foundations:
- LLM basics
- How AI models work
- Tokens
- Tokenization
- Context windows
- Embeddings
- Transformers
- Attention mechanism
- Parameters
- Training vs inference
- Open-source vs closed-source models
Datasets & Training:
- SFT datasets
- Instruction tuning
- Preference datasets
- Synthetic datasets
- Data curation
- Dataset cleaning
- Dataset formatting
- Fine-tuning basics
- Continued pretraining
- Hallucination reduction
Fine-Tuning:
- LoRA
- QLoRA
- DPO
- RLHF
- Quantization
- Model checkpoints
- Adapter tuning
- GGUF models
Inference & Optimization:
- KV cache
- Flash Attention
- Speculative decoding
- Inference optimization
- Model serving
- Batch inference
- GPU basics
- VRAM basics
- Latency vs quality tradeoffs
Local AI Ecosystem:
- llama.cpp
- Ollama
- vLLM
- MLX
- Hugging Face
- Unsloth
- Axolotl
- PEFT
- TRL library
RAG & Memory:
- RAG
- Vector databases
- Chunking
- Retrieval pipelines
- AI memory systems
- Semantic search
Agents & Workflows:
- Prompt engineering
- System prompts
- Tool calling
- Function calling
- AI agents
- Agentic workflows
- Multi-agent systems
- Browser agents
Model Types:
- VLMs
- SLMs
- Dense models
- MoE models
- Coding models
- Reasoning models
Deployment:
- Local inference
- On-device AI
- API serving
- Cloud GPUs
- Edge AI basics
Evaluation:
- AI benchmarks
- Human evals
- Cost-per-token analysis
- Speed benchmarking
- Quality benchmarking
Real-World Skills:
- Building chatbots
- Building AI copilots
- AI automation
- AI SaaS workflows
- AI coding workflows
- AI orchestration systems
- AI product thinking
Start from the absolute basics and gradually make me advanced.
Rules:
- Use simple English only
- Avoid academic jargon unless necessary
- Explain every difficult word in plain language
- Use real-world analogies and daily-life examples
- Use small code snippets when useful
- Show practical use cases
- Compare concepts side-by-side when helpful
- Teach from fundamentals first, then advanced concepts
- At the end of each topic:
- give a short summary
- give a simple mental model
- give beginner mistakes to avoid
- give a small exercise/project
I want deep understanding, not memorization."
Thank me later.

64
373
2,312
102,802