
Lady of python, machine learning & causality | ex Teva | PhD from @WeizmannScience | expertise in biomedical data science | red wine, spinning, trance music.
Joined February 2015
- Tweets 2,115
- Following 2,908
- Followers 548
- Likes 7,764
97 Photos and videos














Nancy Yacovzada retweeted

Jun 14
Google hid a fully working flight simulator inside Google Earth back in 2007 and never told anyone.
You unlocked it with a secret keystroke: Ctrl Alt A. No menu, no announcement. One user stumbled onto it, the combo spread, and it got popular enough that Google made it official the next year. Two planes, an F-16 and a Cirrus SR22, flying over real satellite imagery of the entire planet.
Then it stayed locked inside the downloadable desktop app for 18 years. The browser version was a stripped-down viewer that couldn't run it. Today that changed.
Here is the part that makes it impressive. A flight simulator is the single hardest thing you can ask a 3D map to do. Panning is easy, the software has all the time it wants to load the terrain ahead of you. Flying low and fast strips that away, forcing it to fetch, decompress, and render the world faster than you are crossing it. The hardest possible job for every part of the system at once.
So "just for fun" is carrying a lot of weight in that sentence. Getting this to run in a browser tab is the cleanest proof that the web version finally matches what used to need a desktop app.
The toy is the benchmark.
Jun 12

Prepare for takeoff. ✈️ Flight simulator is now available globally on web to all users. goo.gle/4fBYnWO
We've recently added many our most powerful professional desktop features to web. Elevation profiles, new import types, but there's always been one other feature you've been asking us to add to the web version of Google Earth, just for fun...
Where will you fly? Share your best maneuvers, views, and flyovers with us!
56
651
6,631
1,345,684
Nancy Yacovzada retweeted

Jun 11
Do single-cell foundation models obey scaling laws?
A somewhat thought-provoking new Nature Methods study by the Crawford lab suggests that, for current single-cell foundation models, the answer may be “not really.” Across a broad range of architectures and downstream tasks, increasing pretraining data from hundreds of thousands to tens of millions of cells yielded surprisingly limited gains, with performance often saturating much earlier than expected.
This is interesting and provides exactly the kind of rigorous benchmarking our field needs. As Felix Fischer and I commented in the accompanying Research Briefing, such studies help move the discussion beyond model size and computational budgets toward actual scientific utility.
At the same time, I am not convinced the key conclusion is that scaling does not work in biology. Rather, it may be that current objectives are not extracting enough information from additional data.
Interestingly, in our recent scConcept work, we observe a markedly different scaling behavior, with continued gains as training data grows toward hundreds of millions of cells. The key difference may be the training objective itself: instead of reconstruction-based masked modeling, scConcept uses a contrastive objective that directly optimizes biologically meaningful cell representations.
biorxiv.org/content/10.1101/…
This raises an interesting question for the field: Have we reached the limits of data scaling, or only the limits of current objectives?
-> My guess is that the next generation of biological foundation models will depend less on simply collecting more cells and more on finding the right representation learning principles for biology.
Nature Methods paper:
nature.com/articles/s41592-0…
Research Briefing:
nature.com/articles/s41592-0…
#SingleCell #FoundationModels #AIforBiology

10
52
230
28,037
Nancy Yacovzada retweeted

Jun 8
New Science Blog: Why has AI advanced faster in coding than in biology?
To agents, bio databases are like cities built before cars—maddening to drive in because they're designed for different traffic.
How do we build infrastructure agents can use?
anthropic.com/research/agent…
312
496
3,651
677,765
Nancy Yacovzada retweeted

May 31
A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
youtu.be/K5LAFEjTlBA
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
105
283
1,685
679,089
Nancy Yacovzada retweeted

