
Assistant Professor (RTD-A) @ UniTn -- Representation Learning, Continual Learning, Compatible Learning
Joined February 2021
- Tweets 96
- Following 861
- Followers 174
- Likes 1,303
10 Photos and videos







Jun 12
Back to #CVPR2026 with some good news:
Our paper "A Stationary (and Therefore Compatible) Representation is All You Need" was accepted to IEEE TPAMI 2026!
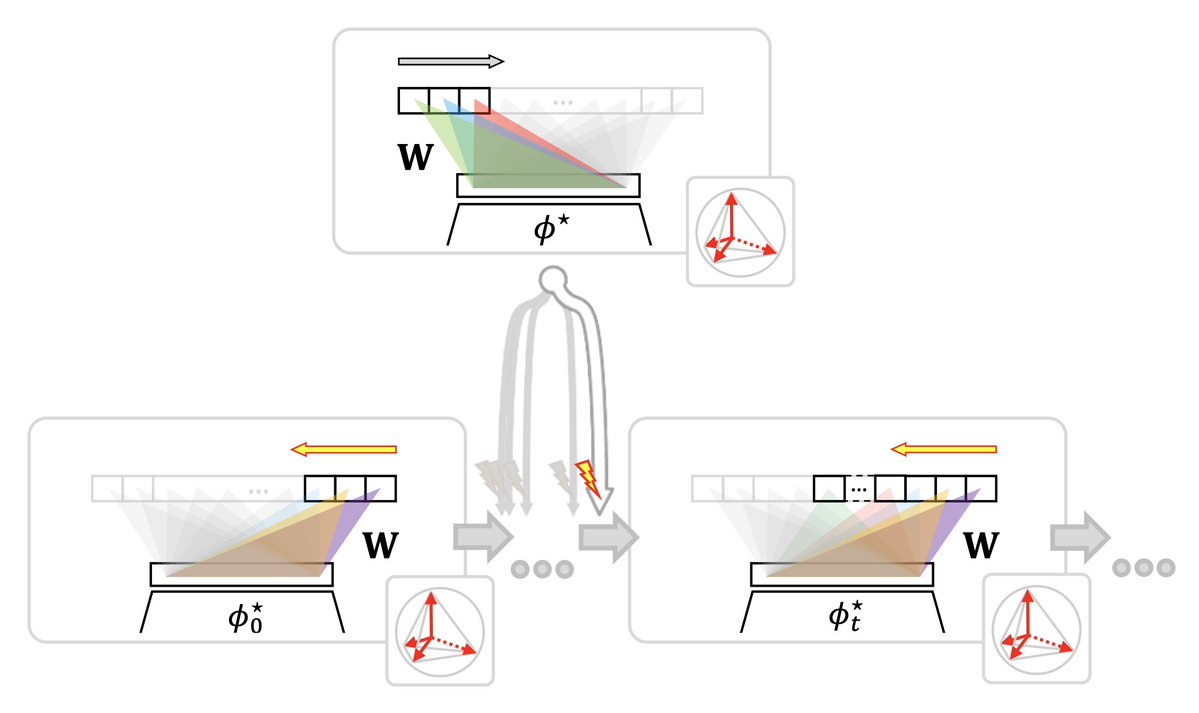
How to update a model over time without re-embedding everything you've already stored 🧵
1
1
3
166
