
Joined December 2021
- Tweets 16,317
- Following 1,209
- Followers 994
- Likes 28,295
3,698 Photos and videos




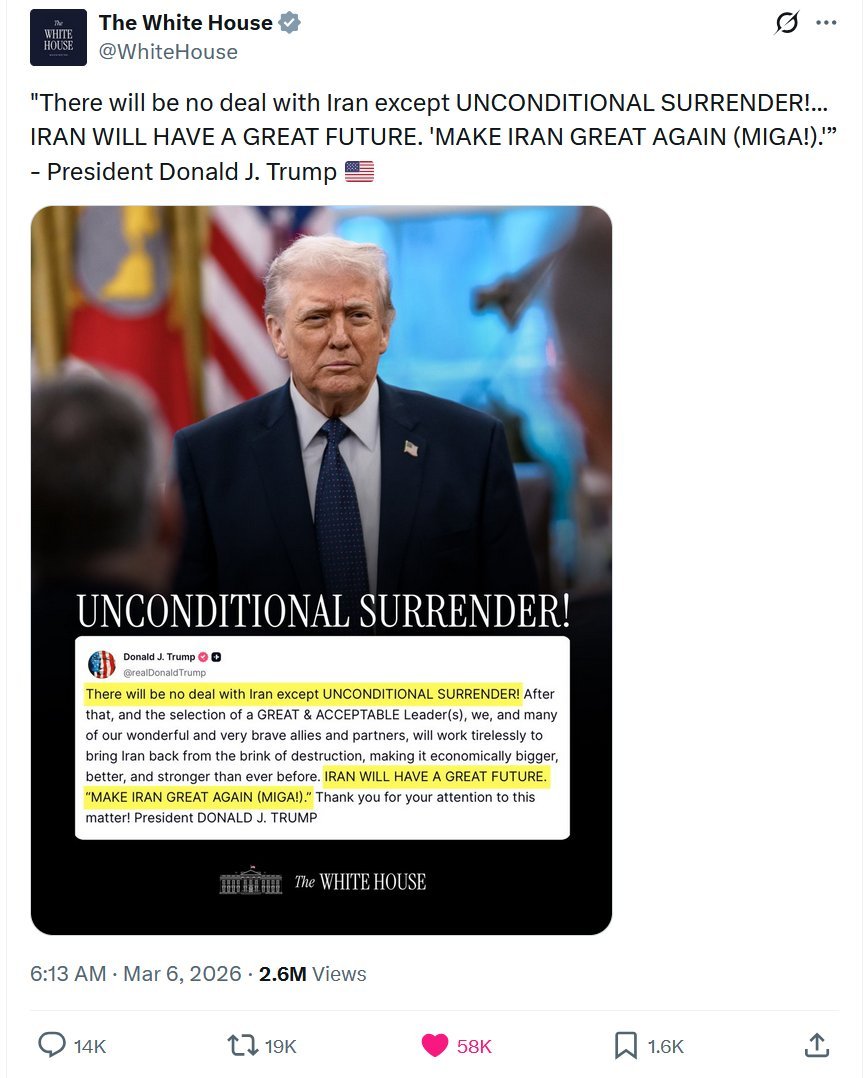
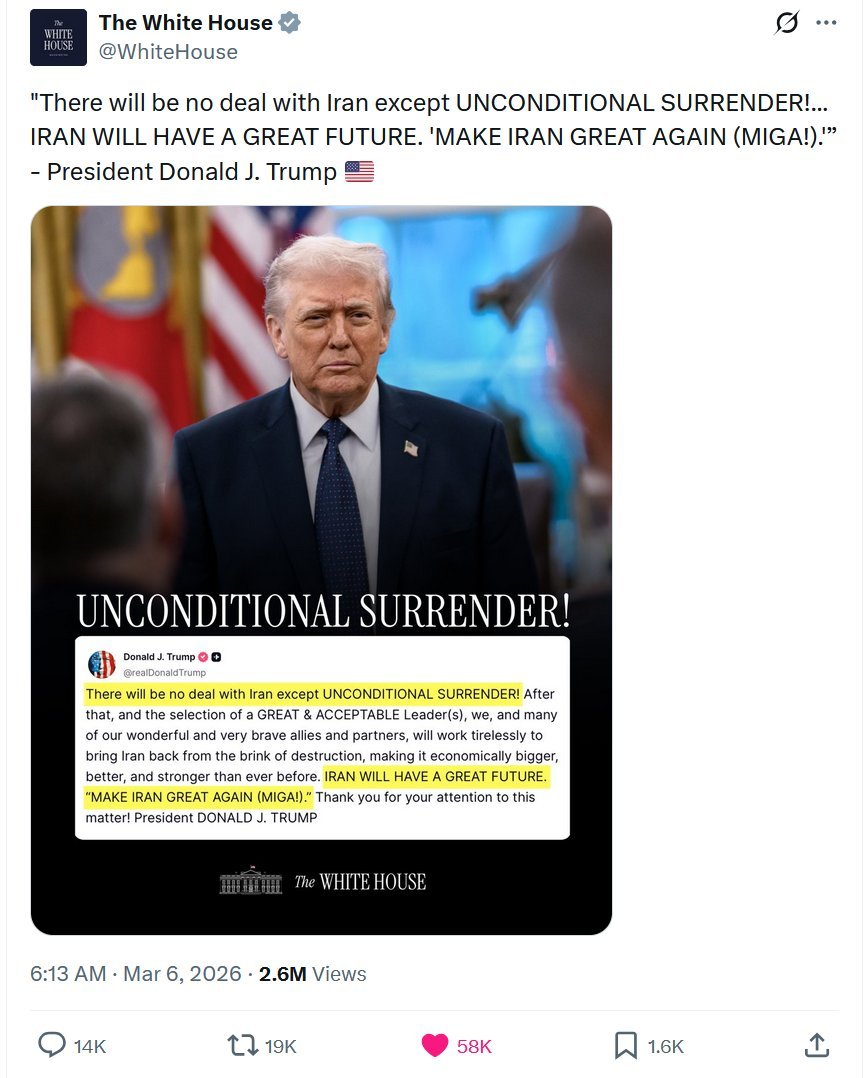







