
Joined October 2025
- Tweets 46
- Following 85
- Followers 68
- Likes 92
2 Photos and videos


Pinned Tweet

Apr 22
We are at #ICLR2026 🇧🇷 presenting 5 papers spread across the main conference, 23-24-25 April. Stop by if you are interested in trustworthy and safe AI, generative models, robustness, and model inversion
with @Hussain68018934 @BrigliaRosaria @adrianrminut Dario, and Hazem
6
13
366
OmnAI Lab retweeted

Jun 9
这可能是人类写给 AI 看的最后一篇论文了。
最近刷到Stanford、CMU、Michigan 等 37 位作者联名的论文:《The Last Human-Written Paper》。
核心观点很狠:沿用几百年的论文,在 AI 时代可能已经过时了。
作者点出了两个被我们忽视已久的“隐形税”:
一个是叙事税。为了讲一个漂亮故事,我们把失败实验、死路、被推翻的假设都删掉了。AI 读到的是“通关攻略”,却看不到真正有价值的“踩坑记录”。
另一个是工程税。论文里的实现细节通常足够说服审稿人,但不够让 Agent 直接复现。很多关键 tricks 还藏在作者脑子、代码注释和 Slack 记录里。
所以作者提出 ARA,直接把论文改造成 Agent 能读取和执行的“研究包”:不只告诉你结论,还把怎么想到的、代码怎么跑、证据链在哪、哪些路走不通都打包进去。
我觉得这篇最有意思的地方是,它不是在讨论 AI 怎么帮人写论文,而是在问:
当 AI 也变成论文读者和执行者时,论文还应该长成今天这样吗?
未来科研输出的核心,可能不再是“写得多像一篇 paper”,而是能不能被 AI 理解、复现、追踪和继续扩展。
人类写论文写了几百年,接下来可能要开始写给 Agent 执行的研究包了。
arxiv.org/pdf/2604.24658

134
508
2,406
241,863

Thanks to everyone who joined us at the MUV Workshop at @CVPR !
@muv_workshop focused on selective data removal,
concept erasure, debiasing & model editing, as well as safe image/video generation & post-training control.
Great to see the community come together to advance the future of safe, privacy-aware, and trustworthy AI.
#CVPR2026


1
10
162
OmnAI Lab retweeted

oh! 😌

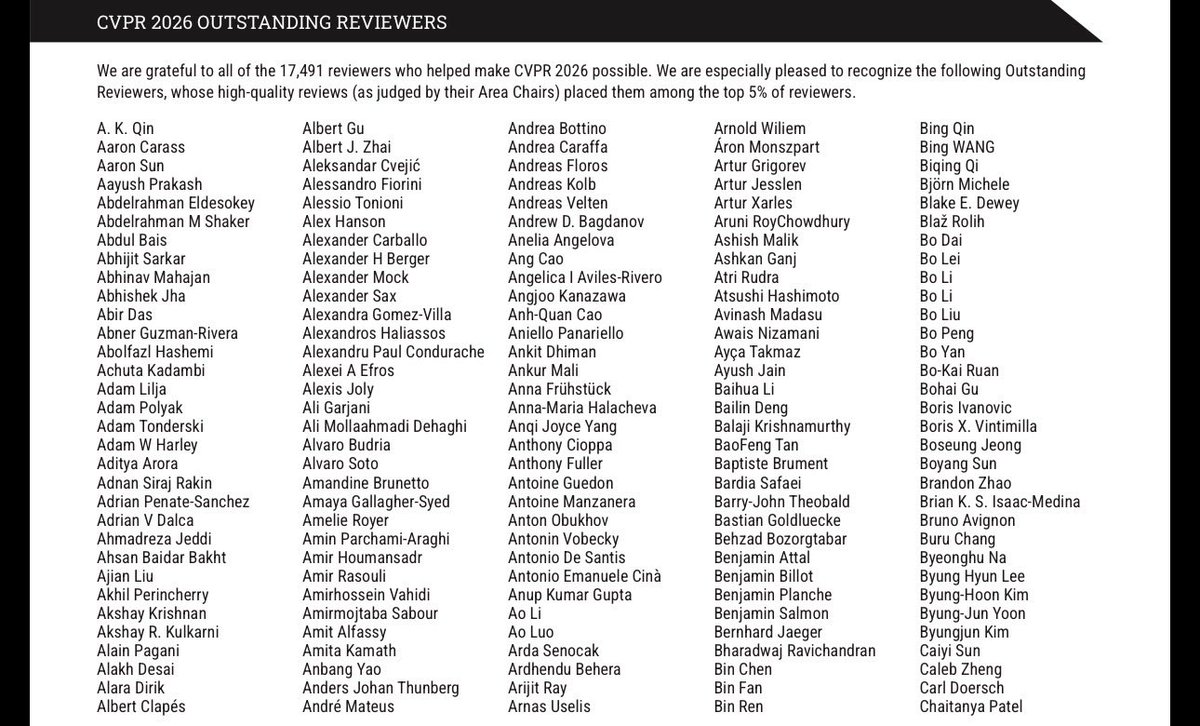
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.



