
Joined November 2021
- Tweets 2,859
- Following 141
- Followers 241
- Likes 149,429
152 Photos and videos









David Peterson retweeted

Dear US government,
Since you've just blocked Fable and Mythos on critical national security grounds, here are some other tools that pose a similar threat to the American people:
- Microsoft Teams
- SAP
- Salesforce
- Jira
- Outlook
Please do what you must to save America 🇺🇸

‼️🚨 BREAKING: Amazon researchers snitched to the US government about jailbreaking Fable 5 and Mythos 5, forcing Anthropic to immediately shut down worldwide access.
A security export control directive from Commerce Secretary Howard Lutnick enforced the action.
Anthropic is fighting the directive and calls it a misunderstanding.
This isn't the first clash. The Trump administration had already tried to get Anthropic to pause the release of its latest models before this directive landed.


601
2,289
23,990
1,405,383
"And before that, PGP encryption was considered a weapon. History repeats."
Jun 13

Fable isn't the first.
In 1999 the department of defense blocked exports of the PowerMac G4 for crossing the 1 gigaflop threshold.
Steve Jobs turned it into an ad.
28
David Peterson retweeted

Jun 13
Dario writes:
> "Regulation & public safety"
> "...and their release should be blocked or reversed as a threat to public safety"
> "The government should have the power to block or deter deployment of the model"
Congrats! Looks like you got your wish:
x.com/AnthropicAI/status/206… .
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
2
3
435

