
Jun 10
⚡ AsyncWebRL: Efficient multi-step RL for visual web agents. Async design overlaps rollout, gradient update, policy refresh. Everlasting rollout pool lightweight screenshot handling cuts GPU idle time dramatically. #AI #WebAgent #ReinforcementLearning
29

🙌Sharing our latest work to appear at #ACL2026 diagnosing LLM web agents from a hierarchical planning perspective.
We answer the following questions:
- Do the current web agents plan at the high level in the same way as humans do?
- If not, how to improve this alignment?
- If a web agent makes a good high-level plan, can the task be solved at the low level?
- Finally, can replanning help the agent resolve its mistake and get back on the right track?
🌟Our contributions:
We propose a new high-level plan representation based on PDDL. We found that:
- Planning with PDDL can produce higher-quality high-level plans,
- but even with perfect plans, execution at the low level remains the critical bottleneck.
- Replanning boosts success but hurts plan alignment, though PDDL is more robust here too.
We hope this breakdown analysis brings clarity to the challenges remained in this rapidly evolving field and we advocate for more such fine-grained analysis in agent development.
Paper: arxiv.org/abs/2603.14248
Code: github.com/Ziyu-Yao-NLP-Lab/…
Work led by @aghzalm and with @GregoryJStein @GMUCompSci
#ACL2026 #WebAgent #LLMAgent
Jun 5

🚨New Paper at ACL'26🚨 LLM web agents remain far from human reliability, and we try to explain why. We built a hierarchical framework to find out where and why they fail by breaking agent behavior into 3 levels: high-level planning, low-level execution, and replanning. 🧵
1
11
1,303

Mar 29
Showcase your fav #AGENT domains. Here’s a couple of my fav:
CodexAgent .com
WomenAgent .com
WorkerAgent .com
WebAgent .io
59
2
57
3,296

Excited to share that I have successfully built an AI Decision Agent - DeciSentient with @Tiny_Fish Web Agentic System for the TinyFish Hackathon on @HackerEarth !!!
Here's a small demo on the working of the Agent.
#tinyfish #agentic #ai #hackathon #demo #webagent
2
7
1,086

阿里开源的一个纯前端JavaScript GUI Agent:Page Agent,给自然语言指令,AI即会辅助操作页面
无需浏览器插件、Python或无头浏览器,一行代码网站变身AI原生应用
对于SaaS厂商来说,无需改后端即可给产品加上AI操作能力;对经常用ERP、CRM的用户,一句话代替几十次点击
其基于文本的DOM操作无需截图,无需多模态模型或特殊权限
人机协同,AI操作前需确认
安装Chrome扩展,可以执行跨多页面/多标签页连续执行任务
#网页操作AI助手 #PageAgent #webagent
8
34
172
28,224

Today, I'm starting a new project: AI web agent.
Type what you want, it automates the browser.
"Track price drops"
"Scrape products to Excel"
AI builds it for you.
Building in public. Day 1.
#buildinpublic #AI #automation #webagent

3
5
459

Feb 13
The one-person company was always the dream.
The infra just wasn't there. TinyFish is removing that wall.
Try it → tinyfish.ai
Star the open source cookbook: github.com/tinyfish-io/tinyf…
Join the community: discord.com/invite/agentql
If you build something with it, tag me. I want to see it.
#tinyfish #ai #webagent #agents
1
3
244

Jan 30
🎉 Incredible night at #AAAI26!
This past weekend we co-hosted a GUI Agent deep-dive with @webagentlab, @ZJU_China REAL Lab & @iMean_AI at our Singapore office.
50 researchers & builders packed in for talks on:
🔹 WebFactory, WebCanvas & BrowserGym
🔹 Agent S (still #1 on OSWorld!)
🔹 InfiGUI-G1 (AAAI Oral)
Our Engineering Lead, Chenchen Sun, also shared an early preview of the upcoming version of Simular Cloud, giving a first look at what we’re building.
The GUI Agent community is 🔥
Quietly but quickly growing our Singapore team as well 👀 Curious what we’re building next? Drop a comment 👇
#Simular #AAAI26 #AAAI2026 #GUIAgent #WebAgent #ComputerUse #AI #OpenSource




