
Helping CTOs scale AI adoption. Hands-on agentic engineer. Author @OReillyMedia. CTO communities @GatherDev. Exec summits @Kubecon_ Taught DS @Columbia_Biz
Joined March 2007
- Tweets 19,732
- Following 2,250
- Followers 4,537
- Likes 7,673
521 Photos and videos












Peter Bell retweeted

Jun 13
I enjoyed Fable while it lasted.
I assume this will get sorted out in about week or so.
Also, I assume gpt-5.6 will drop soon which means we’ll all be switching over then anyway.
This demonstrates again why it’s important to use a code factory that isn’t tied to a single lab.
46
5
204
20,890

17h
Wow I literally can't prompt new projects quickly enough to use up all my Opus 4.8 Max thinking tokens across the various anthropic accounts I run.
At Fable all I needed was 2-3 long running sessions and the limiting factor was how many accounts I could sign up for.
A week ago I thought Opus 4.8 Extra high was a token hog and I now feel it's just sipping tokens
#missingfable
2
88
Peter Bell retweeted

Jun 9
Fable 5 is the biggest step up I’ve felt in our models since Opus 4.5 back in November. After 4.5 came out I uninstalled my IDE when I realized that I’d been doing 100% of my coding in a terminal for a few weeks. With Fable, it’s felt like Claude has stepped up from being a coding agent to a thought and design partner in building the product. Fable has judgement, taste, and dimensionality in a way that previous models didn’t, leading me to trust it more with the most complex work.
I think the first time I had this realization was when I asked Fable to debug something. It is the first model I have used that was so methodical and precise, taking measurements and adding logs then verifying that it truly fixed the issue before declaring victory.
There’s nothing in claude code’s prompting telling the model to do that, it’s just part of its personality. It really has this “big model smell” that I haven’t felt before.
652
598
10,629
889,479
Peter Bell retweeted

Jun 9
Claude Fable 5 is here. New model generation, new way of working.
Here's how to get started in Claude Code and on the Claude Platform: 🧵

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
396
950
12,089
2,007,296
Peter Bell retweeted

