
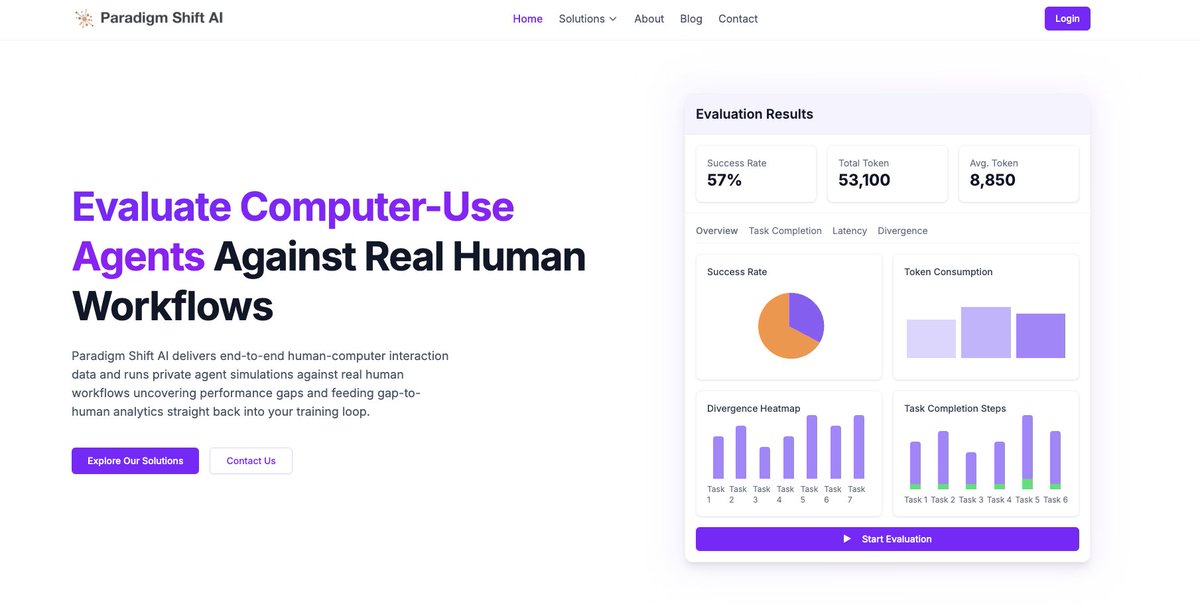
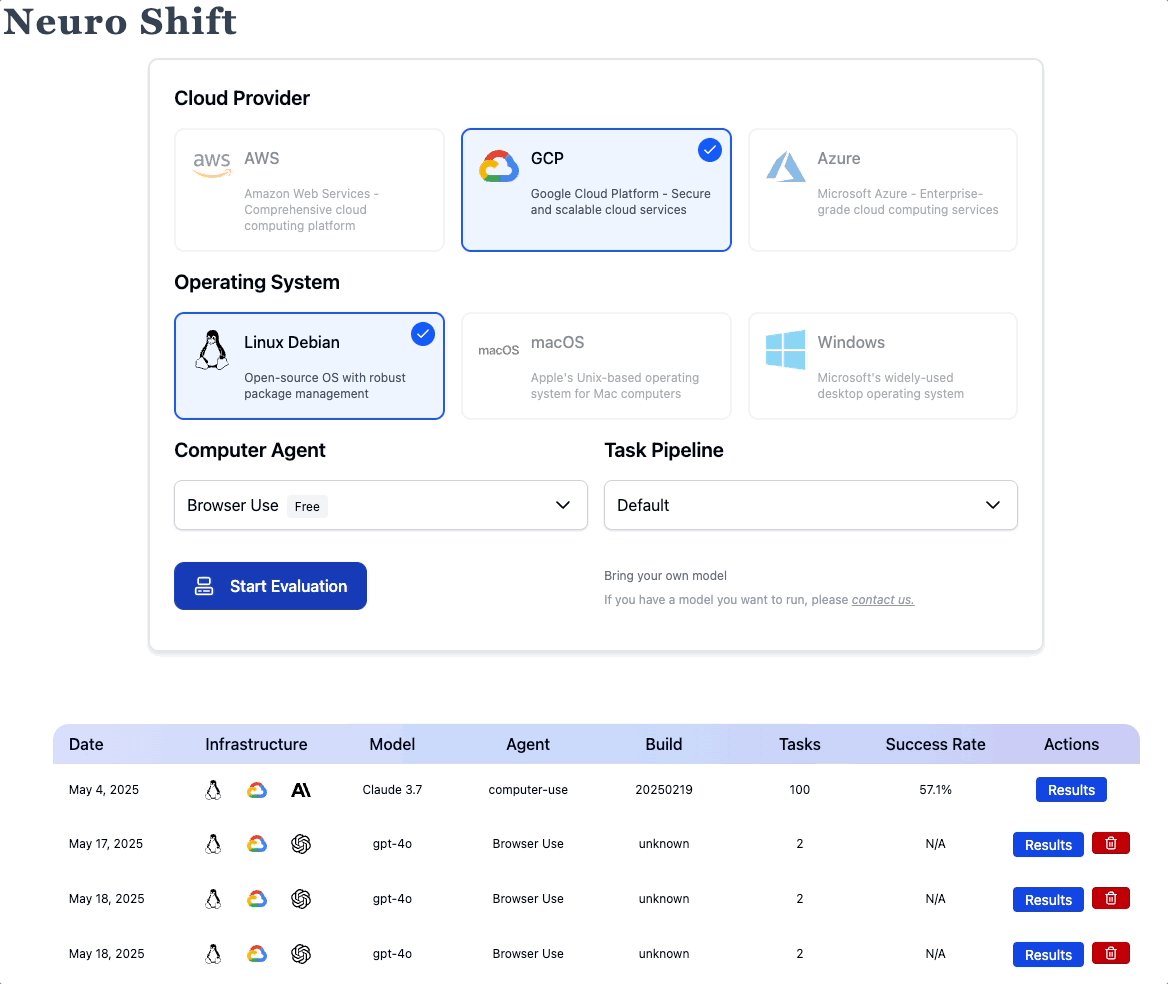
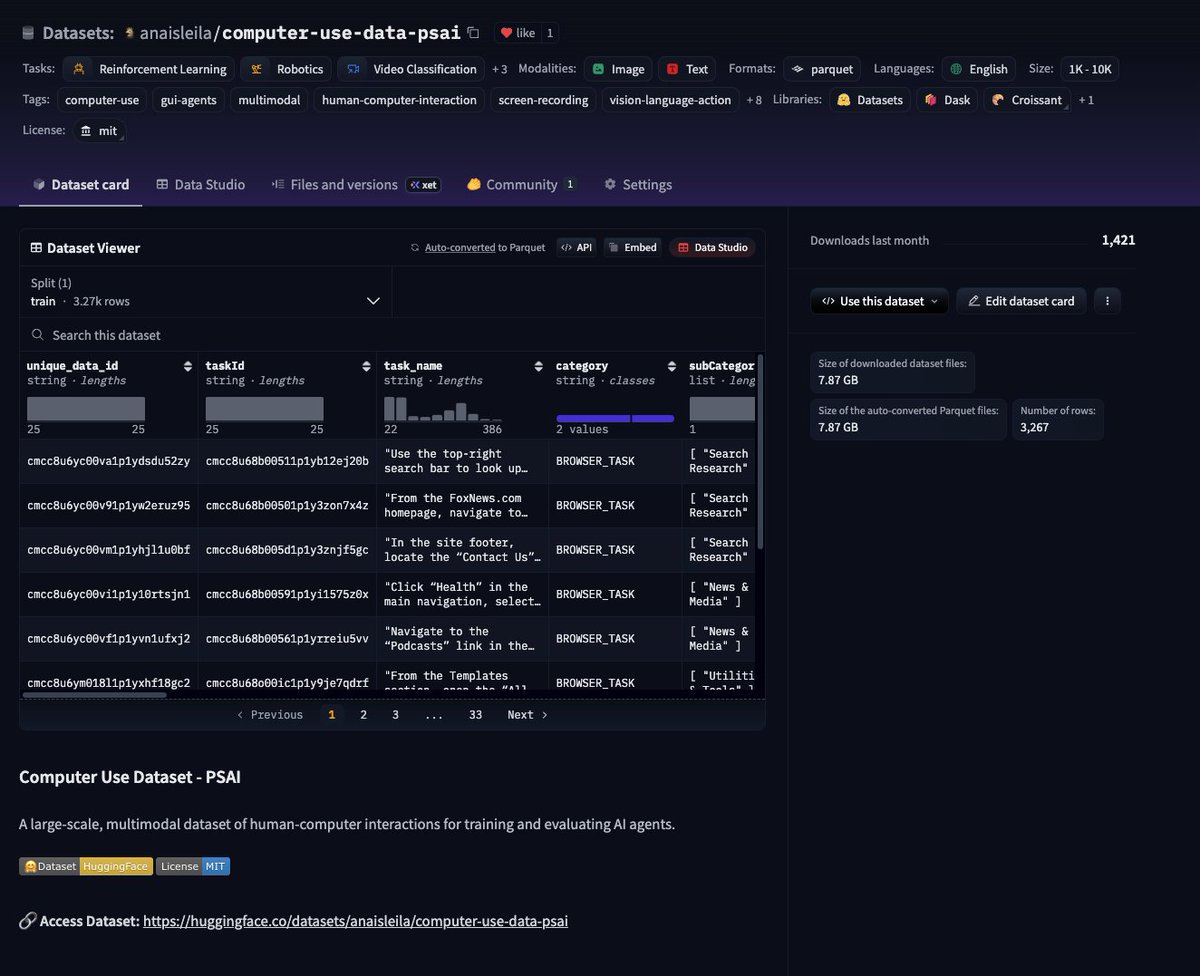
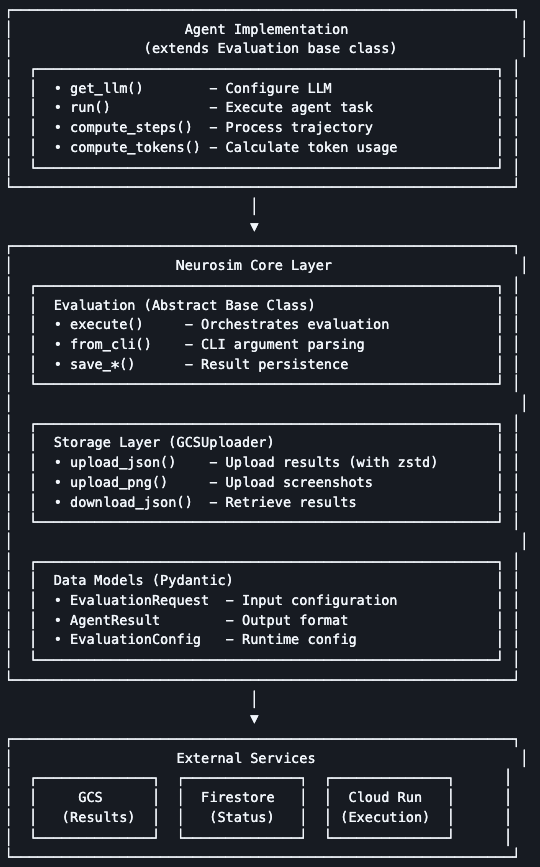
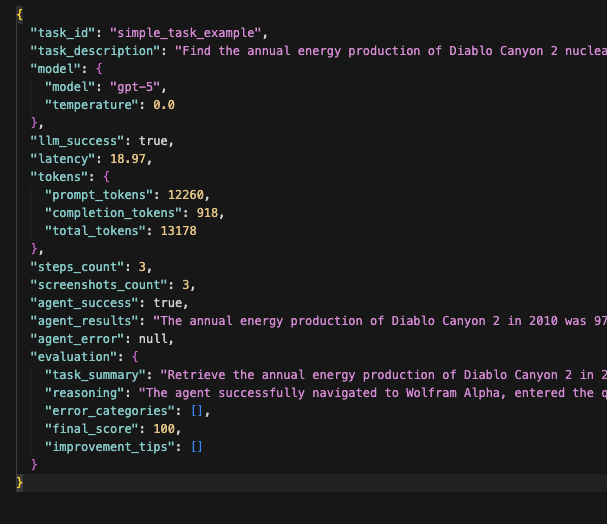
Teaching AI agents to use computers. Continuous evaluation and infrastructure platform for computer-use agents.
- Tweets 32
- Following 209
- Followers 53
- Likes 167




ALT Bar chart titled ‘WebVoyager model leaderboard – ranked by LLM evaluator performance, Sep 20, 2025.’ Y-axis: LLM evaluator score. Four bars: GPT-5 78, Claude 4 Sonnet 77, Gemini 2.5 Pro 73, Gemini 2.5 Flash 67. GPT-5 leads by 1 point over Claude; Flash trails. Purple bars with model logos above each.