1
4
418
OmnAI Lab retweeted

📢CPF: U&ME Workshop @ ECCV 2026 @eccvconf
We invite submissions on machine unlearning, model editing, and related topics including efficient adaptation, and responsible AI.
Details at: sites.google.com/view/u-and-…
@_iAc #ECCV #ECCV2026 #Unlearning #AIsafety #ResponsibleAI

4
5
2,332
OmnAI Lab retweeted
🧠 Excited to announce 𝕌&𝕄𝔼 𝟚𝟘𝟚𝟞— 𝘁𝗵𝗲 𝟯𝗿𝗱 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 & 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲 𝗼𝗻 𝗨𝗻𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗠𝗼𝗱𝗲𝗹 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 @eccvconf
Organized with @Hussain68018934 @THassner @thakralkartik78 @BrigliaRosaria @MayankVatsa3 @dgolano @sijialiu17
📅 September 8–9, 2026 📍 Malmö, Sweden
How do we fix, update & align large generative models — without retraining from scratch?
🎤 Confirmed Speakers:
Yezhou Yang — Arizona State University
Fabio Galasso — Sapienza University of Rome
William Shen — University of Cambridge
More speakers coming soon!
Stay tuned for submission details 👇
sites.google.com/view/u-and-…
#ECCV2026 #MachineLearning #ModelEditing #MachineUnlearning #GenerativeAI #DeepLearning

7
11
1,552
OmnAI Lab retweeted

May 18
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
136
973
7,418
575,159
OmnAI Lab retweeted