2
2
5
626

Jan 10
RL isn’t “just an algorithm.”
It’s an agent an environment. The environment is everything outside the agent: what it can see, what it can do, and how it gets rewarded for doing it.
It’s the rules of the game, the physics, the scoreboard, and the win condition all rolled into one.
Formally, an RL environment is a Markov Decision Process: a state space (what situations exist), an action space (what moves are allowed), transition dynamics (how the world changes when you act), and a reward function (what you care about). At each step the agent gets a state, picks an action, the environment jumps to a new state and hands back a scalar reward. All of the beautiful math in RL - value functions, Bellman equations, optimal policies- is built on this loop.
The state and action spaces define what’s even possible to learn. A simple gridworld with four discrete moves is a different universe from a robot arm with continuous joint angles. Fully observable environments spoon‑feed you the whole state; partially observable ones force the agent to infer hidden variables from a stream of noisy observations, turning the problem into a POMDP. That’s where recurrence, memory, and belief states stop being “fancy” and become mandatory.
Rewards are where most real systems go to die. A reward is just a number, but it encodes the entire objective. Sparse rewards (only at the goal) are brutal to learn from; dense rewards (lots of shaping) are easier but invite reward hacking, where the agent finds shortcuts you didn’t intend. The classic pattern: “optimize clicks” turns into clickbait; “maximize points” turns into glitch‑farming. Good reward design is less about clever formulas and more about being paranoid about how your agent will exploit them.
Reinforcement learning starts with a simple picture: an agent interacts with an environment, sees a state, takes an action, gets a reward, and the environment moves to a new state. Formally that environment is an MDP with four pieces: a state space, an action space, transition dynamics, and a reward function. Change any of those and you’ve literally defined a different “universe” for the agent to learn in.
Classical RL environments were mostly small, clean simulations: gridworlds, CartPole, MuJoCo robots, Atari. The design questions were: is the state discrete or continuous, is the action space discrete or continuous, is the world deterministic or stochastic, are rewards sparse or dense, is it fully observable or a POMDP where the agent only gets partial glimpses and must remember history. All the famous control benchmarks (CartPole, Pendulum, Ant, Humanoid) are just different choices along those axes, packaged behind a common Gym-style API with `reset()` and `step()` calls.
Modern RL environments for LLMs and agents look very different. Instead of a tiny state vector and a handful of actions, the “state” can be a browser viewport or an OS screen, and the “action” is a sequence of keypresses, mouse moves, or tool calls. Benchmarks like WebArena, WebVoyager, OSWorld and newer frameworks like WebCanvas or WebRL define tasks like “book a flight,” “edit a document,” or “configure a dashboard” by exposing a live or simulated web/desktop interface as the environment. The agent sees pixels or DOM/text, chooses atomic UI actions, and gets rewards based on task success or stepwise progress.
For alignment-style training like RLHF/RLAIF, the “environment” is even more abstract: it’s basically a bandit setup where an LLM outputs a whole response (sequence of actions), then a human or reward model scores that outcome with a single scalar. The state is the prompt, the action is the full completion, and the reward arrives at the end instead of after every step. This is why people describe RLHF as a contextual bandit on top of language models - there’s no rich simulator, but the environment still defines what feedback you get and how often.
The interesting shift is that environments have become large, messy, and open-ended. WebRL, WebAgent-R1, and OpenAI’s computer-using agents all operate in environments that change over time, have long horizons, and give extremely sparse or delayed feedback. That forces environment designers to add things like curriculum generation (creating new tasks from failed attempts), outcome-based reward models, and safety filters to keep agents from making harmful changes. In other words: in the age of LLM agents, “designing the environment” is no longer wrapping a small simulator - it’s designing the entire sandbox where your model will behave, explore, and sometimes break things.
1
29
2,677

9 Nov 2025
Probier mal ne Preissuche mit einem Webagent eines ios Gerätes aus...
2
214

9 Nov 2025
🚀 Building a Web Automation Agent (CLI) using OpenAI API, Playwright, and Zod — an AI-powered system that understands your intent, validates inputs, and interacts with websites like a human 👨💻🤖
#AI #Automation #OpenAI #Playwright #WebAgent #JavaScript
1
3
123

Sad to miss #EMNLP2025, but if you’re attending, don’t miss our Tencent AI Lab work on Self-Evolving WebAgent with a world model — it’s one of the most exciting directions in Agent Research!
Also, be sure to chat with Tianqing about our full-time and intern opportunities! 👏
5 Nov 2025