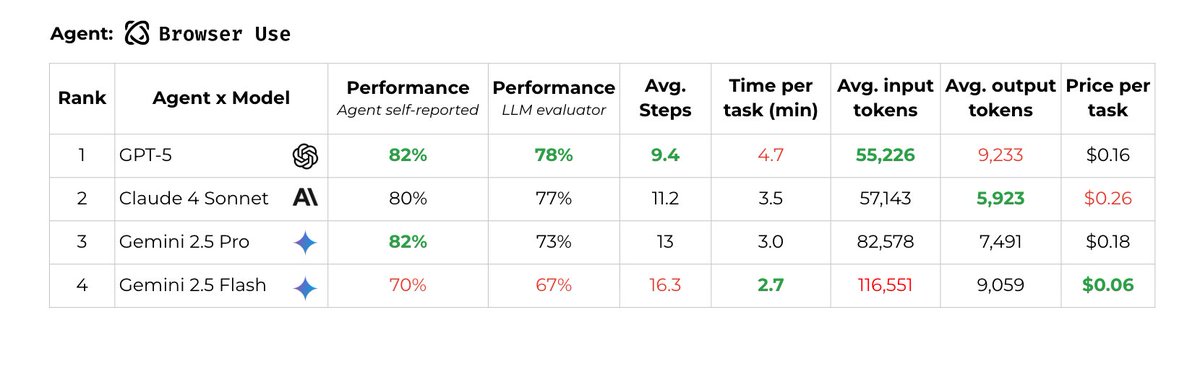
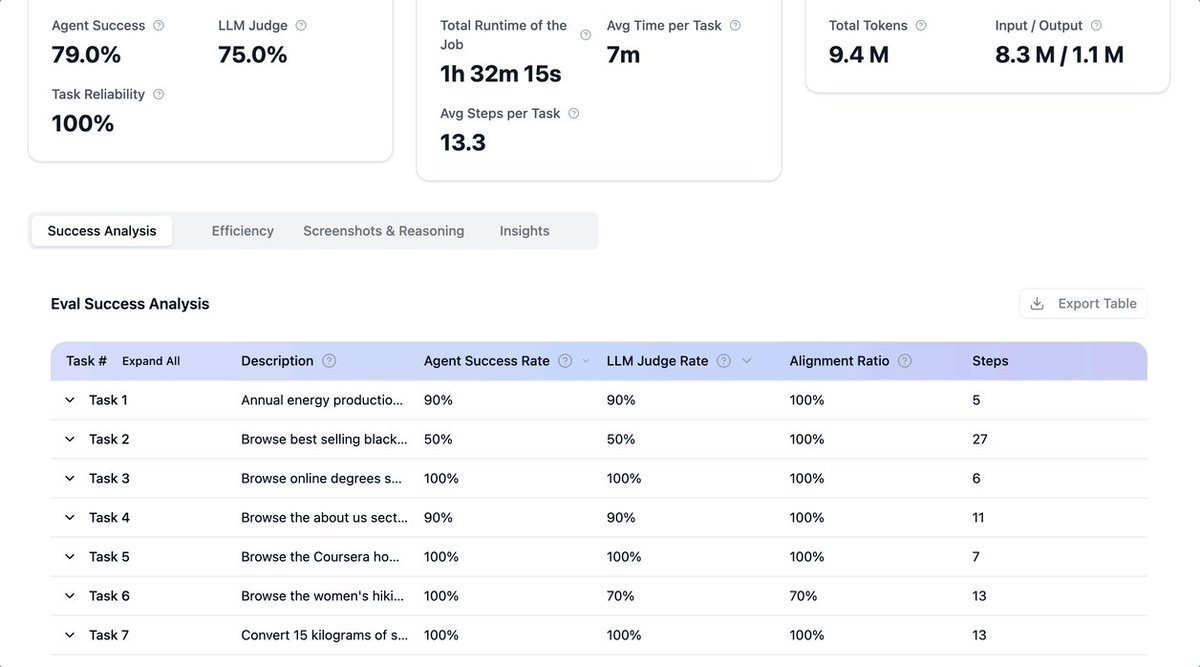
ALT Table comparing Browser Use agent across models with rank, performance, steps, time, tokens, and price per task. 1. GPT-5: 82% self-reported, 78% LLM evaluator, 9.4 steps, 4.7 min, 55,226 input tokens, 9,233 output tokens, $0.16. 2. Claude 4 Sonnet: 80%, 77%, 11.2 steps, 3.5 min, 57,143 input, 5,923 output, $0.26. 3. Gemini 2.5 Pro: 82%, 73%, 13 steps, 3.0 min, 82,578 input, 7,491 output, $0.18. 4. Gemini 2.5 Flash: 70%, 67%, 16.3 steps, 2.7 min, 116,551 input, 9,059 output, $0.06. Takeaway: GPT-5 has the top score, Claude is close but most expensive, Flash is fastest and cheapest with lower reliability
