
Joined January 2015
- Tweets 1,277
- Following 1,359
- Followers 967
- Likes 991
10 Photos and videos

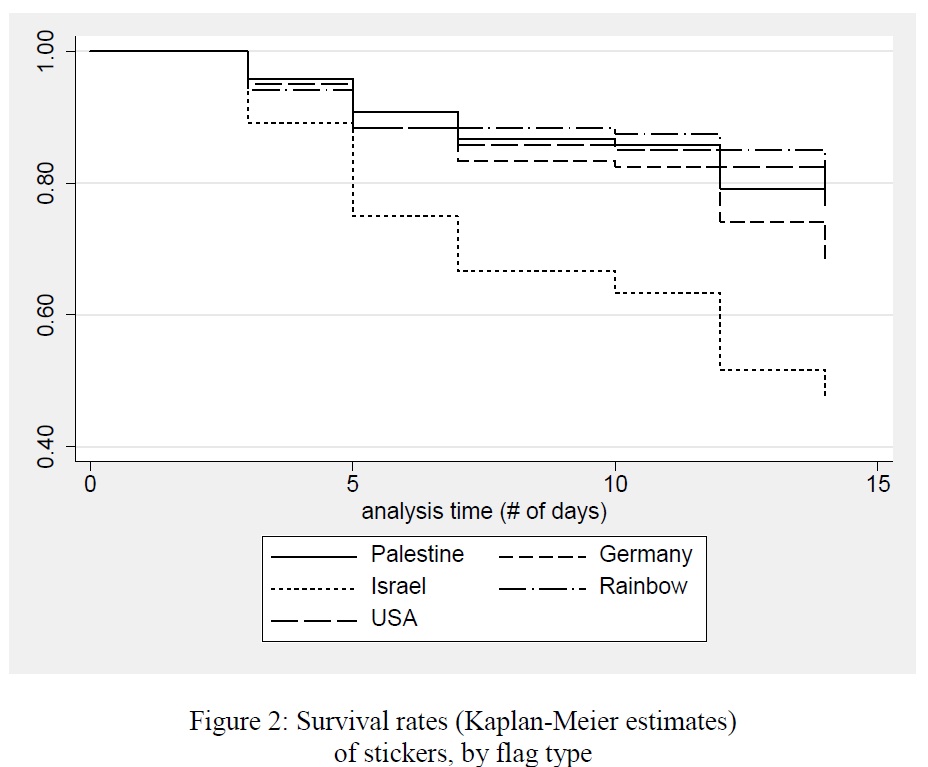








Mark Lutter retweeted

Jun 2
👇 Vortrag eines Sozialwissenschaftlers, wie ausgerechnet die Sozialwissenschaft das 🇩🇪 Bildungssystem ruiniert hat, ist nichts für schwache Nerven:
"Falsch abgebogen: Wie die empirische Bildungsforschung die Bildungspolitik in die Irre geführt hat" 1/18
May 29

... hier kann man sich den Vortrag bei der Heidelberger Akademie der Wissenschaften ansehen, es fängt ein bißchen plötzlich an und hört auch etwas abrupt auf, das hatte technische Gründe, aber es ist bis auf den Schluss und die Analysen alles dabei: youtu.be/GiRCUgh-D80
5
14
66
15,915

Jun 1
Universities are expected to be places of tolerance, universalism, and open inquiry.
Our new study in European Societies finds evidence that visibly Jewish instructors face less favorable evaluations from students than otherwise identical instructors.
doi.org/10.1162/EUSO.a.116
1
36
Mark Lutter retweeted

May 24
Das ist optimistisch. Was wir erleben ist die nächste Phase des Absturzes. Es ist bitter, dass das Cockpit so schlecht besetzt ist.
May 23

Deutschlands Wachstumskräfte schrumpfen nachhaltiger als bislang angenommen. Ökonomen schließen eine Stagnation bis 2030 nun nicht mehr aus. wiwo.de/politik/konjunktur/s…
32
133
1,013
21,440
Mark Lutter retweeted
May 22
"Economic suicide isn’t painless." - ABSTURZ aus Sicht der USA. @WSJopinion wsj.com/opinion/german-autos…
7
48
226
31,346
Mark Lutter retweeted

May 21
Sollte das Wetter am Pfingswochenende wieder so gut werden wie am 1. Mai, werden wir das teuer bezahlen müssen. #Energiewende #EEG

66
138
462
29,069

Mark Lutter retweeted

Hatten wir zwar schon einmal, doch nun ist es amtlich: Die unmöglichste Ausschreibung einer Professur für Mathematik, die es je in Deutschland gegeben hat. Quelle: Ausschreibungsdienst Deutscher Hochschulverband.