May 25
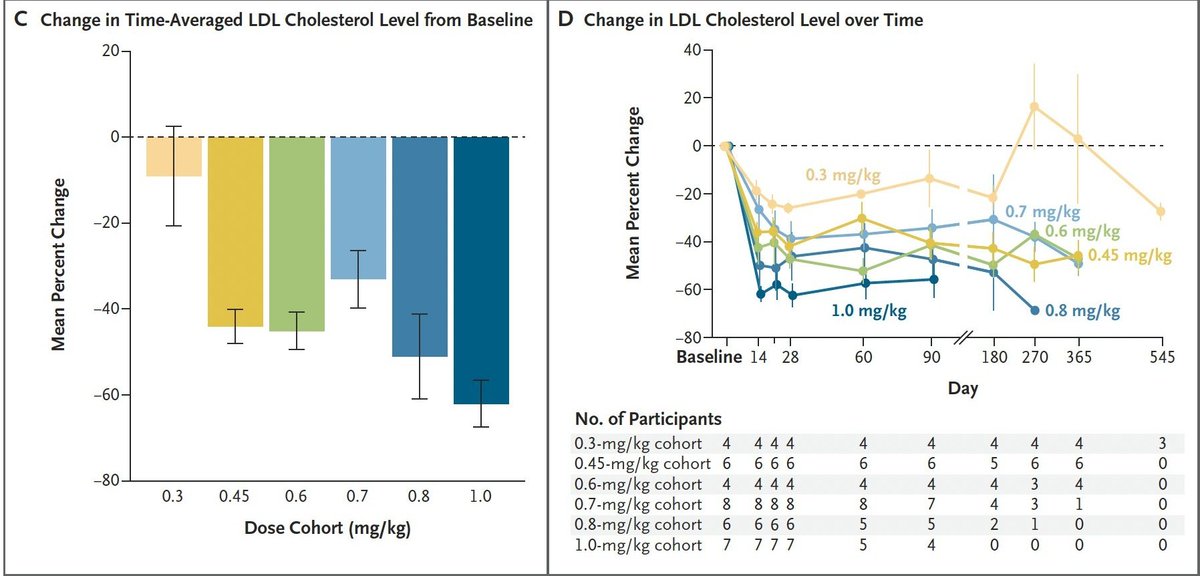
Eli Lilly has done it.
They've gone and made what seems to be a powerful, permanent gene therapy for LDL cholesterol.
That means they'll be able to effectively prevent most heart disease with a single infusion!
558
1,691
15,466
5,774,117
Nancy Yacovzada retweeted

May 25
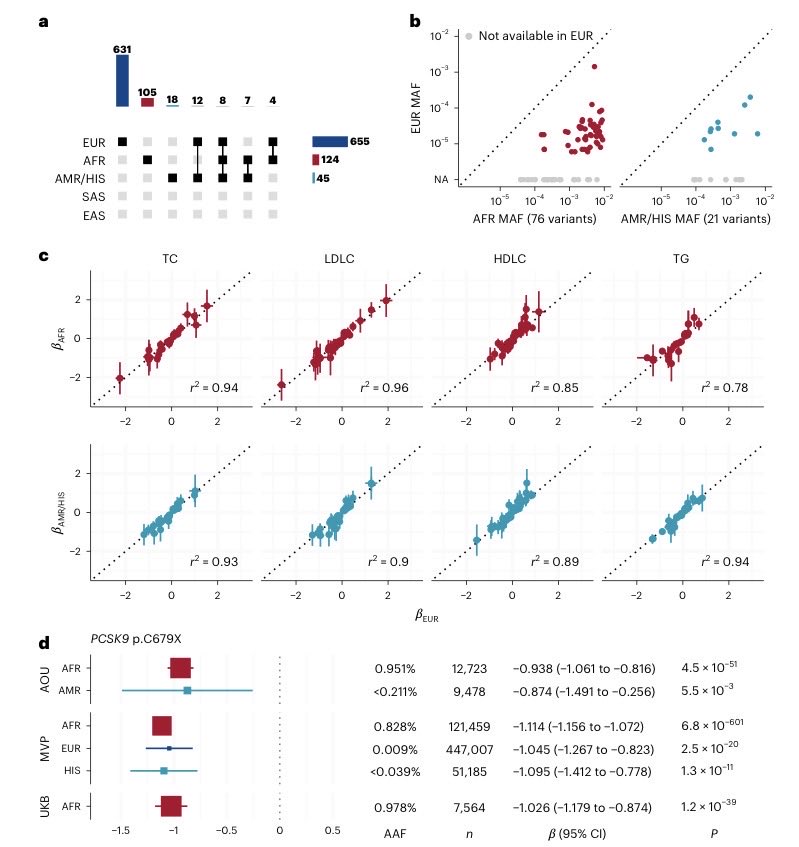
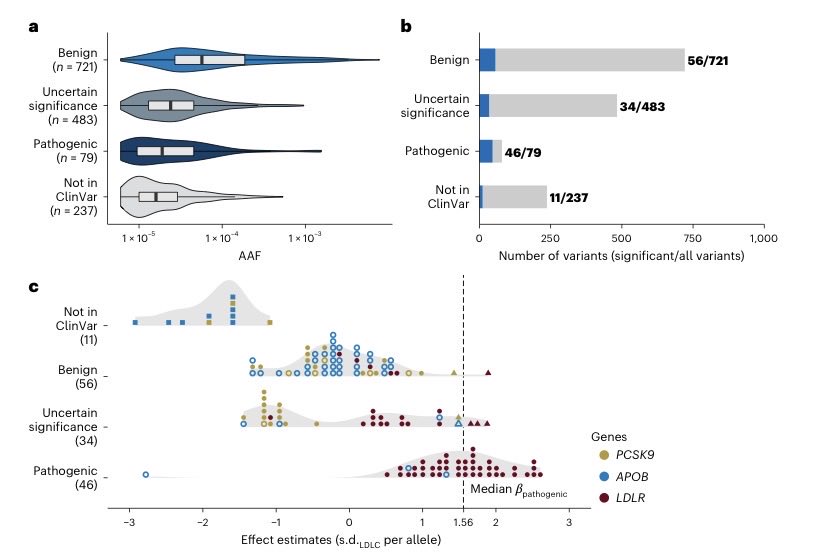
Analyzing protein-coding variants across 1.2M individuals, our study by @skoyamamd identifies new targets for lipid and CAD therapeutics & informs genetic testing for Mendelian dyslipidemias nature.com/articles/s41588-0… @NatureGenet