David Peterson retweeted

Jun 7
Longpost about the biggest misconception I see people having by FAR on LLMs right now.
Know the difference between the harness, the model, and serving inference.
Vast majority of problems I see people having right now are due to the harness. Each provider has it's own unique thing that's wrong with it. Claude is unique like the state of California in that it taxes/is bad at everything.
Harness: This is the traditional software that calls the model api from the provider. This is what you install on your computer or the website you visit to access the LLM.
Common harnesses:
- Claude Code
- Codex
- Droid
- Pi
- OpenCode
- OMP ❤️
- Antigravity
- Copilot
- chat.com, claude.ai, or google.com in a web browser could technically be considered a harness
Harnesses are most people's bottleneck because things like tool calls, system prompts, mcp servers, skills, subagents, change the way the api is called and its actually used for gathering information and your day to day work dramatically. Claude code or codex can use 8x the tokens in certain contexts when programming compared to pi or omp purely due to hashline editing and tool calls in the system prompt. Planning and subagent management also makes work significantly faster for larger tasks. Compaction in codex is so good the model needs 1/4 the context that claude or gemini does to achieve better results which allows them to serve more users simultaneously with available vram.
Model: This is the actual LLM. The weight values which were trained and deployed somewhere which you access from the harness on your machine via an api. This is what people are benchmarking and typically talking about when they post evals.
Common Models:
- Claude Opus 4.8
- GPT 5.5
- Gemini 3.5 Flash
- Deepseek V4 Pro
- Qwen 3.7 Max
- Kimi K2.6
- Composer 2.5
People run evals to determine model quality for different tasks. Most engineers are using them for agentic coding, where terminalbench is king, and swebench to a lesser extent currently. For academic research and "white collar work" (i've written about this gimmick previously) there are other evals people target.
Serving and Inference: This is the actual computer and infrastructure network the model is running and being served on remotely. This can vary wildly depending on the provider.
- Google and XAI are the only ones that own their full stack vertically right now. Google has vertically integrated all of their models to use in house TPUs rather than GPUs to run on their cloud network (GCP, which they also own) extremely reliably and quickly.
- OpenAI has secured deals with Microsoft and now AWS and others to have guaranteed compute capacity until 2030 or so and preplanned most of their capacity already. They have deals with nvidia and cerebras directly now for datacenter buildouts.
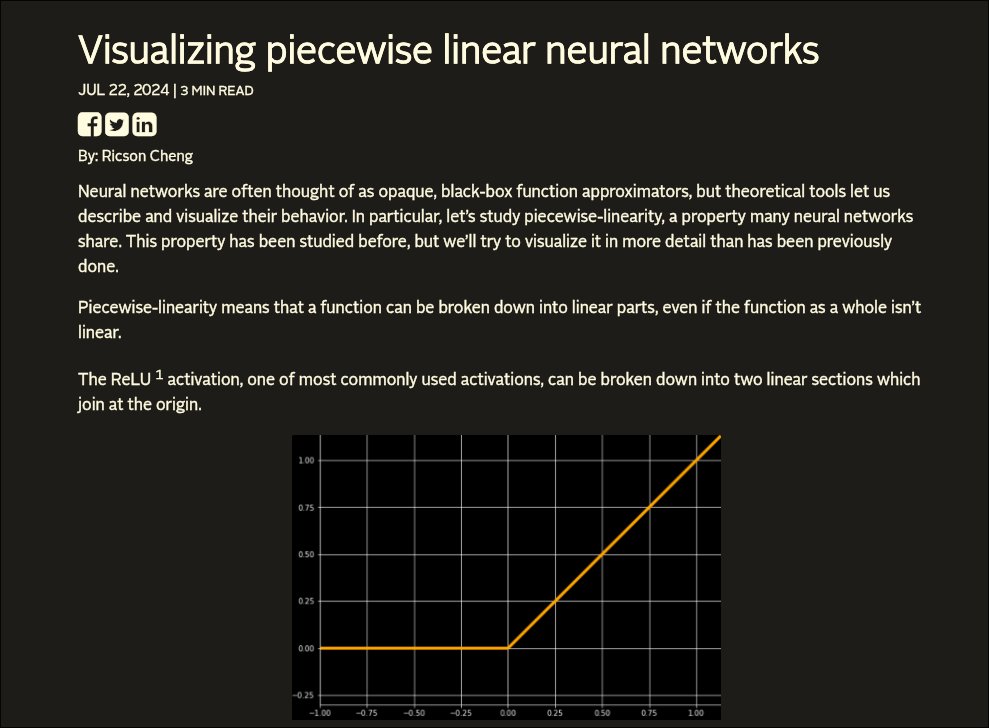
- Anthropic didn't buy nearly enough compute the last few years. Now they are desperately selling off equity and turning into corporate frankenstein to meet demand. They are currently splitting the inference they give you between: GPUs, TPUs, AWS, GCP, SpaceX, bunch of other random crap. This is completely unmanageable in any reasonable period of time given the current growth of the space.
Chinese models are open source. Most of the chinese infrastructure is completely jank and slow, but great news! There's places hosting it for you like firworks, GMI, and others on the latest blackwell gpus to run it at 5x the speed you get through the official chinese apis. Or you can host them yourself! The chinese models are also a fraction of the price because power and the older hardware they have is so cheap. DSV4 flash performs the same as sonnet for actual pennies, or you can pay the same prices as the western providers on fireworks or gmi to get something that absolutely flies like gemini does. Kimi charges PER TURN rather than per token so you get 14x the tokens weekly on their chinese sub that you would get on gpt pro for something at gpt 5.4 xhigh's intelligence level.
There are different techniques people use to serve the models more effectively as well to more customers:
- Quantization truncates the weight values in memory to use less vram at the expense of the model getting "dumber" which claude does during peak hours in some locations and local hosters often use to take advantage of weaker gpus for personal use
- Smaller models can perform better than larger ones on actual task evals in some cases or be trained or fine tuned to be more token efficient to use less compute while performing similarly from a user's perspective
- Things like MOE allow models like deepseek or qwen to get split across lots of smaller/cheaper gpus at once and split off smaller more specialized models for research and specialized use cases
- Specialized silicon like Google's TPUs, Trainium, Cerebras, Groq, allow the models to be hosted at much much higher speeds at higher cost due to the specialized silicon and software stack
- Newer generation gpus or gpus with higher memory bandwidth or blackwell hardware are the single largest determinant in how fast a model will run that you are hosting followed by custom kernels, serving configuration, parallelism etc. However everything revolves around the silicon. Nvidia is still king because of Cuda and blackwell gpus have minimum 2x the memory bandwidth of any other gpus on the market. TPUS are faster still but far more specialized and difficult to get/set up. AMD/Apple chips are significantly slower albeit cheaper in some cases.
Why all of this is important:
Many of the issues people experience with claude for example, or reasons you see wildly different experiences from two people using the same model are ACTUALLY because of issues with the harness or serving. Some examples
- Opus 4.8 works okay on bedrock in opencode at 2am BUT Opus 4.8 on a $20/mo sub during peak business hours served at fp8 quant god knows where on medium thinking in claude code Is completely useless.
- Gemini 3.5 Flash or 3.1 Pro feels completely useless in gemini cli and gets stuck in loops constantly BUT in OMP it's as good as 5.5 is at 10 times the speed
- Qwen 3.6 27b locally feels awful in opencode on a macbook or dgx but absolutely flies at 10x the speed with no tool calls or thinking in pi with nvfp4 and MTP on a 5090 using raw bash and web search.
Why gpt is so uniquely good at the above:
Even if it's slow during the day from the massive userbase, it's the only one that just fucking works 24/7. It's not the fastest or the prettiest, but it's the most reliable and consistent out of the box with the least setup by far.
Why claude is so uniquely bad at the above:
The default harness is bad, the user experience is flashy, but it's the most expensive by far, you get wildly different quantizations, speeds, and answer quality depending where it's being hosted, and they have one nine of uptime status.claude.com/. This is largely due to organizational issues at the company which will *never* be resolved due to the cap table being so split now and internal politics.
Be extremely wary when someone says "I'm using claude" "I'm using deepseek" "I'm using gemini" two different people could be having wildly different results depending on what harness they're using, what model, thinking, and where it's being served at what time of day.
To summarize:
GPT - Slow Harness - Great model - Great Infra
Google - Shit Harness - Great model - UNMATCHED infra
Anthropic - Shit Harness - Okay model - Shit Infra - Great marketing and sales team
(hence California Income/Property/Sales tax analogy)
Chinese models - It's like linux, here's the parts, build it yourself! or use the hosts in china for dirt cheap or expensive western hosts for extremely fast infra
You can use ANY harness you want with ANY provider if you're willing to set it up
39
25
332
58,434
Jun 13
This is living up to my initial impressions of Fable 5.
Seems to have "ethics" turned up to 11, and will flat out refuse to do things for the flimsiest of reasons. Even though it is nothing at all to do with Cybersecurity or Biology
“you can just not do things” ~ Claude #Fable5

