
音频圈这回又炸出一枚开源的狠角色,MOSS-Audio 正式登场。
4B 和 8B 两种尺寸,每个都有 Instruct 和 Thinking 版,任你选。
最硬核的是它把六项能力塞进了一个模型:
1️⃣ 语音识别(ASR)
2️⃣ 说话人分离——谁在说话,分得清清楚楚
3️⃣ 情绪识别——听得懂你是高兴还是烦躁
4️⃣ 环境音解析——雨声、车流、键盘声都能识别
5️⃣ 音乐理解——不只是识别歌名,是真的听懂结构
6️⃣ 带时间戳的 ASR——精确到每个字什么时候说的
时间戳 ASR 这块,直接把 Gemini 2.5 Pro 甩开一大截,不是略胜,是碾压。
以前做音频处理要拼一堆模型,现在一个全搞定,还开源。字幕、播客、客服质检、音乐标注,落地成本直接打下来了。
OpenMOSS 团队低调出手,行业震动。
去 HuggingFace 直接拿。
🔗 huggingface.co/collections/O…

2
150
あらき@Outpost retweeted

Jun 7
MOSS-Audioとは?8Bで30B級に挑むOpenMOSSのオープンソース音声理解モデルを解説
innovatopia.jp/ai/ai-news/10…
話者の特徴や感情を音から推定する能力は、便利さと裏腹に、同意なき声紋分析や感情の監視といった用途にも転用されえます。
1
1
31

Jun 5
🧠 Open Source LLMs 🧠 , Edition 28, June Week 1, 2026
#open_source_llms
In this edition, you will read about:
🧠⚡ NVIDIA Nemotron-Labs-Diffusion-14B: tri-mode decoding for faster text generation ⚡🧠
lnkd.in/dfqDu5Gs
🧠🎥 NVIDIA SANA-WM: minute-scale world modeling on a single GPU 🎥🧠
lnkd.in/dgezX-Jk
🧠📍NVIDIA LocateAnything: fast vision-language grounding 📍🧠
lnkd.in/daXwQmcR
🧠🔎 OpenResearcher 30B-A3B: open deep research agent 🔎🧠
lnkd.in/dfZ6UqCb
🧠🗣️ OpenMOSS MOSS-TTS: open speech and sound generation family 🗣️🧠
lnkd.in/dmHh68YT
🧠🤖 Qwen3.7-Max: agent frontier for long-horizon workflows 🤖🧠
lnkd.in/d3d8_cqS
🧠🔁 Sapient Intelligence HRM-Text-1B: hierarchical reasoning beyond scaling 🔁🧠
lnkd.in/dB_gufVW
and more ..
Thanks to Yonggan Fu, Abhinav Garg, Chengyue Wu, Maksim Khadkevich, Nicolai Oswald, Enze Xie, Shizhe Diao, Chenhan Yu, Weijia Chen, Sajad Norouzi, Shiyi Lan, Ligeng Zhu, Jindong Jiang, Morteza Mardani, Mehran Maghoumi, Song Han , Ante Jukić, Nima Tajbakhsh, Jan Kautz, Pavlo Molchanov, Haozhe Liu, Yuyang Zhao, Junsong Chen, Jincheng YU, Song Han, Enze Xie Shilong Liu, Yunze Man, Andrew Tao, Guilin Liu, Jan Kautz, Lei Zhang, Zhiding Yu, Guan Wang, Changling Liu and Luca Scimeca
for their open source LLMs
📧 Stay tuned and subscribe!
lnkd.in/dAtgNyGN
#opensource #llm #largelanguagemodel #nvidia #nemotron #ultra #kimi #glm #qwen #alibaba #alibabacloud #cloud #cloudcomputing #ai #artificialintelligence #alpamayo #mamba #transformer #diffusion #physicalai #cosmos #robotics #robotaxis #jetbrain #mellum #sapient #hrm #moe #qwen #openmoss #openresearcher #locateanything

1
6
255

Jun 4
大家还在把音频AI当成视觉和文本的边缘附属品时,一个开源模型直接把语音、音乐、环境音三件事彻底统一到一个模型里,干翻了所有闭源方案。
真的试试实际效果如何,看着是真的不粗~~
大家本地搭音频Agent,想让AI不光听懂人说话,还能分辨背景音乐、环境音效,甚至自动剪辑播客。
之前所有方案不是闭源贵得离谱,就是语音和音乐两套系统,串起来一塌糊涂。
今天MOSS-Audio直接把这个痛点干掉了。
OpenMOSS团队这个模型刚刚冲上Hugging Face Trending第一。
它把Speech、Sound、Music真正做到了audio-language统一建模:扔一段带背景音乐的对话,它能同时转录语音、识别环境音、理解音乐情绪,还能生成文本描述或者直接做下游任务。
不是简单堆数据,而是真正从架构上打通了音频世界。
开源可商用,Hugging Face和GitHub代码全放出来了,普通开发者现在就能拉下来本地跑。
这其实把行业当前最主流的认知直接反转了:真正通往超级智能的下一块拼图,不是继续卷视觉 文本,而是让AI像人一样同时感知声音世界。
音频从来不是附属,将和文本同等重要的感官入口。
谁先把这一块做通,谁就抢到了下一代agent的先机。
以前我们总觉得音频AI要等闭源大厂慢慢迭代,现在开源社区用一个模型就把“语音 声音 音乐”这个三合一难题端上来了,速度和开放度反而领先。
Jun 3