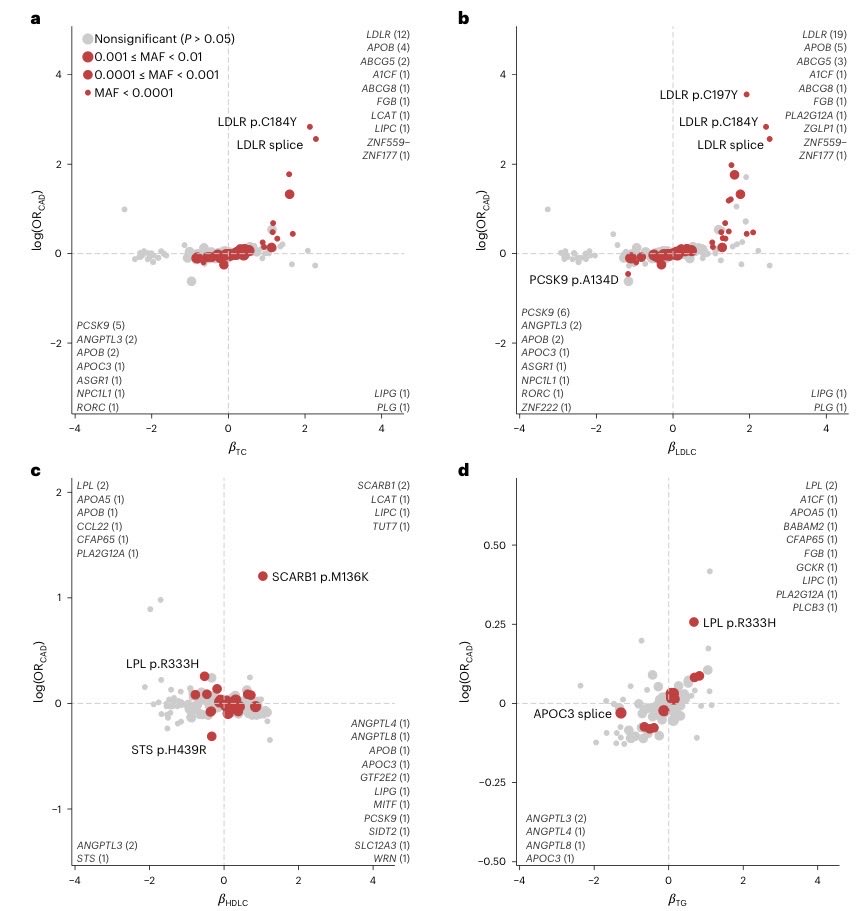
4
38
162
14,787

May 26
Core issue in scRNA perturbation modeling: latent spaces often prioritize cell-state variation over perturbation effect. This ICML paper use factorized VAE w/ sparse perturbation latents identifiability guarantees, improving OOD prediction of unseen perturbations/combinations.
1
92
May 26
Most intriguing part is the theoretical framing of "recoverability": perturbation prediction quality is tied to whether latent representations preserve causal intervention signals rather than merely denoising/compressing transcriptomic variation. Nice!
arxiv.org/abs/2605.19343
33
Nancy Yacovzada retweeted

