
Joined November 2019
- Tweets 3,263
- Following 958
- Followers 512
- Likes 4,678
378 Photos and videos






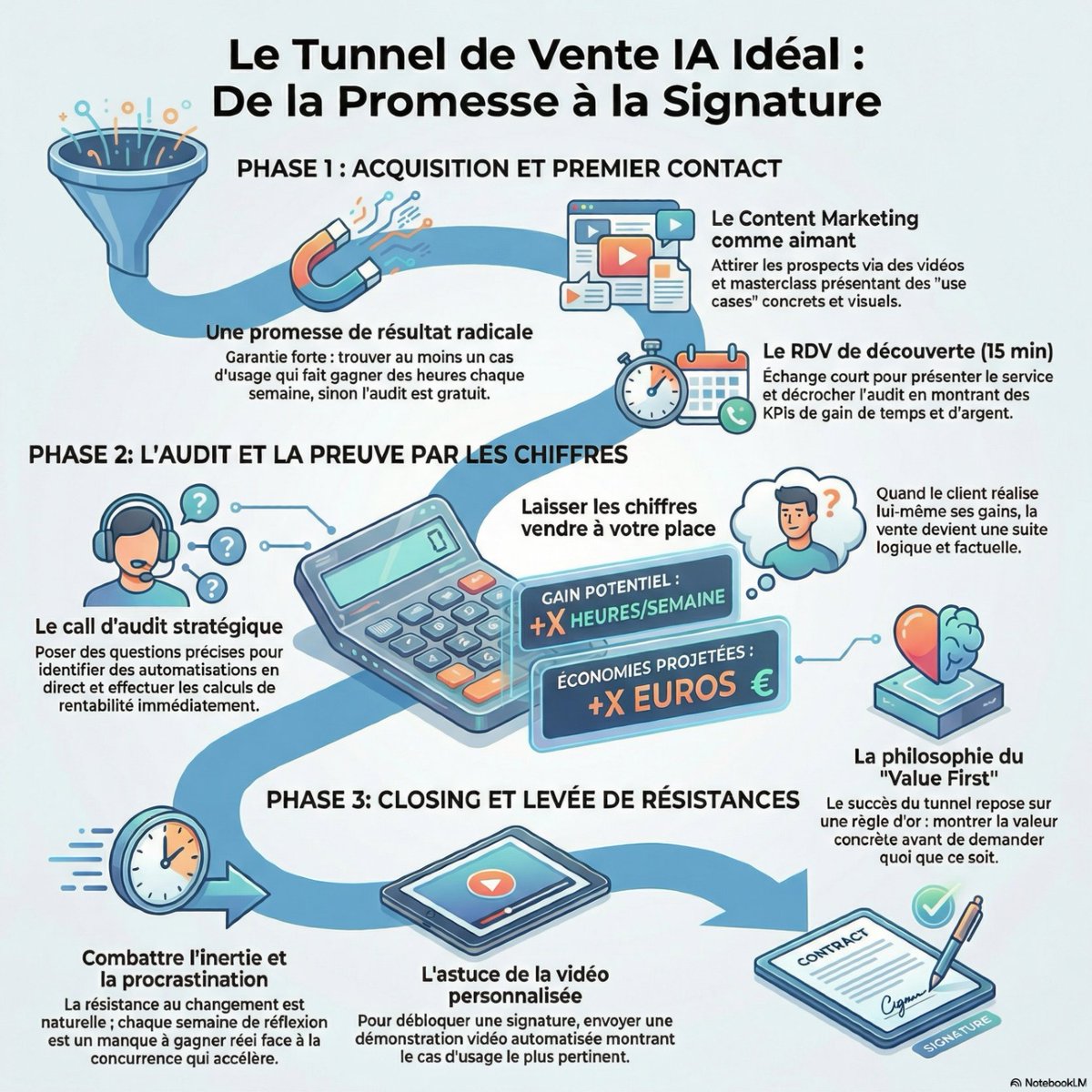


Pinned Tweet

Ces 3 derniers mois, j'ai fait un vrai retour aux sources.
Je me suis isolé pour construire, mais aussi coder une web app de A à Z (@MyDataNestApp).
C'est le genre de projet complexe qui m'aurait pris des mois avec une équipe entière avant, avec des budgets à 6 chiffres.
Pour y arriver, j'ai dû redevenir un élève : apprendre de zéro le Data Engineering et le Dev Web, et level-up en Business Dev.
En aparté, ce travail intensif m'a permis de décrocher une opportunité inattendue en tant que coach pour un grand centre de formation IA en France.
C'est dire à quel point la vitesse d'assimilation de connaissances via LLM est fulgurante...
En toute transparence, je n'aurais jamais pu accomplir tout ça seul.
Ce qui m'a aidé, c'est... mes agents IA 😁
Nous rentrons définitivement dans l'Âge Exponentiel de Raoul Pal. Quel progrès depuis 2022 et la gifle que m'a mis la GenAI.
J'ai toujours cherché à optimiser mon temps, à repousser les limites de la productivité, mais l'IA a complètement redéfini mes limites.
Je suis très exigeant sur la qualité, mais je manquais de temps et de compétences techniques pour tout faire moi-même.
Aujourd'hui, j'ai pu construire des agents IA qui m'épaulent au quotidien sur :
🔹 L'architecture système
🔹 Les workflows d'automatisation (notamment sur n8n)
🔹Le développement back-end et front-end
🔹Le copywriting et la stratégie
🔹Le dév perso / mindset
Et plein de petits détails du quotidien.
Le changement de paradigme est déjà là. En observant le décalage entre la France et ici, en Asie du Sud-Est où l'adoption va si vite, c'est frappant.
Pour vous donner une idée :
J'ai vu un ami économiser l'équivalent d'une formation à 2000€ juste en passant 8h à bien structurer ses requêtes sur Perplexity.
Un autre gère des 100aines de messages de support client quotidiens (qui paient pour cela) via une IA qui, pour être honnête, s'en sort souvent mieux qu'un humain.
C'est fascinant.
Pour ceux d'entre nous qui ont traversé les montagnes russes du marché crypto, l'IA ressemble à une nouvelle page blanche.
Vos compétences acquises dans le Web3 (notamment l'expérience financière et communautaire) sont des atouts incroyables aujourd'hui.
Et le croisement de l'IA et du Web3 a un potentiel immense : la blockchain comme infrastructure financière des agents IA semble inéluctable.
Mon modeste conseil : essayez d'aborder l'IA sous un angle "business" et pragmatique, plutôt que purement technique comme on le voit partout sur X.
C'est plus exigeant de chercher à résoudre un vrai problème / pain point de marché, mais c'est là qu'on apporte le plus de valeur.
Aujourd'hui, la demande est illimitée, je le vois au quotidien, mais savoir y répondre avec la bonne offre est un numéro d’équilibriste.
Bref, tout cela pour dire que l'opportunité de marché avec l'IA est aujourd'hui tellement gigantesque que j'ai besoin de monde.
Je vous propose donc un deal gagnant-gagnant que seul un marché en bullrun comme l'IA le permet.
On a décidé de mettre à disposition gratuitement l'équivalent de 5 000 à 10 000 € de ressources et de formations pratiques pour l'IA et pour le business de l'accompagnement continu.
Pas de théorie, juste du concret pour apprendre et entreprendre.
Si vous avez envie d'apprendre l'IA, de tester des choses et de monter en compétence avec nous pour monter votre business :
📩 Envoyez-moi un DM
👾 Ou rejoignez directement ce Discord qui sera notre QG : discord.gg/waFSHUpTJH
Je vous en dirai plus là-bas, n'hésitez pas 🙏
(Et pour ceux qui connaissent mon parcours, on reparlera du projet avec un “U”, qui est intimement lié à tout cela. Chaque chose en son temps 🤫)
1
3
13
1,050
Je rejoins totalement cette analyse.
La vraie valeur se trouve désormais dans la puissance de l'intégration au cœur des entreprises, dont l'adoption de l'IA est bien plus faible qu'on ne l'imagine (quand je l'ai réalisé, ça m'a choqué 😅)
On se trompe souvent de combat en se focalisant sur la course technologique brute.
Si vous observez la stratégie de @MistralAI, ils construisent un écosystème robuste qui simplifie la vie des professionnels.
C'est exactement le modèle de plateforme dont ont besoin les gens en entreprise.
La réussite de l'IA passera par cette vision pragmatique.

Mistral construit une infrastructure complète avec des entreprises ciblées.
Si "l'intelligence" devient une commodité (et vu la concurrence, ca va le devenir), la vraie valeur sera dans l'intégration et toute l'infrastructure que les entreprises devront adopter. En gros si Mistral réussi son pari, elle deviendra une sorte d'AWS européen
3
199
Le vrai problème des contenus écrits avec l’IA, c’est pas qu’ils sont écrits avec l’IA, c’est qu’ils sont écrits sans mémoire, sans contexte, sans intention, et ça se ressent beaucoup plus que vous ne le pensez.
