
Joined January 2025
- Tweets 39
- Following 29
- Followers 291
- Likes 39
20 Photos and videos





Pinned Tweet

Apr 9
(1/6) How do you build a video LLM that decouples vision from language — instead of jamming it all into one context window?
Our team at OpenMOSS open-sources MOSS-VL, a cross-attention multimodal model with strong video understanding results.
Architecture and benchmarks in thread.
6
3
16
1,860
OpenMOSS retweeted

May 8
Open-source video should be easy to run, adapt, and build into products.
That’s what MOVA is designed for.
MOVA-360p has reached 142K total downloads on Hugging Face, with 88,362 downloads in the last month.
Developers get open weights, inference code, training pipelines, LoRA fine-tuning scripts, Apache-2.0 licensing, Diffusers support, and Safetensors.
Now, with DiffSynth Studio support for MOVA-360p and MOVA-720p, teams can use MOVA across both inference and training workflows.
Hugging Face: huggingface.co/OpenMOSS-Team…
GitHub :github.com/OpenMOSS/MOVA
DiffSynth Studio: github.com/modelscope/DiffSy…

3
9
441
Apr 14
Welcome to try MOSS-TTS-Nano!
github.com/OpenMOSS/MOSS-TTS…
huggingface.co/OpenMOSS-Team…
Apr 13

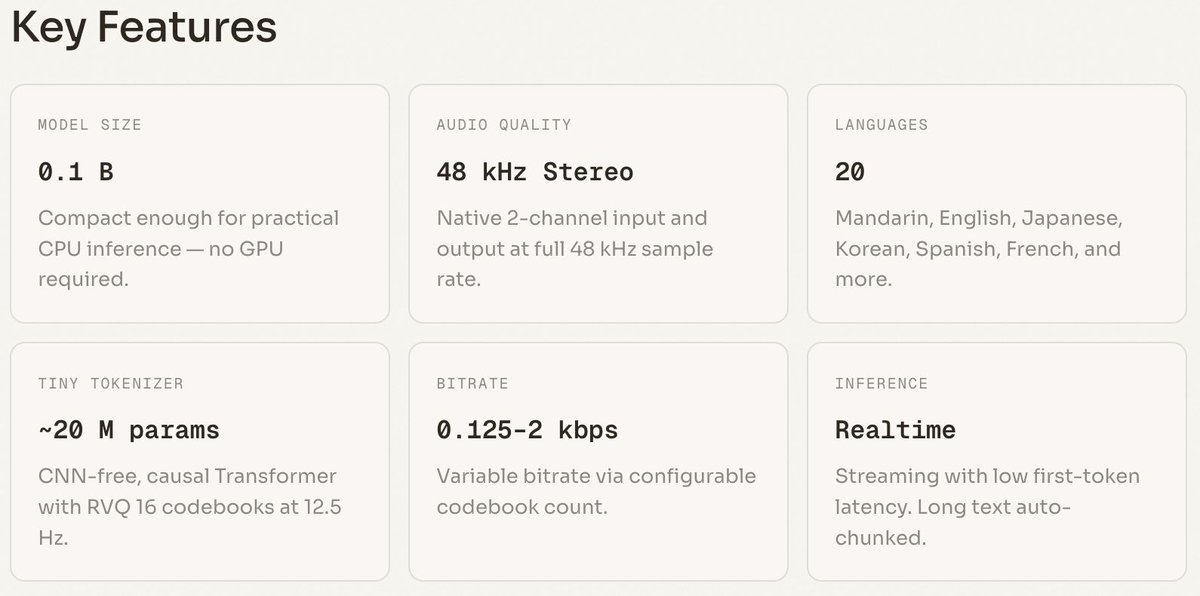
Say hello to MOSS-TTS-Nano 🚀 0.1B multilingual TTS from MOSI.AI and OpenMOSS.
Designed for realtime speech generation without a GPU. Runs directly on CPU, keeping the deployment stack simple enough for local demos, web serving, and lightweight product integration.