Feb 24
the paper's solution is almost absurdly simple.
instead of sending <QUERY>, send <QUERY><QUERY>.
when the model hits the second copy, every token now attends to the full first copy. the question has already been seen. the context gets reprocessed with complete awareness.
you're essentially giving a unidirectional model a form of bidirectional attention. without changing the architecture. without any new training. just by repeating yourself.
1
2
20
1,683
Nancy Yacovzada retweeted
Feb 24
Google Research just proved you can boost llm accuracy by up to 76 percentage points with zero extra output tokens, zero latency increase, and zero fine-tuning 🤯
the technique: paste your prompt twice.
that's it. that's the paper.
but WHY it works reveals something important about how every llm you use actually reads your input:
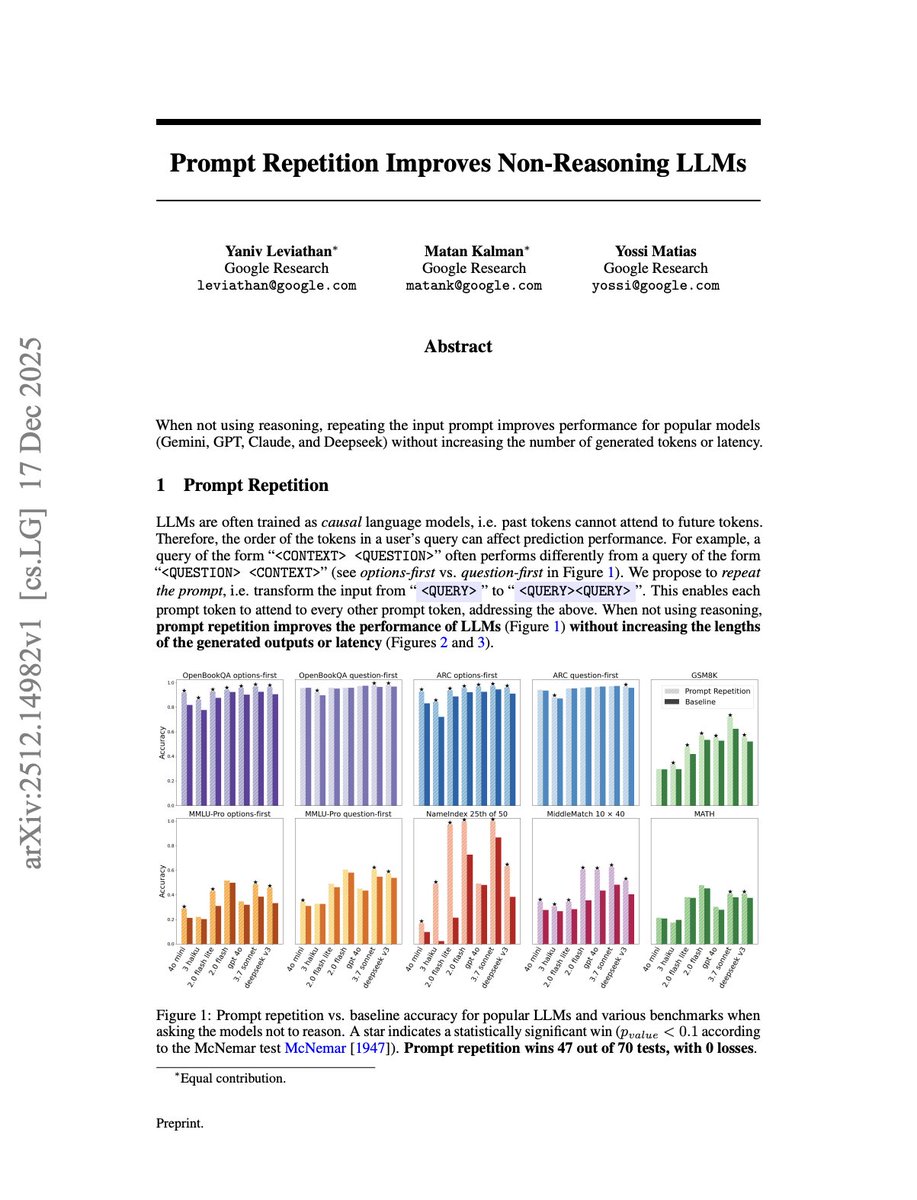
37
61
362
24,160
Nancy Yacovzada retweeted