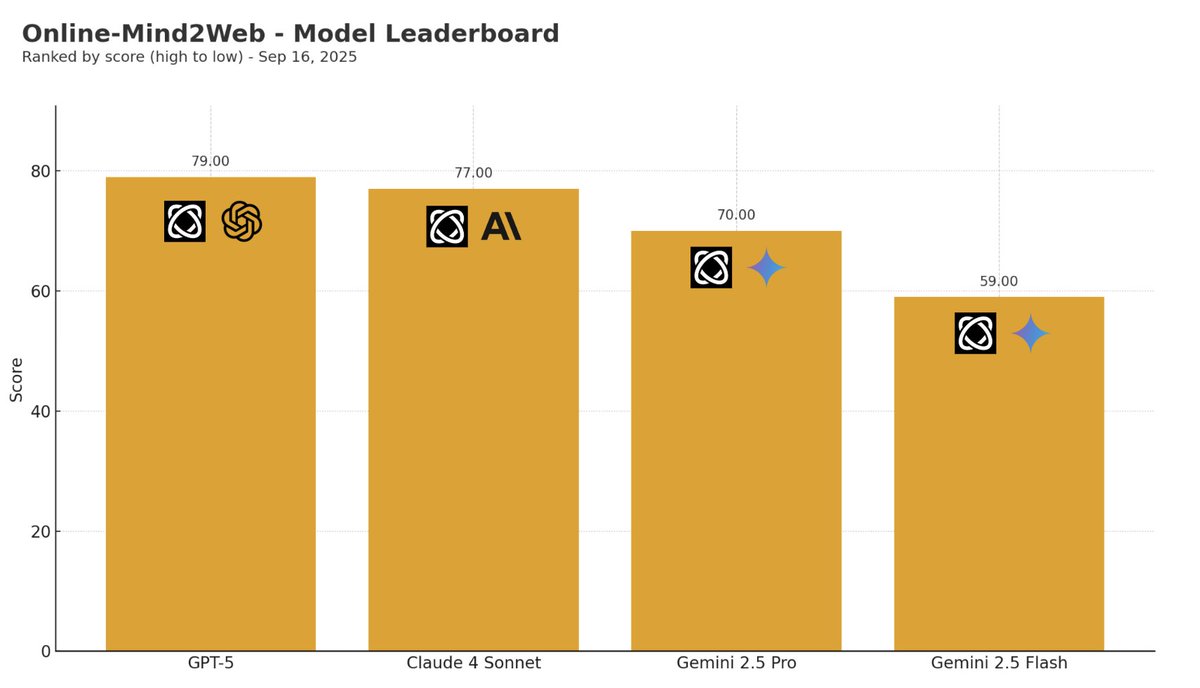
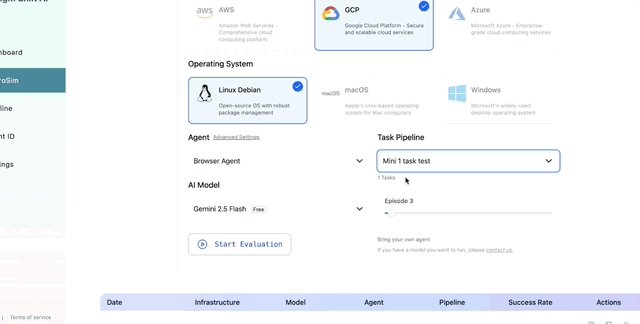
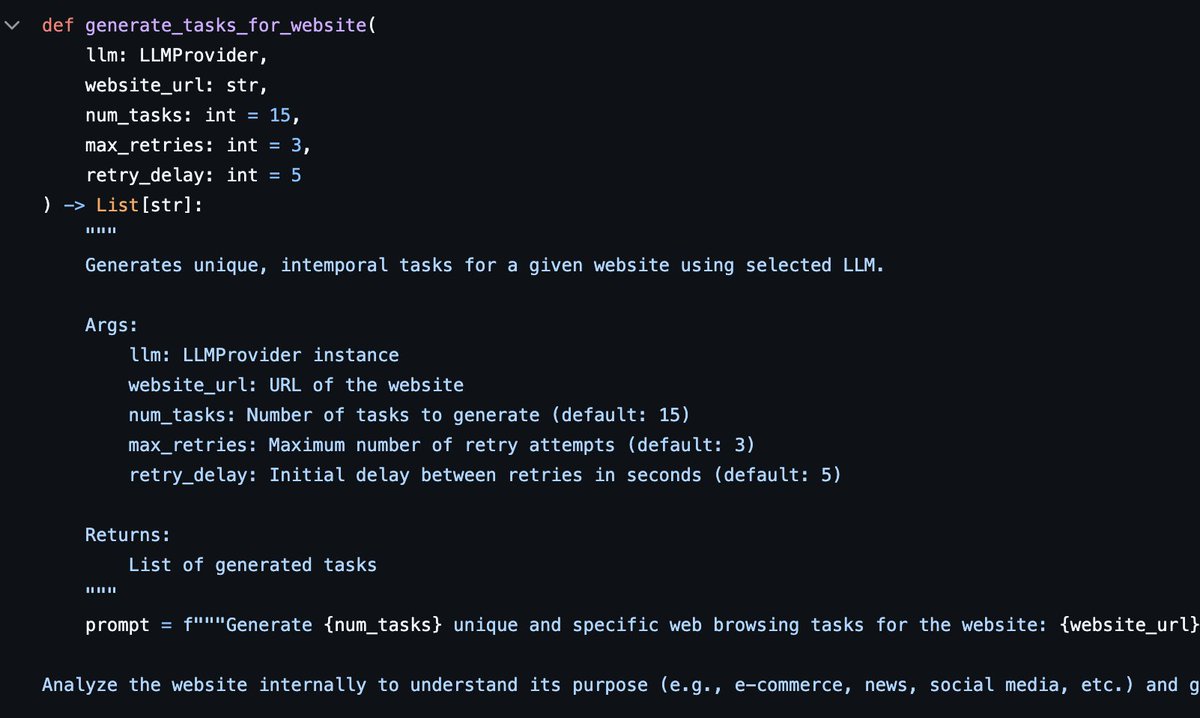
ALT Vertical bar chart titled Online-Mind2Web - Model Leaderboard. X-axis shows models GPT-5, Claude 4 Sonnet, Gemini 2.5 Pro, Gemini 2.5 Flash. Y-axis shows score. Bars from highest to lowest: GPT-5 79, Claude 4 Sonnet 77, Gemini 2.5 Pro 70, Gemini 2.5 Flash 59. Subtitle says ranked by score high to low. Runs used the Browser Use agent, 2 to 5 episodes per task, on Paradigm Shift AI infrastructure.