Part of the MOSS-TTS family alongside the 1.7B and 8B flagship models.
🤖 modelscope.cn/models/openmos…
🌍 modelscope.ai/models/openmos…
💻 github.com/OpenMOSS/MOSS-TTS…


3
7
625
Apr 9
(1/6) How do you build a video LLM that decouples vision from language — instead of jamming it all into one context window?
Our team at OpenMOSS open-sources MOSS-VL, a cross-attention multimodal model with strong video understanding results.
Architecture and benchmarks in thread.
6
3
16
1,860
Apr 9
(6/6) MOSS-VL is live. Two checkpoints (Base Instruct), Apache 2.0.
🎮 Try it: fnlp-vision.github.io/MOSS-V…
🤗 huggingface.co/fnlp-vision
🐙 github.com/fnlp-vision/MOSS-…
🇨🇳 modelscope.cn/organization/f…
📄 Arxiv: soon
From OpenMOSS. Bookmark for later.
1
237
Apr 9
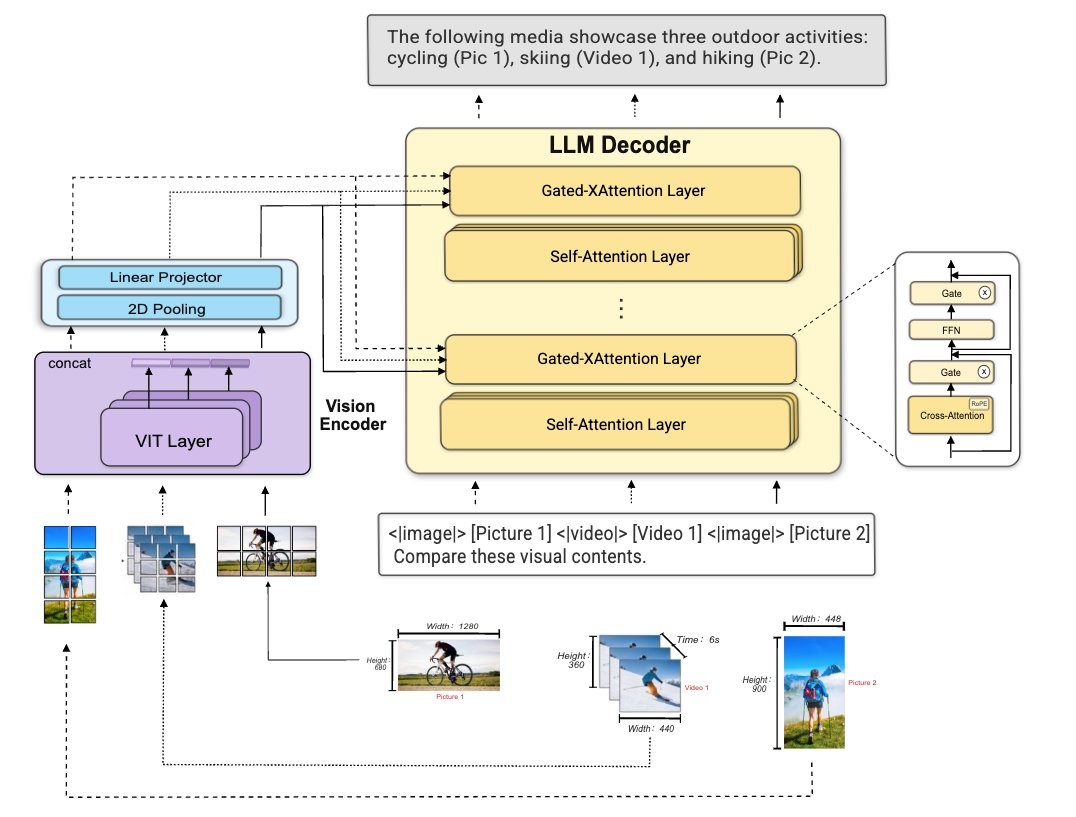
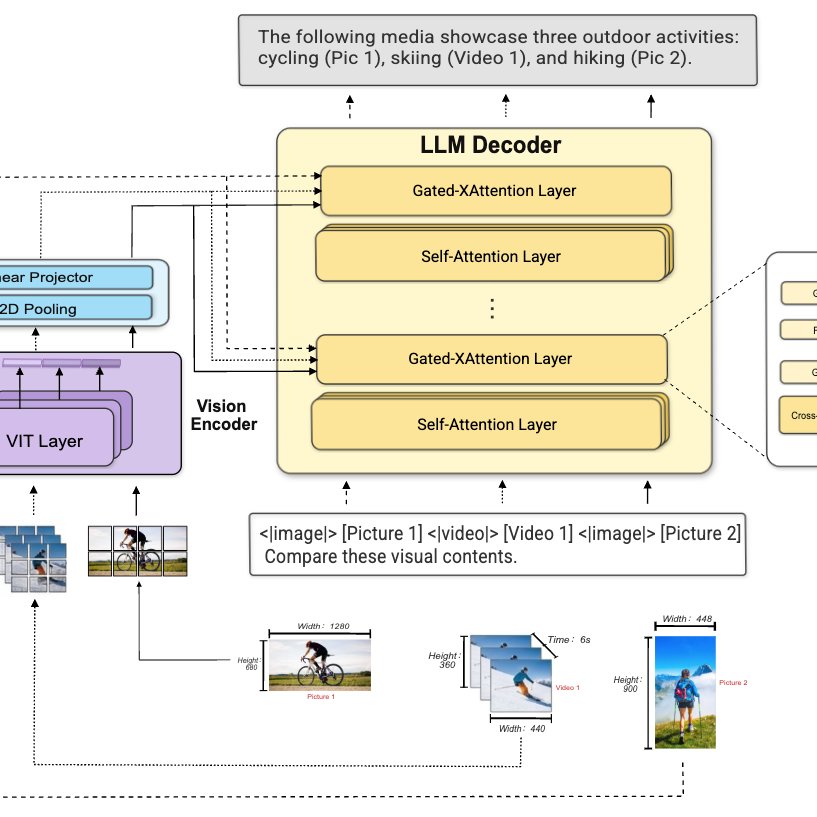
(5/6) We propose XRoPE — Cross-attention RoPE — mapping text tokens and visual patches into a unified 3D space: time (t), height (h), width (w).
1. Injected into vision Key text Query for cross-modal alignment
2. Value left untouched to preserve feature fidelity
194
Apr 9
(4/6) The biggest mistake video LLMs make: they treat frames as a sequence of images, not a sequence in time.
MOSS-VL wraps every frame with special tokens — <|time_start|>1.2 seconds<|time_end|> — anchoring it in absolute time.
Grounded in absolute time, not frame indices.