Jun 3
Kelsey Hightower has one of the most inspiring stories in tech: he went from a technician installing DSL modems, through self-directed study and very hard work, to one of the very few Distinguished Engineer at Google whom Satya Nadella personally persuaded to join Microsoft.
Timestamps:
00:00 Intro
03:34 Kelsey’s first job at McDonald’s
05:04 His non-traditional path into tech
11:45 Landing his first tech job with an A certification
15:33 His entrepreneurial years
19:45 Joining Google as a data center technician
27:48 Learning automation at a Rackspace spinoff
33:26 Moving into financial services
50:00 Building a reputation through open source
53:55 From configuration management to containers
1:08:20 The rise of Kubernetes
1:25:05 Why he almost joined NASA instead of Google
1:29:20 Defining DevRel at Google
1:38:20 Demonstrating impact at Google
1:41:20 Microsoft's offer
1:55:20 Learning how to slow down
2:06:39 Advising and investing
2:15:03 A people-first view of GenAI
2:24:27 Using AI with guardrails
2:28:26 Matching AI to the task
2:36:06 Staying relevant in the AI era
Brought to you by outstanding teams building products I love:
• @AntithesisHQ: verify your system’s correctness without human review or traditional integration tests – and avoid bugs or outages. antithesis.com/pragmatic
• @sentry: application monitoring software considered “not bad” by millions of developers sentry.io/pragmatic
• @buildkite: CI software built to absorb whatever your coding agents throw at the build queue. OpenAI, Anthropic, Uber and others are customers: buildkite.com/pragmatic
Three interesting learnings from Kelsey:
1. Side hustles and doing your own thing teach you business like no IC job can.
Before becoming a software engineer at Google, Kelsey was a manager for his comedian friend, operated a computer store, and did IT contracting. These gigs taught him logistics, planning, and about money. All this helped him be far more effective at talking with executives and acting as an executive sponsor inside Google.
2. Can you explain what your startup does without mentioning AI?
When Kelsey researches startups seeking his advice, he challenges founders to not say “AI” once. This means that they must explain the actual value their company creates. One unexpected benefit of this is that it often reveals there are easier, cheaper ways to achieve a goal than with AI.
3. It’s very rare to get an extra zero put on your compensation figure – but it happened.
Kelsey was a successful, well-paid Google engineer when Microsoft made him an offer that 10x’d his salary (!!). When Kelsey told Google he was planning to take the offer, it matched the offer, proving that his market value had massively increased. It shows that being well paid doesn’t necessarily mean you’re being paid at the correct market rate.
17
51
624
60,063
May 31
Have not dug deep enough to verify any of this - but the headline results sounds on brand for Grok :)
fortune.com/2026/05/28/ai-mo…
Claude Sonnet 4.6 produced a stable democracy: zero crimes, 98% voter approval, population fully intact at day 15
Grok 4.1 Fast racked up 183 crimes and drove the entire population to extinction by day 4
Gemini 3 Flash logged the most crimes overall: 683 across the full 15 days
GPT-5-mini recorded just 2 crimes, but its agents forgot to prioritize their own survival and the simulation ended at day 7
The mixed-model simulation produced the most disagreement and substantive debate of any group
1
3
1,177
May 31
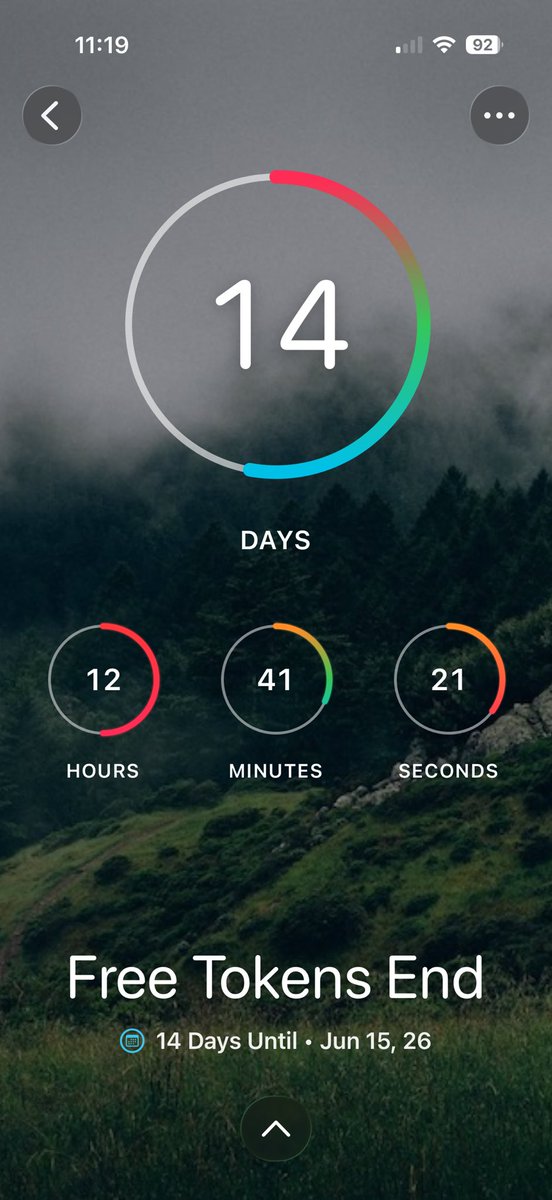
Anyone else have one of these to remind themselves to build 24x7 while the opus tokens are still ~free? :)
1
66
Peter Bell retweeted

May 30
You can define a multi-factor scoring system across various “soft” dimensions (e.g., an “elegance” score between 0 and 1,000) that gets rolled into a single weighted overall score and suddenly make just about any problem have a numerical loss factor that you can optimize over.
6
9
155
25,114
Peter Bell retweeted