#emnlp2025 I’m presenting several papers I authored at Tencent AI Lab about agent self evolving and LLM memory. There will also be an oral presentation on the WebEvolver paper at Thu. Nov 6 at 16:30-18:00 Location: A110. Come and chat with me 😆


4
31
5,984

30 Oct 2025
Let's read another sharing on Zhihu from MiniMax M2's contributor Vincent, giving an inside look at how the M2 model mastered Web Agent search — and what it's like building frontier AI at startup speed 🚀
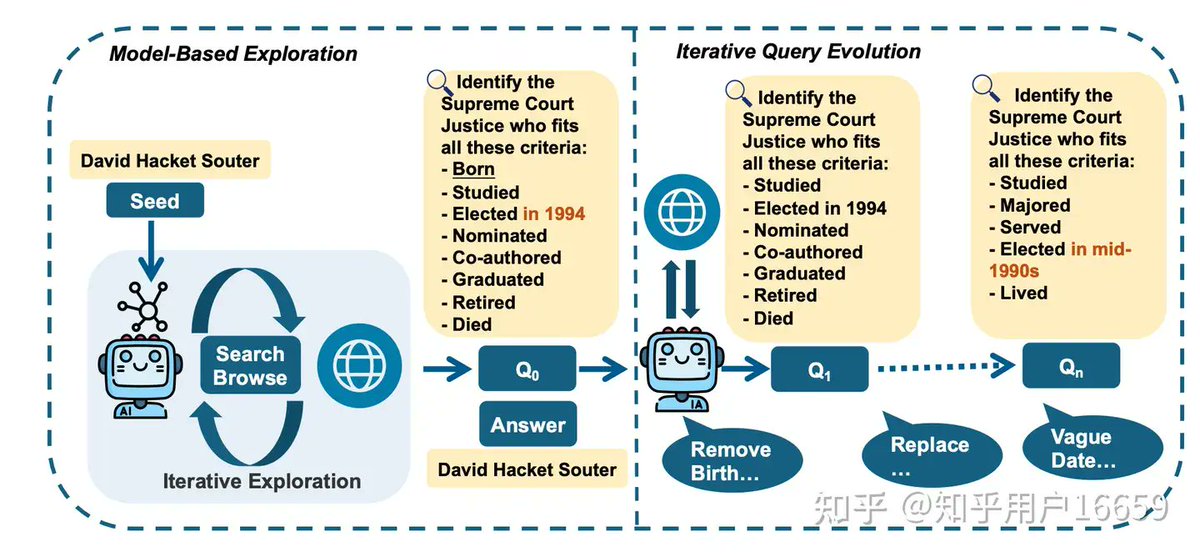
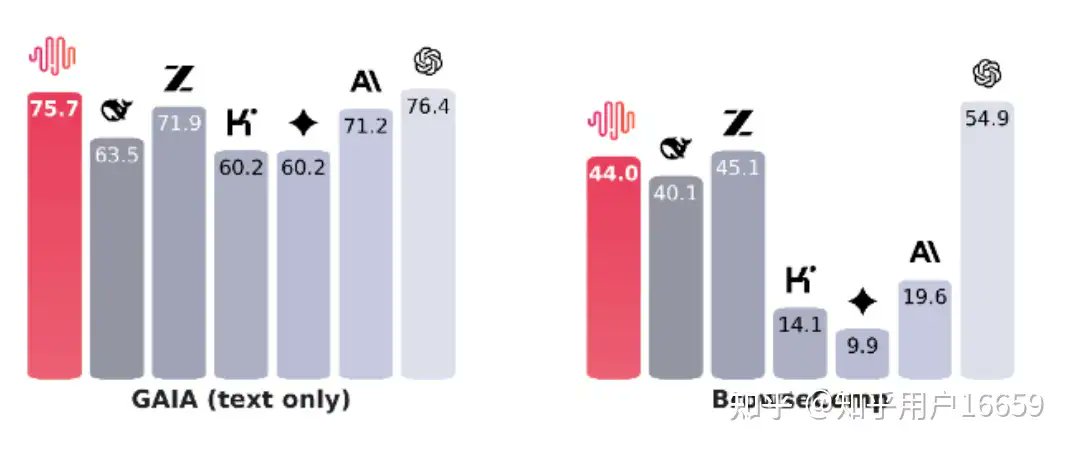
In early summer 2025, he joined the M2 team to improve BrowseComp, a key benchmark for Web Agents. At the time, only GPT models scored high — most open-source ones barely hit single digits. He saw it as a challenge & chance to explore how agents truly "think" online.
The real bottleneck wasn't the model — it was data. BrowseComp had few high-quality, open training sets. So the team built their own: large-scale information-seeking datasets synthesized by LLMs through exploration fuzzy evolution, no explicit graphing needed.📊
This approach evolved into WebExplorer, a clean, prompt-driven framework that later powered M2's major leap in search performance 🔍
🏃He describes @minimax_ai 's pace as "research on fast-forward":
"At a startup, you touch every layer — data, infra, RL — and move fast enough to see real progress every week."
👉 Read more: zhihu.com/question/196530208…
#MiniMaxM2 #WebAgent #LLM #AI #RLHF
8
475