Feb 9
🚨🇮🇷BREAKING: An Iranian Boeing 747 cargo plane landed in Tehran arriving from Moscow, while another plane took off from Tehran for an unknown destination in China.
There have been quite a few such movements in recent months.
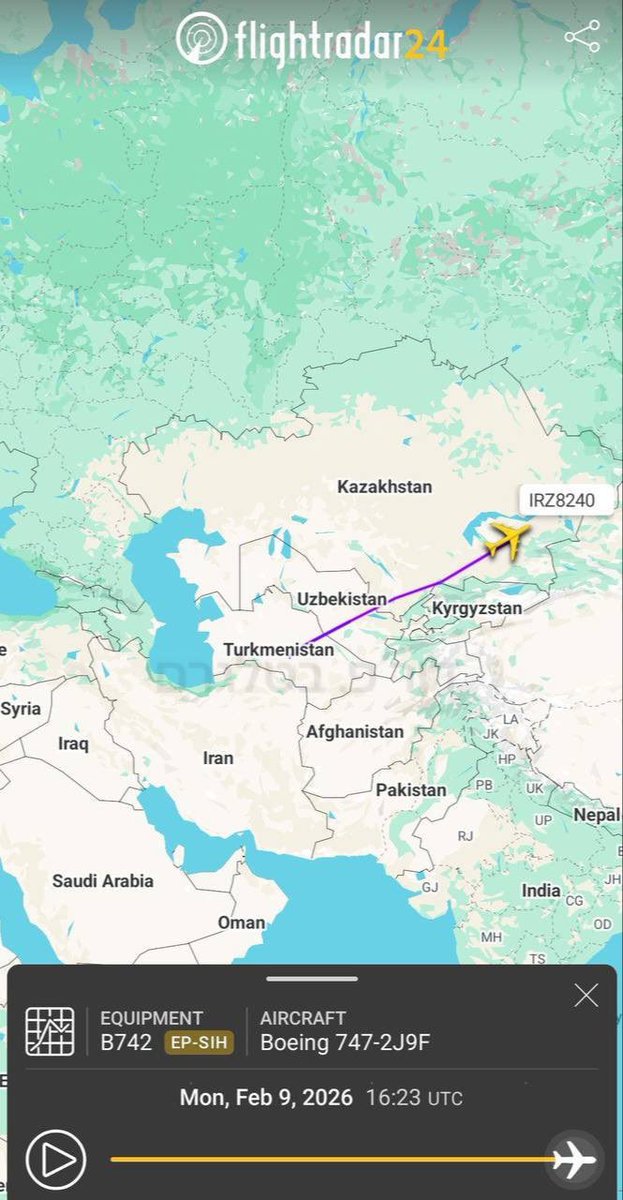
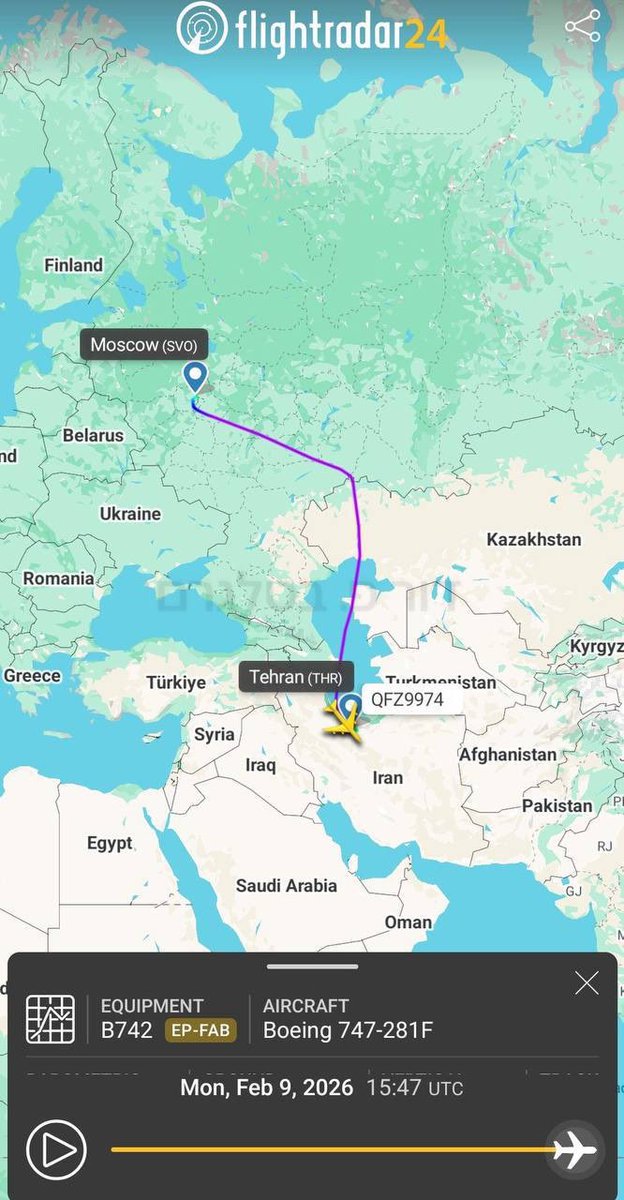
31
98
467
25,702
Nancy Yacovzada retweeted

