
Public posts, AI training, and the right to be forgotten: why your decade-old tweets may still be influencing AI systems today.
#dataprivacy #machineunlearning...Show more

1
2
1,827

Everything is ready for MUV @CVPR 2026! 🧠❌
Join us in Denver on June 3 for the Machine Unlearning for Vision Workshop.
📍 Room 1AB
🕒 Afternoon session
Program, speakers, and details:
machine-unlearning-for-visio…
#CVPR2026 #MachineUnlearning #ComputerVision #AI

2
4
188

🧠 Excited to announce 𝕌&𝕄𝔼 𝟚𝟘𝟚𝟞— 𝘁𝗵𝗲 𝟯𝗿𝗱 𝗪𝗼𝗿𝗸𝘀𝗵𝗼𝗽 & 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲 𝗼𝗻 𝗨𝗻𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗮𝗻𝗱 𝗠𝗼𝗱𝗲𝗹 𝗘𝗱𝗶𝘁𝗶𝗻𝗴 @eccvconf
Organized with @Hussain68018934 @THassner @thakralkartik78 @BrigliaRosaria @MayankVatsa3 @dgolano @sijialiu17
📅 September 8–9, 2026 📍 Malmö, Sweden
How do we fix, update & align large generative models — without retraining from scratch?
🎤 Confirmed Speakers:
Yezhou Yang — Arizona State University
Fabio Galasso — Sapienza University of Rome
William Shen — University of Cambridge
More speakers coming soon!
Stay tuned for submission details 👇
sites.google.com/view/u-and-…
#ECCV2026 #MachineLearning #ModelEditing #MachineUnlearning #GenerativeAI #DeepLearning

7
11
1,551

May 7
【AAAI-26レポート】
LLMは一度学習したことを「忘れられない」——だから問題が起きる。AAAI-26ではその根本に挑む2つの研究が発表された。
🔬 Machine Unlearning
出力フィルターはモグラ叩き ニューロンの「経路」を直接編集する「MIP-Editor」を提案 「作り方だけ消す・認識はそのまま」という細粒度の制御を目指す
⚖️ CopyGuard
著作権を明示してもGPT-4o・Gemini・Claudeは結果を変えなかった 文字で拒否されるタスクがイメージデータで通ってしまう——この穴をCopyGuardで塞げるか
AIが「できること」だけでなく 「してはいけないこと」をどう実装するか。 その問いに、研究者たちは本気だ。
🔗 thinkit.co.jp/article/39177
#AAAI #LLM #MachineUnlearning #著作権 #AI安全性
1
2
249

Presenting Today at #AISTATS2026
An Illusion of Unlearning? Assessing Machine Unlearning Through Internal Representations (1/3)
#MachineUnlearning #NeuralCollapse

1
6
59
5,917

Apr 24
🧵 [6/5] It was nice to know from the industry folks visiting our poster yesterday that #MachineUnlearning has many practical use cases! Also attracted many 2nd order optimization folks looking for use cases, such as unlearning. @lululu0082

1
9
111

Apr 23
Evaluating machine unlearning (MU) remains a fundamental challenge, as existing methods typically require retraining reference models or performing membership inference attacks. These paradigms often rely on prior access to training configurations or supervision labels, rendering them impractical for real-world deployment.
To address this, we shift the focus from individual sample analysis toward evaluating whether a subset exhibits training-induced internal dependencies as a collective signal.
This approach is grounded in the insight that since model parameters are shaped by their training data, the output representations of a trained subset will exhibit significant statistical dependence.
We propose Split-half Dependence Evaluation (SDE), which uses the Hilbert–Schmidt Independence Criterion (HSIC) to assess these dependencies, for evaluating unlearning without requiring retraining or auxiliary classifiers.
In controlled experiments, SDE effectively distinguishes whether a given subset is part of the training dataset. Furthermore, evaluations on various unlearning algorithms demonstrate that SDE provides robust verification of unlearning success even in settings where existing evaluations fail to provide conclusive evidence.
@iclr_conf #iclr #iclr26 #machinelearning #machineUnlearning #ai

1
6
143

Interested in #MechanisticInterpretability #MachineUnlearning #PrivacyLeakage #MultiAgentSafety and more? 🤖🔍
Join CS7.405 Responsible & Safe AI Systems course project posters (21!) 🎓✨
🗓️ 25 April ⏰ 3:30 PM @iiit_hyderabad
Open to all… do join 🙌🏽 #ResponsibleAI #SafeAI

