
computer scientist, professor, researcher in computer vision (teaching machines to see), philosopher and ex-basketball player, scuba diver, human being!
Joined May 2008
- Tweets 3,295
- Following 302
- Followers 230
- Likes 467
132 Photos and videos













Pinned Tweet

🗓️ Poster Session 2 is this afternoon, come find us at board #133 (Paper ID 40689)!
🧘♂️ We'll be presenting ET3: an energy-based framework for adversarial robustness in vision-language models.
📌 With @Hussain68018934, Antonio D'Orazio, Odelia Melamed (Weizmann Institute)
#CVPR26

On Friday, June 5 (afternoon session), I along with @_iAc , Odelia Melamed and Antonio D'Orazio be presenting our paper at CVPR:
A Provable Energy-Guided Test-Time Defense Boosting Adversarial Robustness of Large Vision-Language Models.

1
129
Iacopo Masi ✈️ CVPR 2026 retweeted

Jun 7
This may be a controversial take, but I think it needs to be said: the gap between computer vision research in academia and industry is widening with every conference.
A huge fraction of @CVPR papers—especially those that boil down to "we tweaked/fine-tuned/RL'ed large-scale model X to improve on task Y"—will become obsolete with the next model release. That's not where academia creates lasting value. PIs should adapt much faster to this changing reality.
Academia should focus on fundamentally new ideas, new problem formulations, explaining emergent phenomenology, or uncovering blind spots that industry can later solve with scale, compute, and data.
37
115
1,125
94,344
oh! 😌

We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.



1
4
418
Iacopo Masi ✈️ CVPR 2026 retweeted

Everything is ready for MUV @CVPR 2026! 🧠❌
Join us in Denver on June 3 for the Machine Unlearning for Vision Workshop.
📍 Room 1AB
🕒 Afternoon session
Program, speakers, and details:
machine-unlearning-for-visio…
#CVPR2026 #MachineUnlearning #ComputerVision #AI

2
4
188
How did #ECCV reviews treat you? 😬 If you're not that happy — and you work on #unlearning, #modelediting, #modelmerging, or #interpretability — consider submitting to the 3rd Workshop and Challenge on Unlearning and Model Editing at @eccvconf
We accept both full papers and extended abstracts, so there's a format for every contribution.
📅 Submission deadline: 9 July 2026 (AoE)
🔗openreview.net/group?id=thec…
📢CPF: U&ME Workshop @ ECCV 2026 @eccvconf
We invite submissions on machine unlearning, model editing, and related topics including efficient adaptation, and responsible AI.
Details at: sites.google.com/view/u-and-…
@_iAc #ECCV #ECCV2026 #Unlearning #AIsafety #ResponsibleAI

3
3
1,151
Iacopo Masi ✈️ CVPR 2026 retweeted

May 24
#FG2026 just started! Post your work with the hashtag #FG2026 and interact with other participants.
fg2026.ieee-biometrics.org/
1
2
128
🧠 Excited to announce 𝕌&𝕄𝔼 𝟚𝟘𝟚𝟞— 𝘁𝗵𝗲 𝟯𝗿𝗱 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 & 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲 𝗼𝗻 𝗨𝗻𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗠𝗼𝗱𝗲𝗹 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 @eccvconf
Organized with @Hussain68018934 @THassner @thakralkartik78 @BrigliaRosaria @MayankVatsa3 @dgolano @sijialiu17
📅 September 8–9, 2026 📍 Malmö, Sweden
How do we fix, update & align large generative models — without retraining from scratch?
🎤 Confirmed Speakers:
Yezhou Yang — Arizona State University
Fabio Galasso — Sapienza University of Rome
William Shen — University of Cambridge
More speakers coming soon!
Stay tuned for submission details 👇
sites.google.com/view/u-and-…
#ECCV2026 #MachineLearning #ModelEditing #MachineUnlearning #GenerativeAI #DeepLearning
7
11
1,551
Iacopo Masi ✈️ CVPR 2026 retweeted

May 15
13
14
82
19,112
Iacopo Masi ✈️ CVPR 2026 retweeted

EUROCRYPT 2026 is underway in Rome!
Yesterday we officially opened the conference at the Auditorium Parco della Musica Ennio Morricone, the beautiful Renzo Piano-designed venue hosting the cryptography community this week.
#EUROCRYPT2026 #Cryptography




2
4
106
Iacopo Masi ✈️ CVPR 2026 retweeted

What will the role of researchers be in 5 years?
What happens to narrow scientific foundation models?
Can we really scale our way to genius creativity?
We will attempt to answer these questions (and more) on Sunday in the post-agi workshop at @iclr_conf