On le sent tout de suite, y a un truc bizarre, une fluidité trop propre, des phrases qui cochent toutes les cases mais qui ne disent rien, une forme de contenu tiède, acceptable sur le papier, mais complètement oubliable pour le lecteur.
Et c’est précisément là que beaucoup se trompent avec l’IA. Ils pensent qu’un bon prompt va régler le sujet.
Alors qu’un prompt, même bien écrit, même avec un bon modèle, même avec un Skill correct, ça reste une interface très limitée si derrière vous n’avez pas construit le système qui nourrit la machine.
Le vrai sujet aujourd’hui, c’est pas “comment écrire avec ChatGPT”.
Le vrai sujet, c’est comment devenir architecte de contenu.
C’est à dire organiser votre mémoire, vos idées, vos prises de position, vos anciens écrits, votre ton, vos exemples, vos angles, vos obsessions business, pour que l’IA ne parte pas d’une page blanche, mais d’un environnement éditorial déjà vivant.
Parce que si vous donnez à l’IA un prompt générique, elle vous sortira un contenu générique.
Si vous lui donnez votre pensée structurée, elle peut vous aider à aller plus vite, à clarifier, à densifier, à mieux organiser, parfois même à pousser une idée plus loin que ce que vous auriez fait seul.
Mais elle ne peut pas inventer votre substance à votre place.
Et c’est là que la plupart des contenus IA échouent.
Non pas parce que les modèles sont mauvais, mais parce qu’on leur demande de produire une pensée à partir de presque rien.
On voit beaucoup de gens utiliser les versions gratuites, faire 2 ou 3 prompts, récupérer un texte, le publier, puis s’étonner que ça ne prenne pas, alors qu’en face le lecteur humain a déjà développé une forme de radar, il ne sait pas toujours expliquer pourquoi, mais il sent que le texte n’a pas été vécu.
Et demain, ce sera probablement la même chose côté algorithmes.
Google, notamment sur le SEO, n’a aucun intérêt à laisser remonter massivement des contenus IA faibles, interchangeables, sans apport réel, parce que si nous, humains, on arrive déjà à détecter cette sensation de contenu vide, faut pas croire que les systèmes de classement vont rester aveugles éternellement.
Donc produire plus, oui, mais produire plus de mauvais contenus, c’est juste accélérer vers un mur.
La bonne approche, à mon sens, c’est de sortir de la logique “je cherche le meilleur modèle” et de rentrer dans une logique d’orchestration.
Un modèle pour analyser votre corpus.
Un modèle pour extraire vos angles.
Un modèle pour structurer.
Un modèle pour challenger.
Un modèle pour réécrire dans votre ton.
Un modèle pour vérifier la cohérence.
On ne cherche pas des modèles énormes, ni les plus chers, ni forcément la Formule 1 à chaque étape, parce que souvent, ce qui crée la qualité, c’est pas la puissance brute, c’est la précision du système.
C’est d’ailleurs pour ça que des approches comme Fusion chez @OpenRouter sont intéressantes, parce qu’elles montrent bien qu’on commence à sortir du réflexe “un seul modèle magique”, mais même là, faut rester lucide, l’orchestration ne remplace pas la stratégie éditoriale, elle l’exécute mieux.
La vraie tactique, elle est là.
Vous devez construire une base de contexte :
- Vos posts
- Vos articles
- Vos notes vocale
- Vos idées brutes
- Vos formulations récurrentes
- Vos convictions
- Vos exemples clients
- Vos nuances
- Vos désaccords
Tout ce qui permet à l’IA de comprendre non seulement ce que vous voulez dire, mais surtout comment vous le dites, pourquoi vous le dites, et jusqu’où vous acceptez d’aller dans l’angle.
À partir de là, l’IA devient un levier business énorme et pas un ghostwriter automatique qui sort du contenu LinkedIn aseptisé.
Un système de pensée augmenté, capable de transformer votre matière en assets éditoriaux beaucoup plus vite, avec plus de structure, plus de régularité, et surtout plus de cohérence, et c’est là qu’il y a une vraie opportunité.
Parce que très peu de personnes font ça correctement aujourd’hui.
Beaucoup parlent d’IA, peu construisent une vraie architecture de contenu.
Beaucoup publient plus, mais peu publient mieux.
Beaucoup automatisent la sortie, peu travaillent la mémoire d’entrée.
Alors que c’est exactement là que se joue la différence entre un contenu qui ressemble à tout le monde (ou à rien ?), et un contenu qu’on lit jusqu’au bout, qu’on sauvegarde, qu’on partage, parce qu’on sent qu’il y a quelqu’un derrière.
Mon point est assez simple : si vous utilisez l’IA pour remplacer votre pensée, vous allez produire du bruit.
Si vous l’utilisez pour mieux organiser votre pensée, vous pouvez créer un avantage énorme. Mais faut accepter de faire le travail en amont, documenter, structurer, orchestrer, tester, affiner, et arrêter de croire qu’un prompt miracle va transformer une idée floue en contenu mémorable.
L’IA ne tue pas l’authenticité.
La paresse éditoriale, oui.