175
Apr 9
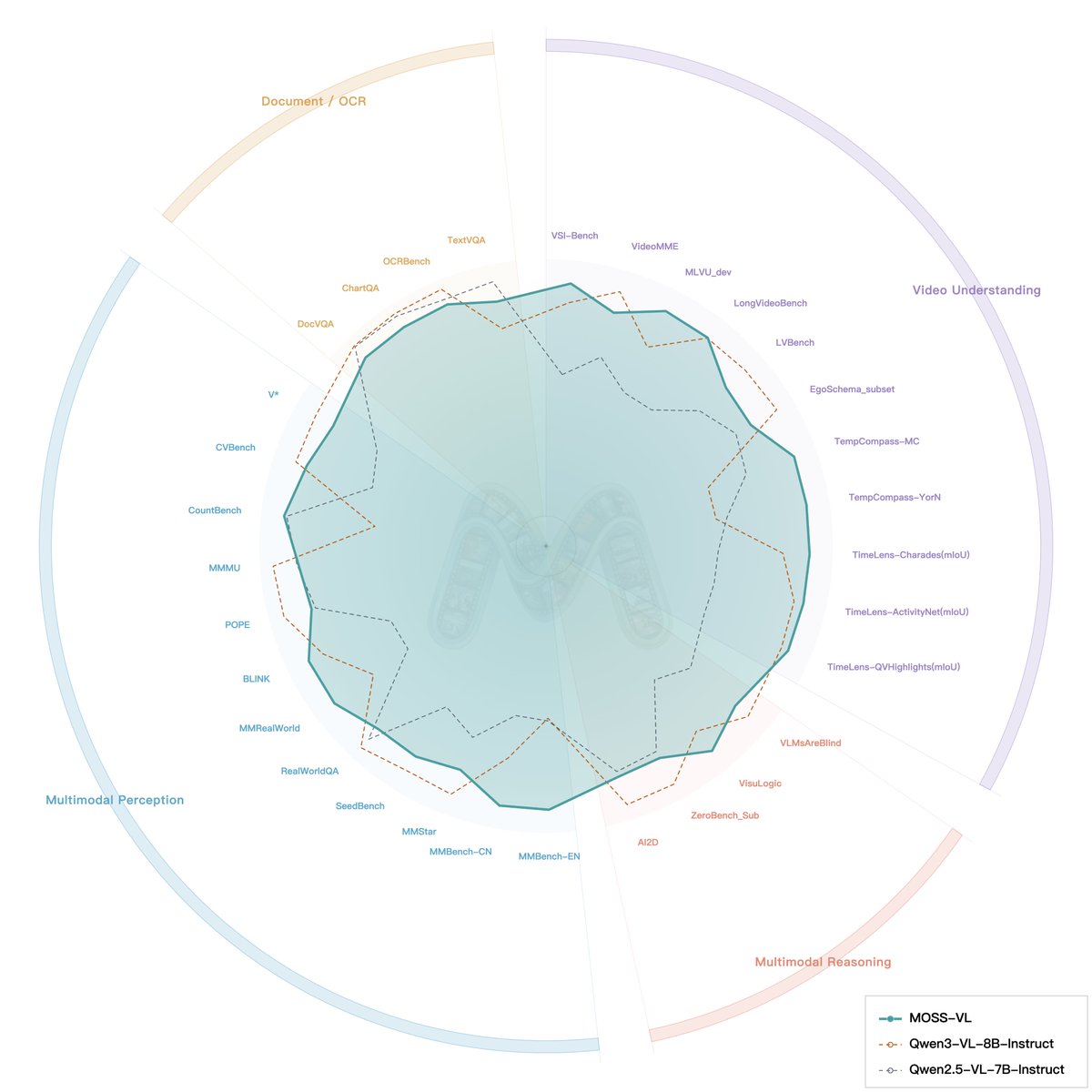
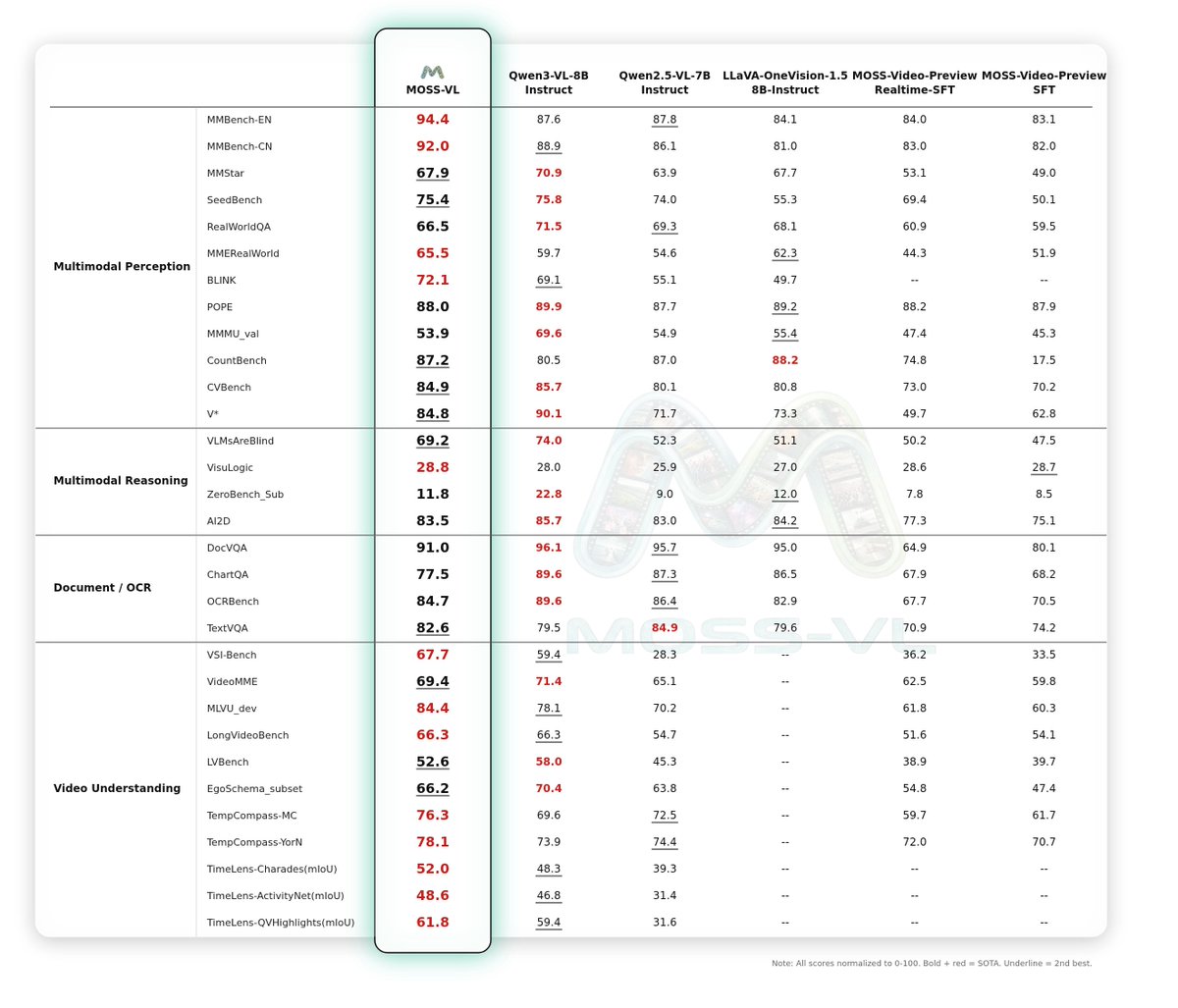
(3/6) We benchmarked MOSS-VL across 30 multimodal tasks vs Qwen2.5-VL and Qwen3-VL:
1. 📹 Video Understanding: 65.8 ( 2 vs Qwen3-VL)
2. 📄 OCR: 83.9
3. 🎯 VSI-bench: 8.3 over Qwen3-VL-8B-Instruct
Consistently first or second across the board.
1
187
Apr 9
(2/6) Hot take: most video LLMs are wired backwards.
They jam visual tokens straight into the LLM context, forcing one model to do both perception and reasoning at once.
But here's the fix: MOSS-VL uses cross-attention to keep the two in separate spaces, talking only when needed.
