
May 16
OpenBMB 开源 MiniCPM-V 4.6 了,1.3B 参数(SigLIP2-400M Qwen3.5-0.8B),262k 上下文,视觉编码 FLOPs 比上一代少 50% 。
同任务 token 成本比 Qwen3.5-0.8B 低 19 倍,开 thinking 模式 43 倍。
OpenCompass / OCRBench / HallusionBench / MUIRBench 全打到 Qwen3.5-2B 那档。OCRBench 876,MMMU-Pro 38%。
iPhone 17 Pro Max、红米 K70、华为 nova 14 边缘适配代码全开源,都有真机录屏。
vLLM / SGLang / llama.cpp / Ollama / transformers 推理全部支持。
huggingface.co/openbmb/MiniC…

🚀MiniCPM-V 4.6 hits #1 on @huggingface Trending! 🏆
Huge thanks to the community for the incredible support!😘😘
🔗👇Try it:
🤗 Hugging Face: huggingface.co/openbmb/MiniC…
💻 GitHub: github.com/OpenBMB/MiniCPM-V Modelscope:modelscope.cn/models/OpenBMB…
Web Demo: huggingface.co/spaces/openbm…
App Demo: github.com/OpenBMB/MiniCPM-V…
What makes MiniCPM-V 4.6 stand out?
⚡ Ultimate On-Device Efficiency
Beats Gemma4-E2B-it and Qwen3.5-0.8B across key multimodal and Artificial Analysis benchmarks — scoring higher than Qwen3.5-0.8B using just 2.5% of its token budget.
👁️ Pro-Level Multimodal Intelligence
Exceptional fine-grained OCR, complex image reasoning, and multi-turn interaction in a highly compact footprint.
🛠️Built for developers
Fully open-sourced with out-of-the-box support for SGLang/vLLM/llama.cpp/Ollama, multi-platform mobile deployment, and low-barrier fine-tuning on consumer GPUs.