1
86
Quand je vous dis que les coûts vont tendre vers 0, cette initiative de @OpenRouter en est la démonstration parfaite.
Avec leur API "Fusion", OpenRouter montre qu'on peut obtenir une qualité incroyable tout en gardant un budget maîtrisé.
C'est ce genre d'outil qui va nous aider chez @MyDataNestApp à optimiser la création de contenu en augmentant la consommation de tokens pour le contexte tout en maintenant un prix bas par token.
Idem pour vos stratégies et vos automatisations quotidiennes, c'est une excellente nouvelle.
Ce n'est pas pour rien si OpenRouter a levé 113 millions de dollars lors d'un tour de table de série B clôturé le 26 mai 2026.
Jetez un œil à ce fonctionnement 👇
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
85
Anthropic vient de se faire rappeler poliment mais fermement qui est le vrai client numéro un, et contrairement à ce que la panique ambiante va essayer de vous vendre, c'est pas du tout un signal de censure ou la fin du marché pour les labos, c'est une accélération brutale.
Parce que si Fable ou Mythos sont vraiment les monstres d'intelligence dont tout le monde parle en coulisses, alors on est plus du tout dans le SaaS classique mais dans le vrai grand Jeu (comme dit Pal) des souverainetés nationales et des fenêtres d'avance technologique de 30 jours qui valent des milliards de dollars, voire beaucoup plus.
Les labos font déjà exactement ça en interne (ils entraînent la génération d'après avec la version non censurée et non bridée de la génération actuelle, jamais avec la version publique), parce que ce petit différentiel privé est précisément leur seule assurance-vie pour garder la tête de la course.
L'Etat américain veut simplement appliquer la même règle du jeu, passer avant le grand public, avant les entreprises, et surtout avant que les modèles open source chinois aient seulement le temps de cloner, distiller, répliquer et transformer l'avantage stratégique de la Silicon Valley en commodité mondiale.
C'est violent, c'est moche, ça ressemble à une mise au pas réglementaire (surtout avec la méthode de l'administration actuelle), mais le deal sous-jacent est d'une simplicité biblique : vous restez des opérateurs privés libres de lever des milliards, de cramer des gigawatts et de vendre vos API partout dans le monde, mais l'Etat se réserve le droit de tirage prioritaire.
Comme dit @RaoulGMI, c'est la version moderne de la Compagnie des Indes avec une charte non écrite qui dit que quand la couronne appelle, tu réponds présent, et c'est précisément là que le contresens du marché devient fascinant.
Beaucoup d'analystes vont y voir une contraction du TAM (le fameux marché adressable) sous prétexte que le gouvernement ferme le robinet de l'innovation grand public, alors que le vrai signal indique exactement le contraire : cette technologie est devenue tellement critique que l'Etat ne peut plus se permettre d'être un client comme les autres, ce qui rapproche instantanément ces boîtes du statut de too big to fail.
Et quand vous devenez trop stratégique pour faire faillite, la dette colossale qui finance les clusters de GPU et les contrats d'énergie commence à bénéficier d'une garantie souveraine implicite (personne ne va l'écrire noir sur blanc, mais tout le monde a compris la musique), ce qui transforme cette contrainte apparente en une gigantesque subvention déguisée.
Le vrai paradoxe, c'est que ça se produit au moment précis où l'adoption en entreprise reste ridiculement faible par rapport au délire médiatique ambiant, y a encore des équipes tech qui galèrent à brancher un assistant sur leur vieux CRM sans faire exploser leur facture d'inférence alors qu'on leur parle de modèles capables de raisonner comme des chercheurs de la NASA.
Le futur ne sera pas peuplé de requêtes envoyées à Fable pour tout et n'importe quoi parce que ça n'a aucun sens économique (personne n'utilise un moteur de Formule 1 pour livrer une pizza froide), et le marché va fatalement se structurer en couches superposées.
D'un côté, les modèles frontières ultra-chers et jalousement gardés pour l'Etat et les cas d'usage hautement critiques, et de l'autre, une armée de modèles spécialisés, orchestrés et distillés qui font 89% du boulot pour 5% du coût (et c'est tant mieux pour nos budgets).
Cette régulation ne tue pas l'innovation, elle force enfin l'écosystème à devenir un minimum rationnel en arrêtant de pousser de l'artillerie lourde pour des tâches basiques et en forçant la construction de vrais systèmes industriels avec des workflows et des mesures de ROI (le truc chiant, donc le truc qui compte vraiment).
Alors oui, Anthropic va plier et accepter les règles du jeu fédérales, mais plier ne veut pas dire rétrécir, ça veut dire entrer dans la cour des infrastructures souveraines où la croissance privée et la sécurité nationale sont devenues impossibles à démêler, et quand un État commence à sanctuariser et à financer une technologie de cette façon, c'est jamais le début d'un ralentissement, c'est en effet le signal de départ du vrai super-cycle, s'il fallait encore le confirmer...