Jun 12
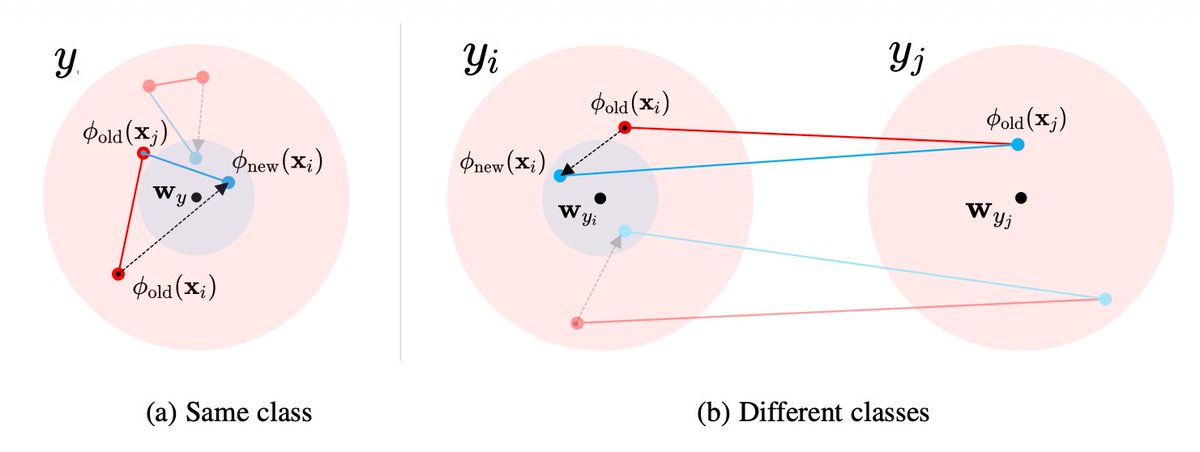
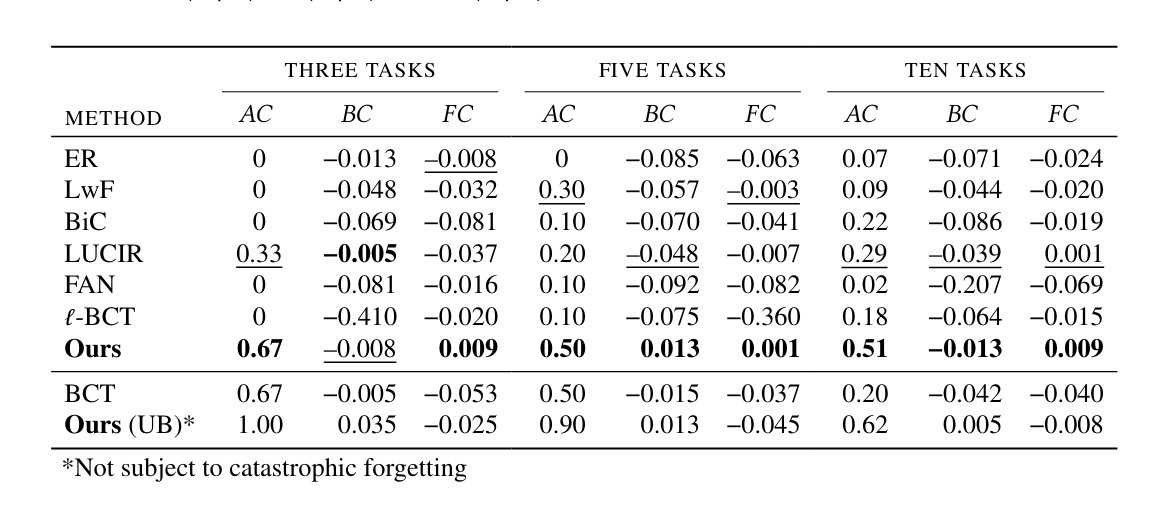
🧲 But since every model is anchored to the same fixed simplex, a fresh model's features stay compatible with all stored ones. The upgrade improves retrieval on the old gallery with no re-indexing — only simplex methods gain, others degrade. 8/
1
54
Jun 12
👥 Joint work with @FedPernici, @ricciunifi, and Alberto Del Bimbo.
📄 Paper: arxiv.org/abs/2606.12488
🔗 Project: niccobiondi.github.io/projec…
1
2
51
Niccolò Biondi retweeted