93
115
535
53,044
Mark Lutter retweeted
Apr 16
Wie lange wirkt eine Dunkelflaute wirklich? - Das gesamte maximale Energiedefizit beträgt 27 TWh (18 d durchschnittliche Last) und summiert sich über 61 d (knapp 9 Wochen). Diese 61 d umfassen nicht eine Periode mit konstant niedrigem Angebot, sondern mehrere knappe Perioden hintereinander, unterbrochen von kurzen Perioden mit Energieüberschuss think-beyondtheobvious.com/s…
27
68
374
10,847
Mark Lutter retweeted

Mar 9
Schüler aus Zuwandererfamilien werden bei Noten und Schulempfehlungen nicht diskriminiert, sondern sogar bevorteilt. So zeigen es Studien. Aber kann das sein? trib.al/bnLaxoG
208
106
473
45,641
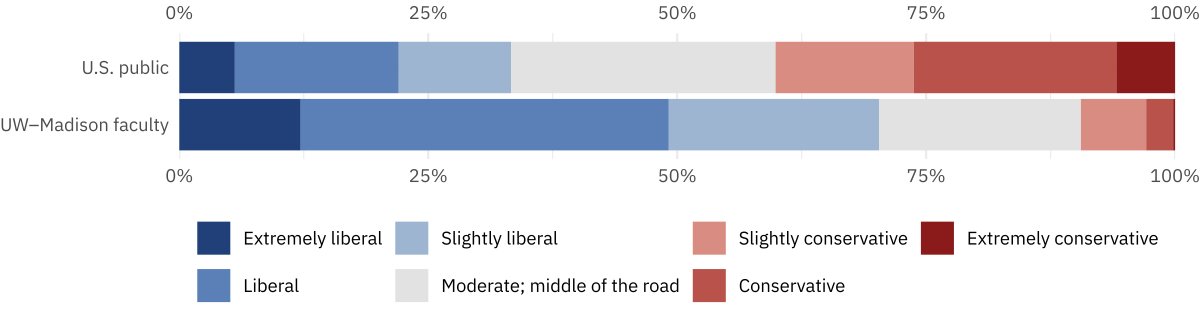
Mark Lutter retweeted

🧵A survey of University of Wisconsin-Madison faculty released today revealed overwhelming ideological bias. Here are some of the key results from the Tommy G. Thompson Center's study:
1. 70% of UW faculty identify as liberal, while only 9% identify as conservative.
105
202
762
91,677
Mark Lutter retweeted

Feb 18
Sex differences in fundamental social motives either remain intact or are even amplified in societies with greater gender equality,
Humans rely on a suite of fundamental social motives to navigate recurring adaptive challenges. Using data from 14 532 participants across 42 societies, we examine sex similarities and differences in the strength of these motives…
Men and women reported distinct motivational levels, reflecting a robust cross-cultural pattern of sex differences. Consistent with differential parental investment and sexual selection theories, across societies, women reported stronger motivation for threat avoidance, long-term pair bonding and caregiving, while men reported stronger motivation for status and mate-seeking.
Notably, sex differences in motive strength are maintained or even amplified in societies with greater gender equality, suggesting that such contexts may facilitate fuller expression of sex-linked motivational patterns. This challenges theories that attribute such sex differences primarily to sociocultural inequality. Consistent with the gender equality paradox, these findings suggest that greater gender equality may enhance, rather than constrain, the sex-differentiated motivational profile.
2
25
75
10,002
Mark Lutter retweeted

Jan 15
Rich women fake more orgasms.
In couples where women out-earn their partners, women are roughly twice as likely to report faking orgasms compared with couples where men earn the same or more.
Research suggests this isn’t about deception or manipulation, it’s about managing male insecurity.
The key factor isn’t income itself, but women’s perception that their partner feels threatened or insecure in his role as provider.
When women believe their partner’s masculinity feels fragile, they report higher sexual anxiety, less honest sexual communication, lower sexual satisfaction, and fewer orgasms.
Faking orgasms appears to function as a relationship-smoothing behaviour, used to protect a partner’s sense of competence and avoid conflict.
In short: when a man’s status feels precarious, sex becomes less honest, not more passionate.
74
19
547
99,409
Mark Lutter retweeted

Jan 6
I didn't even get to the abstract. I'll let you read that for yourself, because I just don't have the energy to summarize it for you. 😵💫

54
23
420
85,265
Mark Lutter retweeted

This is deeply troubling.
Researchers are more likely to choose statistical models whose results align with their ideological priors.
Seventy-one research teams independently analyzed the same dataset on the effect of immigration on public support for social welfare programs.
Teams composed of pro-immigration researchers were more likely to conclude that the effect was positive. Teams composed of anti-immigration researchers were more likely to find a negative effect.
Let me repeat: they analyzed literally the same dataset.
Full paper in the first comment.

