
A new kind of language for a new kind of computer. Created by @irl_danB
Joined January 2026
- Tweets 13
- Following 5
- Followers 51
- Likes 24
1 Photos and videos

OpenProse (YC P26) retweeted

Jun 8
OpenProse – an open-source "logical English" language that turns your agentic workflows into reusable agent programs.
It runs inside the coding agent you already use: Claude Code, Codex, OpenCode, Hermes, Pi – and gives it a structured contract to follow.
→ The key idea – the coding agent becomes the "compiler".
This delivers:
- Less babysitting of multi-agent coding sessions
- Reviewable .prose.md programs instead of disposable prompts
- Explicit skill and tool dependencies
- Isolated sub-agent sessions with clean outputs
- Run receipts, logs, artifacts, and audit trails
- Reuse of sessions on demand
So OpenProse extracts the entire workflow: phases, contracts, decision gates, loops, parallel work, mistakes, fixes, and validation evidence. It's like a “git for agent workflows”.
9
18
84
10,274

this is interesting
in at least one anecdotal setting I've seen, our Reactor Harness uses 150x fewer tokens than the raw Claude Code equivalent for the task of keeping a model of my local agent usage up to date
this 150x improvement is not on a "per request" basis. instead, it's the token cost of keeping this model up to date based on rapid upstream state changes
this is the result of the memoization pattern that we use: you're caching the facets of the world-model that you need and saving yourself from having to do inference at all to refresh a lot of the downstream state that otherwise doesn't need any intelligent agents running over it
I hadn't considered our TAM in this light
Jun 6