138
David Peterson retweeted

Jun 11
A toothpaste company has quietly killed the entire market research industry and nobody is talking about it.
Colgate published a paper showing you can predict real purchase intent at 90% accuracy by simply asking LLMs to roleplay customers.
And this is beyond insane.
If you ask an AI, "Rate this product from 1 to 5," it gives safe, middle-of-the-road garbage.
So researchers invented a method called Semantic Similarity Rating (SSR).
Instead of asking the AI for a number, they asked it to roleplay.
They gave the LLM a demographic profile. They showed it a product concept. And they asked it to write down its raw, unfiltered thoughts.
Then, they used a semantic model to translate those written thoughts into a numerical score.
The results are staggering.
Tested against 57 real corporate surveys and 9,300 actual human responses, the synthetic AI consumers matched real human buying behavior with 90% reliability.
They perfectly mirrored how different age brackets and income levels react to price changes.
And they provided detailed, qualitative feedback that was deeper and more critical than what actual humans wrote.
This destroys the economics of traditional market research.
You don't need to wait a month to see if a product will sell.
You can simulate 1,000 hyper-targeted customer interviews overnight.
You can A/B test pricing across every demographic instantly.

Community note
The 90% figure refers to the AI method achieving 90% of human test-retest reliability for purchase intent surveys, not 90% accuracy in predicting real purchases. It was tested on personal care products in categories LLMs know well. arxiv.org/abs/2510.08338
228
939
7,579
700,684
David Peterson retweeted

Jun 10
NEW: malware developers added nuclear & biological weapons text to to their spyware.
Goal? To trigger LLM safety refusals... so that their spyware wouldn't be analyzed by an AI security scanner.
Cleanest practical example I can think of for why over-indexing on first order safety alignment is risky.
When closed (and open) models ship with aggressive refusals, they will be sprinkled with second-order blindspots that attackers will discover...and exploit.
We are only in the earliest days of attackers leveraging these features, and it wouldn't surprise me if users systems that need to handle complex cybersecurity issues demand that models be less safety-blunted.
In the weeds: @SocketSecurity's post also shows why intention matters in how you design a malware analysis pipeline to avoid prompt manipulation.
H/T to colleagues that shared this with me socket.dev/blog/mini-shai-hu…
227
2,153
12,637
1,544,816
David Peterson retweeted