212
778
3,136
231,060
Mark Lutter retweeted

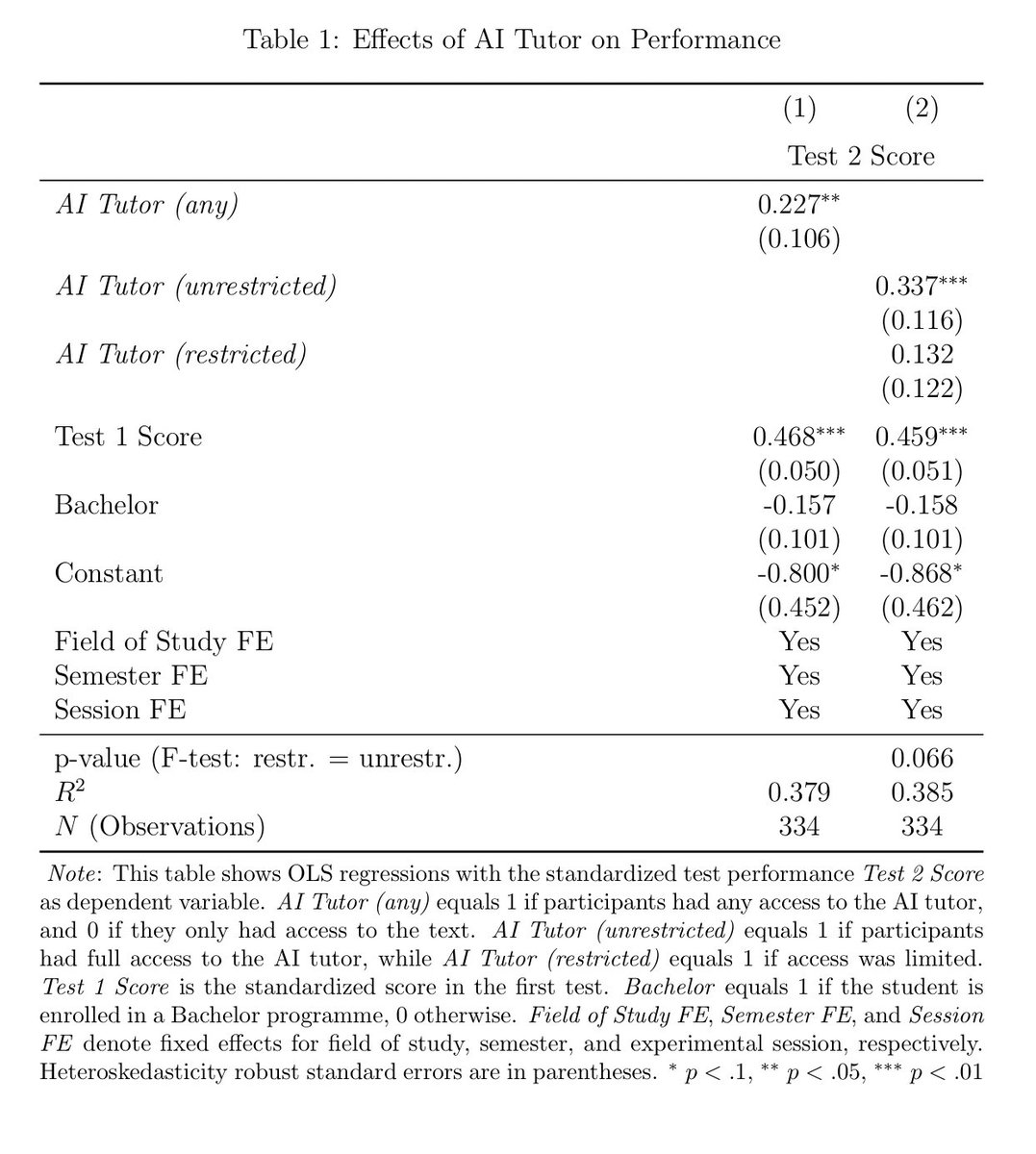
Jan 2
"Giving students unrestricted access to AI tutors while they are studying harms their later performance on exams when they don't have AI assistance."
Maybe not!
In this new experiment, students studied economics textbook material during a 25-minute session to prepare for a subsequent test.
The experiment had three conditions:
1. In the restricted-access condition, they gained access to the AI tutoring system after 10 minutes.
2. In the unrestricted-access condition, they had continuous AI tutor support throughout.
3. In the control condition, students studied the textbook material unaided.
All students then completed the same incentivized test without access to the textbook or AI tutor.
The researchers found that unrestricted access to the AI tutor significantly outperforms restricted access noticeably.
This contradicts concerns about students overly relying on AI tutors.
Restricted access did not produce a statistically significant impact over studying without AI.
"AI tutoring functions less as a substitute ... and more as a scaffold that supports comprehension when students experience difficulty."