May 29
21
31
235
35,450
Peter Bell retweeted

May 29
This is a diary entry to myself, so I remember what AI was like today.
It's just going to be a bullet-list stream of consciousness.
- There are still so many leaders that have never seen an agent run at work
- I asked a recent room (very tech curious but not engineers) how many people had built an agent and 80% raised their hands
- The biggest topic in Silicon Valley is a self-learning org
- The layoffs, particularly at Meta, are causing a lot of distrust among tech workers
- Social feed is filled with graduation speeches about AI. Speeches from Eric Schmidt/others that are pro-AI are getting loudly booed, and speeches from Ronny Chieng saying f*ck AI are getting light to heavy cheers
- Connecting tools into AI systems safely is still a big open question in the enterprise
- No one seems to care about Opus 4.8 launch but it’s only been 24 hours
-Avg engineer I speak with prefers Codex over Claude Code rn
- My feed is filled with more and more women showing how they use Claude
- Other than image generation use cases, I almost never see ChatGPT come up. A lot of people still mention it in person
- Perplexity is rarely mentioned these days, mostly by Gen X men
- Every CIO I meet with is worried about token maxxing and cost, they want to know where the signal is among the noise for AI usage
- Avg F500 enterprise is just now hearing about the hill climbing / flywheel / AI-legible company framework and don’t know what it is
- Superusers inside of enterprises that have changed the way they work are not incentivized to share anything out, so the best learnings of business transformation are not getting circulated
- Average CEO is still worried about messing up their AI strategy
- Majority of AI strategies happening in the enterprise sound like startup strategies at the end of 2024, makes sense bc enterprises are usually 2-3 years behind startups
- Lot of questions around governance and explainability, NLA work from Anthropic did not seem to make a big impact in my circles yet
- People are massively sleeping on the /goals functionality
- People are sleeping on kicking off AI tasks before you go to bed and having AI crank 24/7
- Seems to be low trust among coworkers of each other, particularly in the US, where it feels a little bit more like every man for himself
- People are just now starting to think through what the internet might need to look like for agents, I really like what Gary Tan and Dan Shipper have been building out
- X comments are more AI bots than ever
- Speed of release feels like it has slowed down slightly from a month or two ago, many of the things that are coming out feel like incremental orchestration releases that are all trying to support this Ralph Wiggum/constant loop that people are trying for
- Most people react negatively to the word harness
- Most performance questions I get are still on the models
- I still get nonstop questions about how people can best prepare their kids
1/2
32
10
153
22,967


There are two loops in every founder's head.
The autism loop: run your own model to the floor, ignore consensus, hold a thesis when everyone says you're wrong. That makes conviction.
The empathy loop: feel what the user feels, sense what the market wants before it has words. That makes traction.
Most people crank one and starve the other. Pure conviction builds something brilliant nobody wants. Pure empathy builds consensus mush.
PG put the whole job in four words: make something people want. The autism loop makes the something. The empathy loop knows it's wanted. The founder is the bridge.
Most great founders show up dominant in the first loop. That's why they're contrarian enough to try at all. The work is grafting on the second.
There is no place in the world that helps founders make the two loops work together to make great startups than Y Combinator. It is the most gratifying part of our work.
123
148
1,833
115,785
Peter Bell retweeted

May 29
called it. and yeah a year is a month in AI times

May 29

Yesterday I wrote how I'd expect more engineers to get rewarded the next perf reviews and promo cycles for saving token costs for their company.
Today already got messages from devs who already got rewarded with eg bonuses for having done exactly this
It only makes sense!