Anthropic has been publicly forced to bend the knee to the US government. The ban on Fable and Mythos reads like censorship, and the market will read it as the TAM of the frontier labs collapsing. Instead, I read this as the opposite, as an acceleration event...
The government MUST have first access, because this is The Great Game, the game of nations over the most powerful technology ever discovered, and a technological edge of 30 to 60 days is worth everything.
It's the same edge the labs already exploit internally. You build your next model with your unreleased frontier tech, never with the public one. That private head start is what keeps you accelerating ahead of the competition or at least in line with them.
The US needs that exact advantage now. Before the public, and before the Chinese open source models can copy it. They have no choice. They cannot allow their own technology to be turned against them.
What's being negotiated, in the usual outrageous, hard-ball Trump manner, is the new arrangement:
Anthropic and OpenAI are free market operators and state vassals at the same time. Nobody wants to curtail their growth. The Gov just wants to be Customer Number 1 with privileged access.
This is the East India Company all over again. A private enterprise left free to grow rich and dominant, granted protection and a clear run by the state, on the unspoken condition that it serves the crown's strategic interests first. That charter was the price of the monopoly.
It also sends a message to China and everyone else that US AI is now so advanced the state itself has to control it. They won't, not yet anyway. They just want privileged access, the rest is posturing.
And Anthropic will bend the knee, very soon...
The hidden outcome is the one that matters. The AI firms are now near-explicitly too big to fail, which means the debt funding the capex buildout comes with an implicit state guarantee.
That accelerates the build-out of intelligence. It doesn't curtail it...
Open source accelerates too, because going open ensures no state can intervene in the model itself. Though the same Great Game rules apply there, and the Chinese state will take its own privileged access first.
So the market may wobble, convinced the TAM of AI just collapsed.
The real outcome is an acceleration of intelligence, and a Super Cycle that keeps running.
1
119
En réalité, cela aurait coûté entre 25 000 et 35 000 € avant l'IA, ce qui n'est plus d'actualité.
N'importe quel bon modèle Tiers 1 permet de faire le travail en disons 2h de plus si on part du principe que Fable 5 est vraiment au-dessus, sachant que c'est bien souvent plutôt une question de harnais et de logique métier promptée.
Mais oui, la question de souveraineté est un vrai sujet, même si les modèles ouverts règlent une bonne partie du problème.
Jun 13

Les États-Unis viennent d’interdire l’accès à Fable 5 hors de leurs frontières. Sécurité nationale.
Du jour au lendemain, plus d’accès pour nous.
La question de notre souveraineté numérique, elle, reste entière.
Parce que hier, Fable m’a permis de construire en moins de 4 heures une application qui aurait coûté entre 25 000 et 35 000 €.
Vous mesurez les opportunités que ça représente ?
Opus 4.8 est déjà excellent. Mais Fable allait plus loin : il fonctionnait par boucles d’agents (« agentic loops »). Il se corrigeait seul, testait et itérait plusieurs solutions en parallèle, proposait ses propres améliorations.
Bluffant.
Détail qui compte : ce n’est pas Anthropic qui a retiré le modèle. L’entreprise a publiquement contesté la décision. C’est Washington qui a tranché.
Et ça en dit long : les IA de pointe sont désormais traitées comme des actifs de sécurité nationale.
À nous, Européens, d’en tirer les conclusions. Et de soutenir ceux qui bâtissent notre alternative.
Vive @MistralAI et courage à vous 🤞🤞🤞