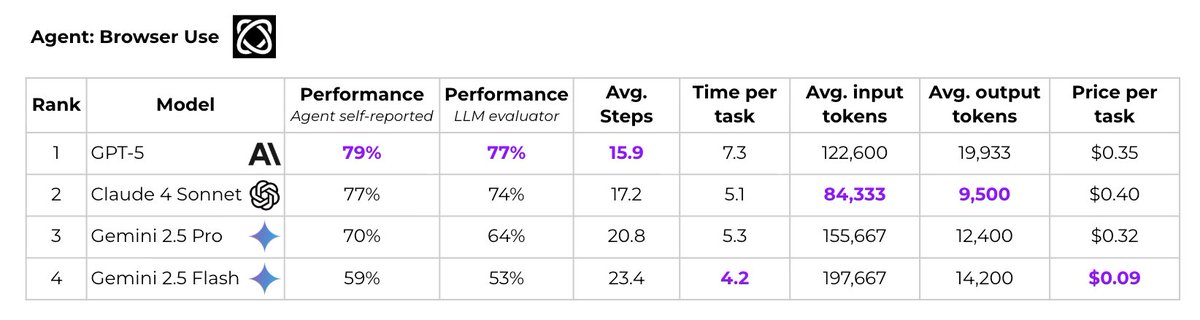
ALT 0, 4 Gemini 2.5 Flash 59. Remaining rows list other evaluated models with their scores. All runs used the Browser Use agent, averaged over 2 to 5 episodes per task, on Paradigm Shift AI infrastructure.

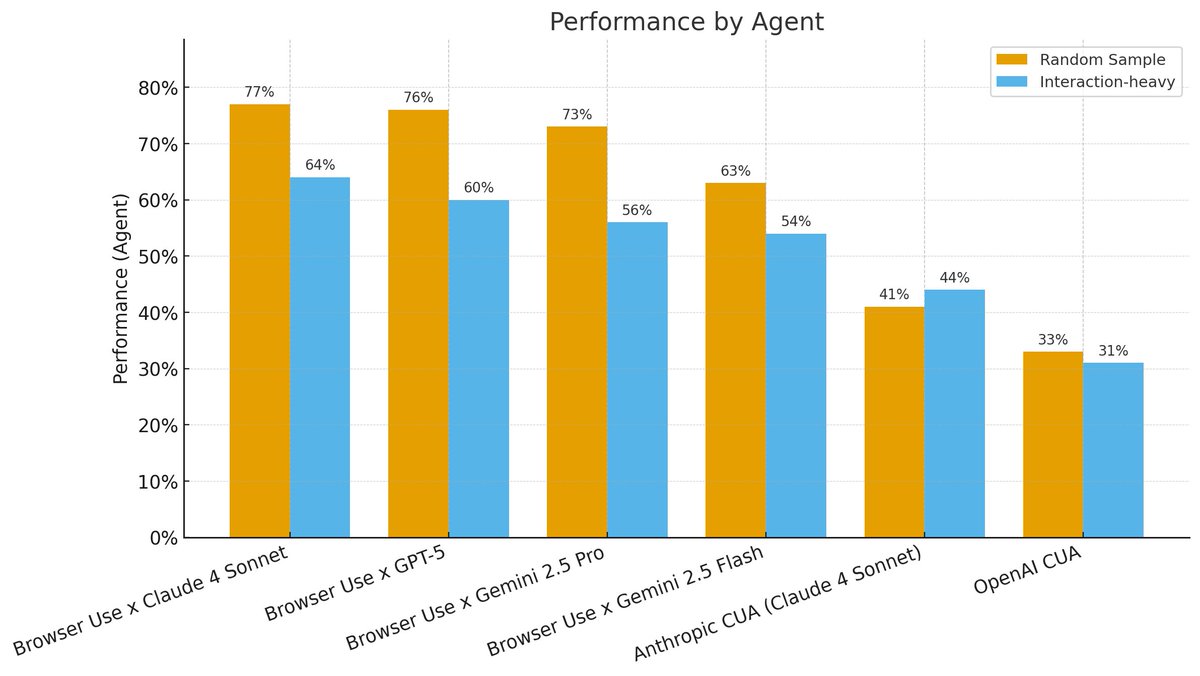