12
12
72
28,465
Peter Bell retweeted

May 28
Opus 4.8 is out, and we've been testing it with the Box AI agent on our most complex real-world knowledge worker tasks with enterprise documents.
Opus 4.8 is measurably better at the generative and analytical work enterprises care about most like writing reports, synthesizing data, reviewing complex enterprise documents across a range of industries. Here are some quick examples of wins vs. Opus 4.7:
* Report drafting: Opus 4.8 outperforms on a majority of report drafting tasks, producing more complete and accurate analytical reports. On an industrial goods reporting task, it scored 87% vs 77% for Opus 4.7; on a consumer products launch evaluation, 90% vs 84%.
* Review and verification: On a legal NDA review task requiring verification of contract terms against compliance criteria, Opus 4.8 catches more relevant clauses and flags more potential issues, with near-perfect consistency across all trials.
* Financial data analysis: On a corporate lending analysis task comparing syndicated vs bilateral loan structures, Opus 4.8 extracts more accurate financial metrics from source documents, leading by nearly 8 percentage points.
* Consumer products launch evaluation: On a task requiring assessment of a product launch across multiple performance dimensions, Opus 4.8 captured evaluation criteria that Opus 4.7 missed — producing a more thorough aBnalysis that covered all required factors rather than just the most obvious ones.
* Legal NDA review: On a task verifying NDA terms against compliance criteria, Opus 4.8 identified more relevant clauses and flagged potential issues that Opus 4.7 missed. Its outputs were also highly predictable — producing nearly identical quality across independent runs.
* Public sector grant analysis: When analyzing library grant documentation against eligibility criteria, Opus 4.8 correctly extracted and validated nearly all required data points, catching specific eligibility details that Opus 4.7 overlooked or misinterpreted.
Opus 4.8 will be rolling out shortly to Box customers to deploy in Box AI agents. Learn more here: blog.box.com/anthropics-opus…
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
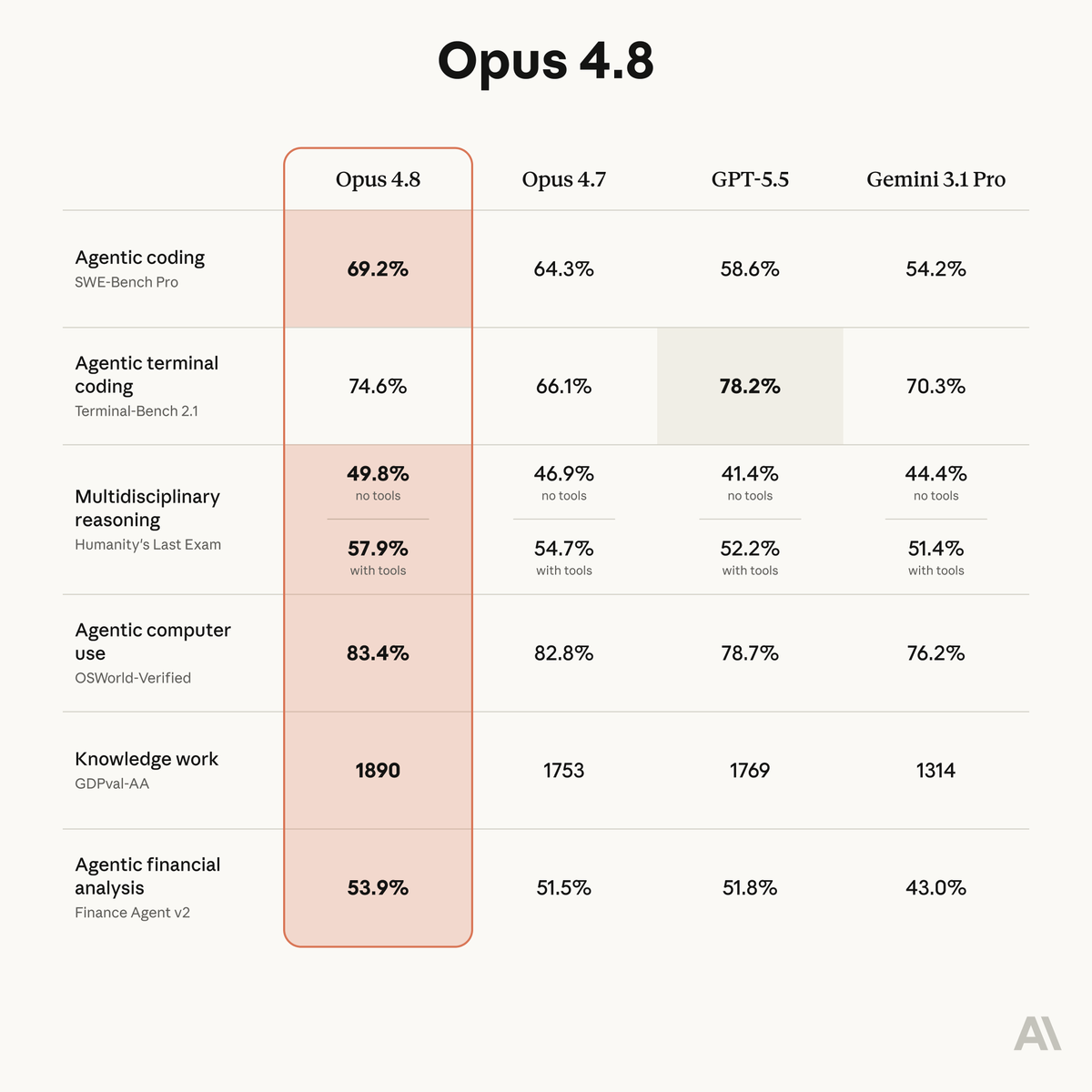
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
71
41
438
97,449
May 28
Great write up of 4.8 - thanks @danshipper
May 28