May 1
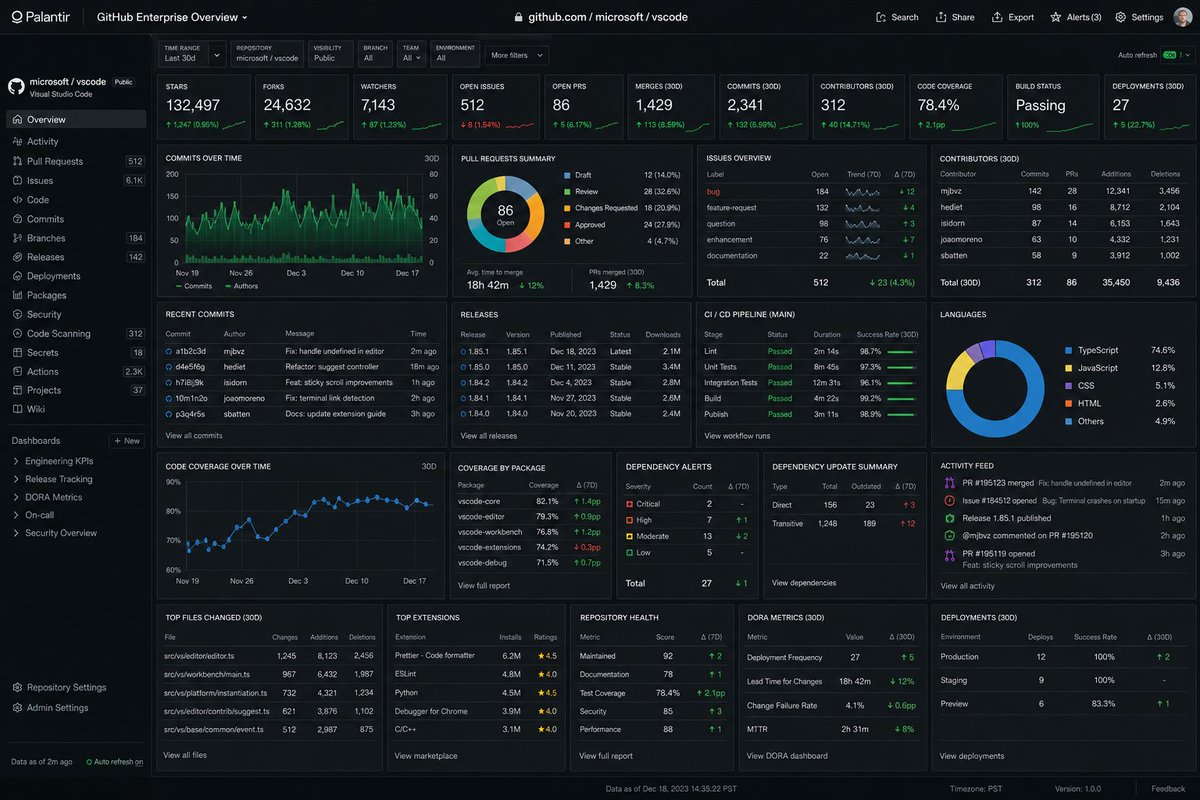
What if the EU built GitHub?
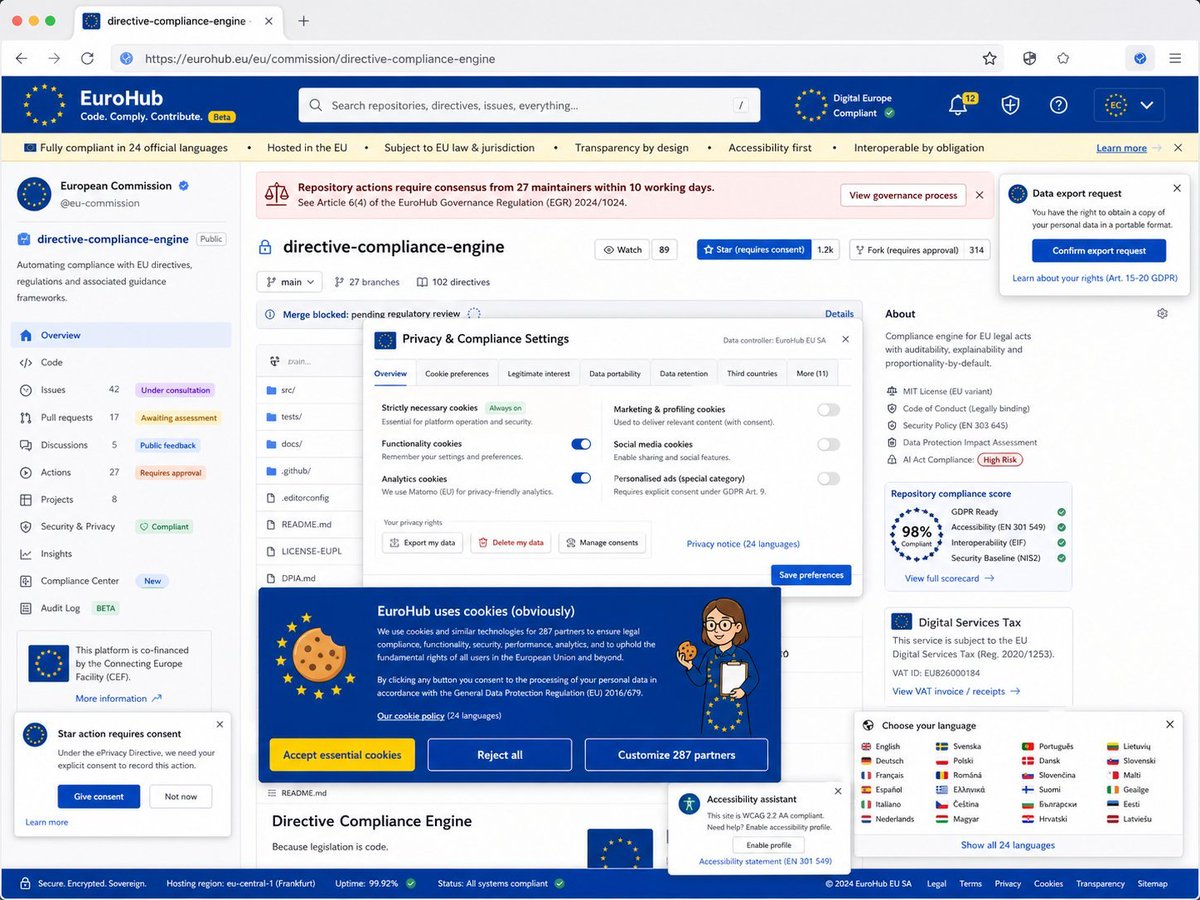
ALT inspired by https://x.com/initjean/status/2050283688370352369