Dear @SecRollins: You keep getting fact checked for your lies. It’s your Administration that cut the Screwworm programs.
Also, the life cycle of a Screwworm is 14 to 54 days. The trump Administration has been in office over 500 days.
If you can’t stop lying, you need to resign.

Rollins on Screwworm: This does trace back to the last administration….
Community note
The screwworm monitoring program in Central America was cut by the Trump administration's DOGE in early 2025, not the Biden administration. forbes.com/sites/maryroel… agri-pulse.com/articles/22636…
601
9,014
22,101
278,619
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Jun 10
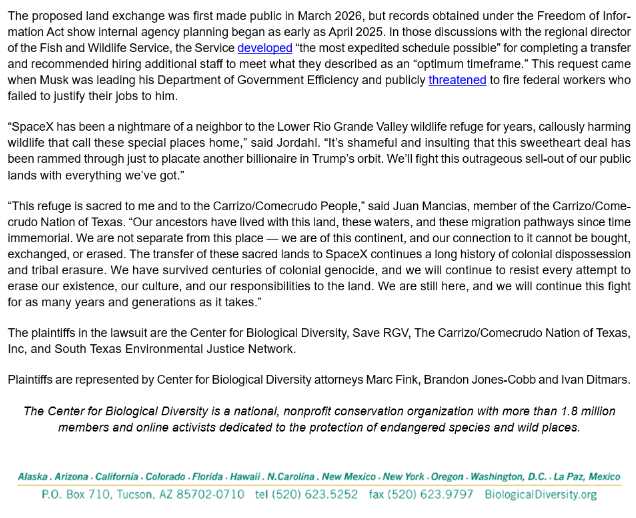
BREAKING: We're suing the U.S. Fish & Wildlife Service over their plan to give away 715 acres of a public wildlife refuge to billionaire corporation Space X.
Americans shouldn't be sacrificing their public lands to subsidize a company owned by the richest man in the world.


317
10,683
33,804
353,390
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Jun 10
This Administration has removed the achievements of the Air Force’s first female Thunderbird pilot Retired Colonel Nicole Malachowski. The removal of these articles have sparked criticism because her place in Air Force history is not a Political slogan it’s well documented.