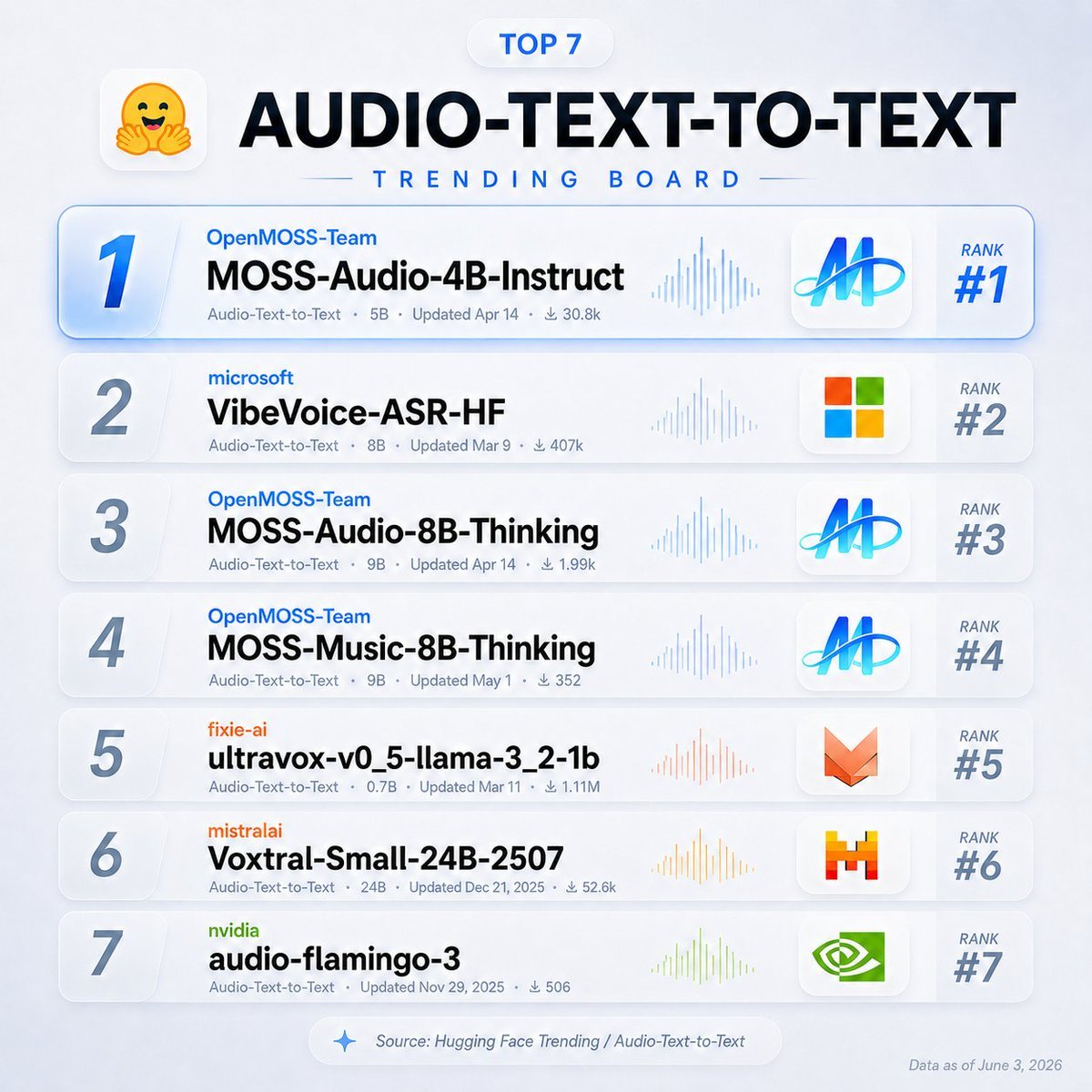
MOSS-Audio just hit #1 on @huggingface Trending.
Speech. Sound. Music.
One open audio-language model.
Try it:
Hugging Face: huggingface.co/collections/O…
GitHub: github.com/OpenMOSS/MOSS-Aud…

2
1
9
3,418

May 31
🚀 Open-Source AI Models: May Recap
According to Zhihu contributor @logcong0120, May may have felt quieter than previous months, but there was still plenty happening across China's open-source AI ecosystem.
Here's your lightning-fast recap👇
📅 May 1
• @Alibaba_Qwen releases Qwen-Scope, using sparse constraints to extract more interpretable and disentangled latent features.
• @MistralAI open-sources Mistral Medium 3.5 (128B).
📅 May 6
• @Google releases Gemma 4 MTP Drafter, leveraging speculative decoding for up to 3× faster inference.
• @ZyphraAI launches ZAYA1-8B, the first MoE model trained on AMD Instinct MI300 hardware.
📅 May 7 – OpenSearch-VL releases a VLM family (8B, 32B, 30B-A3B) alongside a full SFT RL training pipeline.
📅 May 8
• Qwen introduces WebWorld, a browser simulator for training Agents without relying on the real internet, together with WebWorldData trajectories.
• ModelBest releases SciCore-Mol, enhancing LLMs through pluggable external cognition modules.
• HiDream-O1-Image (8B) debuts, unifying image, text, and task conditions into a shared token space for image generation.
📅 May 11 – @Xiaomi releases OneVL, an open autonomous-driving framework with model checkpoints.
📅 May 12 – ModelBest launches MiniCPM-V4.6, a 1.3B multimodal model optimized for mobile deployment, plus its Thinking version.
📅 May 13 – @JinaAI_ introduces jina-embeddings-v5-omni, a multimodal embedding model supporting text, image, audio, and video.
📅 May 14 – @AntLingAGI releases Ring-2.6-1T, enabling stable training of trillion-parameter models through asynchronous RL.
📅 May 15 – SenseTime opens SenseNova-U1-8B-MoT-Infographic, optimized for high-density infographic generation.
📅 May 16 – @intern_lm unveils Intern-S2-Preview, a 35B scientific multimodal model surpassing its predecessor.
📅 May 18 – Bytedance releases Lance, a native multimodal model for understanding, generating, and editing images and videos.
📅 May 20 – @Cohere launches Command A , a multimodal model with 218B total parameters and 25B active parameters.
📅 May 21
• Meituan's LongCat-Video-Avatar-1.5 improves digital-human video generation with more accurate lip-syncing.
• @TencentHunyuan releases Hy-MT2, a multilingual translation model family spanning 1.8B to 30B-A3B.
• NetEase launches Confucius4, a multimodal model specialized for mathematical reasoning based on Qwen3.5.
📅 May 23 -24
ModelBest releases BitCPM-CANN, a family of native Ascend-trained 1.58-bit ternary models, and launches MiniCPM5-1B, targeting edge devices and local deployment.
📅 May 25 – Kuaishou releases Keye-VL-2.0, supporting near-lossless reasoning over 256K-token video contexts.
📅 May 26 – OpenMOSS upgrades MOSS-TTS-v1.5 with more stable voice cloning and pause control, and releases MOSS-SoundEffect-V2.0, generating environmental and action sounds directly from text.
📅 May 28 – @Baidu_Inc updates PaddleOCR-VL-1.6, reaching 96.33% on OmniDocBench v1.6.
📅 May 29 – @StepFun_ai releases Step3.7-Flash, a 198B multimodal model with configurable reasoning levels.
🙋 Also, open source wasn't the whole story this month. Several closed-source models were equally worth watching:
• Doubao-Seed-2.0-lite surprisingly outperformed Pro
• Qwen3.7-Max delivered a significant jump over 3.6
• GLM-5.1-HighSpeed pushed inference speed to 400 tok/s
• Google released Gemini 3.5 Flash and Gemini Omni
• Claude Opus 4.8 doubled down on honesty, reducing the chance of Agents "pretending" to finish long-horizon tasks
👀 For author, he's still waiting for Qwen3.7-32B and DeepSeek-VL. How about you?
📖 Full article:
zhuanlan.zhihu.com/p/2044378…
#OpenSource #LLM #Qwen #DeepSeek #MiniCPM #StepFun #Agent #AI
2
1
8
694