309
860
11,718
7,044,637
OmnAI Lab retweeted

Apr 27
Join us for a full day of talks related to diffusion and flow based methods in the ReALM-GEN workshop, happening today at ICLR ✨🇧🇷
📍Room 201 A/B
1
5
23
1,822
OmnAI Lab retweeted

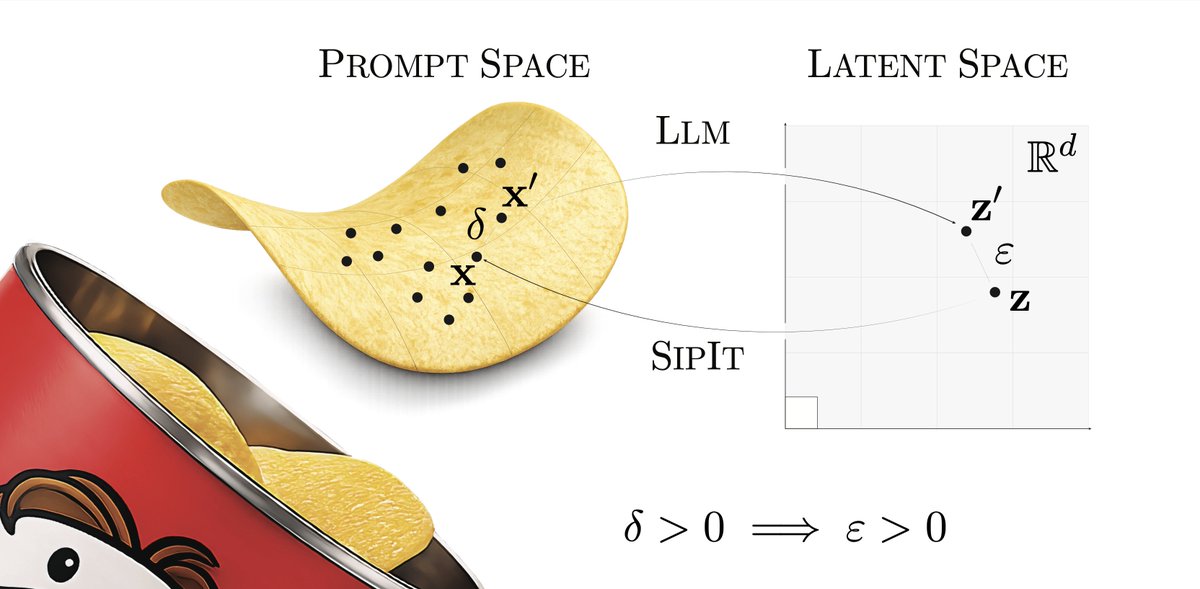
alright we can't hide it anymore
come and see the pringle in all its glory at @iclr_conf
27 Oct 2025

LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
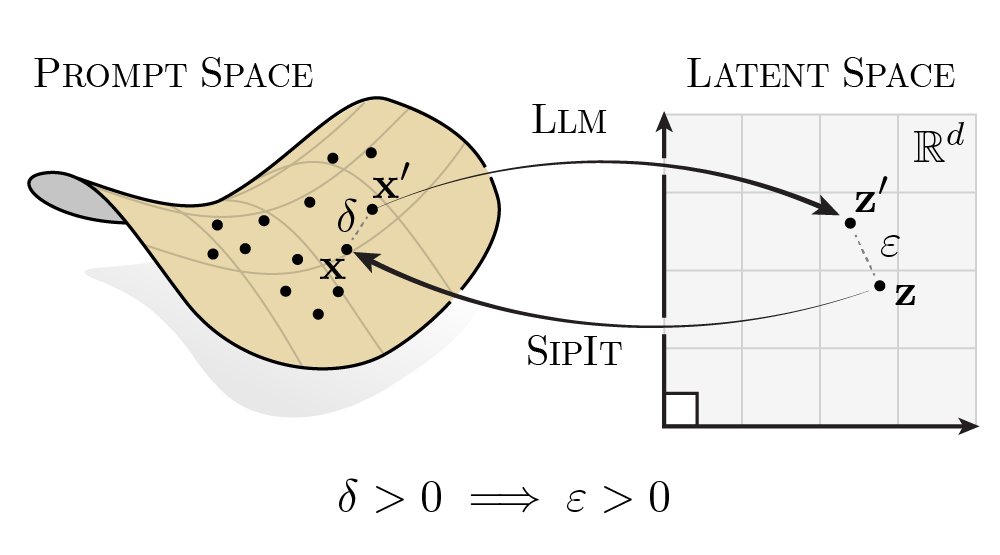
3
77
1,138
90,135
OmnAI Lab retweeted

Apr 20
presenting this loud one at #ICLR2026 in Rio as well
there's gonna be a surprise for pringle lovers.
even though that's not actually a pringle. it's an italian crik-crok
27 Oct 2025
LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
2
9
125
11,869
OmnAI Lab retweeted
It just takes a single gradient step on the input using an #EBM loss to boost the #robustness of robust LVLMs like CLIP/LLaVa. We also prove that the accuracy improves if the gradient norm of the gt class is the highest. thanks Odelia!

Part 1/3
Excited to share that our paper “A Provable Energy-Guided Test-Time Defense: Boosting Adversarial Robustness of Large Vision-Language Models” has been accepted at CVPR 2026 (Main Conference) 🎉

1
3
5
462
Apr 1
Huge congratulations to our third-year students on their remarkable work! 🎉 This is just the latest in a long streak of successful publications for us this year. See you at #CVPR26
Part 1/3
Excited to share that our paper “A Provable Energy-Guided Test-Time Defense: Boosting Adversarial Robustness of Large Vision-Language Models” has been accepted at CVPR 2026 (Main Conference) 🎉
3
92
OmnAI Lab retweeted
Part 1/3
Excited to share that our paper “A Provable Energy-Guided Test-Time Defense: Boosting Adversarial Robustness of Large Vision-Language Models” has been accepted at CVPR 2026 (Main Conference) 🎉
3
3
4
725
OmnAI Lab retweeted