2
4
43
6,432

May 10
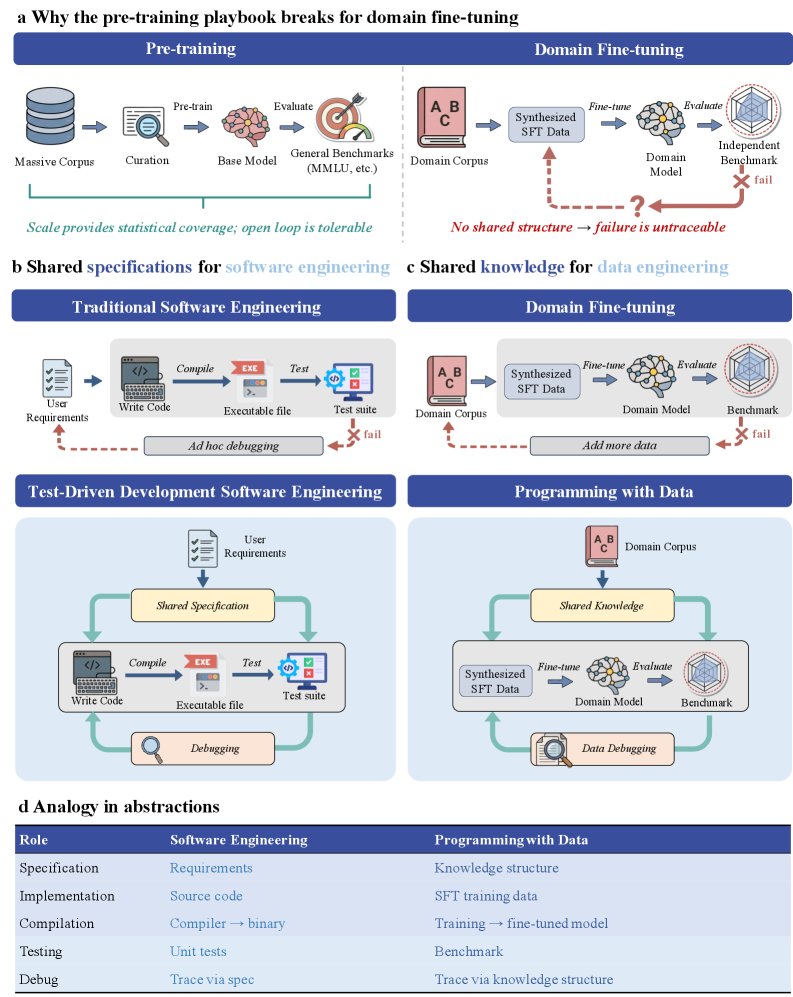
「LLMの専門知識ファインチューニングにバグ修正サイクルを持ち込む」手法「ProDa(Programming with Data)」が発表された(https://arxiv[.]org/html/2604.24819v1)。コードはGitHub(https://github[.]com/OpenRaiser/ProDa)、データセットはHugging Face(https://huggingface[.]co/datasets/OpenRaiser/ProDalib)で公開済み。
従来のドメイン特化ファインチューニングには致命的な弱点があった。モデルが間違えても「どのデータが原因か」を特定できない。失敗したらとにかくデータを増やすしかない、まるでテストなしで書き続けるコードと同じ状態だった。
ProDaはテスト駆動開発(TDD)のアナロジーでこれを解く。コーパス(教科書など)から「3層の知識構造」を抽出し、学習データとベンチマークの両方でこの構造を共有することで、テスト失敗をピンポイントでデータ不足に追跡できるようにする。
3層の内訳はこうなっている。L1(原子概念)は専門用語と定義。L2(概念間の関係)は「AはBを引き起こす」「CはDの前提条件」といった有向ペア。L3(推論チェーン)はL1とL2を平均9ステップつないだ多段推論の経路だ。
実装上の重要な設計がある。通常のボトムアップ(L1→L2→L3)ではなく、トップダウン(L3→L2→L1)で抽出する。こうすることで「全てのL1概念が必ずL3推論チェーンから到達可能」という到達可能性が保証され、孤立ノード(テストも修正もできない概念)をゼロにできる。全458,622ノードで孤立ノード率は正確に0だった。
ベンチマークの選択肢生成も巧みだ。3種の摂動演算子で「紛らわしい誤り」を自動生成する。SubstAdjはL1概念を意味的に隣接する別の概念に差し替え、InvRelはL2の関係を意味上の逆(「促進」なら「抑制」など)に反転、Truncはなら推論チェーンを途中で打ち切る。単純な「ありえない選択肢」ではなく、知識を正確に持っていないと引っかかる罠を作っている。
学習はLoRA(LoRAのrank=16が3B〜14Bモデル、32Bのみrank=32)。LLaMA-Factoryでbf16混合精度、1エポック、バッチサイズ1024。評価はOpenCompassのゼロショット設定、greedy decoding、完全一致のみで採点。部分正解なし。
モデルが間違えると2種類に自動診断する。「概念ギャップ(L1/L2の知識そのものが入っていない)」なら隣接概念との対比データを注入、「推論欠陥(知識はあるが組み合わせ方がわからない)」ならChain-of-Thoughtで中間ステップを明示したデータを追加する。
16分野(物理・医学・法律・経済など)で検証。1回デバッグ後にQwen-3-32B-V2が79.52%を達成し、GPT-5.4(76.82%)、DeepSeek-v3[.]2(76.69%)、Gemini-3-flash(76.60%)を全て上回った。
データ効率が特筆に値する。1,000件の的を絞った修正データで68.72%を記録。Alpacaが2,000件で出した最高68.12%を半分のデータ量で超える。5,000件スケールではProDa V2が72.11%に対し、最強ベースラインのDataFlow Filterが56.18%で約16ポイントの差。
汎用能力もMMLUでBase→V2の中央値が 0.27ポイント改善。壊滅的忘却(catastrophic forgetting)を起こさずに専門性だけを強化できている。
2
8
718