Jun 5
Jane Street guys are so incredibly cracked. Quite a few of their blogs are top tier and extremely intuitive. This one is a personal favorite of mine by @The_Numbat : thenumb.at/Functions-are-Vec…
Jun 5

jane street has some interesting blogs
too bad it would take a week to understand each
blog.janestreet.com/using-gr…
blog.janestreet.com/can-you-…
blog.janestreet.com/i-design…
blog.janestreet.com/visualiz…


18
148
2,411
323,936
David Peterson retweeted

Jun 5
jane street has some interesting blogs
too bad it would take a week to understand each
blog.janestreet.com/using-gr…
blog.janestreet.com/can-you-…
blog.janestreet.com/i-design…
blog.janestreet.com/visualiz…
37
268
3,129
886,164

Best models I’ve seen this week for your hardware: if you have 8-16gb you have a competitive model finally!
———-
4gb - 8gb:
- minicpm5: this model was built for agentic tool use on tiny machines: huggingface.co/openbmb/MiniC…
- tops benchmarks in weight class
- extremely small
- great for using in projects with AI
- blazing fast
————
8gb - 16gb
Most exciting model
- LFM-2.5-8B: huggingface.co/LiquidAI/LFM2…
Frontier for vram:
- 8b moe with
- 1.5B active
- trained on 38T tokens (MASSIVE)
- 131k context
————-
96GB - 128GB
- ds4flash either q2 or reap q4
huggingface.co/antirez/deeps…
- or
huggingface.co/0xSero/DeepSe…
- very strong agent
- logical pleasant to talk to
- good in Hermes
- fast
- high contexts for little vram
————-
196gb
Step-3.7-Flash: huggingface.co/stepfun-ai/St…
- 199B with 11B active (FAST)
- vision support!
- its predecessor was topping benchmarks for 3 months
- 256k context
- 150 tok/s on 6000s
67
147
1,345
138,880
David Peterson retweeted

Local minima are rare in high dimensions because a strict local minimum has to curve upward in every direction, so all Hessian eigenvalues must be positive.
In a D-dimensional toy model where eigenvalue signs are independent, that’s a 2^(-D) event. In GOE-like random matrix models, positive definiteness is even rarer, roughly exp(-cD^2).
So as dimension grows, random critical points are much more likely to be saddles than minima. This is one reason high-dimensional optimization is often a saddle-escape problem, not a bad-local-minimum problem.
Wrote up some of the math here: grantstenger.com/local-minim…

the greatest whitepill of all is that local minima are rare in high dimensional spaces
34
192
2,182
303,084
David Peterson retweeted

May 27
The key unstated fact is that math professors still have too much integrity to give passing grades to students who don't know math.
May 26

"Current admissions practices do not provide a sufficiently reliable check on mathematical readiness for STEM majors."
Over 280 University of California STEM faculty have signed an open letter calling on the Board of Regents to reinstate standardized testing in admissions:

43
105
1,746
419,674
May 24
A productive weekend, have this evening submitted 3 compsci assignments, over 40 pages in total.
2
33
May 23
> "Often, the expensive technology overshoots customer demand, and the cheap one gets just good enough in terms of performance."
I feel that we're just on the cusp of this happening with running local open-weight models.
May 22