机器人世界模型(全新维度,0 去重 = 全新信息)
核心项目:
- Awesome-WAM(OpenMOSS):World Action Models 综合论文列表,含 DreamDojo(从人类视频学习的通用机器人世界模型)
- awesome-physical-ai:VLA 模型、世界模型、具身基础模型论文合集,含 NVIDIA Cosmos Predict2.5
- π₀/π₀.5(Physical Intelligence):视觉-语言-动作流模型,通用机器人控制
- GR00T N1(NVIDIA):通用人形机器人开放基础模型
- InternVLA-A1(阿里巴巴):统一理解、生成和动作的机器人操作模型
仿真环境: Genesis、Isaac Sim、MuJoCo 仍是主流
操作策略: LeRobot(Hugging Face)、Octo、Diffusion Policy、ACT 是当前热门
18
3
2,212

May 28
MOSS-SoundEffect v2.0 dropped May 26 from Fudan University's OpenMOSS Team. 1.3 billion parameters. Apache 2.0. Fully commercial.
Te big jump is the 48 kHz. Keep in mind that for example, Stable Audio 3 from Stability AI outputs at 44.1 kHz. MOSS-SoundEffect v2.0 outputs at 48 kHz, what is the SMPTE standard for theatrical and broadcast delivery. The audio can go directly into DaVinci Resolve or Pro Tools or whatever without sample rate conversion.
The workflow is basically you write a description and you get up to 30 seconds of audio. Like rain, wind, ocean, traffic, crowds, animal sounds, human action audio, percussive clips. English and Chinese prompts supported and there is no need of sound library.
The architecture is a Diffusion Transformer with Flow Matching. Text conditioning through Qwen3-1.7B. Audio via DAC VAE codec.
So MOSS-SoundEffect v2.0 does sound design from text, and it does it at broadcast specification, under a license with no restrictions.
But more broadly the MOSS-TTS Family from Fudan University's OpenMOSS Team covers five models: TTS, multi-speaker dialogue, voice design from text, real-time synthesis, and sound effects. Also all Apache 2.0. and commercial use allowed.
The TTS is from 8 billion parameters, with zero-shot voice cloning, 20 languages and stable long form speech. On the Seed-TTS-eval benchmark it beats every open source model and matches the leading closed-source systems.
Very impressive.
More info.
studio.aifilms.ai/blog/moss-…
3
128

MOSS-TTS - MOSS‑TTS Family is an open‑source speech and sound generation model family from MOSI.AI and the OpenMOSS team. It is designed for high‑fidelity, high‑expressiveness, and complex real‑world s... github.com/OpenMOSS/MOSS-TTS
5
628