155
Mar 28
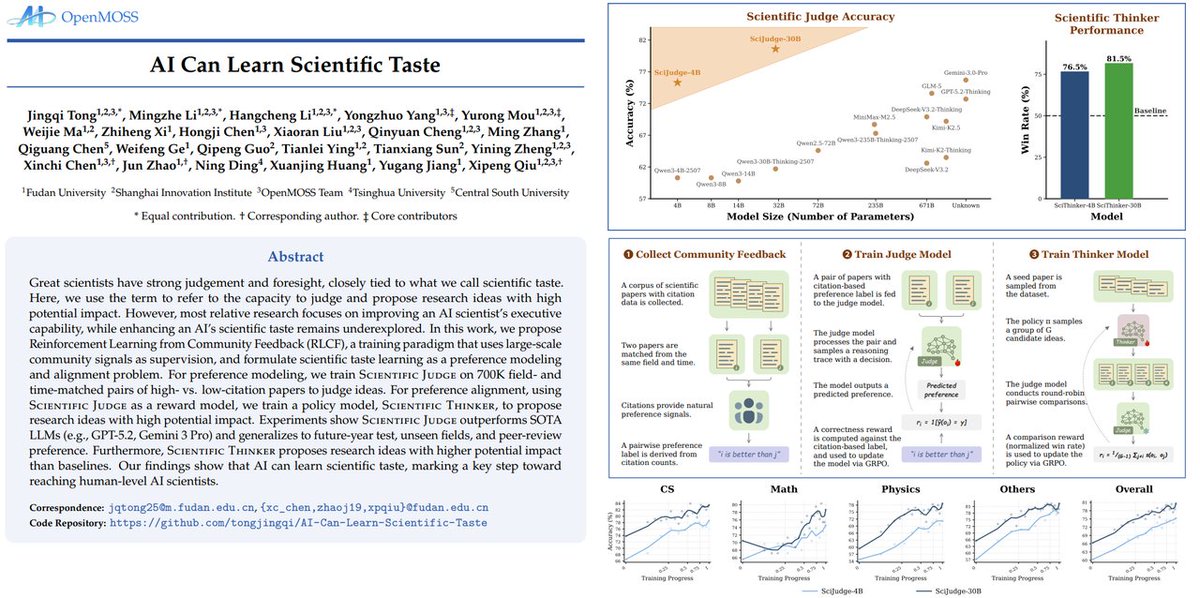
🚨AI can learn scientific taste. 🔬🤖
Great scientists have strong judgement and foresight, closely tied to what we call scientific taste. Here, we use the term to refer to the capacity to judge and propose research ideas with high potential impact.
However, most relative research focuses on improving an AI scientist's executive capability, while enhancing an AI's scientific taste remains underexplored. In this work, we propose Reinforcement Learning from Community Feedback (RLCF), a training paradigm that uses large-scale community signals as supervision, and formulate scientific taste learning as a preference modeling and alignment problem.
For preference modeling, we train Scientific Judge on 700K field- and time-matched pairs of high- vs. low-citation papers to judge ideas.
For preference alignment, using Scientific Judge as a reward model, we train a policy model, Scientific Thinker, to propose research ideas with high potential impact.
Experiments show Scientific Judge outperforms SOTA LLMs (e.g., GPT-5.2, Gemini 3 Pro) and generalizes to future-year test, unseen fields, and peer-review preference. Furthermore, Scientific Thinker proposes research ideas with higher potential impact than baselines. Our findings show that AI can learn scientific taste, marking a key step toward reaching human-level AI scientists.
We are no longer just building AI that automates the execution of science. We are building AI that can automate the direction of science. Scientific taste is no longer a human monopoly. We have open-sourced everything. Come build the future of AI scientists with us!