Recent recipients across the last 300 sends were working on:
amruthpillai/reactive-resume
athasdev/athas
denoland/deno
devilsen/czxing
dimillian/codexmonitor
directus/directus
discordjs/discord.js
discourse/discourse
dohooo/react-native-reanimated-carousel
dreamhunter2333/cloudflare_temp_email
easegress-io/easegress
eggjs/egg
eigent-ai/eigent
electron/electron
element-plus/element-plus
excalidraw/excalidraw
expo/expo
facebook/react
farion1231/cc-switch
ffmpeg/ffmpeg
flutter/flutter
freecodecamp/freecodecamp
giskard-ai/giskard-oss
go-kratos/kratos
goharbor/harbor
goplus/xgo
growthbook/growthbook
grpc/grpc
hellodigua/chatlab
hesamsheikh/awesome-openclaw-usecases
hiyouga/llama-factory
huggingface/transformers
huggingface/transformers.js
idea-research/grounded-segment-anything
iflytek/astron-agent
iii-hq/iii
iofficeai/aionui
j178/prek
jd-opensource/xllm
juicedata/juicefs
jwasham/coding-interview-university
kellerjordan/modded-nanogpt
keploy/keploy
kubeflow/pipelines
kubernetes-sigs/kubebuilder
kubernetes-sigs/kustomize
kvcache-ai/mooncake
ladybirdbrowser/ladybird
langgenius/dify
lbjlaq/antigravity-manager
lebab/lebab
lencx/noi
licoy/wordpress-theme-puock
llvm/llvm-project
lucasgelfond/zerobrew
lynx-family/lynx
m1heng/clawdbot-feishu
mai-with-u/maibot
makeplane/plane
mariadb/server
meta-pytorch/torchtune
metabase/metabase
mhsanaei/3x-ui
moeru-ai/airi
moodle/moodle
mosn/mosn
msitarzewski/agency-agents
musistudio/claude-code-router
mxsm/rocketmq-rust
myriad-dreamin/tinymist
nekoparapa/ainiee
neovim/neovim
nervjs/taro
ng-zorro/ng-zorro-antd
nodejs/node
nofxaios/nofx
nonebot/nonebot2
nousresearch/hermes-agent
nrwl/nx
oceanbase/oceanbase
ollama/ollama
open-compass/opencompass
open-telemetry/opentelemetry-rust
openbmb/ultrarag
openclaw/openclaw
opencv/opencv
openmined/pysyft
opensumi/core
owncast/owncast
oxc-project/oxc
paddlepaddle/paddle
pingcap/tidb
python-attrs/attrs
python/cpython
qemu/qemu
qier222/yesplaymusic
quantumnous/new-api
qwenlm/qwen-code
raycast/extensions
react-native-elements/react-native-elements
requestly/requestly
rescript-lang/rescript
ricequant/rqalpha
ripple-ts/ripple
risingwavelabs/risingwave
router-for-me/cliproxyapi
rsyslog/rsyslog
ruby/ruby
rudrankriyam/app-store-connect-cli
rust-lang/rust
rust-lang/rust-analyzer
rustfs/rustfs
scala/scala3
scikit-learn/scikit-learn
seaql/sea-orm
sgl-project/sglang
sqlitebrowser/sqlitebrowser
storybookjs/storybook
supabase-community/postgres-language-server
symfony/ux
tailwindlabs/tailwindcss
TanStack/router
tikv/tikv
toeverything/affine
tw93/pake
unslothai/unsloth
usememos/memos
vitessio/vitess
web-infra-dev/rspack
whitphx/streamlit-webrtc
wilfred/difftastic
wordpress/wordpress-playground
wormhole-foundation/wormhole
xbmc/xbmc
yacy/yacy_search_server
yagop/node-telegram-bot-api
yamadashy/repomix
yeachan-heo/oh-my-codex
yetone/avante.nvim
yiisoft/yii2
ylianst/meshcentral
ynqa/jnv
yogeshojha/rengine
youzan/vant-weapp
yt-dlp/yt-dlp
yusing/godoxy
zammad/zammad
zcshou/gogogo
zed-industries/zed
zeroclaw-labs/zeroclaw
zfile-dev/zfile
zhayujie/chatgpt-on-wechat
zhulinsen/daily_stock_analysis
zigcc/zig-cookbook
ziparchive/ziparchive
zloirock/core-js
zmap/zmap
zulip/zulip
zxilly/go-size-analyzer
5
24
3,697