289
Je trouve cette analyse très lucide sur les dérives de la régulation.
En voulant s'allier avec l'état pour bloquer la concurrence, on finit souvent par se faire piéger par ses propres règles, c'est ce qui arrive à Anthropic aujourd'hui 🤔
Bloquer un outil de travail sous prétexte de sécurité, c'est se tirer une balle dans le pied. Les attaquants vont continuer à utiliser ces modèles pendant que nos experts se retrouvent désarmés.
Retenez bien cette leçon : on ne contrôle pas l'innovation avec des formulaires administratifs, on la déplace juste ailleurs.
C'est la Chine qui va être contente...👀
Jun 13

L'administration américaine vient d'ordonner la suspension de l'accès au modèle d'IA le plus avancé du marché. Par lettre. Un vendredi à 17h21. Sans preuve écrite.
Ce qui vient de se passer est un cas d'école.
Le motif officiel: un concurrent aurait trouvé un "jailbreak" de Mythos 5. Le jailbreak en question, d'après le communiqué d'Anthropic eux-mêmes: demander au modèle de lire un codebase et de corriger les failles.
Une capacité disponible aujourd'hui dans GPT-5.5 et utilisée quotidiennement par les équipes de cybersécurité du monde entier pour défendre les systèmes.
On ne parle pas d'une arme. On parle de l'outil de travail standard de tout défenseur en 2026.
Le mécanisme est d'une élégance perverse. L'ordre ne dit pas "éteignez le modèle". Il interdit l'accès aux ressortissants étrangers, en sachant pertinemment qu'aucune API au monde ne peut filtrer ses utilisateurs par passeport.
Résultat: Anthropic annonce devoir couper pour tout le monde. L'État n'a officiellement rien éteint. L'entreprise s'auto-ampute pour se conformer. Responsabilité diluée, résultat garanti. C'est la signature de toute la régulation moderne: on ne vous interdit rien, on rend la conformité impossible.
L'ironie, maintenant. Anthropic est l'entreprise qui explique depuis trois ans à Washington que les modèles frontière sont trop dangereux pour être laissés au marché, et que l'État doit pouvoir bloquer les déploiements.
Dario Amodei a publié un essai dans ce sens il y a quelques jours à peine. Leur communiqué d'aujourd'hui ne conteste d'ailleurs pas le principe de ce pouvoir, seulement qu'il soit exercé sans "processus transparent, équitable et clair". Le monopole de la violence régulatoire, oui, mais avec des formulaires.
Ils ont passé trois ans à forger l'arme. Elle vient de servir pour la première fois. Contre eux.
Bastiat l'aurait écrit en une ligne: on ne contrôle jamais le pouvoir qu'on donne à l'État, il est saisi par celui qui tient l'appareil au moment T, jamais par celui qui a rédigé le pitch de la régulation.
Et le plus ridicule reste l'hypothèse implicite de toute cette décision: que cette capacité peut être contenue. Les délais entre modèle frontière fermé et équivalent open weights parlent d'eux-mêmes: GPT-4, environ un an avant Llama 3. o1, quatre mois avant DeepSeek R1. Le gap se compresse à chaque génération et les labs chinois publient les poids.
Dans quelques mois, un modèle aux capacités équivalentes tournera sur n'importe quel cluster à Shenzhen, Dubaï ou dans un garage à Lyon, et aucune lettre du Département du Commerce ne pourra le débrancher.
Le seul effet réel de cette directive: les chercheurs et les défenseurs qui jouent dans les règles perdent l'accès au meilleur outil du marché, pendant que les attaquants, qui n'ont jamais dépendu d'une API avec KYC et safeguards, continuent comme avant. Ce qu'on voit: un modèle "dangereux" suspendu.
Ce qu'on ne voit pas: des milliers de failles qui ne seront pas corrigées, et un écosystème entier qui vient d'apprendre que construire aux États-Unis, c'est accepter un kill switch politique au-dessus de son infra.
On ne contrôle pas la diffusion d'une technologie dont le coût marginal de réplication tend vers zéro. On peut juste choisir qui en profite: tout le monde, ou tout le monde sauf soi.
L'eau ne remonte pas la pente. Elle contourne.
91
L’IA va prendre nos jobs, c'est presque une certitude, mais elle permet surtout à un seul profil affûté de faire le boulot qu'on laissait avant à une équipe entière.
Y a quelques mois encore, pour faire de la croissance proprement, il nous fallait un SDR, un copywriter, un designer, un dev et parfois même un data analyst pour essayer de comprendre ce qui se passait (alors qu'on avait franchement d’autres chats à fouetter), mais aujourd'hui une seule personne dotée de la bonne stack peut aller 10 fois plus vite que tout ce petit monde.
Faut "juste" arrêter de croire (pas si simple) qu'il suffit de 3 prompts sur ChatGPT.
Le vrai sujet c'est d'apprendre à piloter la machine pour connecter des outils plus vite que notre propre équipe tech, lancer des agents qui qualifient et relancent nos leads pendant qu'on dort, ou passer une sortie IA d'un niveau moyen à un rendu tellement propre qu'on peut direct l'envoyer en prod.
Le piège c'est de penser que la tech remplace nos compétences alors qu'en fait elle ne fait qu’amplifier ce qu’on maîtrise déjà, parce que si on est flou elle va juste produire du flou beaucoup plus vite, mais si on a du goût, du jugement et une vraie lecture du marché, elle nous donne un levier de distribution absolument gigantesque.
C’est pour ça que les compétences non négociables aujourd’hui n'ont rien de magique, il faut savoir poser un angle fort pour rendre une idée impossible à ignorer, capter l’attention sur LinkedIn ou X pour pas parler dans une pièce vide, et maîtriser nos automatisations sur par exemple n8n sans forcément être ingénieur mais en comprenant comment lier nos briques.
L'IA va probablement enterrer les profils moyens qui ne vendaient que du temps passé, mais pour ceux d'entre nous qui apprennent à penser, créer, distribuer et automatiser avec elle, c'est le plus gros arbitrage de carrière de la décennie.
2
3
213
La créativité s'exprime fort en ce moment avec Fable 5 👀