1
8
26
11,082


Iacopo Masi ✈️ CVPR 2026 retweeted

Apr 22
We are at #ICLR2026 🇧🇷 presenting 5 papers spread across the main conference, 23-24-25 April. Stop by if you are interested in trustworthy and safe AI, generative models, robustness, and model inversion
with @Hussain68018934 @BrigliaRosaria @adrianrminut Dario, and Hazem

6
13
366
Iacopo Masi ✈️ CVPR 2026 retweeted

Apr 21
Excited to share that "Energy-Based Transformers are Scalable Learners and Thinkers" was accepted to #ICLR2026 as an oral! 🎉
I'll be giving the oral this Friday in Brazil, so come watch if you're around :)

7
45
413
21,286
Iacopo Masi ✈️ CVPR 2026 retweeted

alright we can't hide it anymore
come and see the pringle in all its glory at @iclr_conf
27 Oct 2025

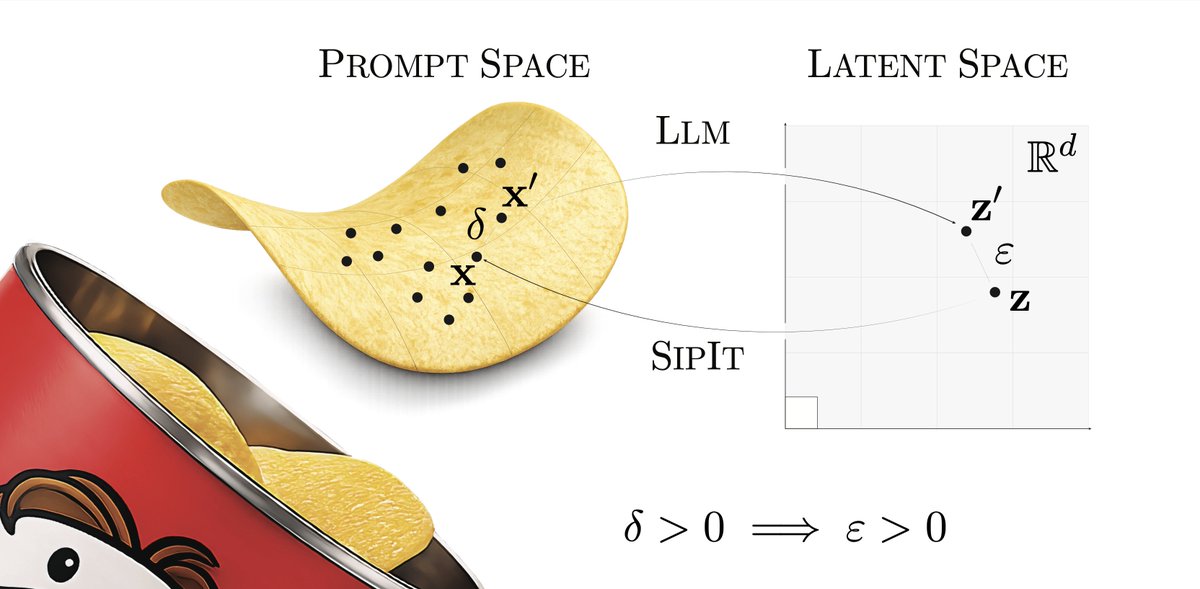
LLMs are injective and invertible.
In our new paper, we show that different prompts always map to different embeddings, and this property can be used to recover input tokens from individual embeddings in latent space.
(1/6)
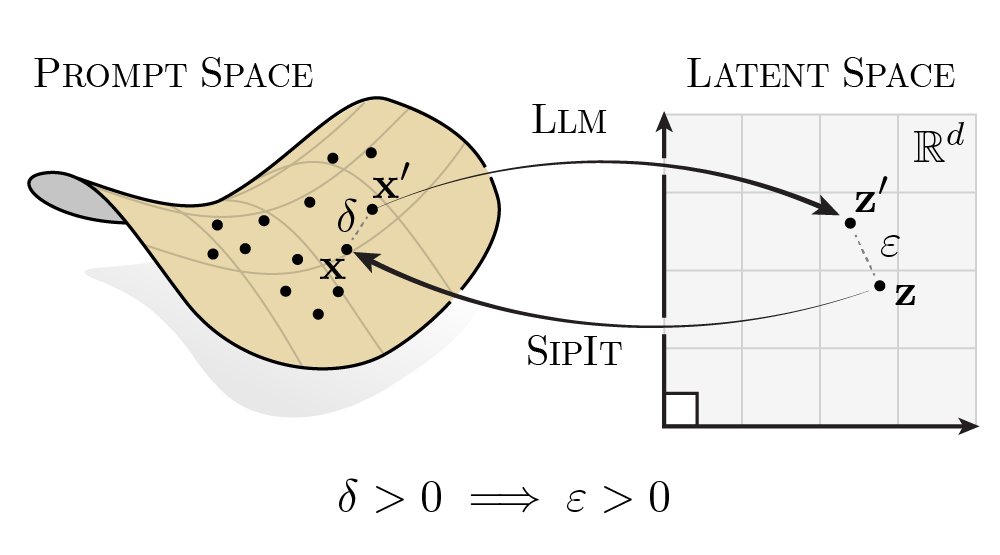
3
77
1,139
90,135
Iacopo Masi ✈️ CVPR 2026 retweeted