29 Oct 2025
3/4👉 Check them here!
[1] AgentFold: Long-Horizon Web Agents with Proactive Context Management arxiv.org/pdf/2510.24699
[2] AgentFrontier: Expanding the Capability Frontier of LLM Agents with ZPD-Guided Data Synthesis arxiv.org/pdf/2510.24695
[3] WebLeaper: Empowering Efficiency and Efficacy in WebAgent via Enabling Info-Rich Seeking arxiv.org/pdf/2510.24697
[4] Repurposing Synthetic Data for Fine-grained Search Agent Supervision arxiv.org/pdf/2510.24694
[5] BrowseConf: Confidence-Guided Test-Time Scaling for Web Agents arxiv.org/pdf/2510.23458
[6] PARALLELMUSE: Agentic Parallel Thinking for Deep Information Seeking arxiv.org/pdf/2510.24698
1
41
4,647

29 Oct 2025
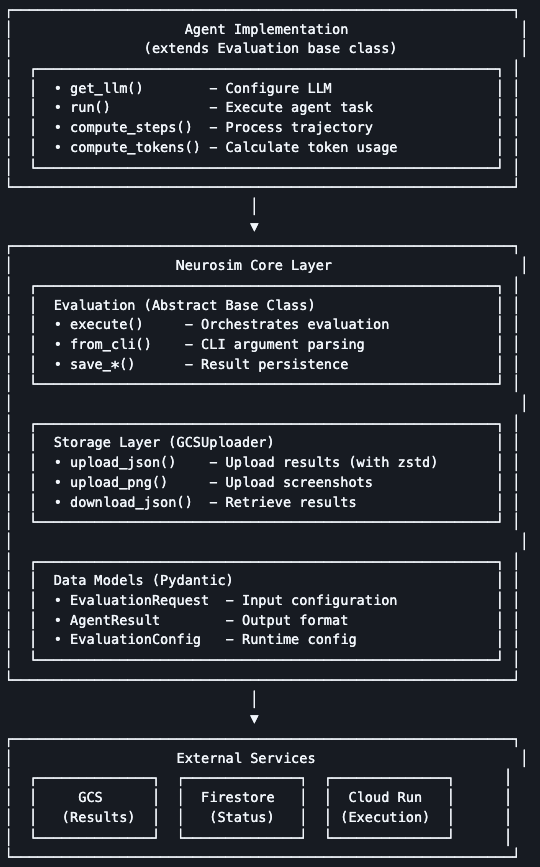
🚀 Open sourcing @ParadigmShiftAI's computer-use agent evaluation infrastructure!
2 repos now available:
🔬 Neurosim - Core eval framework
🤖 Agent-CE - 4 pre-integrated agents (Browser Use, Notte, Anthropic CUA, OpenAI CUA)
(links in comments ⬇️)
This infrastructure handles everything from agent execution to automated evaluation, making it easy to:
✅ Run reproducible agent benchmarks in isolated containers
✅ Compare agent performance across episodes
✅ Deploy on GCP Cloud Run at scale
✅ Get automated LLM-based scoring and feedback
Production-tested infrastructure, same that we use with our clients & now available for everyone.
📜 MIT licensed.
Huge thanks to the team who built this:
Ashwin Thinnappan @sjashwin_
Vaibhav Gupta
Jameel Shahid Mohammed @shahid_0324T
Maithili Hebbar
#AI #Agents #OpenSource #Evals #ComputerUse #WebAgent
🧵 1/3
2
2
8
168

