
PhD student at MIT in Computer Science. @MIT_CSAIL @MITEECS @nlp_mit
Joined November 2025
- Tweets 87
- Following 696
- Followers 742
- Likes 1,726
7 Photos and videos






Pinned Tweet

Jun 1
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
1
9
54
13,977
Philip Schroeder retweeted

Jun 10
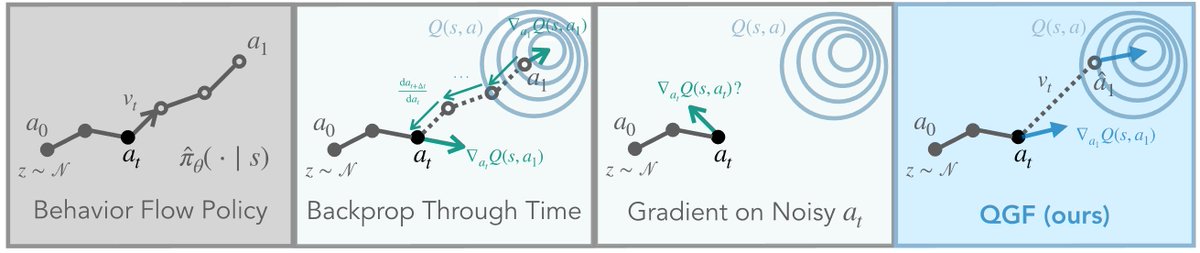
Training diffusion & flow policies with RL is hard, but training them with behavioral cloning is easy. So what if we just train flow policies with BC, and only "do RL" at test time?
We found an easy way to do this (called Q-Guided Flow), and some surprising findings👇🧵
5
25
201
24,084
Philip Schroeder retweeted

Jun 10
Today, we bring SAC to RSL-RL, one of the most widely used RL frameworks in massively parallel robot learning, developed at RSL @leggedrobotics.
We try to understand the long-standing performance gap between SAC and PPO, and crystallize important factors
sabagian.github.io/sac_relea…


PPO has long dominated robot locomotion training in simulation. SAC, despite its sample efficiency, couldn't keep up.
We analyze why:
🔗sabagian.github.io/sac_relea…
🔥Integrated into RSL-RL, our approach requires only minimal changes, making SAC a drop-in alternative out of the box.
5
21
137
10,908
Philip Schroeder retweeted

Jun 11
srly, at least the closest thing we have today.

Jun 2

The bottleneck to on-robot reinforcement learning is good, scalable reward prediction. Robometer is a massive step in that direction, and the authors have been wonderfully open as well, releasing a large dataset and continuing to improve their model post release.
Thanks to @aliangdw @yigitkkorkmaz and @Jesse_Y_Zhang for joining me and @DJiafei!
3
18
3,534
Philip Schroeder retweeted

Jun 8
Nice thread of lessons on training a reward model for real-world manipulation!
Love it when authors summarize important learnings from a project 😃
Jun 8

Our SOTA reward model for robotic manipulation. I'm very proud of this work; it was more than a year in the making. Lessons learned below:
2
13
2,808
Philip Schroeder retweeted

Jun 8
Our SOTA reward model for robotic manipulation. I'm very proud of this work; it was more than a year in the making. Lessons learned below:
Jun 1

Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
4
7
34
6,264
Jun 5
Great discussion on @RoboPapers about the need for more large-scale collection of authentic failures and sub-optimal-but-successful trajectories for training reward models.
starts here: youtube.com/watch?v=sD_jrS_r…
and more here: youtu.be/sD_jrS_rXAs?si=t-rK…
Historically there has been limited demand for this type of data since it is less directly useful for imitation-style policy training, and for reward-model training it is unclear how to extract useful dense signal from these videos without hand-labeling each timestep (which is painful and slow). Robometer offers a solution to this by adding trajectory-level preference prediction (i.e., choosing which of two trajectories is more successful) as a second objective. This provides global ordering signal from failed and suboptimal trajectories, indirectly improving per-timestep progress predictions without requiring dense labels for these trajectories.
It would be good to see future work explore ways of more directly deriving dense signal from the failed/sub-optimal trajectories. But overall Robometer is a real advancement and should scale nicely as more data becomes available!
Congrats to @aliangdw, @yigitkkorkmaz , and @Jesse_Y_Zhang on the great work and thank you to @chris_j_paxton, @micoolcho, and @DJiafei for these great conversations!
Jun 2

Learning robust, general-purpose reward functions for robotics unlocks many potential applications, like on-robot reinforcement learning or dataset validation. However, there’s a question of how to actually train such reward functions. Training success/failure prediction leads to ambiguous signals partway through a demonstration — it’s hard to measure progress — making the method unsuitable for reinforcement learning, among other things. Predicting progress, on the other hand, does not give a good way of using failure data.
So why not do both? Robometer combines both progress and preference supervision, resulting in a stable, scalable, and highly general reward learning approach. @aliangdw @yigitkkorkmaz
and @Jesse_Y_Zhang join us to tell us more.
Watch Episode #84 of RoboPapers, with Chris Paxton and Jiafei Duan today!
1
13
2,025
Philip Schroeder retweeted

Jun 3
We found that state-of-the-art VLMs (Gemini, GPT-5, etc.) fail at predicting task progress for online RL, so we built our own: SOLE-R1.
SOLE-R1 is trained on 10 million images and video frames, and 4 million chain of thought traces that reason over both space and time.
The result is a video-language reasoning model that can be used as a reward for online RL with no other reward signals!
Jun 1
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
1
6
33
4,474
Philip Schroeder retweeted