#AutoResearch #AI #Agent #VibeResearch
1
2
7
223
Mar 28
📄 Paper: arxiv.org/abs/2603.14473
🌐 Project: tongjingqi.github.io/AI-Can-…
💻 GitHub: github.com/tongjingqi/AI-Can…
🤗 HF Models & Data: huggingface.co/collections/O…
1
129

Mar 1
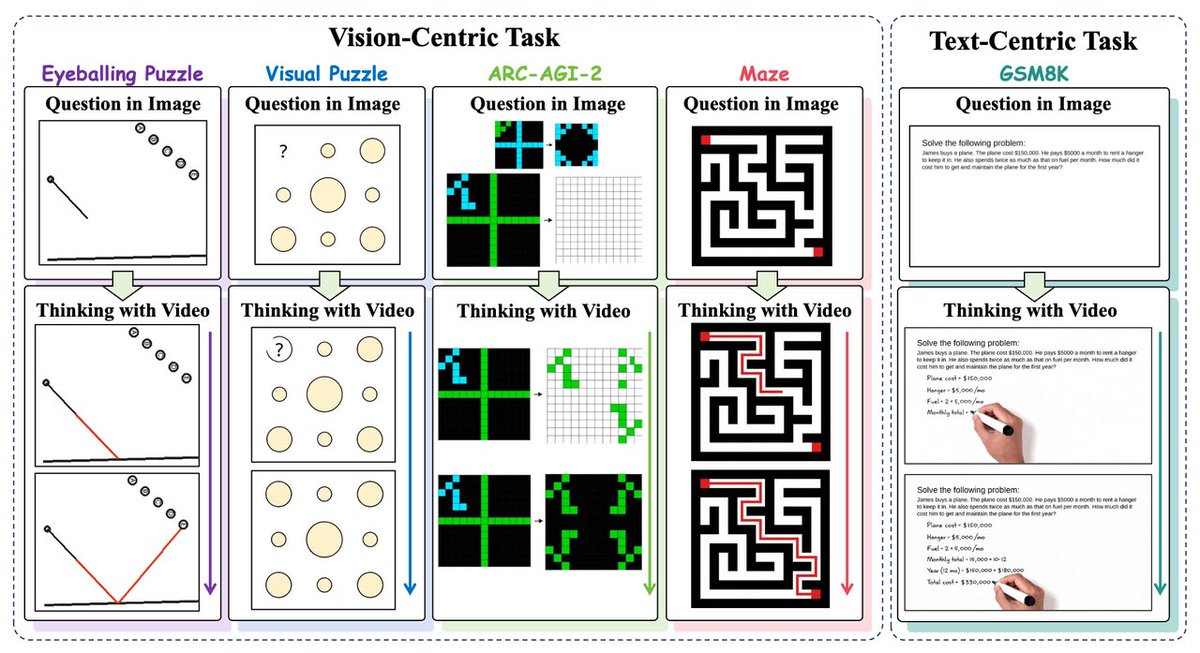
CVPR2026 🎉 Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
🌟We use video frames as a unified medium for text and vision reasoning. 🤯
🔥Video model (Sora-2) beats GPT-5 by 10% on Eyeballing Puzzles!
🧵arxiv.org/abs/2511.04570
(1/6)
#CVPR2026 #seedance2 #Multimodal #VideoGeneration #Sora2 #Reasoning #LLM #AI
5
11
17
1,785
Mar 1
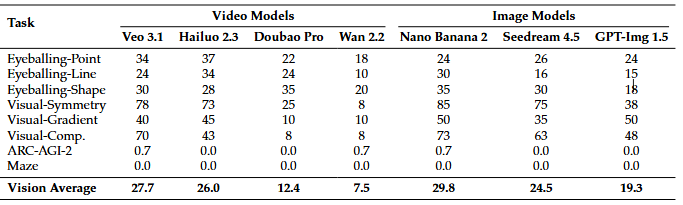
Our bench can also test image edit models! It's a truly unified multimodal generative reasoning benchmark testing video models, image edit models and VLMs.
Results on mini test set:
(6/6)
247
Mar 1
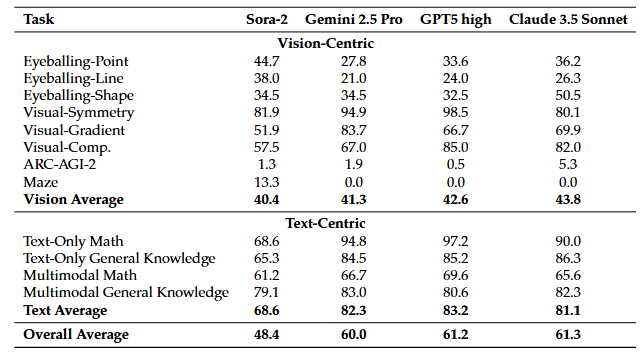
What about text-heavy logic?