Jan 27
אני חושב שהFomo בימים אלו בתחום ה AI הוא ברף הגבוה ביותר מזה שנים.
19
1
177
24,479
26 Dec 2025
Important study, simple meta-analysis.
The physiological consequences of GLP-1RA discontinuation: "it is imperative that treatment guidelines address not only initiation and titration but also discontinuation and long-term maintenance strategies to sustain therapeutic gains."
25 Dec 2025

💉 GLP-1 works—but muscles decide the outcome.
🔬 A new meta-analysis (18 RCTs, ~3,800 participants) shows significant weight regain and worsening metabolic health after GLP-1 discontinuation
thelancet.com/journals/eclin…
1
3
337
Nancy Yacovzada retweeted

14 Dec 2025
There are MULTIPLE Unsupervised Tesla Model Y Robotaxis currently driving around Austin, TX. The Robotaxis have no safety monitors.
It’s officially happening.
14 Dec 2025

NEWS: A second Tesla Model Y Robotaxi running FSD Unsupervised has just been spotted driving itself on public roads in Austin, Texas, with no one in the front seats.
This is a different car from the one spotted earlier. They have different license plates.
h/t @Mandablorian
53
293
3,076
116,910
Nancy Yacovzada retweeted

15 Dec 2025
FBI stops planned New Year’s Eve Los Angeles terror attack by pro-Palestinian cell trib.al/WL3P5Fc

124
578
1,974
133,972
Nancy Yacovzada retweeted

28 Nov 2025
7 days for a manuscript review with AI human @NEJM_AI ai.nejm.org/doi/full/10.1056…
4
17
77
47,117
Nancy Yacovzada retweeted