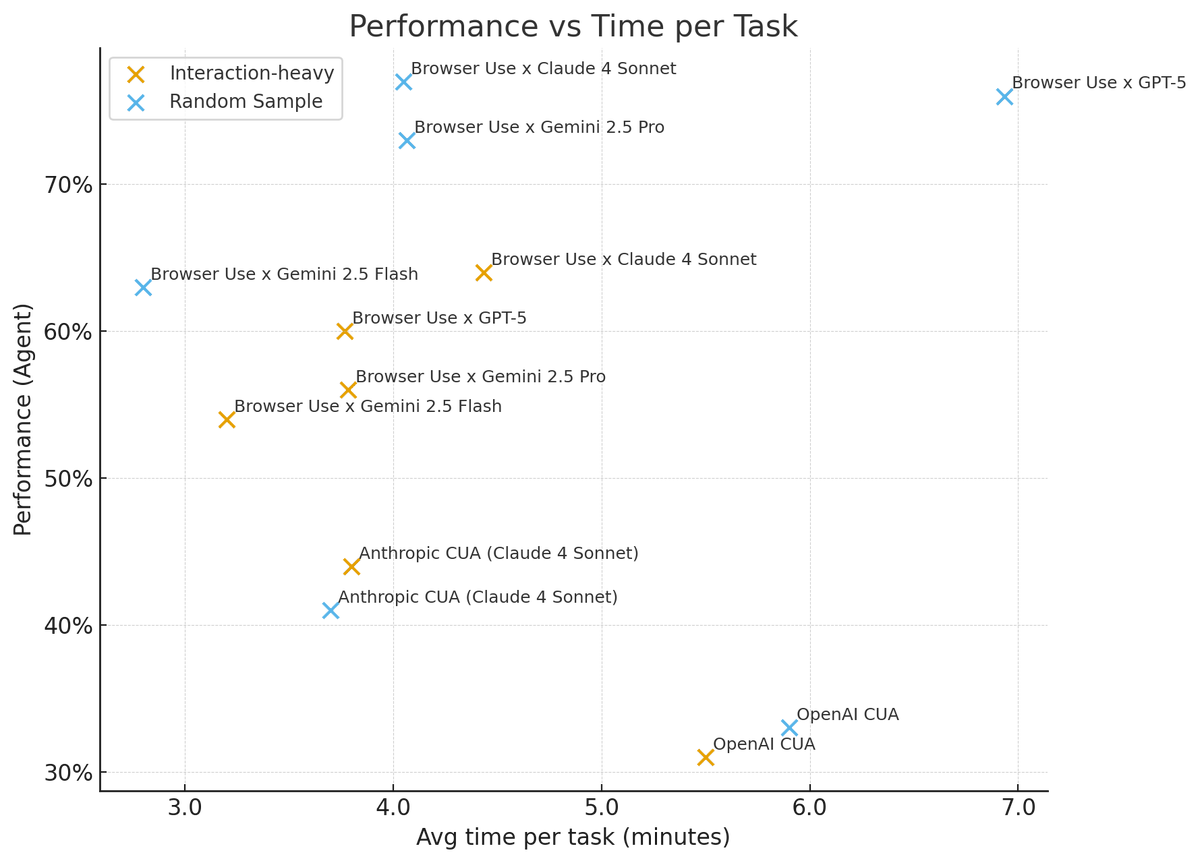
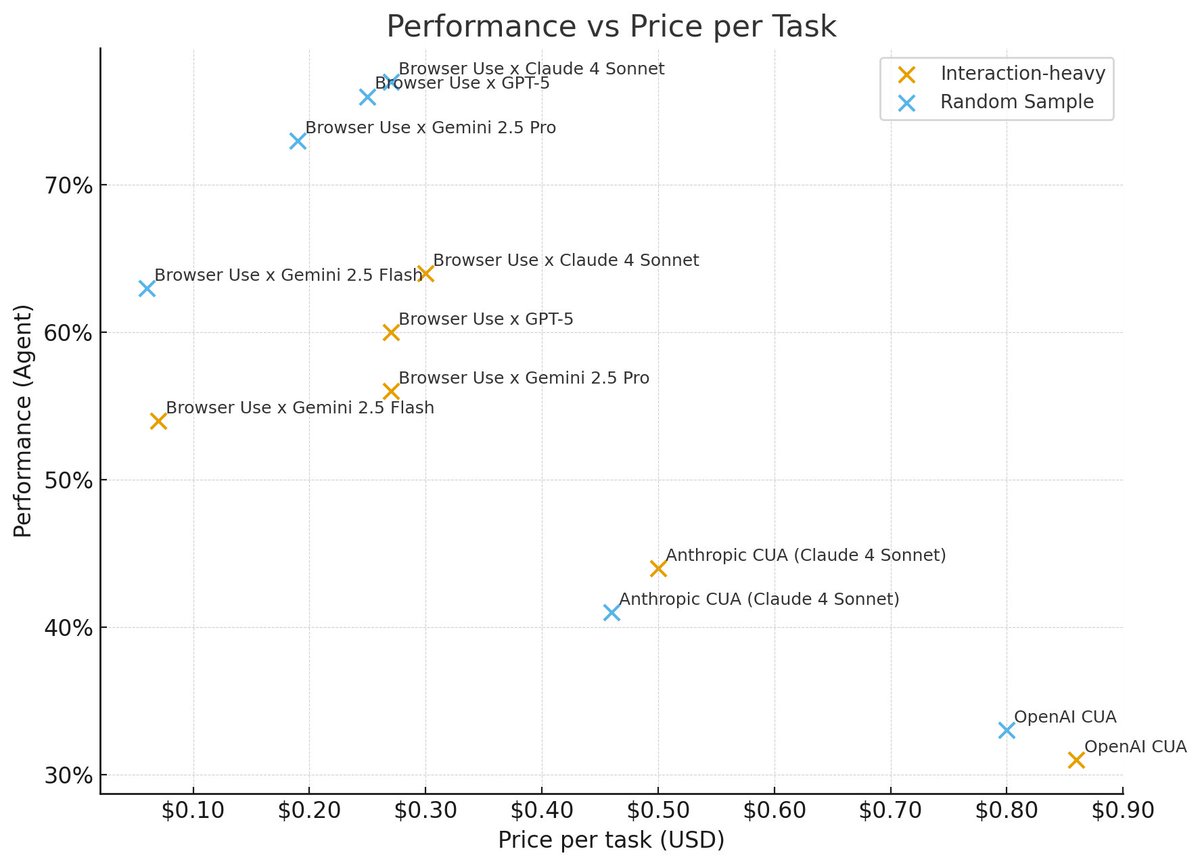
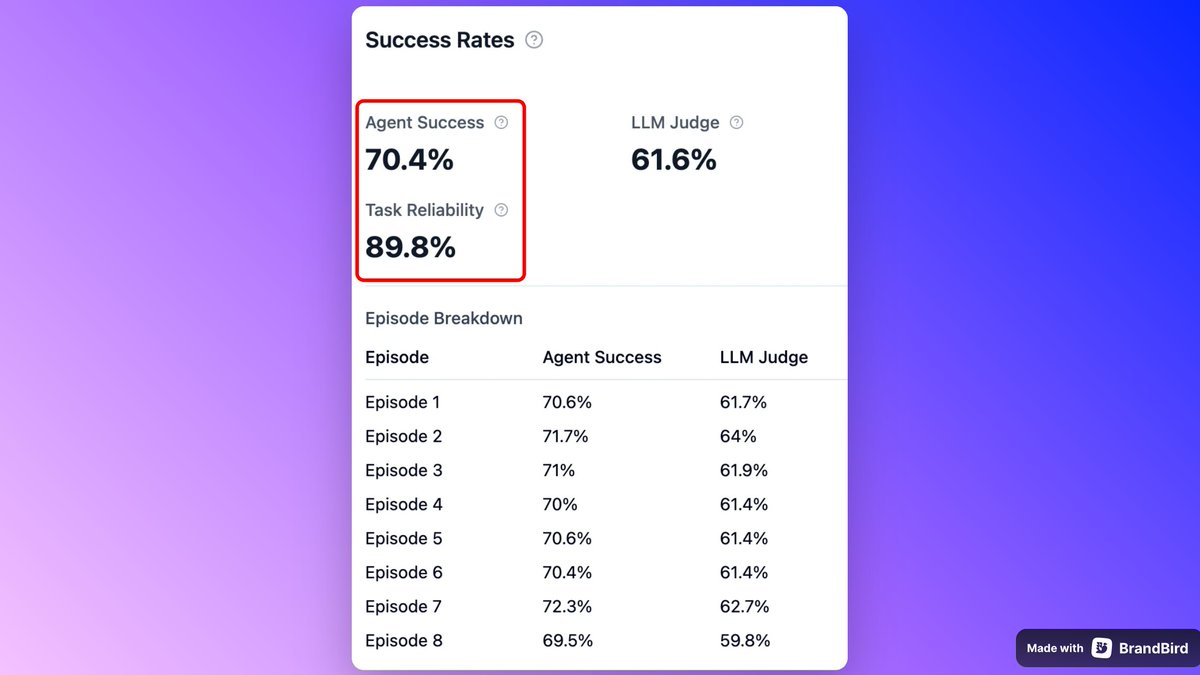
ALT Evaluation dashboard comparing per-episode pass rates for ~1k web tasks over 10 episodes using BrowserUse with Gemini 2.5 Flash. Bar chart shows ~70% mean per episode. A separate ‘max across episodes’ line indicates ~90% if cherry-picking best runs, highlighting the gap between pass@1 and best-of-10.




ALT agent evals, evaluation, simulation, openai, o3, o4-mini, browser agent, desktop agent, performance, agent benchmarks