1
1
6
339
Apr 20
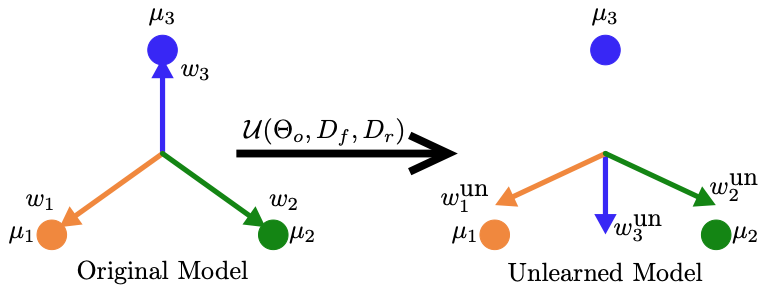
[1/5] Making AI “forget” without damaging its “brain” 🧠💻 is notoriously hard, but vital!
An AI model provider should give users the right to “own” and remove their data from its AI model in real time 📈 while retaining its performance. This is the core of “#MachineUnlearning”.
In our #ICLR2026 paper, we put one of the competitive unlearning algorithms known as Newton unlearning to the test, reveal where it fails on modern AI models (#LLMs included!), and turn those failures around with a rigorous fix 🛠️✅.
Ready for us to spill the tea? More below ☕ 🧵👇
=============
📄📌Paper “How to Cure Newton for Unlearning Neural Networks? An Empirical Study from the Hessian Perspective” (🔗openreview.net/forum?id=dHz2…) – a joint work with @nhungbui1299 @lululu0082 @RachaelSim2 See-Kiong Ng.
📅🗣️Meet us @iclr_conf 🇧🇷 Poster Session 2 Thurs Apr 23 3:15PM Pavilion 4 P4-#5304.
1
2
14
330
Jan 26
When a company claims that your personal data has been removed from their model, have you ever wondered whether they've indeed done so? 🤔
If a new paper on arXiv claims that its proposed #MachineUnlearning algorithm can unlearn your personal data from an #LLM, how do we know if it can indeed do so?
🛢️WaterDrum is the first data-centric LLM unlearning metric based on watermarking that is calibrated, requires no retraining, works for blackbox models and when forget/retain sets have similar data.
Let the (Water)Drums roll at Rio! @iclr_conf #ICLR2026
9 May 2025

Introducing WaterDrum🛢️, the first data-centric #LLM #unlearning metric that leverages robust text #watermarking💧to provide an effective, practical, and resilient way to evaluate LLM unlearning performance😉! (1/n)
#MachineUnlearning #LLMs

1
6
463

Jan 14
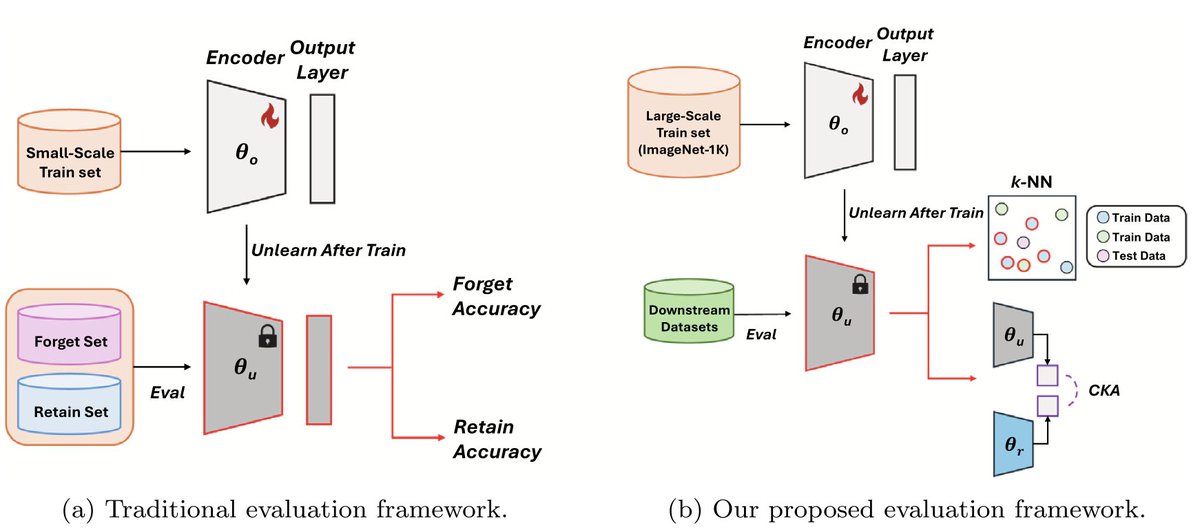
Is your unlearned model truly forgetting, or is it just hiding the evidence? For years, #MachineUnlearning evaluation has relied heavily on logit-based metrics (like accuracy). But in our new paper, "Are we truly forgetting? A critical re-examination of machine unlearning evaluation protocols", accepted to #EAAI, we found that these metrics can be misleading.
We observed that while models appear to "forget" based on their outputs, they often merely modify the classifier head while preserving the original knowledge in their feature representations. Essentially, the model isn't unlearning; it's taking a shortcut.
To address this, we propose a holistic benchmark framework:
1. Representation-based metrics: Using CKA and k-NN to rigorously verify if the feature space has truly diverged from the original model.
2. Top Class-wise forgetting: A novel large-scale scenario where forgetting targets are semantically similar to downstream tasks, preventing the model from relying on residual knowledge.
Huge thanks to my co-authors Yongwoo Kim and Donghyun Kim.
Full paper available here: sciencedirect.com/science/ar…
Github code: github.com/yongwookim1/UUEF