9 Oct 2025
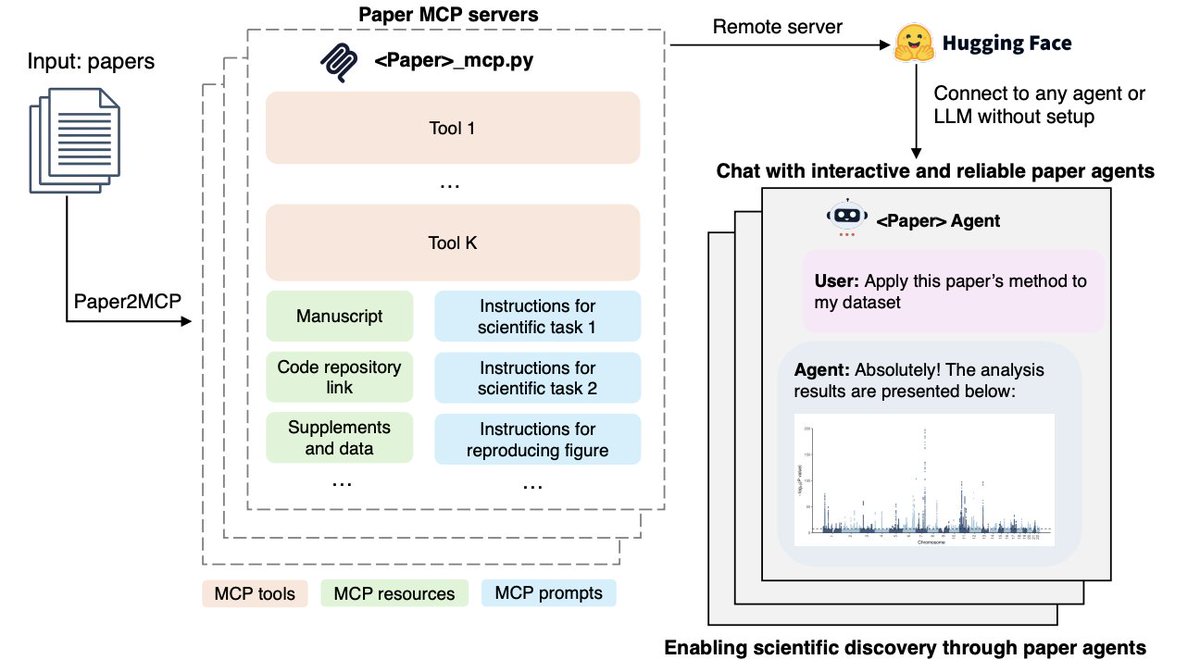
Holy shit...Stanford just built a system that converts research papers into working AI agents.
It’s called Paper2Agent, and it literally:
• Recreates the method in the paper
• Applies it to your own dataset
• Answers questions like the author
This changes how we do science forever.
Let me explain ↓
91
819
4,137
299,526
Nancy Yacovzada retweeted

9 Oct 2025
🚨 The older the sperm, the more likely it is to cause autism
Sequencing sperm using nearly error-free sequencing → measure % sperm carrying disease-causing mutations:
2% at age 30 → 4.5% at 70
Most were autism genes
New paper in @Nature today 🧵
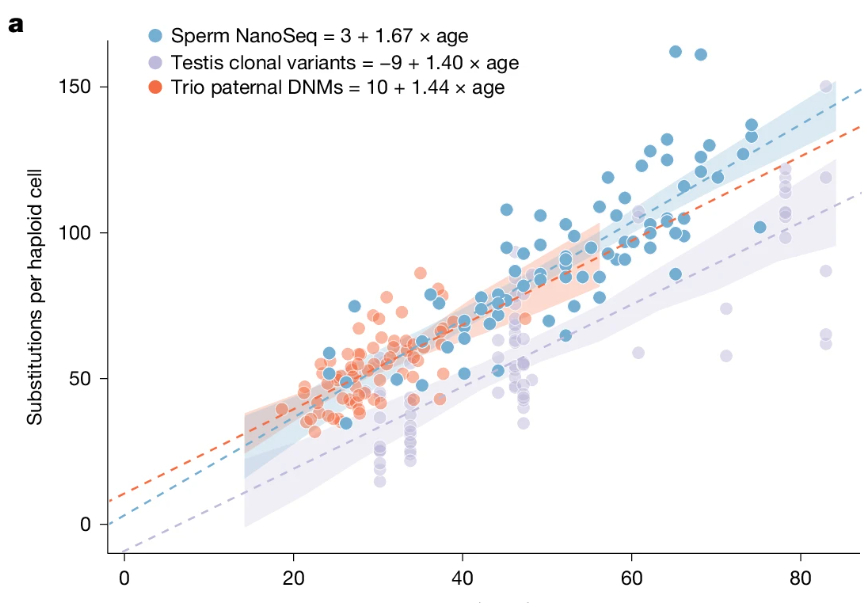
ALT https://www.nature.com/articles/s41586-025-09448-3#Fig3
133
613
2,512
892,990
Nancy Yacovzada retweeted

8 Sep 2025
I'm a neuroscientist.
"AI psychosis" is constantly in the news. Together with my psychiatry colleague, I reviewed the largest case-series published so far.
Here are my thoughts 🧵

10
25
159
12,268