Claude Fable 5 just changed the AI game.
People are one-shotting games, 3D worlds, app builders and insane code optimizations. There's a major shift.
10 examples:
64
On franchit un cap immense pour la communication globale.
Je pense que cette fluidité dans la traduction instantanée va transformer notre manière de collaborer et de diffuser nos messages à l'international.
Par exemple, on a plus de limites linguistiques pour connecter les communautés.
Suivez cela de très près et réfléchissez à comment intégrer ces fonctions rapidement dans vos stratégies de contenu.
Faut pas rater ce train👀

Say hello, hola, 你好 to Gemini 3.5 Live Translate: our latest audio model built for fast, cross-language communication. 🌐
1
138
On passe notre temps à s'extasier sur la puissance des nouveaux modèles mais on oublie souvent le principal.
Le grand défi de l'intelligence artificielle c'est d'abord de la rendre rentable (du moins côté US^^).
Je pense que Kevin met le doigt sur le vrai sujet chaud du moment : si les entreprises trouvent pas un retour sur investissement rapide, tout le secteur va coincer.
Donc ouvrez vos horizons et observez les solutions d'optimisation, même celles qui se cachent dans l'univers de la crypto.
$SERV 👀
Jun 8

Pretty insane to see 600k views on this article about a relatively little known project
I'll tell you why I wrote it, and it wasn't for any financial incentive (the team didn't ask me to write it, and I hold only a small amount of the token)
If you've followed my posts, I've been consistently writing about the unsustainable costs of intelligence that enterprises are facing
Demand for intelligence is near infinite, but only when there is ROI
If everyone tokenmaxxes with the most expensive models with the highest levels of reasoning, most use cases won't find ROI
What happens if we don't find ROI?
If enterprises don't find ROI, we start to see an unwind of the AI trade which has massive implications across financial markets and the global economy
We NEED for enterprises to find ROI, and soon
So that means we need to highlight more solutions that enable enterprises to get better intelligence-per-dollar spend, and get them adopted
I've been doing a LOT of research on this topic and posted a playbook for enterprises to reduce costs a few days ago (will link it in replies)
And I found this project OpenServ that has a solution called SERV Reasoning just hiding in plain sight, and in crypto of all places
That's what made me write about it, and I was naturally skeptical about it when I began (bc crypto)
I'm glad many people found this article helpful, let's keep the cost optimization dialogue going
73
D'après vous, quelle est la pire faille d'un prompt unique "tout-en-un" ?
0%
Hallucination sémantique
0%
Oublis en cours de route
0%
Le ton qui change
0%
Tout est bon chez moi !
0 votes • 14 hours
46
Je trouve cette vision de la programmation fascinante et je pense comme beaucoup qu’on assiste à la plus grande libération créative de notre époque.
On ne remplace pas la réflexion humaine, on supprime simplement les barrières techniques. Le code a toujours été une simple interface entre notre cerveau et la machine.
Et je ne serais pas étonné si l'IA développait son propre langage pour gagner en efficience.
Oubliez la syntaxe et concentrez-vous sur la structure logique et la résolution de problèmes. C’est là que se situe votre véritable valeur désormais.
On va avoir besoin de profils capables de conceptualiser et d'abstraire des architectures complexes avec une clarté absolue.

Elon Musk thinks coding dies this year.
Not evolves. Dies.
By December, AI won’t need programming languages. It generates machine code directly. Binary optimized beyond anything human logic could produce. No translation. No compilation. Just pure execution.
Musk: “You don’t even bother doing coding.”
Code was never the point. It was friction. A tax we paid because machines didn’t speak human. AI just learned fluent human. The tax is gone.
Now plug that into Neuralink. No syntax. No keyboard. No screen.
Musk: “Imagination-to-software.”
Thought becomes executable. You imagine an outcome, the system architects and compiles it into reality instantly.
We’re not automating programming. We’re erasing it from existence.
The entire profession collapses into a thought. Decades of training reduced to irrelevance. The gap between idea and instantiation hits zero.
You don’t build anymore. You imagine, and it materializes.
Not incremental progress. Total phase shift. The way humans have created things for ten thousand years just became obsolete.
Welcome to a world where the limiting factor isn’t skill, resources, or time. It’s whether you can picture what you want clearly enough for a machine to birth it into existence.
1
5
253
On se demande vraiment ce qui se passe dans la tête des décideurs tech qui continuent d'arroser OpenAI et Anthropic à coups de millions de dollars par mois pour faire tourner leurs API.
Quand on voit ce founder lâcher Anthropic pour DeepSeek sans cligner des yeux, on se dit que le réveil de nos géants de la Silicon Valley va être extrêmement douloureux, le vent pourrait tourner beaucoup plus vite que prévu.
Faut être lucide 2 minutes, payer 20 à 30 fois plus cher pour des performances marginales en production, c'est juste de l'hérésie financière.
Comment les Américains pensent maintenir ces tarifs exorbitants face à des alternatives open source ou asiatiques qui s'alignent sur les benchmarks pour une fraction du prix ?
D'autant que notre futur se jouera bientôt en local avec l'offensive de Nvidia sur les PC, le coût de l'inférence s'effondre à une vitesse de folie et la fête des API payantes touche probablement déjà à sa fin...
Jun 4

Pulled the trigger today and switched 100% of Lindy traffic to DeepSeek v4, churning from Anthropic models.
Saves us millions of $ and we're actually seeing an *increase* in performance on many core use cases. Transformative for the business.
2
96
Ce n'est pas sur LinkedIn qu'on verra un partage de valeur aussi élevé 😁🙏