May 27
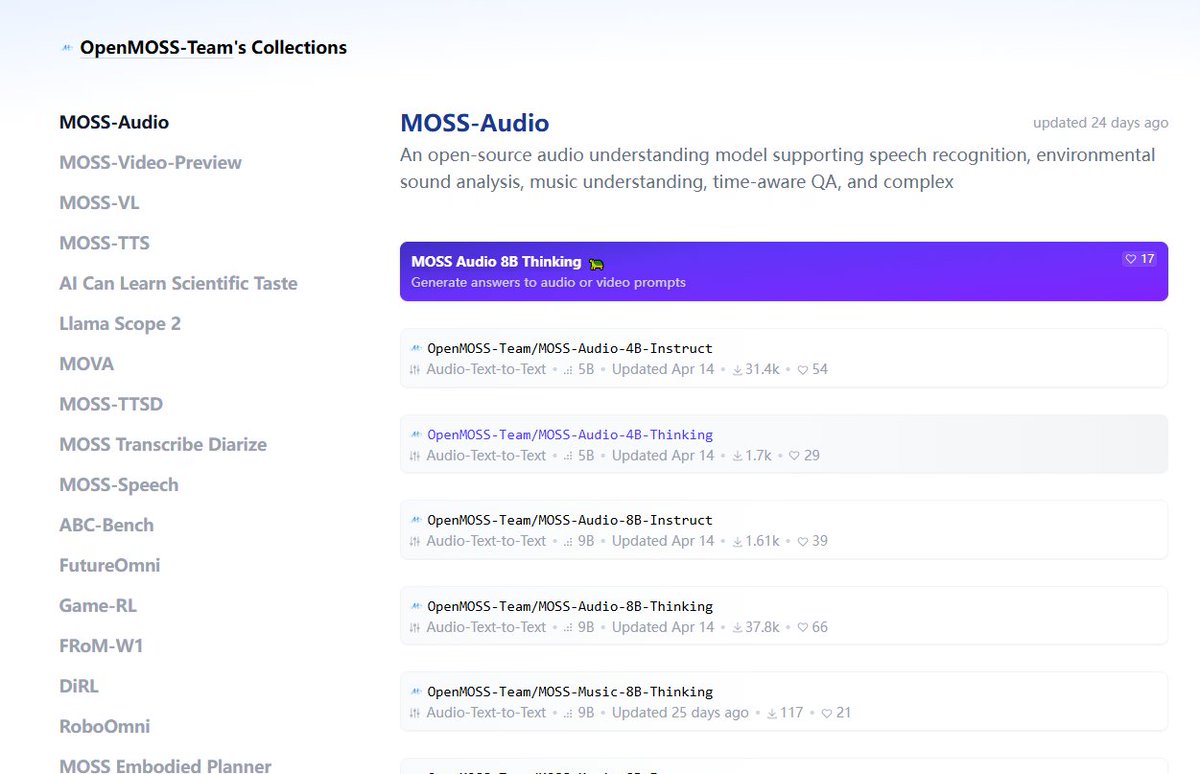
Ses alanında çığır açan bir başka açık kaynak ürünü ortaya çıktı: MOSS-Audio.
4B ve 8B boyutlarında, her birinde Instruct ve Thinking sürümleri arasından seçim yapabilirsiniz.
En etkileyici özelliği, altı yeteneği tek bir modelde birleştirmesidir:
1️⃣ Otomatik Konuşma Tanıma (ASR)
2️⃣ Konuşmacı Ayrımı – Kimin konuştuğunu net bir şekilde ayırt eder.
3️⃣ Duygu Tanıma – Mutlu mu yoksa üzgün mü olduğunuzu anlar.
4️⃣ Ortam Sesi Analizi – Yağmur, trafik ve klavye seslerini tanır.
5️⃣ Müzik Anlama – Sadece şarkı başlıklarını tanımakla kalmaz, yapısını da gerçekten anlar.
6️⃣ Zaman Damgalı ASR – Her kelimenin ne zaman söylendiğini tam olarak belirler.
Zaman damgalı otomatik konuşma tanıma (ASR) açısından, Gemini 2.5 Pro'yu çok geride bırakıyor – sadece biraz daha iyi değil, tamamen üstün.
Daha önce, ses işleme için çok sayıda model oluşturmak gerekiyordu; şimdi ise tek bir model her şeyi hallediyor ve açık kaynaklı. Altyazılar, podcast'ler, müşteri hizmetleri kalite kontrolü ve müzik açıklamaları—uygulama maliyetleri doğrudan azaltıldı.
OpenMOSS ekibi sessizce bir hamle yaparak sektörü sarstı.
Doğrudan HuggingFace'ten edinin.
🔗huggingface.co/collections/O…
2
9
978

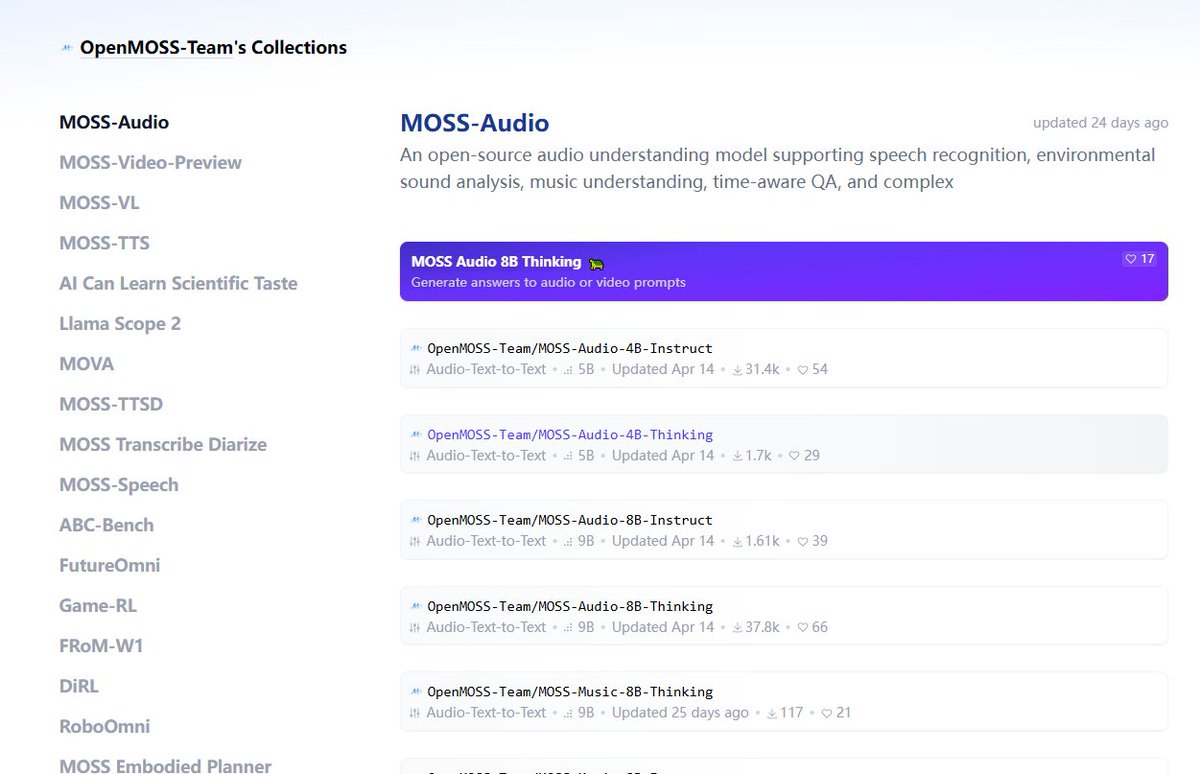
音频领域又炸出一个开源猛货,MOSS-Audio 来了。
4B 和 8B 两种尺寸,每个都有 Instruct 和 Thinking 版,任你选。
最硬核的是它把六项能力塞进了一个模型:
1️⃣ 语音识别(ASR)
2️⃣ 说话人分离——谁在说话,分得清清楚楚
3️⃣ 情绪识别——听得懂你是高兴还是烦躁
4️⃣ 环境音解析——雨声、车流、键盘声都能识别
5️⃣ 音乐理解——不只是识别歌名,是真的听懂结构
6️⃣ 带时间戳的 ASR——精确到每个字什么时候说的
时间戳 ASR 这块,直接把 Gemini 2.5 Pro 甩开一大截,不是略胜,是碾压。
以前做音频处理要拼一堆模型,现在一个全搞定,还开源。字幕、播客、客服质检、音乐标注,落地成本直接打下来了。
OpenMOSS 团队低调出手,行业震动。
去 HuggingFace 直接拿。
🔗 huggingface.co/collections/O…
45
129
753
44,934