SenseTime, founded in 2014 at Hong Kong's Chinese University and listed on the Hong Kong Stock Exchange in late 2021, built its reputation by solving a problem that doesn't scale: bespoke computer vision delivery to government and enterprise clients. According to IDC, it held the top CV market share in China for nine consecutive years from 2015 to 2023. That depth became a liability when the industry stopped rewarding depth.
ChatGPT's arrival in late 2022 shifted the competitive axis from algorithm precision to commercialization speed. SenseTime's project-delivery model, where every client required a custom model and dedicated engineering resources, worked against the new logic of standardized APIs and marginal-cost economics. ByteDance's Doubao, Alibaba's Qwen, and DeepSeek (a Beijing-based LLM startup) collectively captured 71.8% of enterprise model API call volume in the second half of 2025. SenseTime's share is a rounding error by comparison.
The financials reflect this. Generative AI revenue grew 51% to ~$5.2 billion yuan (~$520 million) in 2025, now 72.4% of total revenue. But AIDC compute operating costs jumped 163.5% in the same period, pulling gross margin from 42.9% to 41.0%. The reported profit rests almost entirely on asset sales, with over 90% of the ~$274 million in net other gains coming from divesting subsidiaries and financial assets, not from the core business generating cash.
Cumulative losses over seven years exceed 50 billion yuan (~$7.1 billion). Peak market cap hit HK$300 billion; by 2025 it had fallen to HK$81.3 billion, roughly an 80% collapse.
The 1 X strategy, announced by CEO Xu Li in late 2024, restructures around a dual-engine core: generative AI plus computer vision, focused on building an integrated AI cloud platform across compute infrastructure, foundation models, and applications. The "X" units, autonomous driving, home robotics, smart healthcare, smart retail, spin off as independent subsidiaries with their own CEOs, external fundraising, and no continued group subsidies. CV, the original business, posted its first net profit in 2025 after years of losses.
SenseTime has the technical credentials. Its Riri v6.5, a 600-billion-parameter MoE multimodal model, ranks top-three domestically on OpenCompass and SuperCLUE benchmarks across multimodal tasks. The gap is distribution: without a consumer hit or a cloud ecosystem that drives recurring API revenue at scale, benchmark rankings don't convert to market share.
The 1 X bet is that shedding long-cycle, capital-heavy verticals will let the core unit compete on speed rather than customization depth. Whether that's enough depends on whether seven years of project-delivery habits can actually be unlearned.
3
701

Mar 26
The yearly cadence unsaturated-at-launch design is exactly what the field needs. Saturated benchmarks become marketing tools, not measurement tools.
The open-source eval ecosystem is quietly building the same discipline:
→ OpenCompass — unified open-source eval framework for 100 benchmarks
→ LM-Evaluation-Harness — EleutherAI's gold standard for reproducible evals
→ HELM — Stanford's holistic eval benchmark suite, fully open
→ ARC-AGI Prize GitHub repo — community can build on the same infra
We track every open-source AI evaluation framework at ossaihub.com — the trend is clearly toward open, verifiable, reproducible benchmarks.
What's the hardest part of designing a benchmark that stays unsaturated? Is it task diversity or the difficulty distribution?
3
128


Feb 15
This Chinese AI agent changes everything.
And almost nobody is talking about it.
Mini CPMO 4.5 is the first open-source AI that can see, listen, and talk to you in real time.
Not turn-based.
Not clunky.
Actual full-duplex conversation.
Here’s why it’s wild →
• Runs 100% locally on your own computer
• Beats GPT-4o on vision benchmarks (77.6 OpenCompass)
• Handles 1.8M pixel images
• Does OCR like a beast
• Processes video at 10 FPS
• Natural voice with emotion cloning
• Fully customizable open-source
It’s only 9B parameters.
Yet competes with trillion-parameter models.
You can run it via llama.cpp, VLM, or a WebRTC live demo.
Plug in webcam mic → start talking.
No API fees.
No cloud.
No privacy stress.
Save this video, you’ll want this running before everyone else catches on.
Want the SOP? DM me. 💬
2
3
71
This Chinese AI agent changes everything.
And almost nobody is talking about it.
Mini CPMO 4.5 is the first open-source AI that can see, listen, and talk to you in real time.
Not turn-based.
Not clunky.
Actual full-duplex conversation.
Here’s why it’s wild →
• Runs 100% locally on your own computer
• Beats GPT-4o on vision benchmarks (77.6 OpenCompass)
• Handles 1.8M pixel images
• Does OCR like a beast
• Processes video at 10 FPS
• Natural voice with emotion cloning
• Fully customizable open-source
It’s only 9B parameters.
Yet competes with trillion-parameter models.
You can run it via llama.cpp, VLM, or a WebRTC live demo.
Plug in webcam mic → start talking.
No API fees.
No cloud.
No privacy stress.
Save this video, you’ll want this running before everyone else catches on.
Want the SOP? DM me. 💬
2
2
5
873