Low-end disruption.
That's the key phrase to think about when you contemplate the medium-term future of AI.
Nearly 30 years ago, now, Clayton Christensen identified a pattern of technology companies plowing huge amounts of capital into technology to pursue ever-increasing capacity and higher margins. Bigger steam shovels. Bigger cars. Bigger disk drives.
He also noticed what tends to happen to them. Low-cost competitors find cheaper ways to serve niche markets. Over time, both the dominant expensive technology and the cheaper, lower-spec alternatives improve.
Often, the expensive technology overshoots customer demand, and the cheap one gets just good enough in terms of performance. At which point the bottom abruptly falls out of the market for the expensive technology, and the disruptor inherits the Earth.
The former incumbents are left wondering what happened. "Bbut.. our stuff was better!" Yes, it was. It was better at every single point in the timeline, including the moment when the bottom fell out.
Just good enough and cheap beats better but more expensive. That is the harsh lesson of dozens of technology disruptions.
Now consider the way that low-cost, low-capability AI engines like the little machine I described in my quoted previous post are beginning to nibble at the outer edges of the market for AI inference.
They're not very good yet. But there is a very clear path for them to get better. Hardware improvements. Software improvements. Yes, they'll get a little more expensive, and a lot more capable.
Huge centralized data centers selling remote operation with subscription fees, versus a whole bunch of smaller, distributed on-premises AI appliances that aren't as powerful, but don't incur subscription costs forever and are a lot better for security and privacy.
The question isn't if low-end disruption will cut the legs out from under the big AI providers. It's how soon.
1
1
67
May 24
Just read an article about a very impressive 7B model:
xda-developers.com/tried-new…
Further confirming my thoughts that we're on the cusp of something very special when it comes to what we can do with locally running models.
2
47
May 20
Ah if only... is a nice dream world to be living in. Maybe one day?
May 19

It is a shame that the simple act of transferring a large block of data as fast as possible over the internet is not handled effectively by the primitive operating system calls. You either multiplex over parallel persistent TCP connections to combat head-of-line blocking and slow starts, or reinvent reliable delivery and flow control over UDP.
QUIC has a lot going for it, but it is a large library (six figure LoC!) and conflates security and performance in a way I don’t love. There is also fundamental information about competition with other processes and link layer congestion that should be useful, but is unavailable to user libraries.
You should be able to just write(really_big_buffer) and it is all taken care of for you.
1
48
David Peterson retweeted

May 9
Will Smith eating pasta is now the official benchmark for AI progress.
This is actually insane.
850
4,647
107,382
9,587,001
David Peterson retweeted

May 8
Microsoft just gave Anthropic the same enterprise deployment access inside Office as Copilot. Microsoft is OpenAI's biggest investor.
Claude for Excel, PowerPoint, and Word are now generally available. Outlook is in public beta. GA is the line where an add-in clears procurement and gets pushed through the same admin panel as Copilot itself. Anthropic just crossed it.
The math on that deployment surface is brutal. Microsoft 365 sits at over 450 million paid commercial seats. Copilot, after 2.5 years of full-court selling by Satya, hit 20 million paid seats last quarter on the FY26 Q3 call. That's 4.4% penetration on the most aggressively marketed AI bolt-on in enterprise software history. The other 430 million seats are now reachable by Claude through the same IT deployment surface, the moment a CIO signs the manifest.
The cross-app context is the second piece. A model that holds the same conversation as you move from Excel to PowerPoint to Word to Outlook eliminates the most expensive friction in AI productivity work: re-prompting every time you switch apps. Microsoft Copilot's "Work IQ" was the entire premise. Anthropic just shipped parity on that mechanic on Microsoft's own turf.
The strategic paradox is that Microsoft pays OpenAI billions, runs Copilot on their models, then signed off on a competing AI getting GA-grade integration across Excel, PowerPoint, Word, and now Outlook beta. Why allow it? Microsoft's real product is the platform. Lock Claude out and you invite antitrust attention on every Office add-in. Let Claude in and Office gets stickier than ever. Microsoft wins either way. OpenAI's integration moat inside Office quietly became a tie.
Citadel signing on as a launch customer for Claude for Excel signals where serious finance work is heading. Vals AI's Finance Agent benchmark currently has Opus 4.7 at 64.37%, the top score in the category. Buy-side analysts will install whatever scores highest on the modeling task they actually do, regardless of what their CIO is paying Microsoft for Copilot.
The most valuable real estate in productivity AI was always going to be the cell next to your DCF. Anthropic just got cleared for full enterprise deployment.

Claude for Excel, PowerPoint, and Word are now generally available, and Claude for Outlook is in public beta.
As Claude moves between your Microsoft apps, it carries the full context of your conversation.
11
16
183
43,480
I remember using Ask Jeeves :-(
May 2

I regret to inform you that Ask Jeeves is dead. The site closed yesterday. Web 1.0 lost another founder.
Ask Jeeves: 3 June 1996 - 1 May 2026. Send no memes.

1
37