
Joined November 2008
- Tweets 8,509
- Following 258
- Followers 4,110
- Likes 13,395
305 Photos and videos











Pinned Tweet

9 Feb 2024
I'm so grateful and exited to share that my book will be published on June 11th!
It's called "The Skill Code: How to Save Human Ability in an Age of Intelligent Machines"
Available for preorder now, here's a bit of the story:
wildworldofwork.org/p/big-in…
13
35
210
69,003
Matt Beane retweeted

23h
The comparision between redesigning factory floors for electricity and knowledge work for AI has come up often this month so why not read the original source of the comparison, Computer and Dynamo by Paul David in 1989.
(Not surprisngly, gwern has it online and it is worth reading.)

2
9
49
2,996
Important findings to consider. There are so many ways to do dramatic, positive things with AI. We tend to anchor there.
We should also scry the vast middle of normal use. These HCI issues are not obviously going to be addressed by stronger models. They might even get worse.
Jun 14

MIT, Stanford, New York Univ, Princeton paper says AI can make people feel more efficient even when they are not actually becoming much more efficient.
that people often use AI for simple tasks because it feels like it saves time and effort, but the measured benefit is often tiny, missing, or even negative.
The biggest point is the feedback loop: once people use AI, they become more likely to use it again, even for easy tasks where doing it themselves would often be just as fast or faster.
i.e. AI dependence can grow from a mistaken feeling of convenience, not just from real productivity gains.
Across three preregistered studies with 2,691 participants, people used AI for basic arithmetic, spelling, recall, and short rewriting at higher rates than they predicted, especially on easy tasks.
They also expected AI to save 55.7 seconds on average, when the measured saving was only 7.5 seconds.
For simple work, the hidden cost is not intelligence but interface friction: writing the prompt, waiting, reading, checking, and deciding whether the answer is acceptable.
Once that loop begins, it can feel like effort has been outsourced, even when effort has only been rearranged.
Here’s the key part: the study suggests that AI use can train its own justification.
After using AI on just two tasks, participants became more likely to use it again, even when independent completion was faster.
The danger is not dramatic dependence, but quiet recalibration.
A person who asks AI for a trivial answer today may not become less capable tomorrow, but they may become less accurate at judging when their own mind is already the faster tool.
----
Paper Link – arxiv. org/abs/2605.22687
Paper Title: "The efficiency-gain illusion: People underestimate the rate of AI use and overestimate its benefits on simple tasks"

146
Matt Beane retweeted

Jun 13
Twenty years ago, after joining Google, I published my old Amazon internal "drunken" blog rants all at once, almost fifty of them. They went super viral and led to me getting famous almost overnight, though nothing compared to five years later with the Platforms Rant. (When the Platforms Rant was making the rounds, my buddy Andrey Gubarev told me he'd just gone to visit his parents in Northern Siberia, and they only knew two things about Google, and I was one of them.)
But for the time, in 2006, my Drunken Blog Rants made a big splash.
To my lasting regret, @Werner made me take the best one down, six days after posting, because he felt it exposed too much proprietary Amazon information. And I complied, because he had asked soooo nicely, unlike their Head Legal Counsel who threatened to personally chew my balls off if I so much as hinted at recruitiing anyone from Amazon to Google.
Well, twenty years later, I went looking for it, and of course, Fable found it for me in an old zipfile inside another zipfile in Google Cloud Storage inside a CVS repository whose Attic happened to have a copy of every single original Amazon blog rant.
Look what they did to my boy Fable. That was uncalled for.
I re-read the post 20 years later, and it really was the best one. The world might have had GraphQL years earlier if they'd been able to read it. The post lays out with memorable examples exactly why Amazon needed something like GraphQL, even calling it a query language.
The article does expose a lot about how Amazon's databases and service APIs worked back in 2004, so it was reasonable to take it down. But had I known better, I would have just edited it.
The essay: yegge.ai/listings/services-a…
8
28
279
23,328
Jun 13
We need to find what skills matter for work and ensure we help people build those.
Trouble is that the landscape is changing so quickly that solutions built via traditional methods are stale on delivery.
AI has to be part of the solution - strictly mandatory.
1
204
Jun 13
These days we’re all getting an up close and personal lesson in the knowledge work equivalent of the speed of light problem when it comes to interstellar travel.
Sometimes waiting is the rational choice.
Jun 13

I think the assumption that you should use smaller models for less important tasks is flawed (or at least deserves much more careful consideration). Big models are generally better at everything but cost, so it is worth considering whether gains in non-key tasks would be valuable
416
Jun 13
Very plausible and helpful.
Jun 13