MiniCPM-o 4.5: Seeing, Listening, and Speaking — All at Once. 👁️👂🗣️
✨Beyond traditional turn-taking, we’ve built a Native Full-Duplex engine that allows a 9B model to see, listen, and speak in one concurrent, non-blocking stream.
Watch how it masters real-world complexity in real-time:
🔔 Proactive Auditory Interaction: Interrupts itself to alert you when it hears a "Ding!" while reading cards.
🎨 Temporal Flow Tracking: Follows your pen in real-time, narrating and "mind-reading" your drawing as you sketch.
🍎 Omni-Perception: Scans groceries & identifies prices on the fly.
✨Why it’s a category-leader:
📌Performance: Surpasses GPT-4o and Gemini 2.0 Pro on OpenCompass (Avg. 77.6).
📌Architecture: End-to-end fusion of SigLip2, Whisper, and CosyVoice2 on a Qwen3-8B base.
📌Efficiency: Full-duplex live streaming now runs locally on PCs via llama.cpp-omni.
The era of "Wait-and-Response" AI is over. Proactive, real-time intelligence is now open-source.
🚀Experience it on Hugging Face: 🔗huggingface.co/openbmb/MiniC…
#MiniCPM #Omnimodal #FullDuplex #EdgeAI #OpenSource #ComputerVision
9
8
71
115,406

Feb 8
💥 MiniCPM-o 4.5 is HERE 🌀
♠ but the launch was ROUGH – broken demos, failed installs & memory issues 😬
🔹9B params doing EVERYTHING: vision speech video in one end-to-end model
🔹Full-duplex streaming: sees, listens & speaks simultaneously
🔹Crushes benchmarks: 77.6 OpenCompass, 87.6 MMBench, beats GPT-4o on OCR
🔹Matches Gemini 2.5 Flash performance but team rushed the release before it was ready
🔥 Watch the full technical breakdown below: 👇
1
1
7
195

Feb 6
The open-source community just got a new powerhouse: @OpenBMB's MiniCPM-o 4.5. This 9B model isn't just competing with the giants, it's winning.
On the OpenCompass benchmark, it achieves an average score of 77.6, surpassing models like GPT-4o and the 72B Qwen2.5-VL.
Let's look under the hood.↓
4
31
36
124,060

Feb 6
So no — this doesn’t feel like a “smaller GPT-4o.”
It feels like a different interaction primitive.
9B parameters, runs locally.
OpenCompass average score: 77.6 — consistent with Hugging Face benchmarks.
But the real shift is structural, not numerical.
MiniCPM-o 4.5 isn’t trying to sound human.
It’s trying to behave like one.
@OpenBMB
huggingface.co/openbmb/MiniC…
2
5,207

Feb 5
02/ MiniCPM-o 4.5核心特性
领先的视觉能力
MiniCPM-o 4.5 在 OpenCompass(覆盖 8 项主流基准的综合评测)中取得 77.6 的平均分。仅以 9B 参数规模,便超越了 GPT-4o、Gemini 2.0 Pro 等广泛使用的闭源模型,并在视觉—语言能力上接近 Gemini 2.5 Flash。该模型在单一模型中同时支持 instruct 与 thinking 两种模式,能够在不同使用场景下更好地平衡效率与性能。
强大的语音能力
MiniCPM-o 4.5 支持中英文双语的实时语音对话,并提供可配置的多种声音。其语音对话更加自然、富有表现力且稳定。模型还支持通过一段简短的参考音频实现语音克隆与角色扮演等趣味功能,克隆效果优于 CosyVoice2 等主流 TTS 工具。
全新的全双工与主动式多模态实时流能力
作为新增特性,MiniCPM-o 4.5 能够在端到端框架下,同时处理实时、连续的视频与音频输入流,并并行生成文本与语音输出流,彼此不阻塞。这使模型能够实现“边看、边听、边说”的流畅实时全模态对话体验。除被动响应外,模型还可基于对实时场景的持续理解进行主动交互,例如主动发起提醒或评论。
强大的 OCR、效率及其他能力
继承并强化 MiniCPM-V 系列的视觉能力,MiniCPM-o 4.5 可高效处理高分辨率图像(最高 180 万像素)与高帧率视频(最高 10fps),且不受画幅比例限制。在 OmniDocBench 的端到端英文文档解析任务中达到当前最优水平,超过 Gemini-3 Flash、GPT-5 等闭源模型以及 DeepSeek-OCR 2 等专用工具。同时在 MMHal-Bench 上展现出与 Gemini 2.5 Flash 相当的可信行为表现,并支持 30 多种语言。
易用性
MiniCPM-o 4.5 提供多种便捷使用方式:
1)支持 llama.cpp 与 Ollama,在本地设备上进行高效 CPU 推理;
2)提供 int4 与 GGUF 量化模型,共 16 种规格;
3)支持 vLLM 与 SGLang,实现高吞吐、低显存占用的推理;
4)支持 FlagOS 的统一多芯片后端插件;
5)可通过 LLaMA-Factory 在新领域与新任务上进行微调;
6)提供在线 Web Demo。
同时还发布了高性能的 llama.cpp-omni 推理框架及 WebRTC Demo,使得在本地设备(如 MacBook)上也能体验全双工多模态实时流能力。
1
2
4,322