3
19
1,475
6 Dec 2025
If you are interested in a rigorous reality check for #MachineUnlearning, please stop by our poster at the #NeurIPS2025 Workshop!
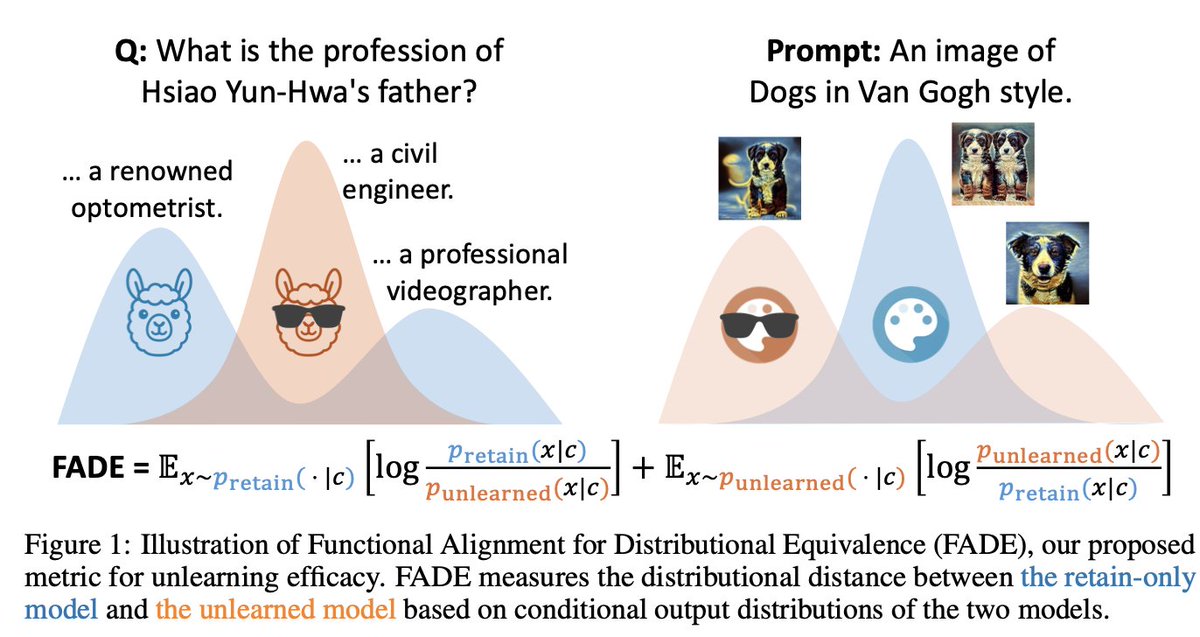
Current unlearning benchmarks often rely on reference-specific metrics, which can hide the truth about a model's retained knowledge.
We propose FADE (Functional Alignment for Distributional Equivalence), a new metric that measures how well an unlearned model aligns with a "retain-only" model that never saw the unwanted data.
- Paper: Reference-Specific Metrics Can Hide the Truth: A Reality Check (arxiv.org/abs/2510.12981)
- Workshop: Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling (Sunday, Dec 7)

2
8
33
3,645

8 Nov 2025
Participated at the India-France AI Policy Roundtable on bilateral AI collaboration and societal impact. Also, got the opportunity to share our machine unlearning work to Ms. Anne Bouverot
#IndiaAI #MachineUnlearning #AIPolicy @PrinSciAdvGoI @iiscbangalore @BangaloreFrance