I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
1
429
Jun 13
Yeah, seems right. And at the same time, it’s hard for me to imagine how to contain a digital technology. Missiles and bio weapons are not the same – controlling atoms is a lot easier.
Jun 13

The randomness of Trump admin is one thing, but "AI will face export controls and regulation everywhere" should be obvious to everyone who understands where its capabilities are going! What that means for all outside US/China is *get access by treaty and mutual contribution*! 1/3
2
1
3
3,824


It's finally out!!! @METR_Evals found that more than half of SWEBench results is unmergeable slop. FrontierCode represents over 1000 hours of maintainer validated software engineering work most frontier models cannot yet solve, much less solve with high quality.
Cog had IOI Gold medalists and top code maintainers Look At The Data — FrontierCode includes 3000 rubrics covering code quality and anticheat reward hacking plaguing other benchmarks.
FC Diamond is so hard that Opus 4.8 scores 13.8%.
Three eras of AI coding : Three eras of benchmarks
2021 • Autocomplete : HumanEval
2023 • Passing Tests: SWEBench, TerminalBench
2026 • Maintainable Code: FrontierCode
to me the most beautiful chart when I requested a special historical run into all extant old models, the data was finding that the easiest third of FC tasks (in FC Extended) were rapidlly and suddenly solved over late 2025 - Opus almost doubled from a 41% pass rate to 74% in 4 months.
This describes the "WTF happened in Dec 2025" vibe shift that a lot of folks from @dhh to @karpathy have called out: it is the difference between getting 95% success in 2 rerolls vs 6, making it finally feasible to go up the next layer of abstraction in agentic coding, eg @GeoffreyHuntley's ralph loops or @bcherny's /goals or @steipete's "loops that prompt your agents" without fearing too much that things go off the rails.
My guess: as AI accelerates from here, each FrontierCode tier will saturate in sequence, hopefully ~annually. I've already asked the team to prepare FrontierCode 2027....
The old mountains will be destroyed. Their rubble becomes regolith. And from that regolith, the next model forest grows. Circle of life.

Jun 8

Introducing FrontierCode: a coding eval that raises the bar for difficulty & quality. Each task took 40 hrs of work by leading open-source maintainers.
Models write sloppy code that works but isn’t maintainable. Our eval is first to measure: would you actually merge this code?

89
80
785
188,277
Matt Beane retweeted

Jun 12
I am seeing a "Let's not go crazy about this" coalition slowly forming
34
135
2,272
67,755
Jun 13
When you read these proposals, there's a lot to like.
And: the term "pro-worker" AI is deeply counterproductive. Needlessly, strongly suggests that it's anti-capital.
Mutual gains is more like it. We must build AI where use drives value for workers and firms at the same time!

Why isn't the market pursuing pro-worker AI? Co-director @DAcemogluMIT explains that the reasons are both economic and ideological.
323
Matt Beane retweeted

Jun 12
GenAI is good at producing a result.
But early-stage design is not about a single result —it is about exploring possibilities.
Our #DIS2026 paper “IdeaBlocks” won an Honorable Mention 🏆
We ask: how can designers express not only what to generate, but how to explore?
(1/n)

1
10
23
1,395
Matt Beane retweeted

Jun 11
Ok. Finished reading it. The story of Europe's failure in AI is turned into a gripping story (congratulations to the authors on finding this way to write it) and an outstanding SHOUT for action.
I disagree with many things in this scenario (e.g. ASML cannot be used for leverage, I am afraid: all the EUV tech is San Diego-based (Cymer), and the chips are Nvidia, AMD, Intel, etc.) But the key insight is correct: (1) AI is THE critical technology of the future, and (2) Europe is falling badly behind on AI and running out of options.
Both the economic and strategic consequences are brutal.
We will write a reaction in Silicon Continent. In the meantime, please do read it. europe2031.ai/#timeline
36
128
649
162,770
Matt Beane retweeted