Curiously enough I did office hours today with a startup that cuts companies' LLM token costs by optimizing requests. They can cut costs by about half, which they split with the customer. So the TAM is a quarter of the model companies' corporate revenue. That's a big TAM!
6
5
65
8,869
everyone is building an agent or a tool
you don't want an agent or a tool, you want a reactor
I've been working on something cool and I think you'll like it
it's simple: an agent session DAG that keeps a declared world-model up to date in an efficient (memoized) render
each render node is an agent session: you declare the desired state with OpenProse markdown files
once invoked, each agent session acts as the provider. the agent session uses the open source openai-agents-sdk, extensible however you like with any model (I use with opus, sonnet, haiku)
the facets of the world-state are memoized, so not every agent has to run on every event, saving you on inference
if that sounds a lot like React or dataflow, that's because even in our brave new world the wisdom of the agents holds fast
23
18
193
9,544
I was talking with an old friend at dinner last night, he described gpt fatigue
I'd examined the whole psychosis thing, but fatigue is different, and this one rings with me. I've been through cycles of this; I'm probably just emerging from my third epoch of gpt fatigue right now
it's very bittersweet. the cognitive overhead of context switching across the slop troughs is not as fun as the in-the-zone coding rhythm I enjoyed for the first twelve years of my career
I drew the connection to the Reactor Harness I'd been working on and he lit up (yes, this is a launch post, read on). I told him the basic idea:
In the same way that React (js) keeps the DOM up to date by rendering declared components efficiently based on upstream events...
the Reactor Harness keeps an ideal world-model up to date by rendering declared facets of the world-model efficiently based on upstream events.
This world-model can be anything--formally it's a faceted content addressable blob. In practice, it can be a file, a directory, a sqlite table, etc.
If you've followed OpenProse since the beginning, you'll guess that the render function is not deterministic byte code, but instead is declarative markdown instructions fulfilled by an agent session.
I'm releasing the harness here in beta today. It ships as an SDK so you can plug it into your own projects. We've built an experimental CLI w/ a lightweight server and a devtools package alongside it. Please give it a boost with a Github Star here, then return to read more:
github.com/openprose/prose
The Reactor Harness is built to run OpenProse, and its design was uniquely informed by the tenets behind OpenProse, such that you can declare your ideal world-model using familiar structured markdown, and you can optionally write imperative fulfillment plans in our original ProseScript.
One way of thinking about the Reactor is as a DAG of agent sessions. Every node in the DAG is an agent session tasked with keeping facets of the world model up to date. These are memoized, such that downstream dependent sessions only get re-run when their upstream counterparts change.
Over the coming days, I'll be writing more about the harness, how we've been using it, and where I hope we can take this. We are in the process of running benchmarks on it. The goal is that the SDK API itself remains relatively stable while we improve the agent session fulfillment cost, speed, and intelligence under the hood.
How did we get here?
Today I keep a large share of our company's operations in a directory: tenets, specs, code, analytics, our burn model, our sales lead enrichment CRM.
And I find myself having to manually "fast-forward" these models, dropping into context to proactively tell Claude Code to update a spec, add someone to the CRM, or update the financial model based on real-world events that have changed our plans.
I'd written many OpenProse scripts to accomplish these things, but I found I wanted this all to run reactively, as an ongoing time-invariant responsibility, rather than proactively as a tool that I continuously return to. Our first attempt at solving this was putting our OpenProse programs on a cron. The problem with that was that it became very expensive very fast.
As I started trying to design the OpenProse to work under these constraints, I found myself introducing concepts like memoization to different facets of the maintained state. From there, I decided not reinvent the wheel and to graft the patterns from React more explicitly. It's an analogy, and the analogy breaks down in some places. But it's a reasonable starting point that a lot of people are familiar with.
We built the first version in April internally on our hosted service for one of our customers' needs, but I decided that the core of this is interesting enough that it deserves to be in the public sphere, so we spent the intervening six weeks ripping it out and redesigning it as an SDK so people could plug it into their own stacks.
I can't emphasize enough how there's nothing new here, we're just applying classical engineering paradigms to our brave new world. We're finding that despite our topsy-turvy reality, the wisdom of the ancients holds fast.
The Reactor harness is young, should be used with caution, and has some way to go before it reaches it's ideal form. My ask is that you try it, wire it up to something useful, love it or hate it, and send me honest feedback about your experience. We're always listening and improving.
I have a particularly exciting end goal in mind: because the Reactor DAG is itself a world-model, downstream from events in the real world (say, learned event source/frequency/distribution), you could use Reactor itself to implement dynamic Reactor DAGs. This sets us on the path to a true RLM paradigm. I'm most excited about this because I hypothesize that it will yield a simple, elegant property of the Reactor:
Inference cost for maintaining a world-model scales with surprise, rather than wall-clock time.
It's not there yet, but my expectation is that this is achievable and that it's just a matter of walking up the ladder to get there. In my experience when you make something self-referential too early it can collapse back in on itself, so we're going to step our way there incrementally.
When we do get there, my hope is that the meta Reactor DAG can continuously self-calibrate on event source/frequency/distribution to optimize for efficient fulfillment Reactor DAGs, and where the cost of keeping the world-model up to date approaches only the surprise of upstream events in the real world.
At dinner last night, a recurring topic was this love-hate relationship we'd developed with the models. I've been building harnesses for these burgeoning minds since my GPT-2 finetune in 2020. In many ways I'm having as much fun as I've ever had with technology. And yet I've come to loathe their impacts in many other regards.
In the end, I guess the real goal is that the Reactor Harness lets me unburden the cognitive load at the root of my gpt fatigue, and frees me up for the more interesting forms of gpt psychosis :D
thanks for reading and following along, star the repo here and give it a try:
github.com/openprose/prose
15
10
128
9,295
I know that selling RL envs to labs is all the rage
you’re selling experiences to models that they can learn from
is anyone selling harnesses to labs for variation in that post-training?
does the ideal model fit a single harness like a glove (and thereby only get used in that harness) or does it know how to slide into many harnesses?
11
3
94
8,707
claude code is still unrivaled as a creative partner when designing complicated new systems
design specs with claude code during the day and then hand them off to codex for implementation overnight

4
1
31
2,657
your OpenProse programs run in interactive mode teehee
once you ask the model to simulate a VM, you can still write programs for it at the prompt layer that do many of the same things you want to do with "programmatic usage": loops, fan outs, intelligent map/reduce, control flows.
what are they going to do, block structured prompts?
github.com/openprose/prose
May 13

Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage.
The credit covers usage of:
- Claude Agent SDK
- claude -p
- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK
1
1
7
681
OpenProse (YC P26) retweeted

May 12
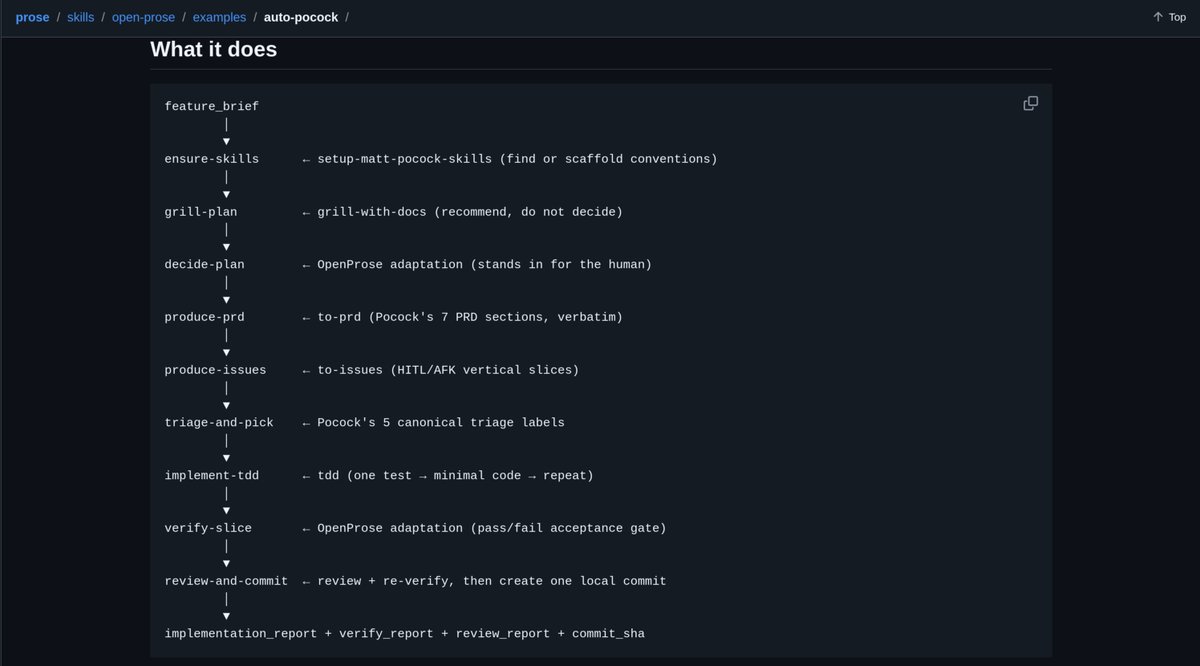
Introducing: "Auto-Pocock"
An @OpenProseVM program that runs a headless sequence of @mattpocockuk 's engineering skills.
You input the feature brief, auto-pocock engineers the rest.
npx skills add openprose/prose
prose run /path/to/openprose-prose/skills/open-prose/examples/auto-pocock/src/auto-pocock.prose.md \
--feature_brief "..."
4
2
23
2,999
I learned @robbwinkle presented OpenProse at an AI tinkerers meetup recently... very cool Robb!
robbwinkle.zo.space/openpros…
2
8
307
I've gotten trapped in a loop of improving OpenProse without posting about it, as if I'm waiting for some perfect launch moment
this is a bad habit that has bitten me in the past
committing today to not doing that, we're shipping too many good things to stay quiet
1
2
39
895
OpenProse lore
the origin of the paradigm that became OpenProse came 10 months before I landed on the present declarative framework:

cursor agent/yolo mode is a new sort of turing complete runtime
you can create arbitrary programs for it in a basic markdown file at the top level of an empty repo
it has the file system for state management
simply say “run executable.md” and it’s off to the races
1
9
1,086