Apr 21
Sad to miss #ICLR2026 this year, but our work will be there with Simone and Stefano.
We propose the first training-free framework for permanently removing concepts from generative video models.
📅 Fri, Apr 24 • 11:15 AM – 1:45 PM
📍 Pavilion 4 P4-#4305
Bye bye DiCaprio!
1
5
10
645
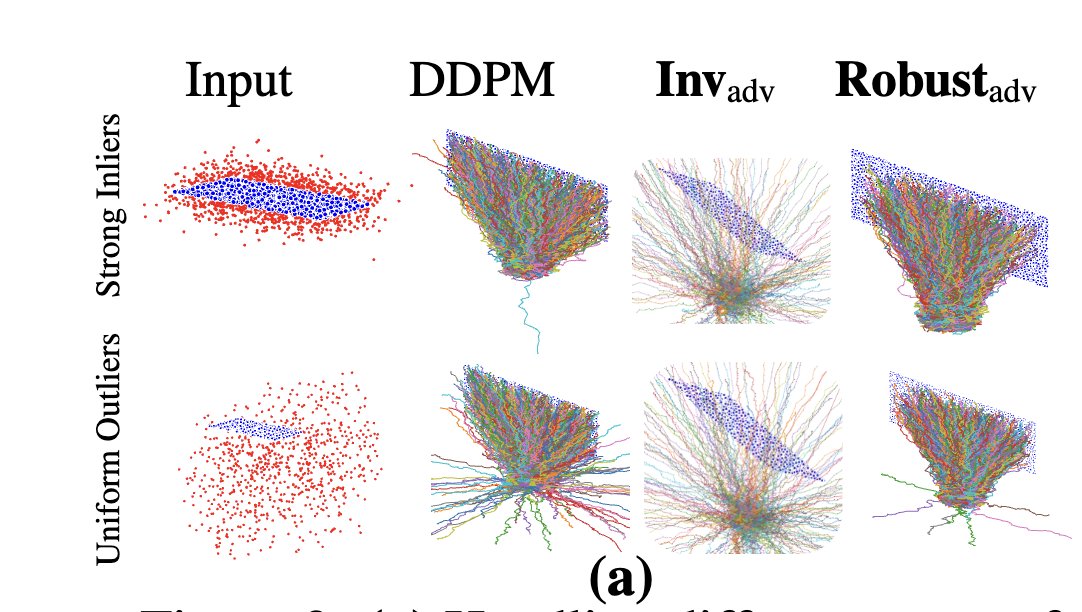
It just takes a single gradient step on the input using an #EBM loss to boost the #robustness of robust LVLMs like CLIP/LLaVa. We also prove that the accuracy improves if the gradient norm of the gt class is the highest. thanks Odelia!
Part 1/3
Excited to share that our paper “A Provable Energy-Guided Test-Time Defense: Boosting Adversarial Robustness of Large Vision-Language Models” has been accepted at CVPR 2026 (Main Conference) 🎉

1
3
5
462
Some "fixed" samples are very tricky, like VLM switches from Red Sox (incorrect) to Reds (correct), while, for example, @Hussain68018934 did not know the difference between the two, and we initially thought it was a mistake.
1
1
57
Joint work with @Hussain68018934 , Antonio from @OmnAI_Lab & Odelia from @WeizmannScience
Oh, this will be presented at @CVPR 2026 in Denver!
Link to the pre-print arxiv.org/pdf/2603.26984 #CVPR2026
116

@karpathy have you seen Flywheel? this is basically what we're building. x.com/i/status/2032178064533…

Andrej Karpathy on autoresearch with an untrusted pool of workers:
"My designs that incorporate an untrusted pool of workers (into autoresearch) actually look a little bit like a blockchain.
Instead of blocks, you have commits, and these commits can build on each other and contain changes to the code as you're improving it.
The proof of work is basically doing tons of experimentation to find the commits that work."
The idea that distributed & permissionless autoresearch ~= proof-of-useful-work remains a high-level intuition for now, but it is extremely intriguing to say the least.
Someone needs to take this further. See QT for more on what's missing.
1
1
35
2,450