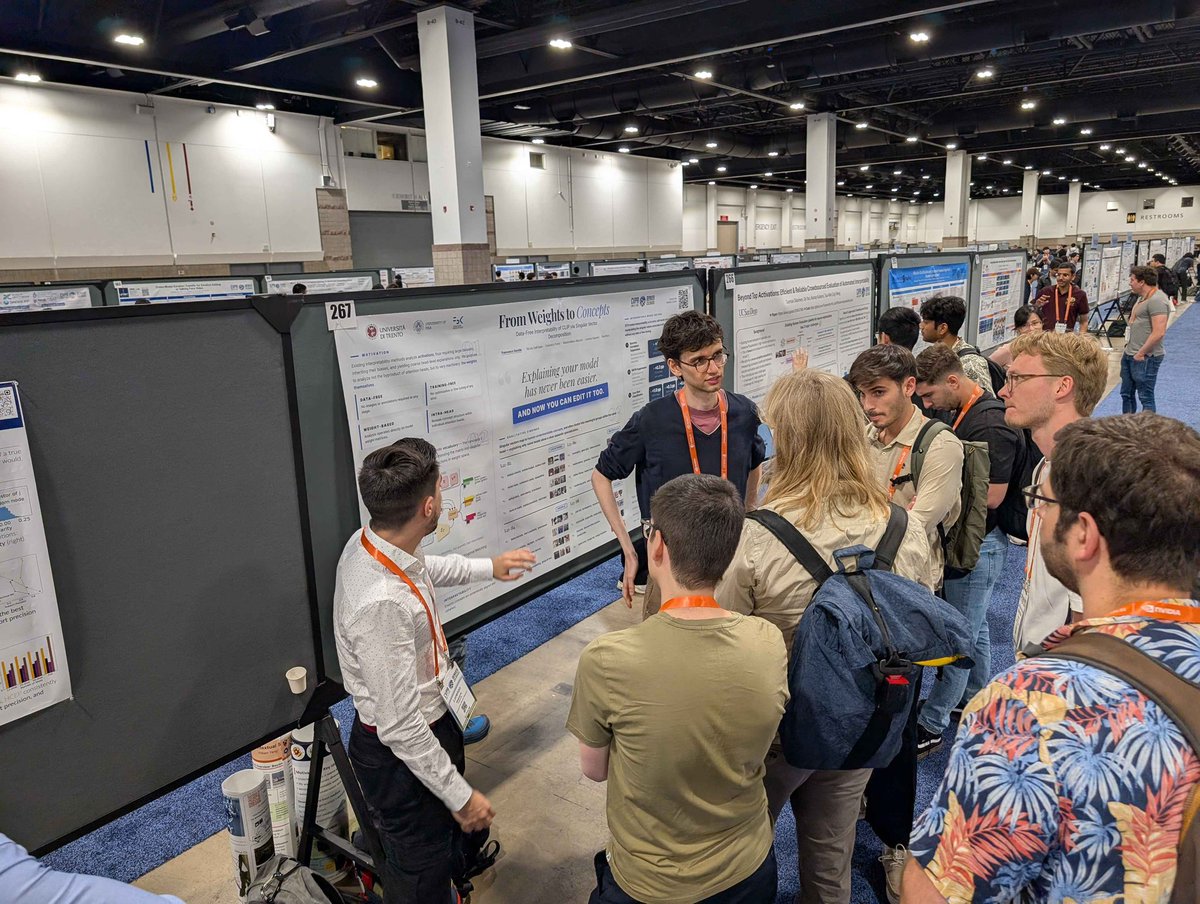
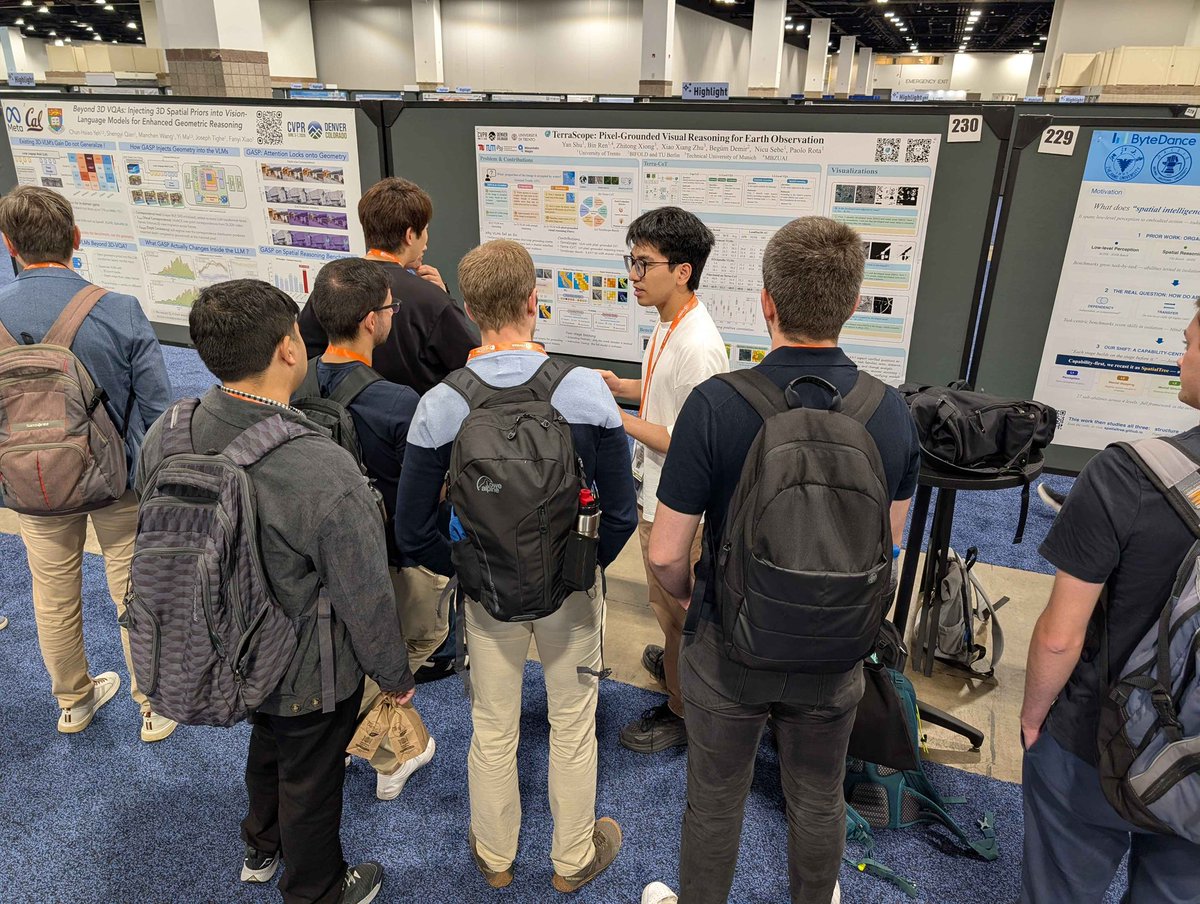
🙏 CVPR is a wrap for the MHUG lab! A huge thank you to everyone who stopped by our posters, asked questions, and shared ideas. It’s been an incredible few days. See you next year! 👋 #CVPR2026
More pics from our posters 👇