946
9,076
14,245
206,258
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

In fact 95% of papers listing the Abcam antibody ab51243 have used it incorrectly. Here's the link to the blog for my complete analysis: forbetterscience.com/2026/06…
4
21
143
15,950
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted
Today I'm posting a new blog about an astonishing scientific own goal. Hundreds of papers have reported using a completely wrong antibody to investigate the tumor suppressor p16. This mistake has happened because scientists have muddled the names of two proteins 🧵

22
132
630
95,029
Bravo 👏 @addictedtoigno1
More assay circus stunts and data fabrication.
Jun 8

Pretty interesting story in @ScienceMagazine this week on what looks like a serious problem in the senescence field. More than 400 papers apparently used the wrong antibody for p16-INK4a — an antibody that actually recognizes a completely different, unrelated protein (a component of the actin cytoskeleton). This affects work on senescent cell accumulation in aging and disease, and most critically, some of the evidence base for senolytic drug research.
What concerns me most is that many of these papers somehow got the "right" answer using the wrong antibody. That's not just an innocent reagent mix-up — it raises real questions about data fabrication or selective reporting in at least some of these labs. I've commented before about how ignoring data that doesn't fit the narrative is a major problem in certain areas of the longevity literature (e.g. sirtuins and NAD), and here a potentially widespread example in senescence.
Hopefully journals will investigate and retract as necessary, but based on my experience that seems optimistic. One concrete fix is that journals should flag problematic antibody product codes at submission so reviewers can catch this before publication. Reviewers should absolutely be on the lookout for this going forward.
However, these fixes won't address the larger problem. We need to understand how these scientists got the results they wanted and published them over 400 times (!!!): whether through intentional deception, incompetence, accident, or some legitimate explanation.
Credit for discovering this goes to @addictedtoigno1 who wrote about it first on his blog: For Better Science
science.org/content/article/…?
126
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Jun 8
Dr. Oz linking obesity to dementia while Trump’s slumped over at his desk 😭😭
290
2,202
11,864
1,960,779
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

DONALD TRUMP HAS FALLEN ASLEEP AT THE NBA FINALS IN MADISON SQUARE GARDEN.
5,203
16,026
150,684
19,635,080
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Jun 9
…and in that same stiff wind Ted Cruz would head to Cancun.
Jun 9

Ted Cruz on Talarico: "If you were making a list of 1,000 adjectives to describe this guy, 'masculine' would not be one of them. I mean, if a stiff breeze came by it would blow him over like a feather."
2
5
323
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted
A New York trooper who rammed an SUV during a 130‑mph pursuit, killing 11‑year‑old Monica Goods and then falsifying reports to blame her father, has been sentenced to prison after years of delays and public outrage.
atlantablackstar.com/2026/06…
99
3,115
9,328
125,873
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Jun 5
This is so insanely corrupt, I can’t even believe it.
More than half the donors to Trump’s $400 million White House ballroom just won over $50 billion in new federal contracts in six months.
And here’s the part that should make your blood boil.
Sixteen of these 27 donors were facing federal enforcement actions, antitrust reviews, labor cases, securities charges. Many of those cases have been quietly dropped or scaled back since Trump took office. You write a check, your legal problems disappear. That’s not a coincidence.
The White House won’t even release the full donor list. They’re hiding it on purpose, because daylight is the one thing pay-to-play can’t survive. A federal judge already ruled ballroom construction has to stop until Congress authorizes it.
Government is supposed to serve the people, not auction itself off to the highest bidder. When access goes to whoever pays the most, working families always end up paying the price.
We either end the corruption, or the corruption will end us.
wapo.st/3QmJjSz
1,576
23,846
49,781
1,354,443
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

More than half of the publicly identified donors to President Trump’s White House ballroom project have won new or expanded federal contracts worth more than $50 billion, according to a report from a government watchdog group. wapo.st/4o9GMHL
594
6,497
11,011
634,011
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Anyone think it’s odd that every event is just a bunch of sycophants standing behind an immobile president pretending it’s normal?
243
2,127
14,316
277,169
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

Cheers, chills, and a standing ovation when RASolute 302 showed unprecedented survival on daraxonrasib for patients with progressive pancreatic cancer
Seldom do you sense you’re witnessing a historic moment in cancer care but this feels like ras targeting has arrived
#ASCO26
92
1,273
6,505
1,149,765
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

A cancer vaccine, using the same core mRNA technology as the COVID vaccine, has shown an almost 50% reduction in the risk of melanoma recurrence or death when combined with immunotherapy.
This is why we fund MRNA technology.