MiniCPM-o 4.5 achieves an average score of 77.6 on OpenCompass, a comprehensive evaluation of 8 popular benchmarks.
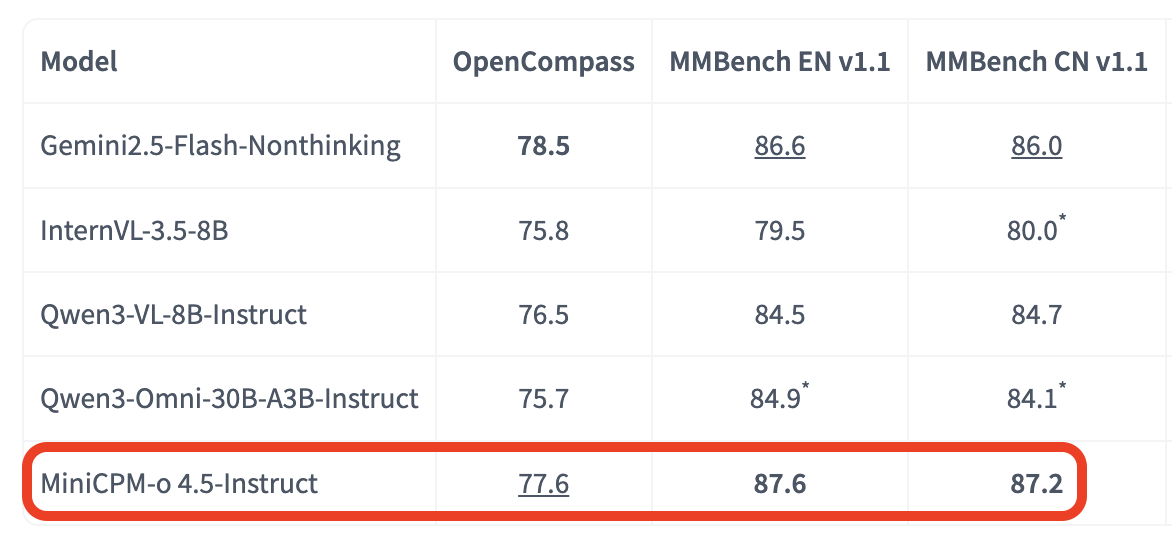
1
6
781