Mes agents Hermes tournaient avec des clés API rangées dans des .env sur le serveur.
J'ai migré la clé Fireworks dans Bitwarden Secrets Manager. Au boot, l'agent appelle bws, résout
la clé en mémoire, ne touche plus à un fichier local. Bitwarden est la source de vérité.
Ce matin au démarrage, les logs montrent : "Bitwarden Secrets Manager: applied 1 secret
(FIREWORKS_API_KEY)". Appel modèle juste après, réponse 200. Le cache s'est régénéré tout seul.
La clé est résolue à la demande. J'ai redémarré l'agent pour vérifier : il repart sur la même
résolution Bitwarden au boot. Il ne dépend plus d'une clé gardée en RAM.
Si tu montes un business avec des agents IA, tu vas multiplier les clés. Fireworks, OpenRouter,
Anthropic, des tokens GitHub, des accès Notion. Tu ne veux pas les balancer dans un .env que tu
oublies sur un VPS. Un jour tu recrutes, un jour tu vends un accès, un jour tu migres de serveur.
A chaque fois ce sont des secrets qui traînent. Bitwarden devient ton point central. Tu rotates
une clé, tous tes agents la récupèrent au prochain démarrage. Tu n'ouvres pas un fichier, tu ne
fais pas de grep, tu ne copies rien dans un chat.
Quand tu passes du bricolage local à un système qui tourne pour des clients, la barre change. Un
client ne veut pas que ses leads ou ses données passent par un serveur où tes clés sont lisibles
avec nano. C'est la différence entre un prototype et une infra de production. Tu ne peux pas
prétendre livrer des systèmes fiables si la base est bancale.
Ce genre de détail te rattrape quand tu scales. Tu ne vois pas le .env au quotidien, il ne te
gêne pas. Jusqu'au jour où tu recrutes, où tu migres de machine, ou où un client te demande comment sont stockées ses données. A ce moment là, tu copies des secrets à la main, tu en oublies un, tu en laisses un train derrière toi.
Maintenant mes agents ne démarrent que si le vault répond. Pas de vault, pas de clé, pas de
service. C'est devenu la porte d'entrée obligatoire. Je ne laisse plus de secrets clients dans un
fichier local. Bitwarden est le seul endroit où ils existent.

2
54
Vous exploitez à peine 1% du potentiel de l'IA, et ce n'est vraiment pas la faute de la machine.
Le problème c'est qu'on l'utilise encore trop souvent comme un simple moteur de recherche amélioré, alors que le vrai levier réside dans notre discipline à creuser chaque sujet, itération après itération, en refusant systématiquement la première réponse linéaire.
Quand on passe du temps à structurer nos sessions de travail en poussant l'ingénierie de prompts à son maximum, on ne cherche pas une simple formule magique du premier coup, on cherche à déclencher un effet compound d'itération cognitive où chaque relance ouvre de nouvelles portes délaissées par la majorité par simple habitude de consommation rapide.
Il faut comprendre que l'asymétrie itérative se joue précisément dans cette capacité à dépasser le premier niveau superficiel, en activant le réflexe d'exploitation totale, parce que la machine ne fatigue jamais et qu'elle peut toujours descendre d'un niveau de profondeur supplémentaire si on sait la piloter.
Plus on fait l'effort de creuser nos questions avec l'IA, plus on entraîne notre esprit à penser de manière systémique. Ce travail produit des données d'une précision rare qui convertissent naturellement mieux car elles répondent à un besoin de qualification technique hors d'atteinte des généralités habituelles.
Il y en a qui attendent passivement que l'outil devine leurs intentions, alors que la valeur exponentielle apparaît dès qu'on s'impose la discipline de tout lui demander, de traquer ses raisonnements et de refuser toute première réponse comme un résultat final.
Testez ce réflexe immédiatement : à la prochaine réponse de l'IA, passez outre cette première prise, posez trois questions de plus pour débusquer la faille ou le détail technique sous-jacent, et mesurez la valeur de ce que vous découvrez d'inédit grâce à cette discipline de fer, puis recommencez. 10 fois. Forcez-vous. Avec la pratique, vous finirez par vous sentir augmenté cognitivement par l'IA.
1
98
Je partage complètement cet avis 👀
On a trop nourri la peur collective ces derniers temps.
Je pense que faire paniquer les gens sans amener du constructif, ça mène juste à un rejet massif de l'innovation.
Les chiffres montrent bien que la réalité du terrain est bien différente.
Bâtissez des récits qui inspirent et qui rassemblent, on a un grand besoin d'optimisme pour avancer sereinement.
le futur s'annonce passionnant si on prend les bonnes décisions ensemble 🙏🏼
May 28
Sam Altman se calme sur la destruction des jobs pour une raison simple :
1 : sur la destruction des software engineers la data montre complètement l’inverse.
2 : agiter un chiffon enflammé devant l’humanité en amenant aucune forme de solution est extrêmement dangereux, je ne suis pas d’accord avec Sam Altman sur beaucoup de choses, mais je n’ai pas envie qu’il finisse brûlé par un cocktail Molotov.
3 : il est temps de calmer le jeu, de vendre un futur optimiste où chacun trouvera sa place dans un futur d’abondance qui va aller coloniser le cosmos.
Le futur va être génial !
1
75
Je pense aussi qu'on touche du doigt la limite de notre mémoire de travail face à la complexité de la nature.
La biologie ou la recherche de nouveaux traitements, c'est juste trop vaste pour nos cerveaux de primates. 🤔
Mais faut pas voir ça comme une défaite pour l'humanité.
Voyez plutôt l'intelligence artificielle comme une extension cognitive obligatoire.
On va enfin pouvoir déléguer la gestion des milliards de combinaisons possibles pour se concentrer sur la direction et l'éthique. 👀
Prenez les devants et apprenez à diriger ces systèmes complexes.
C'est pas la fin de notre utilité, c'est le début d'une collaboration immense. 👌🏼
May 28