1
7
19
884
Niccolò Biondi retweeted
🚀 CVPR, here we come!
The MHUG team is bringing a massive lineup of 17 papers this year, and we couldn't be more excited to share what we've been building! 🧠💻
🧵👇

1
6
15
480
Niccolò Biondi retweeted

5 Dec 2025
Excited to present our #NeurIPS2025 paper on "λ-Orthogonality Regularization for Compatible Representation Learning" today! 🎉
Come chat with me at Poster #2503 in Exhibit Halls C, D, E
📅 Fri, Dec 5 | 🕚 11am – 2pm PST
#MachineLearning #AI #Compatibility #RepresentationLearning
1
3
4
471
Niccolò Biondi retweeted

5 Dec 2025
λ-Orthogonality: a tiny near-orthogonal adapter with a controllable λ "knob" to balance geometry preservation and adaptation. Enables backward-compatible embeddings (no full backfill) with near new-model performance and <50% gallery updates. @NeurIPSConf #NeurIPS2025
5 Dec 2025

Excited to present our #NeurIPS2025 paper on "λ-Orthogonality Regularization for Compatible Representation Learning" today! 🎉
Come chat with me at Poster #2503 in Exhibit Halls C, D, E
📅 Fri, Dec 5 | 🕚 11am – 2pm PST
#MachineLearning #AI #Compatibility #RepresentationLearning
1
1
5
344
Niccolò Biondi retweeted
4 Dec 2025
Encouraging to see compatibility discussed in this NeurIPS workshop. The theoretical understanding of the problem’s structure is still limited, with room for useful progress. @NeurIPSConf #NeurIPS2025
sites.google.com/view/ccfm-n…
7 Jul 2025

Is your AI keeping Up with the world?
Announcing #NeurIPS2025 CCFM Workshop: Continual and Compatible Foundation Model Updates
When/Where: Dec. 6-7 San Diego
Submission deadline: Aug. 22, 2025. (opening soon!)
sites.google.com/view/ccfm-n…
#FoundationModels #ContinualLearning
1
2
380
14 Nov 2025
LeJEPA what else
12 Nov 2025

LeJEPA: a novel pretraining paradigm free of the (many) heuristics we relied on (stop-grad, teacher, ...)
- 60 arch., up to 2B params
- 10 datasets
- in-domain training (>DINOv3)
- corr(train loss, test perf)=95%
Paper: arxiv.org/pdf/2511.08544
Code: github.com/rbalestr-lab/leje…
1
87
18 Sep 2025
🎉 Thrilled to share that our paper has been accepted to #NeurIPS2025 — more details coming soon!
@NeurIPSConf @miccunifi
2
1
17
1,286
Niccolò Biondi retweeted