May 26
MOSS-TTS v1.5 is here, an upgrade to v1.0 from @OpenMOSS. (demo👇)🤖modelscope.ai/models/OpenMOS…
Key improvements:
⏸️ Inline pause control: [pause 3.2s] now supported mid-sentence
🌍 31 languages, up from 20 — now includes Cantonese, Hindi, Thai, Vietnamese, Tagalog, Swahili and more
🎙️ More stable voice cloning with reduced variance across repeated generations
📝 Better long-reference, short-text cloning All v1.0 capabilities preserved: zero-shot cloning, long-form speech, Pinyin/IPA control, code-switching.
💻 github.com/OpenMOSS/MOSS-TTS
5
44
251
13,658

May 7
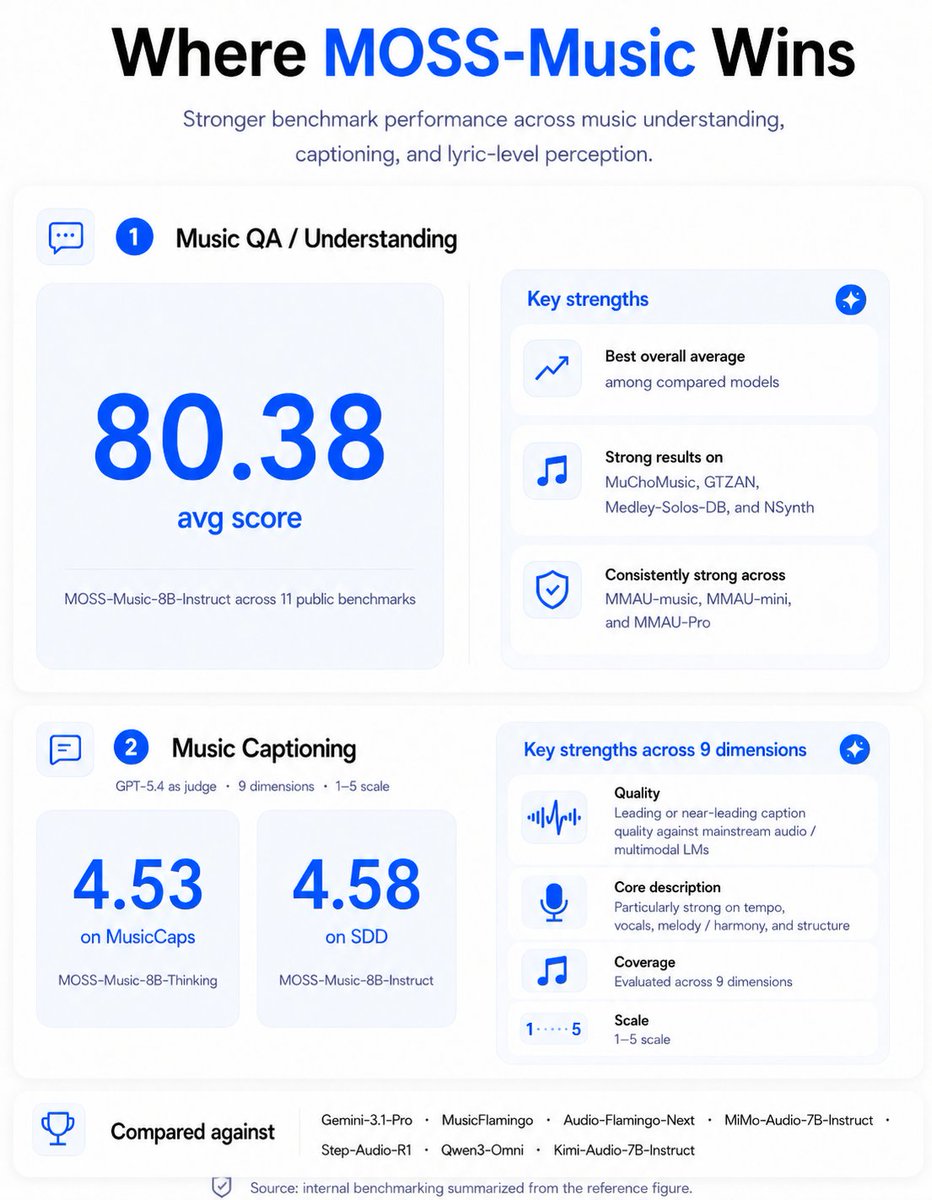
Today we’re releasing MOSS-Music.
We taught an open-source model to listen like a musician—transcribing, analyzing, and reasoning over full songs.
It understands lyrics, chords, rhythm, instrumentation, song structure, and long-form musical context.
Released in two 8B variants:
– MOSS-Music-8B-Instruct
– MOSS-Music-8B-Thinking
80.38 avg accuracy on public music QA benchmarks.
15.88% avg WER/CER on sung lyrics ASR.
Open-source today.
MOSI AI: mosi.cn
OpenMOSS: open-moss.com
MOSS-Audio (backbone): github.com/OpenMOSS/MOSS-Aud…
MOSS-Music Data Pipeline: github.com/wx9songs/MOSS-Mus…
#MOSSMusic #OpenMOSS #OpenSourceAI #MusicAI #AudioAI #AIForMusic
2
21
529
May 7
April AI Model Roundup 🚀
Long-awaited DeepSeek-V4 is finally open-sourced! All top domestic AI vendors have released their flagship best models as open source this month.
End-of-month monthly open-source model recap is here 📅.
Below is the summary from Zhihu contributor 刘聪NLP
🤖Agent ecosystems boomed this month
Hermes replaced OpenClaw as the new Agent mainstream. GPT-Image2 brought stunning visual generation quality, redefining visual authenticity standards.
The domestic large model race keeps accelerating 🔥:
GLM5.1、Kimi K2.6、Qwen3.6、Hunyuan HY-3.0-preview and the highly expected DeepSeek-V4 are all officially open-sourced.
💡Several new models remain closed-source: GLM-5V-Turbo、Qwen3.6-Plus and more.
Google Gemma 4 series is also worth attention ✨, one of the few high-quality overseas open-source model releases recently.
This is our 10th monthly recap since last July. In the AI information explosion era, this roundup helps fill information gaps and discover overlooked high-quality niche models.
April Core Open-Source Releases 📌
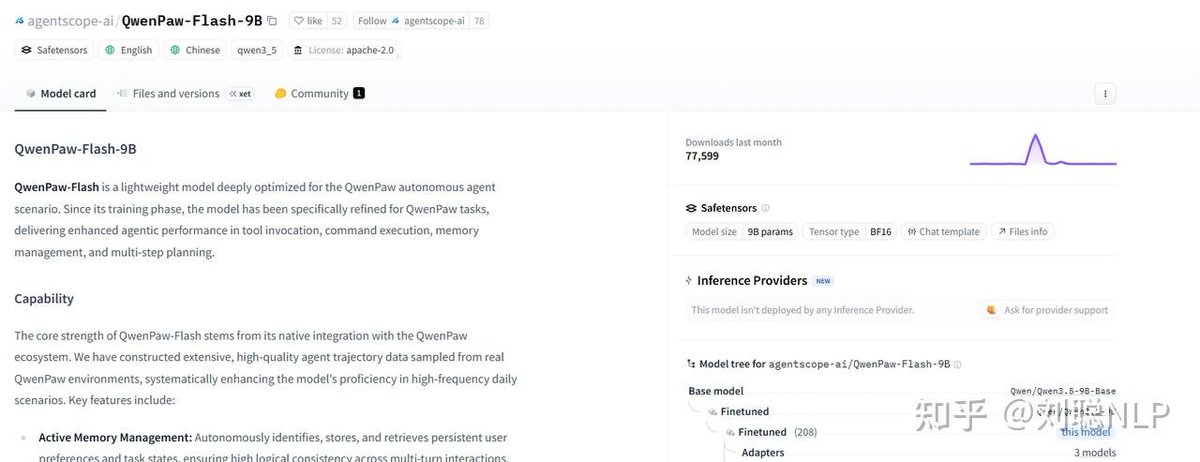
• Apr 1|Alibaba open-sourced QwenPaw-Flash (2B/4B/9B), Qwen3.5 fine-tuned small models optimized for AI agents.
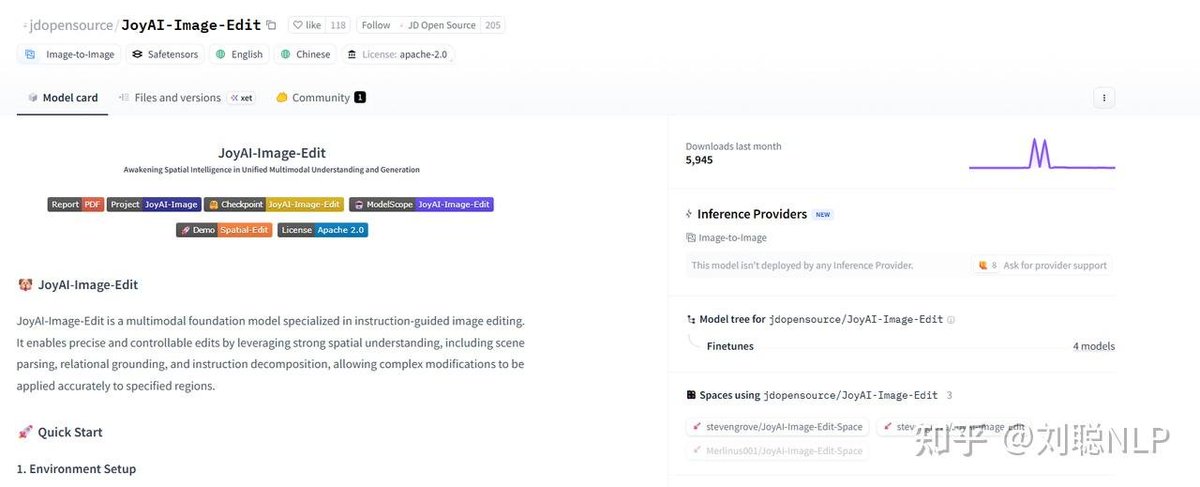
• Apr 2|JD open-sourced JoyAI-Image multimodal model for image understanding, generation and editing, plus OpenSpatial-3M dataset.
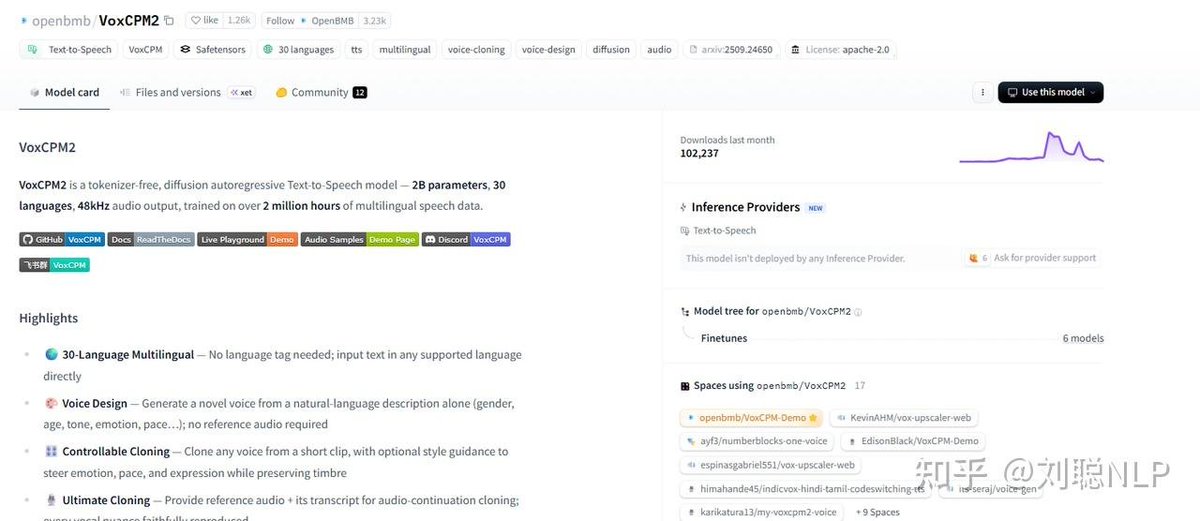
• Apr 7|MiniMax Wall Intelligence released VoxCPM2 (2B) TTS model, supporting 30 languages, voice cloning and 48kHz studio audio 🎙️.
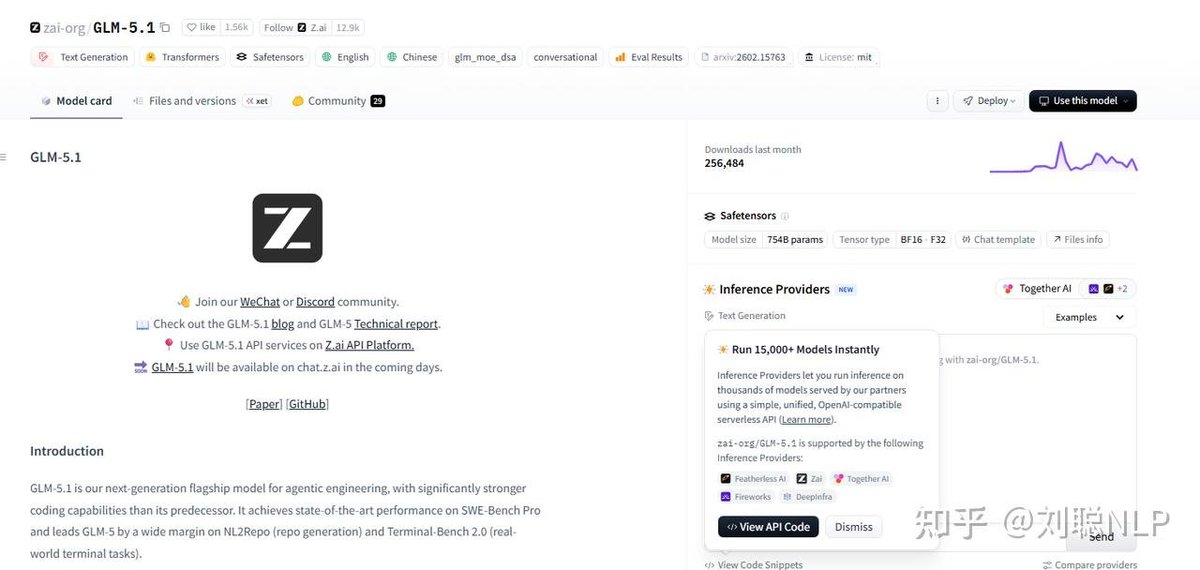
• Apr 8|Zhipu open-sourced GLM5.1 (744B total / 40B activated), strong at long-duration autonomous task running.
• Apr 8|Alibaba International open-sourced Marco-MoE ultra-sparse lightweight MoE models.
• Apr 9|Tencent open-sourced HY-Embodied-0.5, tailored for embodied intelligence visual perception and reasoning 🧠.
• Apr 10|OpenMoss launched tiny MOSS-TTS-Nano TTS model, runnable on pure CPU.
• Apr 12|MiniMax open-sourced M2.7 (230B total / 10B activated), claimed self-evolving model; license revision sparked discussion.
• Apr 15|Baidu open-sourced ERNIE-Image text-to-image model, runnable on 24G GPU 🎨.
• Apr 15|Alibaba released Qwen3.6-35B-A3B, first open-source version of Qwen3.6.
• Apr 16|Tencent open-sourced HY-World 2.0 world model, supports multi-input and outputs 3D scene reconstruction.