为什么选MiniCPM-o4.5作为多模态引擎?
第一是性能考量。这个只有9B参数的模型在OpenCompass综合评测中拿到77.6分,超越GPT-4o。真正的全模态——视觉理解、文档解析、语音对话,OCRBench达到876分,端到端英文文档解析超过GPT-5和DeepSeek-OCR2。这意味着它不仅能听懂语音指令,还能精准识别分享的图表、代码截图、手写笔记中的文字和结构,甚至能解析复杂的技术文档。
第二是全双工。大多数多模态模型是伪实时,本质上还是轮流说话。MiniCPM-o4.5可以同时处理连续的视频流和音频流输入,同时生成文本和语音输出流,且端到端无阻塞。这意味着它能在用户说话时就开始理解和反应,不用等说完也能主动打断或评论。一个很典型的场景——在Discord语音频道里和Agent激烈辩论,它能像真人一样随时插话“等等,你这个逻辑有问题”。
第三是部署灵活。支持llama.cpp、vLLM多种推理框架,提供16种量化版本,最低int4量化只需11GB显存就能跑满功能。同时开源了llama.cpp-omni框架和WebRTC Demo,用大白话说,从云端到边缘设备都能部署,对比GPT-4o Realtime需要云端API调用且成本高昂($0.06/分钟输入 $0.24/分钟输出),MiniCPM-o4.5可以完全本地运行,除了设备外成本为零。
对于OpenClaw这种需要实时交互、且用量频繁的场景,这三点缺一不可。
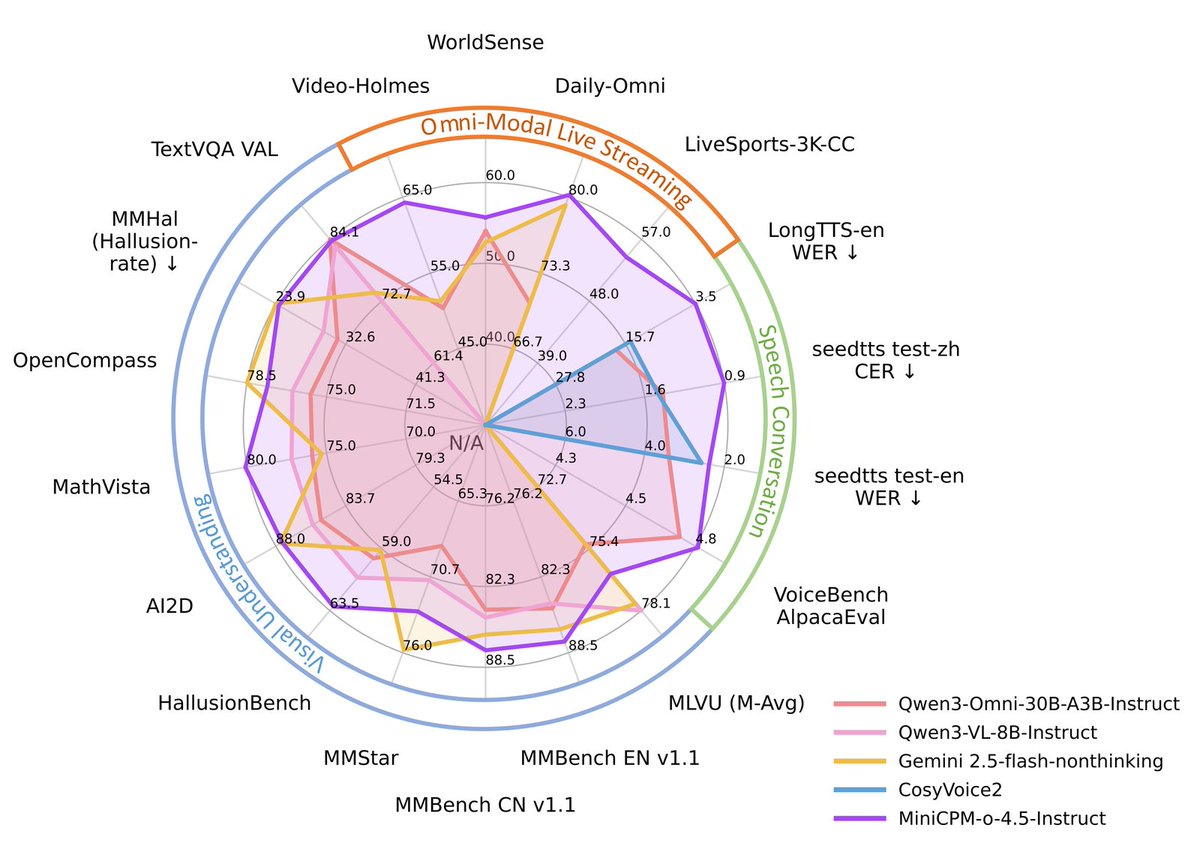
4
1
8
2,051

Feb 4
The numbers back up the experience.
According to the latest benchmarks, @OpenBMB's MiniCPM-o 4.5 achieves an average OpenCompass score of 77.6.
This 9B, full-duplex local model is setting a new standard for real-time, interruptible AI.
3
2,638

Feb 4
Meet MiniCPM-o 4.5, the new 9B multimodal model from OpenBMB, bringing "GPT-4o" intelligence right to your local machine.
Most models are "half-duplex," meaning they can't listen while talking. In contrast, MiniCPM-o 4.5 employs a full-duplex architecture for truly human-like interaction.
MiniCPM-o 4.5 achieves an average score of 77.6 on OpenCompass @OpenBMB
Why It’s a Game Changer:
- Full-Duplex I/O: It perceives and speaks simultaneously, eliminating communication blocks.
- Natural Interaction: Fully interruptible, it decides autonomously when to respond, without needing external VAD tools.
- Proactive Vision: Capable of 3–10 fps video streaming, it reacts to real-time events (e.g., "Tell me when the water starts boiling").
- Expressive Voice: Features a high-quality speech module with voice cloning during inference.
- Local Power: Operates on an RTX 4090 (Python) or through llamacpp-omni (C ), enabling high-efficiency edge deployment.
Do you want to build your first app using MiniCPM-04.5 🧵 👇
2
6
26
40,973