1 Sep 2025
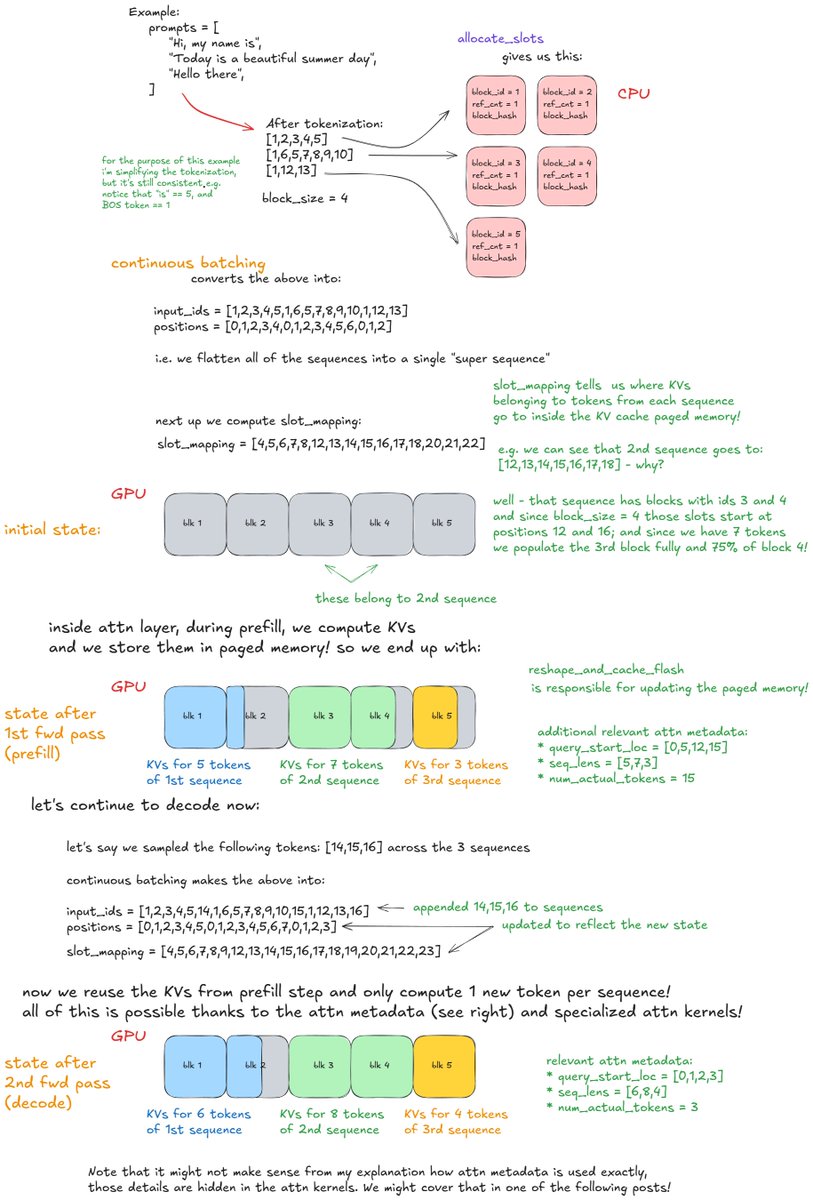
New in-depth blog post - "Inside vLLM: Anatomy of a High-Throughput LLM Inference System". Probably the most in depth explanation of how LLM inference engines and vLLM in particular work!
Took me a while to get this level of understanding of the codebase and then to write up this one - i quickly realized i understimated the effort. 😅 It could have easily been a book/booklet (lol).
I covered:
* Basics of inference engine flow (input/output request processing, scheduling, paged attention, continuous batching)
* "Advanced" stuff: chunked prefill, prefix caching, guided decoding (grammar-constrained FSM), speculative decoding, disaggregated P/D
* Scaling up: going from smaller LMs that can be hosted on a single GPU all the way to trillion params (via TP/PP/SP) -> multi-GPU, multi-node setup
* Serving the model on the web: going from offline deployment to multiple API servers, load balancing, DP coordinator, multiple engines setup :)
* Measuring perf of inference systems (latency (ttft, itl, e2e, tpot), throughput) and GPU perf roofline model
Lots of examples, lots of visuals!
---
I realize i've been silent on social - many of you noticed and thanks for reaching out! :) --> I'm so back! lots of things happened.
Also, in general, I'm a bit sick of superficial content, it really is an equivalent of junk food (h/t @karpathy).
I want to do the best/deepest technical work of my life over the next years and write much more in depth (high quality organic food ;)) so I might not be as frequent around here as i used to be (? we'll see). I'll make it a goal to share a few paper summaries a week or stuff that's relevant / in the zeitgeist.
If you have any topics that happened over the past few weeks/months drop it down in the comments i might focus on some of those in my next posts.
---
Huge thank you to @Hyperstackcloud for giving me an H100 node to run some of the experiments and analysis that i needed to write this up. The team there led by Christopher Starkey is amazing!
Also a big thank you to Nick Hill (who did a very thorough review of the post - basically a code review lol; Nick's a core vLLM contributor and principal SWE at RedHat) and to my friends Kyle Krannen (NVIDIA Dynamo), @marksaroufim (PyTorch), and @ashVaswani (goat) for taking the time during weekend when they didn't have to!
63
400
2,568
324,030
Niccolò Biondi retweeted

3 Mar 2025
Calling all AI researchers & comic lovers! 🚀
Can your model pick the right comic panel? 🤖
Join the #ICDAR2025 Comics Understanding Competition & submit your results by 15/04/2025! 📆
Challenge: rrc.cvc.uab.es/?ch=31
Dataset: huggingface.co/datasets/VLR-…
Submissions are open!
1
5
11
485
Niccolò Biondi retweeted

5 Nov 2024
Are you a professional working on video in Milan ? Come to the Milan Video Tech Meetup this Thursday (Nov. 7, 6:00 PM CET) at the NTTData headquarters, Via Ernesto Calindri, 4.
I'll talk about how to use GenAI to improve the performance of video codecs.
meetup.com/milan-video-tech-…

1
3
10
318