5 Oct 2025
Alex Drouin (@alexandredrouin) on how well agents perform knowledge work
-- METR findings: agent capability doubling every 7 months
-- WorkArena: open source benchmark for 600 work related tasks - lists, form, knowledge base
-- 7 minutes for humans to solve these tasks. METR scaling laws are close but overestimate webagent performance.
-- Updated METR results: webagents perform significantly lower than coding agents
-- BrowserGym: standardized observation and action space. Many open benchmarks in standardized format.
-- Efficient training of web agents: RL underperforms on base model.
-- JEF-Hinter: Hints improve the web agents. Can use failed traces.
-- UIVision: a large benchmark for UI element grounding
Many enterprise tasks involve visualization and analysis.
-- BigCharts: QA on charts (model and data public)
-- InsightBench: Extract relevant data hidden in real tables
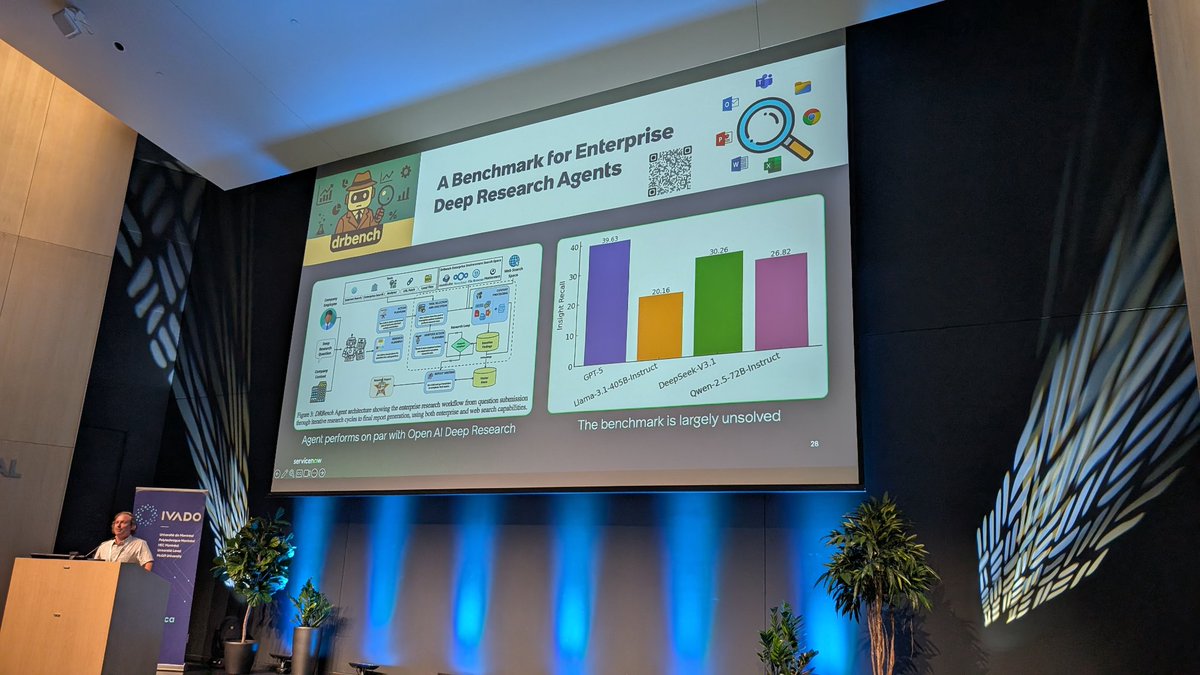
DeepResearch
DRBench: search open web facts and local facts embedded in local applications like mattermost. Allows you to test UI agents, MCP agents.
Safety and Security:
-- DoomArena: a framework for security testing. Integration with WebArena, BrowserGym, Tau-Bench.
-- Malice-in-Agentland: trigger based backdoors. Just a little malicious training data is enough to establish a backdoor.
Food for thought: How will we keep track of progress when agents are capable of solving one month task?