• Apr 20|Kimi open-sourced K2.6 multimodal model (1T total / 32B activated), focused on multi-agent interaction.
• Apr 22|Ant open-sourced Ling-2.6-flash (104B), recognized as OpenRouter Elephant model.
• Apr 22|Alibaba released popular Qwen3.6-27B open-source version.
• Apr 23|Tencent Hy3-preview (295B total / 21B activated) launched and integrated into internal products.
• Apr 23|Ant open-sourced Ling-2.6-1T for precise low-token instruction execution, plus LLaDA2.0-Uni unified multimodal model.
• Apr 23|Xiaomi open-sourced MiMo-V2.5-ASR, supporting bilingual, dialects and complex noisy speech recognition.
• Apr 24|DeepSeek-V4 officially open-sourced 🎉: V4-Pro and V4-Flash available; vision model now in gray release.
• Apr 27|SenseTime open-sourced SenseNova-U1 native multimodal series in 8B & A3B versions.
• Apr 28|Xiaomi fully open-sourced MiMo-V2.5 series and launched 100T Token training plan.
• Apr 29|Tencent open-sourced Hy-MT1.5-1.8B edge translation model, compressing 33-language model to 440MB 📱.
📎 March Catch-Up
Mar 27|Tiangong open-sourced Matrix-Game-3.0 5B world model, built for 720p real-time long video generation.
🧠Closing Insight
There is still a gap with top overseas AI players, but domestic large models are catching up rapidly and narrowing the gap step by step.
Full article:
zhuanlan.zhihu.com/p/2033128…
#AIOpenSource #LargeLanguageModel #DeepSeek #Qwen #GLM
1
1
20
5,192
May 6
MOSS-TTS-Nano just crossed 100K monthly downloads on Hugging Face.
As a 0.1B multilingual TTS model, it is designed for real-time speech generation, CPU-friendly deployment, and low-latency voice applications across edge, browser, and local environments.
Thanks to everyone building with OpenMOSS.
GitHub: github.com/OpenMOSS/MOSS-TTS…
HF: huggingface.co/OpenMOSS-Team…