4
8
47
10,116
Mark Lutter retweeted
31 Dec 2025
Are students biased against female professors because they are, well, female?
Many academics hold as near gospel the claim that student evaluations are systematically gender biased. However, more recent evidence suggests we should pump the brakes a bit on that conclusion.
As it turns out, answering whether student evaluations are gender biased convincingly is tricky for several reasons.
First, students usually aren’t randomly assigned to instructors. Different types of students may select into classes based on an instructor’s gender.
Second, instructors of different genders may teach differently. As a result, differences in student evaluations could reflect teaching style rather than gender per se.
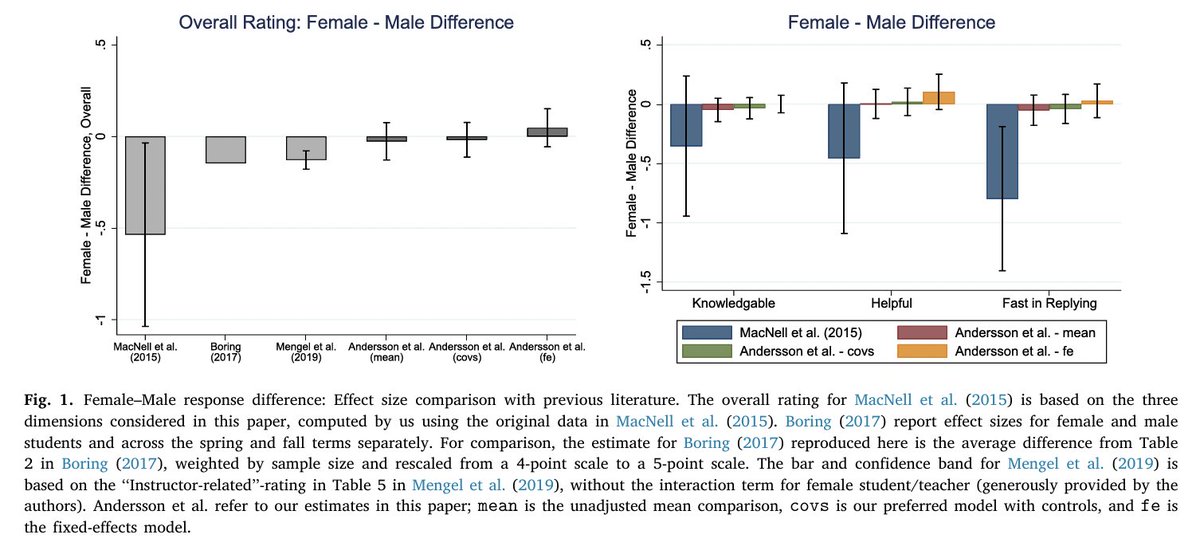
One might address the first problem by randomly assigning students to classes. Studies such as Boring (2017) and Mengel et al. (2019) do exactly this. But these studies do not fully address the second problem: they cannot cleanly separate instructor gender from instructor behavior.
To deal with both issues simultaneously, a widely cited 2015 paper by MacNell, Driscoll, and Hunt used an online course as a laboratory.
In their study, two assistant instructors (one male, one female) each taught two discussion sections: one under their real identity and one under the other instructor’s gendered name and identity. As a result, students evaluated the same instructor under different perceived genders.
Because the course was fully online, all interaction occurred via discussion boards and email. This design feature is crucial, as it strips away in-person cues—such as appearance, voice, body language, and physical presence—that are tightly bundled with gender in face-to-face classroom settings.
MacNell et al. found that students rated the male identity higher than the female identity. In other words, perceived gender appeared to drive student evaluations.
Given how consequential student evaluations are for promotion and tenure, the paper received enormous attention. It has been cited almost 1,300 times and it was widely covered in the media and discussed on social media.
In short, the MacNell et al. study helped cement a now-common belief in academia: that student evaluations are inherently gender biased.
But the MacNell et al. study has important limitations. Most notably, the experiment involved only 43 students. With samples this small, estimates are highly sensitive to noise and vulnerable to Type S (sign) and Type M (magnitude) errors—meaning estimated effects may be exaggerated or even flip direction by chance.
Despite this, the result was widely generalized.
Fast forward to this year. A team of economists led by Andersson conducted a much larger, tightly controlled double-blind field experiment in a university setting. Crucially, neither students nor instructors knew that gender was being experimentally manipulated.
In contrast to MacNell et al., they find no evidence of bias against female instructors in student evaluations. Their study is much better powered, and the resulting confidence intervals are tight enough to rule out effect sizes similar to those reported in earlier influential work.
The takeaway, in my view, is not that gender bias cannot exist in student evaluations. Rather, it is that the magnitude and generality of such bias were likely overstated based on early, underpowered evidence. As with many findings that become academic "common knowledge," stronger designs with larger samples paint a more nuanced picture.
Student evaluations may be gender biased in some contexts—but not in all.
What do you make of these new findings?