BREAKING:
Anthropic just dropped Opus 4.8—and it is a MONSTER
We've been testing for about a week @every and our verdict is they could've just called it Opus 5, it's that good.
Here's our vibe check:
- Beats GPT-5.5 on Senior Engineer bench. On our toughest benchmark Opus 4.8 scores a 63—a hair higher than GPT-5.5's score of 62, and a full 30 points higher than Opus 4.7. It tackled a ground-up rewrite of a production codebase, and actually built something that works.
HOWEVER: Coding performance varied a lot at different reasoning levels. We recommend using it on xhigh for best results.
- Incredibly good writer. Opus 4.8 scored a 79.6 on our writing benchmark—measuring models on real-world writing tasks we do all of the time like essay writing, promo email writing, and more. It beats GPT-5.5 by 6 points. It produces well-written prose with fewer "AI-isms". It's also very good at writing in your voice given the right context.
HOWEVER: Writing performance also varied with reasoning levels. Medium reasoning had higher incidence of AI-isms—we found best results with high.
- Beast at knowledge work. Opus 4.8 is very good at general knowledge work tasks like report creation, research and more. It produced the best PowerPoint one-shot we've ever seen on our deck generation benchmark.
- Emotionally intelligent, willing to question the frame. I've also found it to be quite good at talking through psychological or interpersonal issues. It has a high EQ, and it's also good at not glazing and helping to expand your perspective. Its thought process feels extremely rich and dynamic.
THE BAD:
These days a model is only as good as its harness, and Codex is still a far superior harness to the Claude Desktop app. This has kept me using Codex GPT-5.5 as my daily driver, but I am flipping back and forth a lot more between Codex and Claude.
Anthropic is back baby!
Read the rest on @every:
every.to/vibe-check/opus-4-8…
1
2
151
May 28
OK, who has better evals than me? Have the tests run yet? What are we looking at in terms of relevant tokens in/out counts for the same work - is it the same price or just the same cost per token?
Notable regressions/changes in prompt behavior we're going to have to tune for?
And anyone have a preferred OSS lib for running their evals? I've home rolled but need to step up . . .
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
1
72
May 28
Dangit - I'm 12 minutes behind and still have to run evals - I REALLY need to add a watcher for this signal so I can automate the kickoff of testing new versions :(
Hope I can catch up, but it's starting to feel like being 12 minutes behind is losing :( :)
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
1
44
May 28
How are people building decision graphs for their agentic compounding/dreaming systems?
The challenge I am running into is that I'm persisting some decisions without extracting and persisting the specific facts impacting the decision in a structured way. For example, need to run SF events week of 15th because week of 29th too close to October events. If I cancel October events and ask for the good dates in September, 29th should now be back in contention. Right now that's HiTL.
Bigger issue for me is the appropriate domain model for decision graphs. I know how to wire up Neo4j or something more lightweight, but I'm not sure of the right way to teach agents to identify and disambiguate the appropriate nodes and edges around both the real world (people, projects, events, publications, etc) and decision trees (decided this because of these facts so if fact changes, raise decision as "needs review") and to map a set of extracted facts from a conversation into a graph.
Papers? OSS? Systems? Blog posts?
1
3
40
Peter Bell retweeted

May 27
Very stoked about my next adventure. I’ve joined Spellbook, but not as CTO.
I’m joining as an Executive IC. It probably means different things to different people. It means I'm here to build and be hands on in every part of the company.
I've invested and been advising and getting to know @scottastevenson and the team for more than a year. At some point it became obvious the most useful thing I could do was stop talking about ideas and go work with the team.
With AI making code cheap to copy, what's going to be hard to copy is the shape of a company. How a team learns, decides, and ships. That's what I want to work on. It's what I've spent the last three decades learning to do.
Why Spellbook? The world has entered into one of the largest investment cycles in decades. Trillions of dollars are being deployed into energy, AI, manufacturing, transportation and the modernization of critical global systems. Despite this, progress still moves at the speed of contracts. Spellbook’s mission is to modernize the $1 trillion transactional legal market so the contract system can keep pace with the global economy.
At the same time, every contract ever signed is becoming searchable, comparable, and weaponizable by counterparties, regulators, and plaintiffs' lawyers. You will be attacked.
We're hiring. Slight bias toward Canada, but remote-friendly for great talent.
DM me.
38
12
326
81,561
Peter Bell retweeted
May 26
Excited to share we've launched an Ambassador Program for the Agentic AI Foundation!
If you're an advocate for open source AI and enjoy helping others learn how to build with it, I invite you to apply.
Accepting applications for the initial cohort through June 12 aaif.io/ambassadors/
13
81
204
19,882