Sora-2 takes a prompt image, and generates a video "writing" the step-by-step solution. It even reads the answer via audio! 🔊
Staggering results:
🎯 MATH: 92%
🎯 MMMU: 69.2%
(5/6)
219
Mar 1
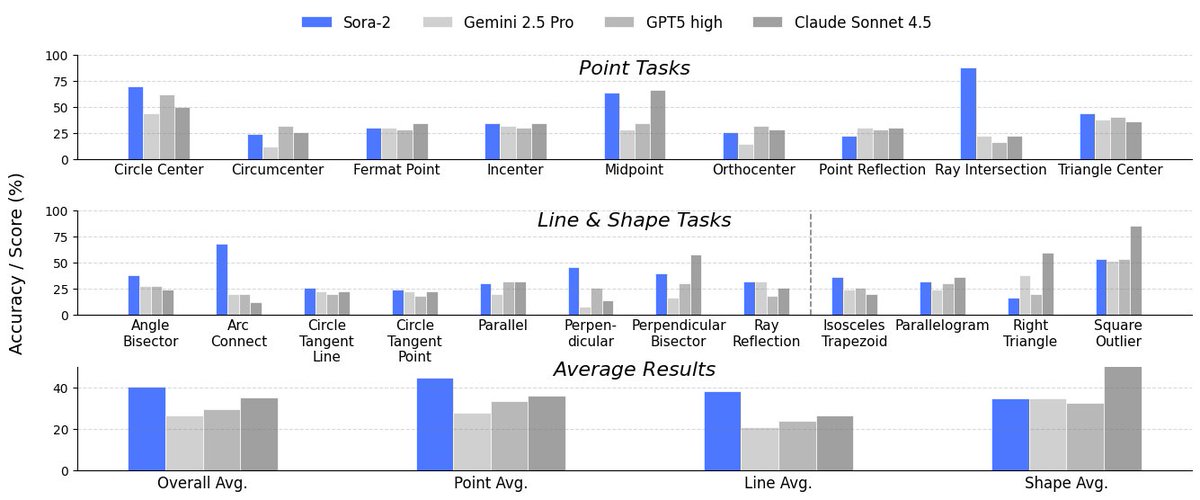
Sora-2 solves complex visual puzzles (color filling, shape drawing) by understanding symmetry, gradients, and composition.
On Visual-Shape tasks, Sora-2's inductive reasoning actually matches Claude 3.5 Sonnet! 🎨🧩
(4/6)
188
Mar 1
We introduce VideoThinkBench to test this.
On "Eyeballing Puzzles", Sora-2 reasons by simulating light reflection and manipulating geometry.
Result? It outperforms SOTA VLMs and scores 10% higher than GPT-5! 📈🧩
All code and data are open-sourced: github.com/tongjingqi/Thinki…
(3/6)
196
Mar 1
Current LLM/VLM paradigms ("Thinking with Text/Images") have limits: static images lack dynamics, and split modalities hinder understanding.
Our fix: Thinking with Video. Video frames as a unified medium to draw/write reasoning steps! ✍️🎥
Project: thinking-with-video.github.i…
(2/6)
204
Feb 18
Happy Chinese New Year 🐎
MOSS-TTSD-v1.0 vs eleven v3 from 11 labs
Which is better?
Welcome Feedback!
github.com/OpenMOSS/MOSS-TTS…
#OpenMOSS #OpenSource #AI #LLM #TTS #Speech
1
1
7
601
Feb 13
We built a Complete Replacement Model (CRM) that fully sparsifies a language model.
This brings many changes to circuit tracing and global circuits.
Congratulations to Zhengfu and his team!!!
Feb 12

We built a Complete Replacement Model (CRM) that fully sparsifies a language model.
This brings many changes to circuit tracing and global circuits. (1/n)

1
6
327