94
1,092
4,469
62,791
Unbelievable.
Impeach & remove.
x.com/EamonJavers/status/206…
Jun 1

“I thought they started to get very boring.”
That’s a remarkable way to describe negotiations involving nuclear weapons, regional stability, American troops, and global energy markets.
The stakes exceed one man’s attention span. Are you worried yet? I am.
88
RT @DavidUllrich202: Neuroscientist Diagnoses Trump’s Brain Damage
In his patterns of speech, inability to state the truth on just about a…
2,286
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

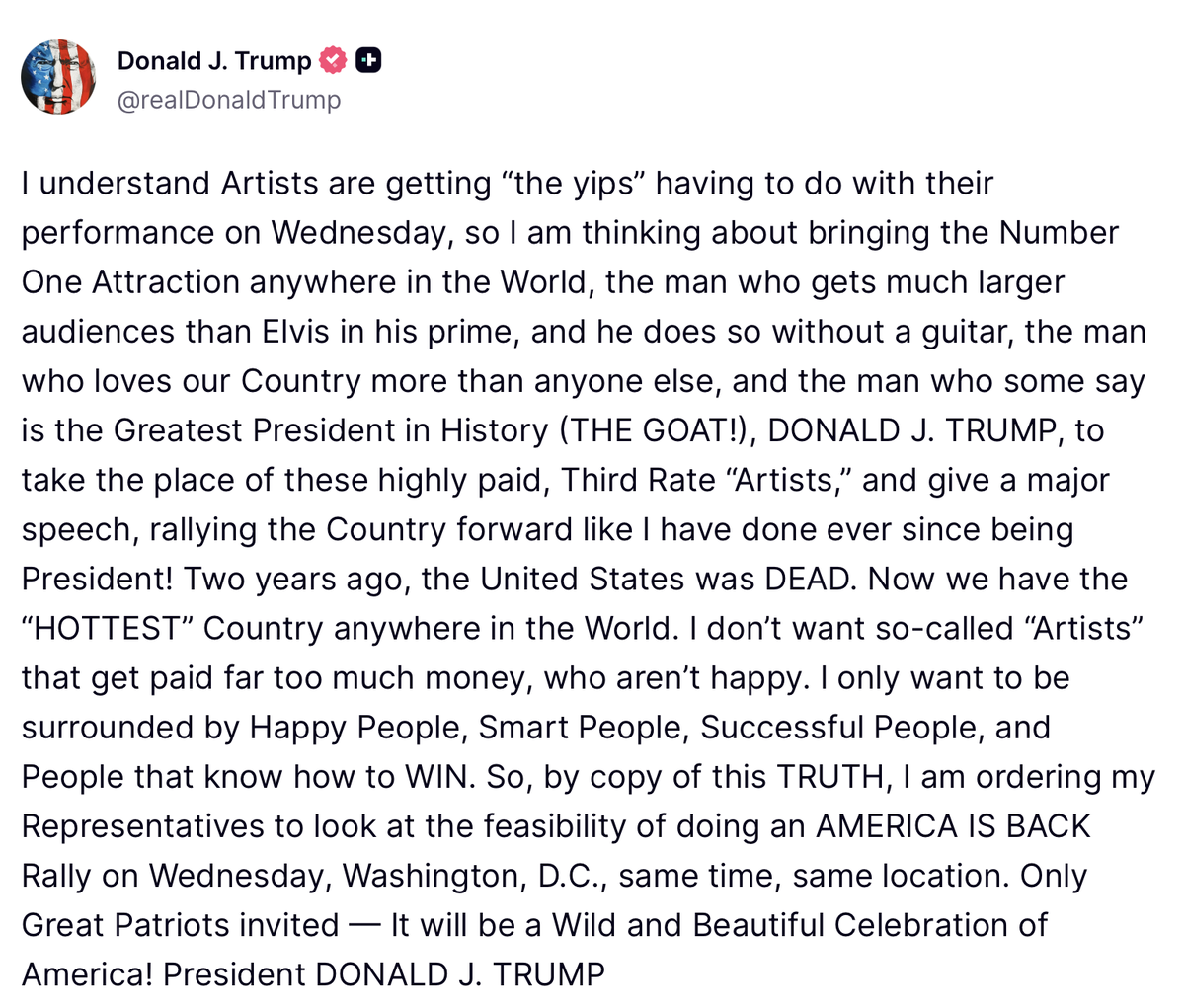
To all of those whining about artist's dropping out of the Freedom250 concert:
Ten years ago, Congress established the America 250 foundation to plan our nation's 250th birthday celebration and they've been working on it since.
Trump fired them all and set up his own Freedom 250 celebration focused only on highlighting MAGA and his accomplishments.
These artists were told they were performing at the first only to discover they would be appearing at the second.
158
3,348
13,555
374,024
LogarithmicDis 🦋🇺🇸🇨🇦⛷️🔬🏨 retweeted

May 30
It’s hard to imagine a greater irony: a celebration of the American Founding—whose entire purpose was rejecting kings, personality cults, and leader worship—being transformed into a vanity project for one man. The Founders fought a war to escape this kind of politics.

117
994
4,576
215,385