Jun 2
The bottleneck to on-robot reinforcement learning is good, scalable reward prediction. Robometer is a massive step in that direction, and the authors have been wonderfully open as well, releasing a large dataset and continuing to improve their model post release.
Thanks to @aliangdw @yigitkkorkmaz and @Jesse_Y_Zhang for joining me and @DJiafei!
Jun 2
Learning robust, general-purpose reward functions for robotics unlocks many potential applications, like on-robot reinforcement learning or dataset validation. However, there’s a question of how to actually train such reward functions. Training success/failure prediction leads to ambiguous signals partway through a demonstration — it’s hard to measure progress — making the method unsuitable for reinforcement learning, among other things. Predicting progress, on the other hand, does not give a good way of using failure data.
So why not do both? Robometer combines both progress and preference supervision, resulting in a stable, scalable, and highly general reward learning approach. @aliangdw @yigitkkorkmaz
and @Jesse_Y_Zhang join us to tell us more.
Watch Episode #84 of RoboPapers, with Chris Paxton and Jiafei Duan today!
2
8
62
15,556
Philip Schroeder retweeted

Jun 2
Beginning to see some smoother rollouts with RLT, much better than yesterday
Jun 1

well it’s still pretty rough but this was my first RL Token rollout success. it’s definitely not yet an improvement over the base vla but I’ve got a good pipeline in place and have been making small incremental improvements across multiple sessions today
5
8
56
5,993
Philip Schroeder retweeted

May 31
We're presenting PEEK at ICRA in Vienna this week 🏰
Stop by at the 9-10:30am poster session on June 3 to say hi and check out some cool VLA generalization 🤖
10 Oct 2025

How can we help *any* image-input policy generalize better to visual and semantic variations?
👉 Meet PEEK 🤖 — a framework that uses VLMs to decide *where* to look and *what* to do, so downstream policies — from ACT, 3D-DA, or even π₀ — generalize more effectively!
5
23
7,235
Philip Schroeder retweeted
Jun 1
🚪 “Knock knock!”
👂 “Who’s there?”
🤖 “Zero-shot reward model for robot manipulation”
Jun 1
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
2
18
3,045
Jun 1
Excited to introduce SOLE-R1, a video-language reasoning model for zero-shot reward prediction for robot manipulation tasks!
SOLE-R1 reasoning can serve as the SOLE signal for learning new tasks (completely from scratch) through online RL - i.e., robots start with random actions and learn previously unseen tasks guided only by SOLE-R1 rewards, without any demonstrations, ground-truth rewards, success indicators, or task-specific tuning.
SOLE-R1 significantly outperforms strong baselines (e.g., Robometer, RoboReward, TOPReward, GPT-5, Gemini-3-Pro) in zero-shot online RL when evaluated across 40 tasks - including a real-world tabletop manipulation setting and 4 sim environments (LIBERO, ManiSkill, Meta-World, RoboSuite).
We open source all models, training data, and code.
Website, demos, and paper at: philip-mit.github.io/sole-r1…
🧵 (1/6)
1
9
54
13,977
Jun 1
(5/6)
Evaluation setting:
We evaluate whether SOLE-R1 can serve as the SOLE supervision signal for learning manipulation skills from scratch via online RL. We run experiments across 4 sim benchmark suites (LIBERO, ManiSkill, Meta-World, and RoboSuite) and in a real-world tabletop manipulation setting with a Franka arm. Across all settings, we evaluate a total of 40 tasks, spanning pick-and-place, articulation, button/lever/knob interactions, and mobile manipulation.
Results:
SOLE-R1 achieves ≥50% success rate on 24 tasks, substantially outperforming all baselines. The strongest baselines include GPT-5 and Gemini, but they reach 50% success on only 7 and 5 tasks, respectively. The non-reasoning models achieve near-zero success on all tasks, with the exception of Meta-World tasks, where Robometer, RoboReward, and ReWiND achieve above 40% success rate on 4 tasks.
1
1
294
Jun 1
(6/6)
🌐 Website: philip-mit.github.io/sole-r1…
📄 Paper: arxiv.org/abs/2603.28730
👩🏻💻 Code: github.com/Philip-MIT/sole-r…
Thank you to my co-authors: @thomas_weng, Karl Schmeckpeper, @_ericrosen, Stephen Hart
And special thanks to @BizaOndrej for supervising this work from the very start!
More to come soon!
1
4
317
Philip Schroeder retweeted

May 28
This was one of the better ACT rollouts we saw today.
Task: Package auxiliary parts for the electronic devices into a plastic bag.
5
4
55
3,353
Philip Schroeder retweeted

May 27
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
13
33
233
75,125

TOPReward is now in LeRobot!
Its an elegant solution using the model's own logit probabilities, and worked very well when I compared it to other VLA rewards (vid below, the red line)
How to use in LeRobot: github.com/huggingface/lerob…
Congrats @DJiafei @allen_ai @UW!
May 27

🤖 Zero-shot robot rewards are now in LeRobot with TOPReward!
TOPReward, from @allen_ai, @UW, and @cole__ai @Amazon , turns a frozen video VLM into a robot reward model by reading log P("True" | video instruction) directly from the model’s logits.
Project: topreward.github.io/webpage/
Paper: arxiv.org/abs/2602.19313
8
37
4,879