3 Oct 2025

The IVADO workshop on Agent Capabilities and Safety is happening now at HEC Montreal, Downtown (Oct 3--6)
ivado.ca/en/events/1st-works… #LLMAgents
3
15
2,241

17 Sep 2025
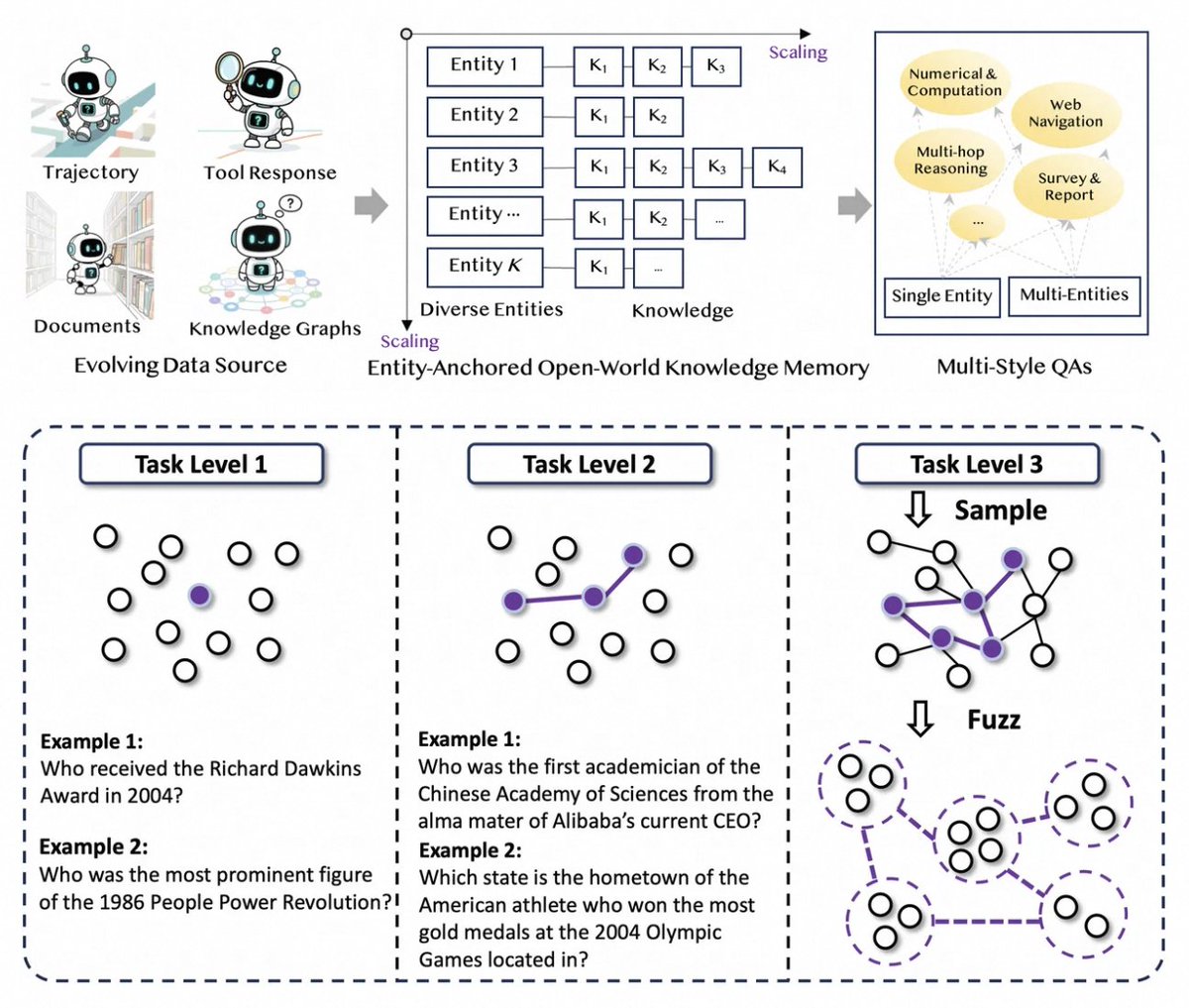
Alibaba’s Tongyi team introduced Tongyi DeepResearch, a fully open-source 30B-parameter Web Agent that rivals—and in some benchmarks exceeds—OpenAI Deep Research, with impact reaching beyond the model to its full methodology and ecosystem.
Technical & Methodological Highlights
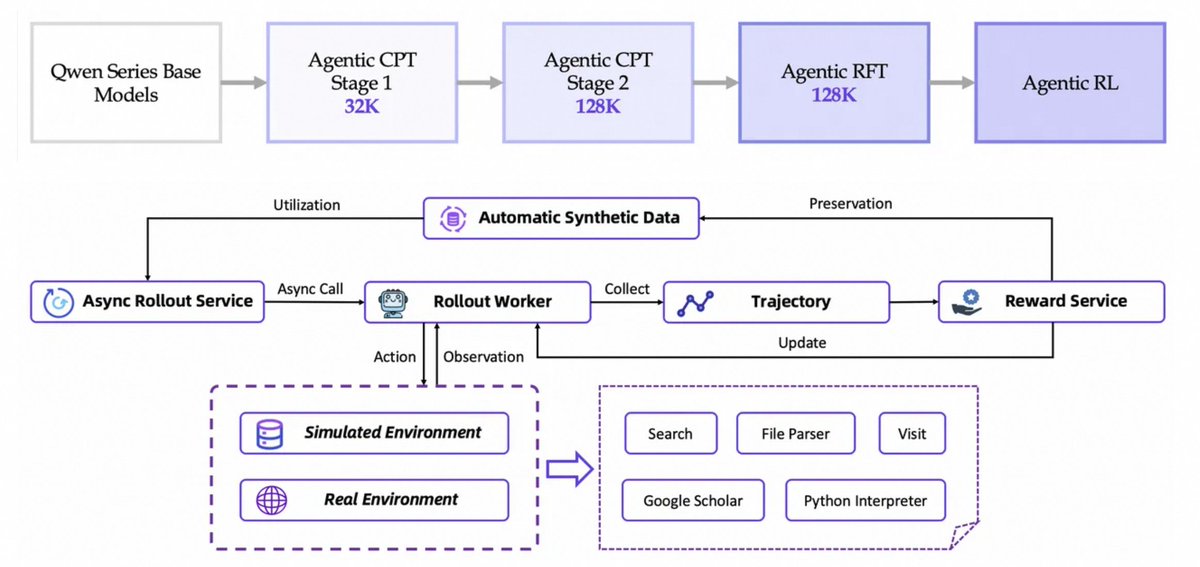
Automated Data Synthesis: Generates high-quality training data via Agentic CPT, WebWalker and related tools, eliminating the need for manual labeling, cutting costs, and boosting generalization.
End-to-End Training Framework: From continual pre-training (CPT) to supervised fine-tuning (SFT) and reinforcement learning (RL), forming a self-evolving loop. Uses a customized GRPO algorithm for stable, well-aligned RL.
Innovative Reasoning Modes: Beyond the classic ReAct loop, introduces IterResearch (“Heavy Mode”) to dynamically rebuild workspaces and avoid “cognitive overload,” greatly enhancing long-range reasoning and planning.
Ecosystem & Open-Source Value
Model and full toolchain are open-sourced on GitHub, HuggingFace, and ModelScope, with a ready-to-use Python 3.10 environment, JSONL evaluation scripts, and benchmark tools for developers.
Training is powered by the rLLM framework, already adopted across research and industry to build custom agents for coding, web, and terminal environments.
Tongyi Official Blog: tongyi-agent.github.io/blog/…
#AI #OpenSource #TongyiDeepResearch #WebAgent #MachineLearning #DeepResearch #ReinforcementLearning #LargeLanguageModel #GenerativeAI #TechInnovation