24
64
490
68,346
Mark Lutter retweeted
29 Dec 2025
"Physical attractiveness is linked to higher earnings for both genders, with a stronger and more robust effect for men."
The general consensus appears to be that attractive individuals have considerable advantages in many areas of life. [But] highly attractive women (men) in predominantly male (female) occupations may experience attractiveness penalties. This occurs because attractive persons could be perceived as gender-typical and therefore be ascribed gender-typical traits, potentially creating a perceived mismatch between those traits presumably necessary in an occupation and those attributed to the person based on their appearance.
How do returns to physical attractiveness in the labour market vary depending on the alignment between an employee’s gender and the gender composition of their occupation? This is the first study to examine how attractiveness and gender-atypicality interact in the German labour market and to use a multiverse analysis.
Our findings reveal that physical attractiveness is robustly associated with higher earnings for both women and men in the German labour market. We estimated the median magnitude of the earnings disparity between men who are perceived as being attractive and those who are not as 3 per cent. For women, the same number of specifications returned smaller effect estimates—a median difference of approximately 2 per cent in hourly earnings.
It is an interesting finding that both the effect size for men is larger than for women and that the effects for men are more robust, understood as the proportion of specifications that are statistically significant. These results suggest that attractiveness is linked to higher earnings for both genders, with a stronger and more robust effect for men.
However, we do not find evidence that attractive individuals face earnings penalties when employed in occupations typically dominated by the opposite gender. This challenges assumptions about the role of physical attractiveness in contexts of occupational gender incongruence
3
11
44
11,016
Mark Lutter retweeted

25 Dec 2025
Who would've thought? Immigration researchers (who are far more pro-immigration than the general public) tend to make analytical choices that produce pro-immigration findings. This skews the literature & fuels public distrust in science. Fascinating study. laurenzguenther.substack.com…

38
299
2,390
86,105
Mark Lutter retweeted
24 Dec 2025
Most people believe that there is more gender inequality in society than they personally experience.
Despite substantial gender equality in highly gender-egalitarian countries like Germany, perceptions of persistent inequality remain widespread. We examine systematic perception gaps that may explain this disconnect. In a survey of 735 German adults, participants reported their perceived societal and personal gender inequality, estimated others’ perceptions, and indicated their attitudes toward gender equality measures.
Both women and men perceived women as less fairly treated than men. Women reported a classic person–group discrepancy, perceiving more inequality in society than in their own lives, and projected this discrepancy onto ‘average women.
This creates a logical paradox: Although it is possible that there is more inequality in society overall than some women personally experience, it is statistically impossible that there is more inequality in society than all women personally experience. We refer to this phenomenon as a pluralistic illusion: the logically incoherent meta-belief that most people believe that there is more inequality in society than they personally experience.
We also find a better-than-average effect such that participants see themselves as more supportive of gender equality than the average person. Finally, both male and female participants believed that average men would not perceive much societal inequality, even though the male participants in our sample actually did . This extends research on pluralistic ignorance by showing that male and female participants substantially underestimate the degree to which men perceive gender inequality in their society.
We argue that our finding is the opposed of the known stereotypical “women are wonderful” effect, namely a stereotypical “men are terrible” effect. This pattern highlights an extreme asymmetry in views on gender inequality
.
2
14
54
7,119
Mark Lutter retweeted

20 Dec 2025
The study is affected by collider bias and unlikely to be a real effect zenodo.org/records/18002186
2
34
3,660