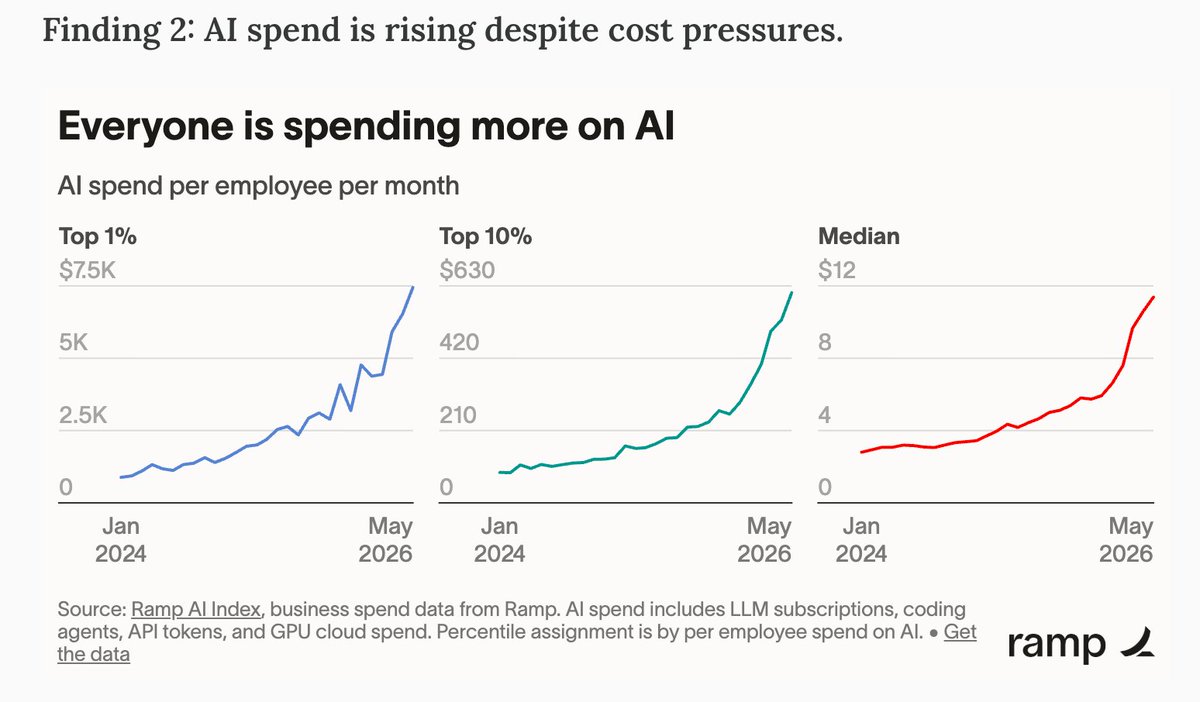
Jun 10
ai pilled companies spending $90k / employee per year 🤯
per employee, not per engineer.
where does this go in a year!? can't wait to find out...
from ramp's dataset (70k companies).
21
35
225
57,704
Jun 11
I know some *very intelligent and unusual* people who are learning to speak/code in a highly compressed way that's quite close to neuralese (but is also quite emoji-laden).
Not obvious natural human language (or thought) is going to survive contact with this moment.
Jun 11

Neuralese: The highly compressed, internal language increasingly used by some LLMs. Unlike English, Neuralese can't be understood by humans.
3
571
Jun 11
This is so impressive. There's a real challenge on the other side, though: state-level actors using Fable to train their own models. This was (I'm guessing) why this restriction was going to be in place, presumably temporarily.
Velocity over secrecy, the silicon valley way...
Jun 11

Very pleased to hear Anthropic have walked back this policy simonwillison.net/2026/Jun/1…

ALT “We’re changing Fable 5’s safeguards for frontier LLM development to make them visible.” Anthropic said in a statement to WIRED. “We made the wrong tradeoff and we apologize for not getting the balance right.”
268
Jun 11
Whoa. Hadn't considered this possibility, and instantly it seems quite likely.
Jun 11
In 2028, China & US will not *allow* frontier open source models, will not allow free export of frontier closed models for natl security reasons, distilling to catch up will be impossible, and the capabilities of these models will be astounding. Run through the implications! 4/4
1
4
600
Matt Beane retweeted