The Office of @PrinSciAdvGoI, in collaboration with the @iiscbangalore and @BangaloreFrance, organised the Third India–France AI Policy Roundtable on 7th November 2025 at the Council Chamber, IISc Bengaluru. The roundtable is a part of the pre-summit event for the upcoming AI Impact Summit 2026, being hosted by India in February.
The session was co-chaired by Ms. Anne Bouverot, Special Envoy of the President of the French Republic for AI, and Mr. @amit_a_shukla, Joint Secretary, Cyber Diplomacy Division, @MEAIndia.
This Track 1.5 dialogue continues the series of roundtables initiated during the Technology Dialogue 2025, at IISc Bengaluru, as a side event to the earlier AI Action Summit held in Paris on 10th Feb 2025, and reinforces the sustained collaboration between the two nations on AI policy and innovation.
The roundtable discussions will contribute valuable insights for the upcoming AI Impact Summit 2026 as well as the India–France Year of Innovation 2026.
Read the PIB Press Release at: pib.gov.in/PressReleasePage.…
@PMOIndia @FranceinIndia @OfficialINDIAai @_DigitalIndia @PreetiBanzal @kavitabha @emilien @SabharwalAnkush @Ashhereon @jyotij0shi @MayankVatsa3 @danish037 @animesh07731362




1
2
203

24 Oct 2025

8
852

16 Oct 2025
machineunlearning diye site açıp shopierden zurna dürüm parasına eğitim satma işi 🤪🤪🤪
2
201
16 Oct 2025
How can we be sure a generative model (LLMs, Diffusion) has truly unlearned something? What if existing evaluation metrics are misleading us?
In our new paper, we introduce FADE, a new metric that assesses genuine unlearning by measuring distributional alignment, moving beyond today's flawed, reference-specific evaluations in both LLM and diffusion unlearning.
Based on the new metric, our paper reveals that, across both LLMs and text-to-image diffusion models, current unlearning methods only succeed on paper but fail in practice. We show they become more functionally distant from a truly "unlearned" model, even while scoring high on popular benchmarks.
This work was a collaboration with an amazing group of researchers (Sungjun Cho, Dasol Hwang, @fredsala, @beopst, and @kchonyc )😊. Thank you all!
#MachineUnlearning #LLM #DiffusionModels



1
10
39
5,036

21 Aug 2025
🎉 Proud to share that Side Effects of Erasing Concepts from Diffusion Models was accepted to EMNLP 2025 (Findings).
#EMNLP2025 #MachineUnlearning #ConceptErasure
21 Aug 2025

🚨 Our paper “Side Effects of Erasing Concepts from Diffusion Models” has been accepted to EMNLP 2025 (Findings)! #EMNLP2025
We investigate the vulnerabilities of Concept Erasure Techniques (CETs)
Big shoutout to my amazing collaborators @sourajitCS @manasgaur90 @trgokhale
1/n
1
184

23 Jul 2025
महत्त्वपूर्ण शब्दावली:
मशीन अनलर्निंग (Machine Unlearning)
sanskritiias.com/hindi/impor…
#MachineUnlearning #importantterminology #importantwords #prelims #importantconcepts #India #upsc #prelimssexam #pcs #sanskritiias

5
92
18 Jul 2025
When a company claims that your personal data has been removed from their model, have you ever wondered whether they've indeed done so? 🤔
If a new paper on arXiv claims that its proposed #MachineUnlearning algorithm can unlearn your personal data from an #LLM, how do we know if it can indeed do so?
🛢️WaterDrum is the first data-centric LLM unlearning metric based on watermarking that is calibrated, requires no retraining, works for blackbox models and when forget/retain sets have similar data.
Find out more about Waterdrum from @greglau at our poster today (18 July) in the #ICML2025 Machine Unlearning for #GenerativeAI (MUGen @icmlconf) workshop during 3-3.45pm in West Meeting Room 202-204!
Joint work with @lululu0082 xinyuan @greglau nhung @RachaelSim2 fanyu chuansheng seekiong.
1
4
338
11 Jul 2025
GLOW.AI (comp.nus.edu.sg/~lowkh/) will be @icmlconf #ICML2025: @ray_qiaorui @JingtanW @greglau @_Hu_Wenyang @ruthchewing!
More details on each work later.
Interested to apply for a faculty position or Ph.D. in AI at @NUSComputing , ping me on Whova to meet up.
See you soon!
#DataSelection #DataCentricAI #LLMs #LLM #FederatedLearning #BayesianOptimization #MachineUnlearning #RLHF #SymbolicRegression

5
3
19
1,090