True, but does it matter?
Will humans soon be permanently behind, like in Poker, Go and Chess?
It's worth pointing out that this is a bit different. Because language models can actually tell us how and why something works, so maybe the gap won't be as large as in these other domains.
But I still suspect there's a ceiling for what humans can understand. The main bottleneck is working memory. Oh, and the obvious example of that is of course biology. Generally speaking we have a pretty good idea how each individual part, for example in the human body, is working. But we can't really predict the downstream effects of one change. This is a big problem in drug discovery.
I suspect AI will be able to predict downstream effects of drugs much better than we do in a few months/years. Because to me it all seems too similar to what Mythos and GPT-5.5 just did with math and cyber.
It's just a scaled up version of that with even more interactions and possible combinations, which AI can keep track of.
1
174
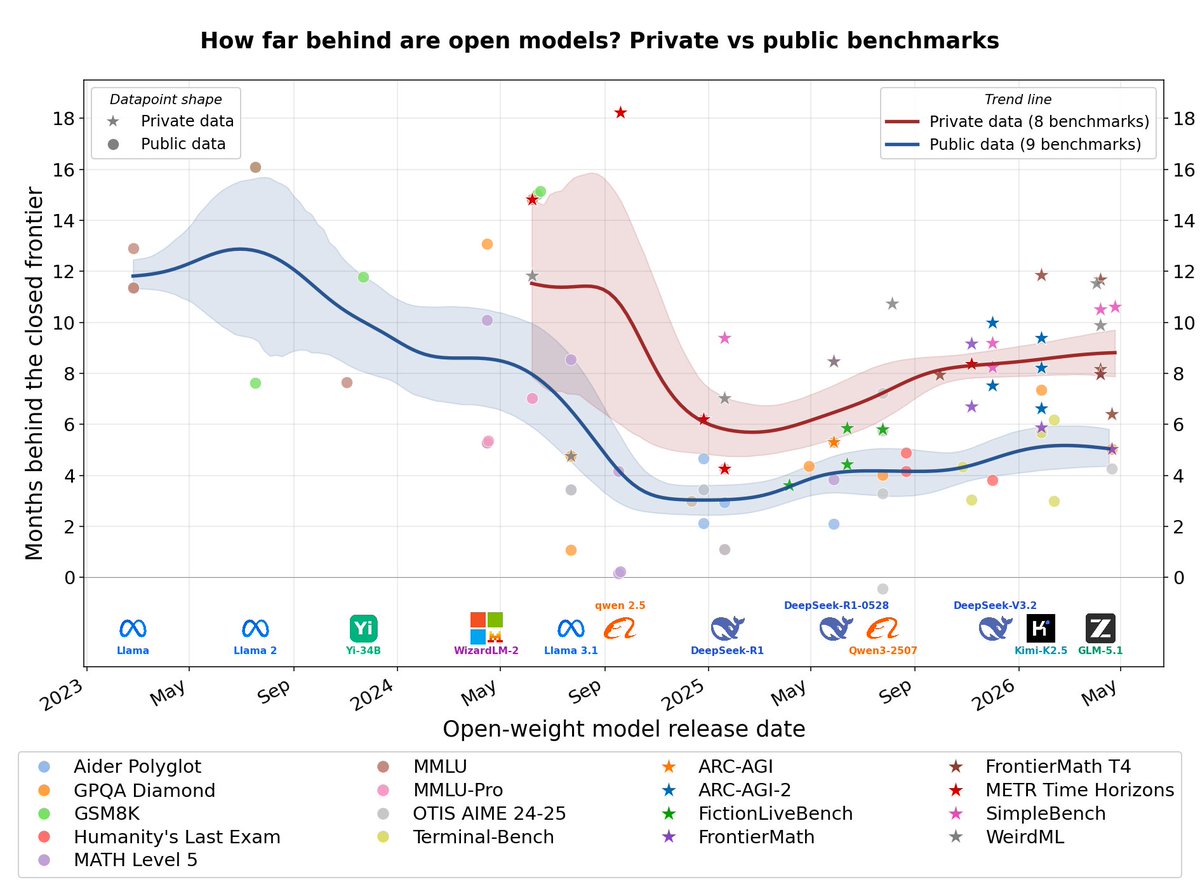
On pense souvent qu'il y a un fossé géant entre les modèles ouverts et fermés.
En réalité, on parle seulement de huit à dix mois de décalage.
Je trouve que c'est une excellente nouvelle.
C'est pas énorme face au niveau de personnalisation que ces outils vous offrent.
Misez sur l'open source pour vos applications de demain.
L'adaptation fine à vos données va de toute façon combler ce petit retard.
Perso, j'ai hâte de voir la suite des événements. 👀
May 28

How far behind are open models?
Across 17 selected benchmarks, private ones show a gap of 8-10 months today, almost 2x the gap on public ones (4-6 mo).
More discussion (including limitations), code and blog in the thread.
61
"Des centaines de milliards perdus" c'est le titre qu'a choisi Frandroid pour parler des investissements dans l'IA.
Une façon intéressante de dire "des centaines de milliards investis dans l'infrastructure de demain".
On peut voir le verre à moitié vide. Ou constater que les plus grandes transformations technologiques de l'histoire ont toujours exigé des mises colossales avant de porter leurs fruits.
Mais le pessimisme paie mieux que la nuance, apparemment. ☕
2
34