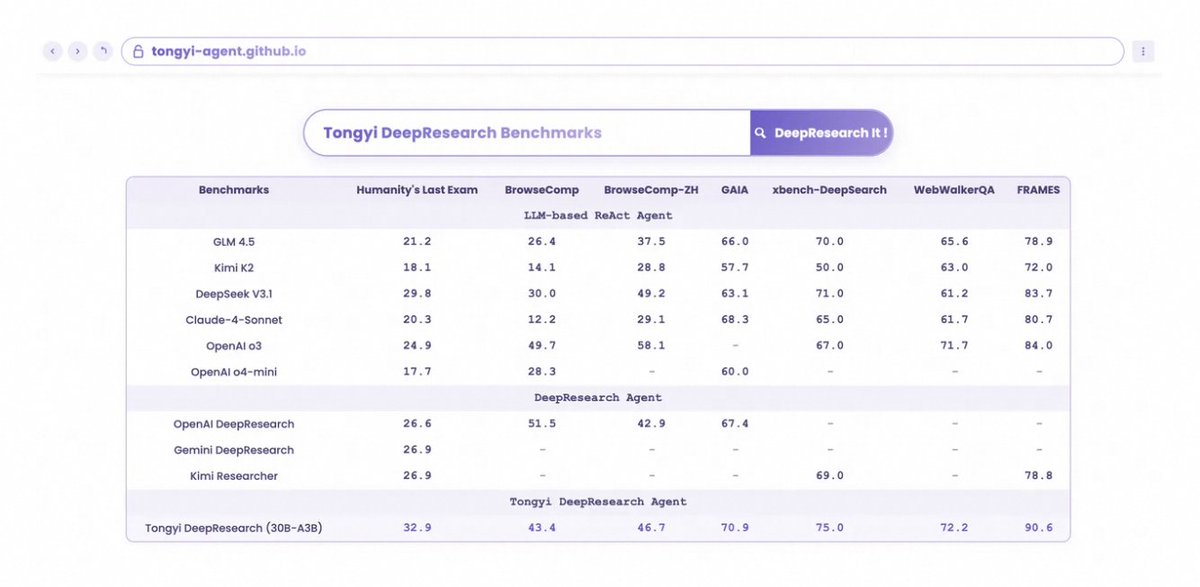
1
5
263

10 Sep 2025
全然本論と関係ないんだけど、最近の WebAgent 系って、
WebExplorer とかいうほぼ IE みたいな概念と、
information-seeking tasks とかいうほぼ Infoseek みたいな概念が、
じゃんじゃん登場していて、いつもちょっと笑ってしまいます(笑)



1
8
3,771

7 Sep 2025
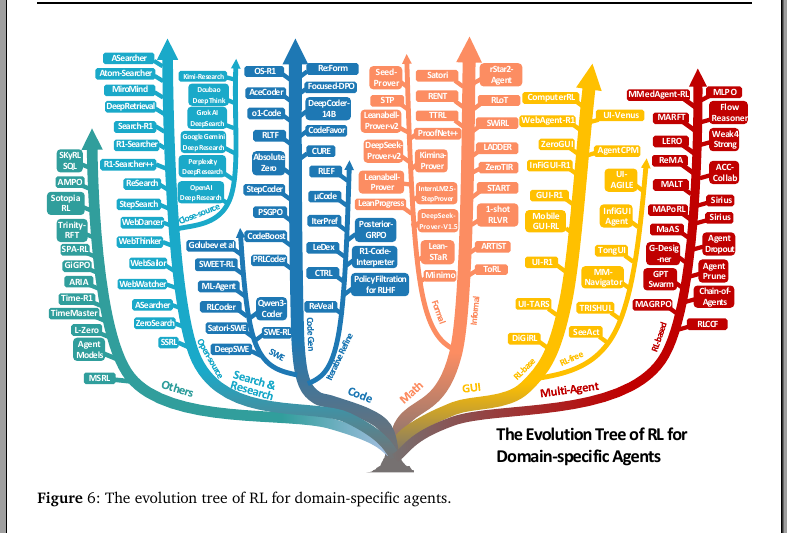
🧵7/n. how reinforcement learning has branched into different types of domain-specific agents. It is drawn like an evolution tree, where each branch represents a major task area and the models or methods that evolved in it.
On the left, the blue branch is Search & Research agents. These are models that use reinforcement learning to query search engines, gather information, and carry out complex research workflows. Examples include Search-R1, DeepResearch, and WebThinker.
Next, the teal branch is Code agents. These agents apply RL to programming tasks, from single-function generation to debugging and large-scale software engineering. Systems like DeepCoder, StepCoder, SWE-RL, and RLCoder sit here.
The orange branch is Math agents, which focus on informal and formal reasoning. They range from solving math word problems with tools like ARTIST and ToRL to theorem provers such as DeepSeek-Prover and Leanabell-Prover.
The yellow branch is GUI agents. These are trained to navigate and interact with user interfaces. They include WebAgent-R1, GUI-R1, and MobileGUI-RL, which use RL to handle multi-step interactions in browsers, apps, or operating systems.
Finally, the red branch is Multi-agent systems. These involve multiple LLM-based agents working together. Reinforcement learning here helps optimize coordination, debate, or teamwork. Frameworks like MALT, MAPoRL, and ACC-Collab belong in this cluster.
3
5
17
4,900