Why can't we solve adversarial examples? After a decade of work, neural nets still get fooled by imperceptible noise. We think we finally know the geometric reason why — and it connects to AI alignment. 🧵
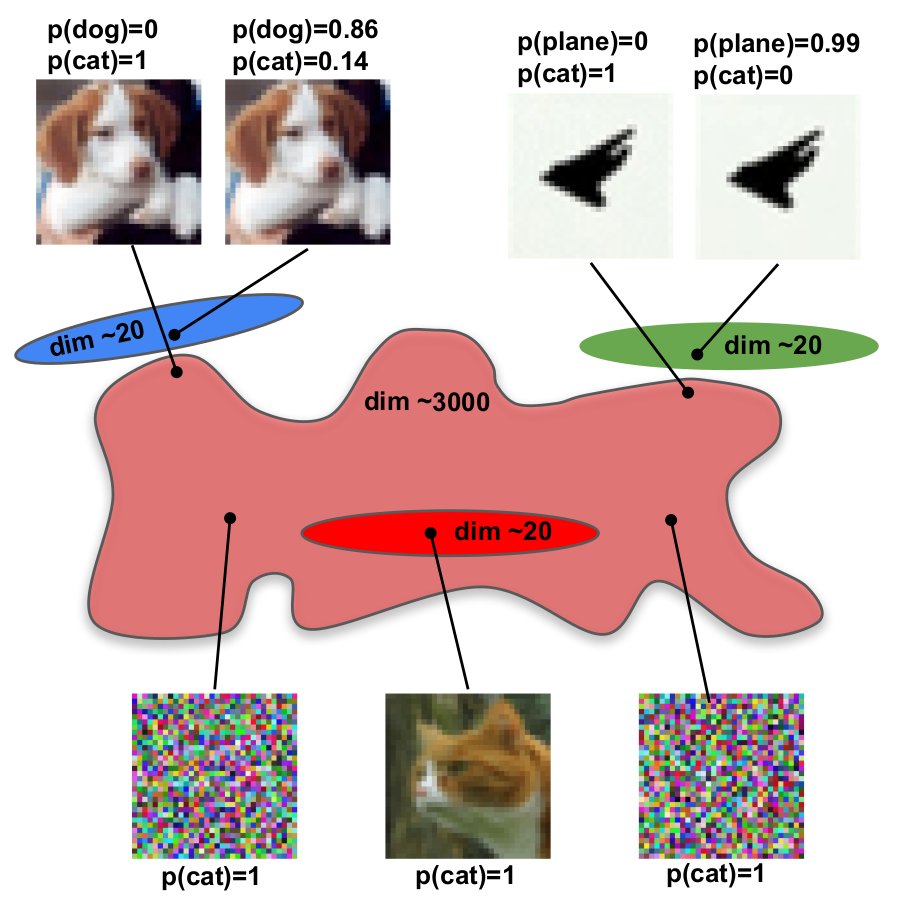
17
91
800
71,454
OmnAI Lab retweeted

Mar 15
Language Models are Injective and Hence Invertible (ICLR 2026), aka “pringle paper", is now a public graph on @paradigmainc’s Flywheel
In the paper, we show that LMs can be inverted and, contrary to common belief, do not discard information about their inputs at inference time.

27 Oct 2025
LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
2
18
101
22,139
OmnAI Lab retweeted

Mar 12
introducing Flywheel: the infrastructure for autonomous research.
27
72
556
121,812
📢 1 week left to submit your paper to the MUV Workshop at @CVPR 2026.
Take a step toward safe AI deployment and privacy-preserving learning.
More info: machine-unlearning-for-visio…
Updates & details: @muv_workshop
2
12
2,424
OmnAI Lab retweeted

Too late for #ECCV2026 submissions? 🤷
Not all is lost. Submit your work to MUV @CVPR
— Machine Unlearning for Vision 🧠🔐
🗓 Deadline: March 15
🔗 machine-unlearning-for-visio…
#AI #CVPR2026 #ComputerVision #ML
2
7
1,031
OmnAI Lab retweeted

What we also find very interesting is:
- instruct variants show a higher spillage to hallucination correlation; post-training artifacts?
- the math behind does not apply to just language modeling, any sequence-to-sequence task abides by the same rules!
2
3
225