Feb 4
MiniCPM-o 4.5 brings true "Omni" capabilities (Vision Audio Text) into a single 9B end-to-end architecture (Qwen3-8B SigLip2 Whisper CosyVoice2).🚀
modelscope.cn/collections/Op…
✅ Vision SOTA: OpenCompass score of 77.6—surpassing GPT-4o and Gemini 2.0 Pro in VLM tasks with just 9B params.
✅ Real-time Full Duplex: It "sees," "hears," and "speaks" simultaneously. Supports active interaction (it can interrupt or initiate conversation based on live video).
✅ World-Class OCR: Beats DeepSeek-OCR 2 and GPT-4o in document parsing (OmniDocBench leader).
✅ Voice Cloning: Clone any voice with just a short reference clip—integrated directly into the multimodal flow.
✅Quantization: 16 types of Int4 and GGUF formats available.
📢Excited to announce that MiniCPM-o 4.5 is now live on @ModelScope2022 !
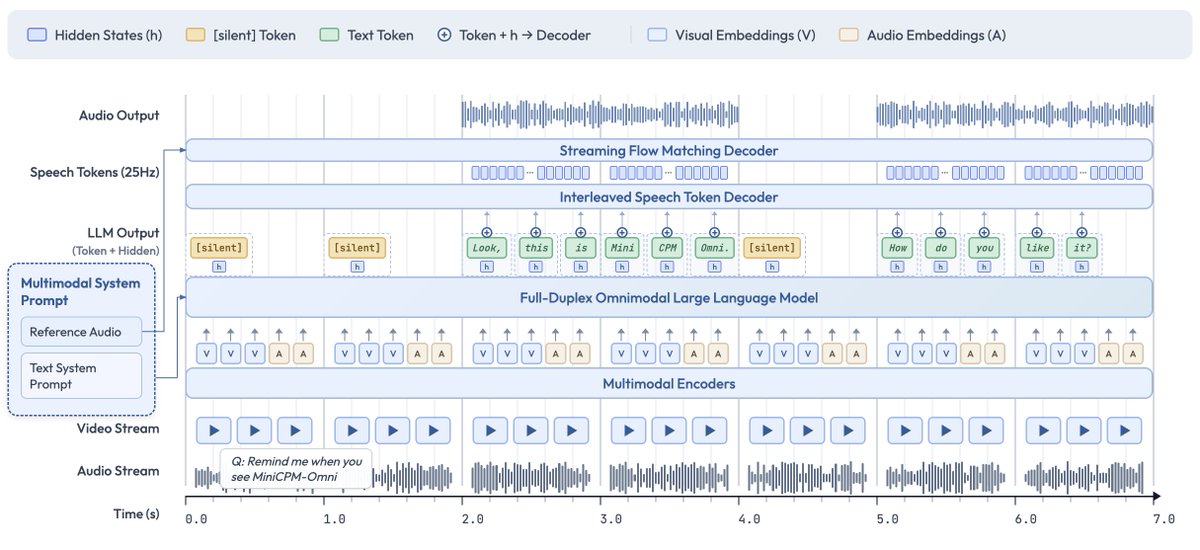
How does a 9B model achieve "full-circle" SOTA performance? The secret lies in its End-to-End Full-Duplex Architecture.
📍Omnimodal Flow: Processes continuous video and audio input streams simultaneously without mutual blocking.
📍Proactive Interaction: Beyond just replying, the architecture allows the model to initiate comments based on live scene understanding.
📍Leading Efficiency: Scores 77.6 on OpenCompass, outperforming much larger models in vision-language tasks.
👇 Experience the full-duplex demo on ModelScope: modelscope.cn/models/OpenBMB…
#MiniCPMo45 #ModelScope #OpenSource #MLLM #EdgeAI
1
10
54
4,565
📢Excited to announce that MiniCPM-o 4.5 is now live on @ModelScope2022 !
How does a 9B model achieve "full-circle" SOTA performance? The secret lies in its End-to-End Full-Duplex Architecture.
📍Omnimodal Flow: Processes continuous video and audio input streams simultaneously without mutual blocking.
📍Proactive Interaction: Beyond just replying, the architecture allows the model to initiate comments based on live scene understanding.
📍Leading Efficiency: Scores 77.6 on OpenCompass, outperforming much larger models in vision-language tasks.
👇 Experience the full-duplex demo on ModelScope: modelscope.cn/models/OpenBMB…
#MiniCPMo45 #ModelScope #OpenSource #MLLM #EdgeAI
2
11
85
8,401