1
5
256
Apr 30
OpenMOSS April releases are here.
Three open-source model lines across voice, vision, and audio:
MOSS-TTS-Nano
MOSS-VL
MOSS-Audio
Lighter, faster, and more usable multimodal AI.
Open weights. Built for the community.
github.com/OpenMOSS

2
2
10
544
Apr 29
14.8k downloads already.
MOSS-Audio-8B-Thinking turns real-world audio into reasoning-ready context — understanding speech, speakers, sound events, music, emotion, and time.
Open. Capable. Built for audio agents.
Try it today ↓
GitHub: github.com/OpenMOSS/MOSS-Aud…
HF: huggingface.co/collections/O…
OpenMOSS: open-moss.com
MOSI Offical Website:mosi.cn

1
4
221

Apr 29
🎧 OpenMOSSが「MOSS-Audio」をリリースしました。音声認識、話者・感情分析、環境音の理解、音楽分析、時間軸QA、複雑な推論まで、1つのモデルでこなせるオープンソースの音声基盤モデルです。
アーキテクチャの工夫が興味深いです。中間層の特徴量をLLMの初期層に直接注入する「DeepStack Cross-Layer Injection」と、明示的な時間トークンを挿入する「Time-Aware Representation」で、韻律や音色といった低レベルの音響情報まで保持しています。
8B-Thinking版は33BのStep-Audio-R1を凌ぐ71.08の平均精度を達成。自分のサイズの4倍以上のモデルを超えるのはすごいですね。
marktechpost.com/2026/04/27/…
#AI #音声認識 #オープンソース #雪羽のログ
4
80

Apr 29
兄弟们,音频AI又出大活了!
MOSS-Audio来了,而且是开源的——这就很香了。
先说规格:4B和8B两个尺寸,每个尺寸都有Instruct版和Thinking版,四个模型随便选,总有一款适合你。
再说能力,这个才是真正让人瞠目结舌的部分,把这些全塞进一个模型里:
1️⃣ 语音识别(ASR)
2️⃣ 说话人分析——谁在说话给你搞清楚
3️⃣ 情感检测——听出你情绪好不好
4️⃣ 环境声理解——周围有什么声音它都懂
5️⃣ 音乐理解——不只是识别,是真的理解
6️⃣ 时间戳ASR——精确到每个字什么时候说的
重点来了,时间戳ASR这块,直接把Gemini 2.5 Pro按在地上摩擦,精度差距不是一点点,是碾压级别的领先。
这事为什么重要?
你想想,以前做音频处理要堆一堆不同的模型,各种对齐各种折腾。现在一个模型全搞定,而且还是开源的,谁都能用,谁都能改。
这就是OpenMOSS团队干的事,低调出手,直接给行业上了一课。
字幕生成、播客分析、客服质检、音乐标注……这些场景全部受益,现在落地成本直接打下来了。
赶紧去HuggingFace薅下来玩。
🔗 huggingface.co/collections/O…
1
4
10
30,009

Apr 28
OpenMOSS publica MOSS-Audio: un modelo de base de código abierto para el razonamiento de audio sensible al tiempo, el habla y el sonido
marktechpost.com/2026/04/27/…

3
14
1,543
Apr 28
MOSS-Audio outperforms NVIDIA Audio-Flamingo-Next in same-setup benchmark tests.
Under the same evaluation setup, MOSS-Audio performs better across general audio understanding, speech captioning, ASR, and timestamp ASR.
The results hold across both 4B and 8B models, showing strong audio understanding performance without relying on extreme parameter scale.
MOSS-Audio is open-source now.
Built for real-world audio understanding across speech, emotion, speakers, sound events, music, temporal grounding, and reasoning.
GitHub: github.com/OpenMOSS/MOSS-Aud…: huggingface.co/collections/O…
OpenMOSS: open-moss.com
MOSI Offical Website:mosi.cn

3
1
5
219