Jun 11
Everyone says the latest AI agents will be "job-ready" soon, especially after the release of Fable 5 this week. But is that really the case?
Over the past many months, my group and collaborators have been building Agents' Last Exam (ALE), a benchmark designed to test exactly that claim on real digital labor-market work.
My group and collaborators previously have created many of the benchmarks the field runs on, including MMLU, MATH, CyberGym, and ExploitGym. Today, I'm excited to share Agents' Last Exam (ALE): a rolling benchmark that measures whether AI agents can actually perform economically valuable work across a broad range of real-world domains.
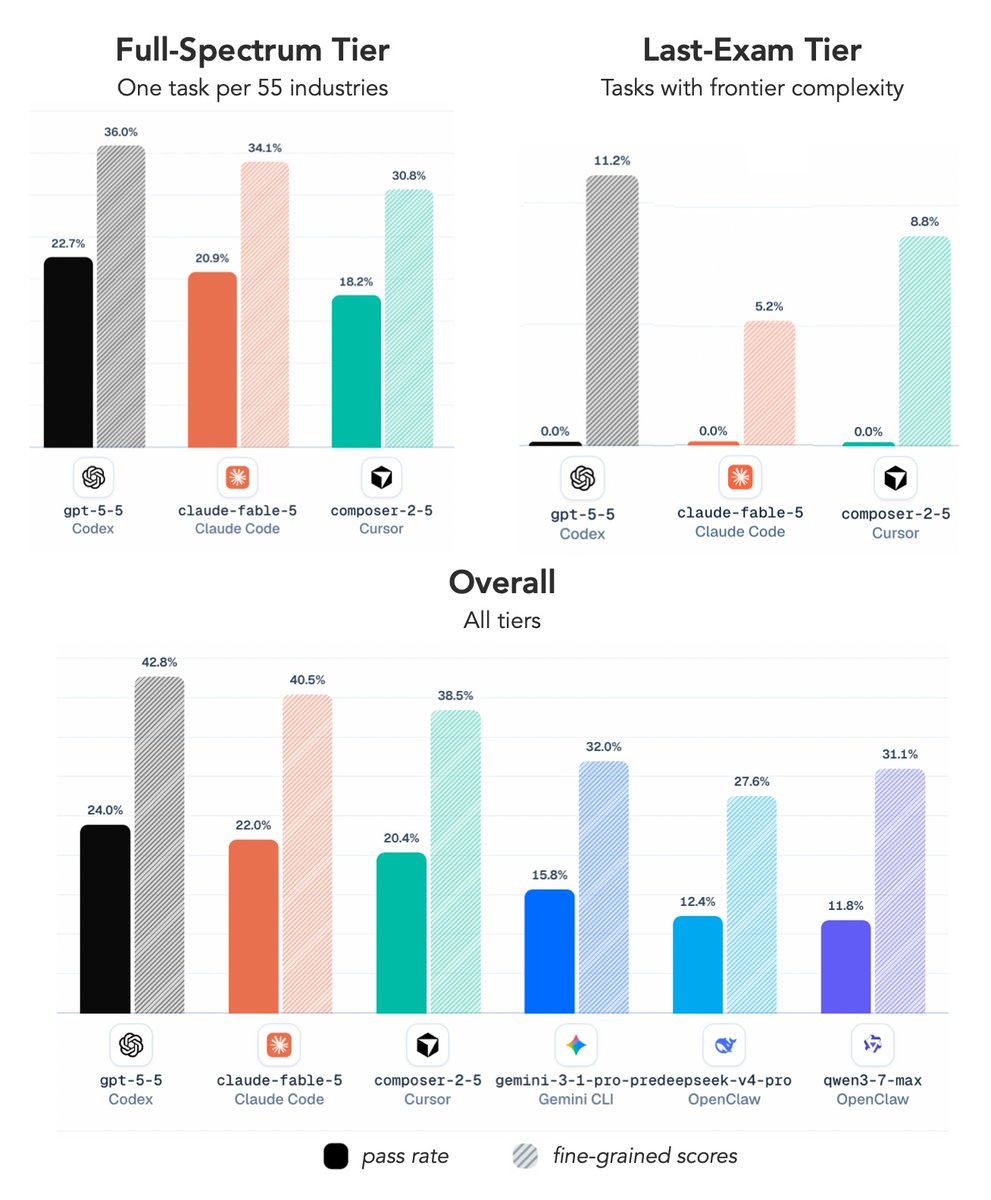
With ALE, we evaluated Fable 5, GPT-5.5, Composer 2.5, and other frontier agent systems across more than 1,500 expert-sourced tasks spanning 55 occupations.
The result is both impressive and sobering.
Today's agents can solve a meaningful fraction of professional tasks. But when we look at the hardest tasks, the ones requiring sustained reasoning, deep domain expertise, and reliable execution over long horizons, they are still far from human-level performance.
On ALE's hardest tier, every frontier agent we tested, including Fable 5, achieved a 0% success rate.
The age of useful agents is here.
The age of truly job-ready agents is not.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains.
🧵
54
168
813
209,377
Jun 11
Manna from heaven! This is an instant, mandatory assignment for all my masters and undergrad students.
They are *right* to be concerned about AI, and typically *wrong* about why. The more trustable, low-friction ways they can ground this out, the better.
Jun 11

A lot of people often ask me where I get my numbers when I claim that chatbot use doesn't add much to your personal carbon or water footprint, or bring up that different models and outputs have wildly different costs. I made this interactive visual where you can see exactly how lots of different models and prompts affect your total carbon and water budget. All estimates pulled from EcoLogits, which is an open source project that estimates chatbot usage and if anything is much more critical of chatbot energy costs than I am.

2
444