
Research Scientist @MSFTResearch. NLP/HCI Research.
Joined April 2022
- Tweets 412
- Following 823
- Followers 1,539
- Likes 4,294
55 Photos and videos








Philippe Laban retweeted

Jun 10
Woke up this morning to read @vauhinivara’s brilliant existential essay at @nytimes on em dash that reinforces the beauty of language and resistance to a world where LLMs homogenize it :-)


2
3
40
2,800
Philippe Laban retweeted

Jun 2
Post-training makes LLMs safer and better at following instructions, but less diverse.
🤔 Can we get that diversity back without sacrificing alignment?
Introducing ReDiPO: a preference optimization recipe for restoring distributional diversity while preserving safety and instruction-following.

1
10
32
10,786
Philippe Laban retweeted

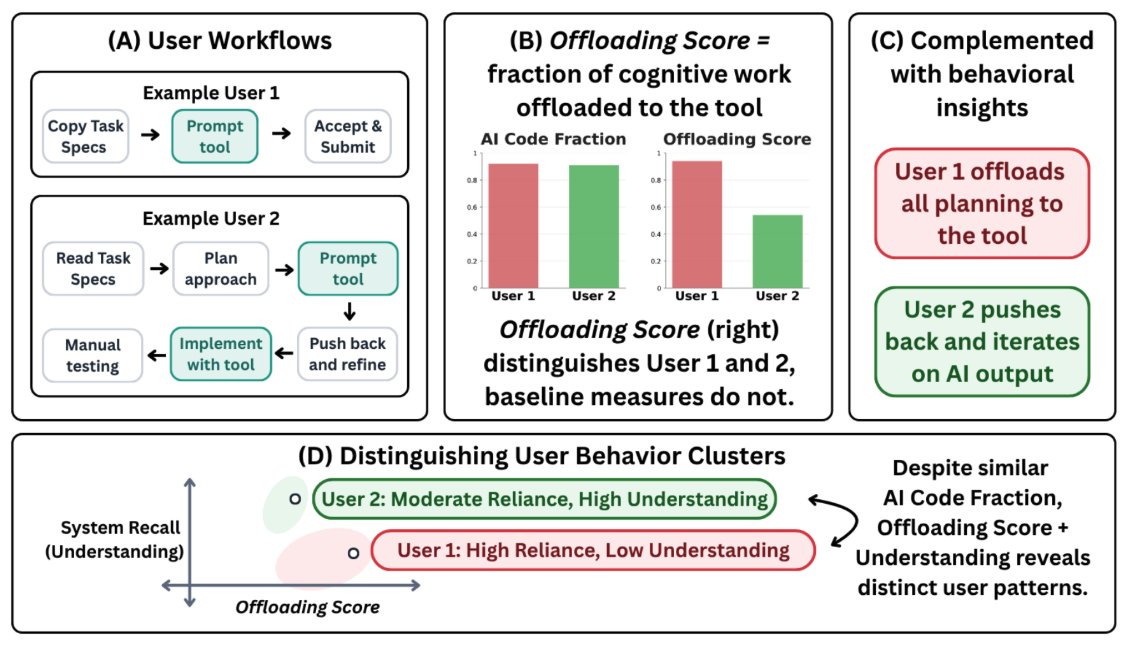
People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)

7
74
208
75,359
Philippe Laban retweeted

May 29
We built a joint experimental and computational platform for scalable multi-modal single-cell chemical screens — profiling RNA, protein (including phospho-signaling), and chromatin accessibility responses to thousands of small molecule perturbations in parallel. biorxiv.org/content/10.64898…

2
40
180
13,664
Philippe Laban retweeted

New paper! Have you or a loved one been harmed by a bad multiple-choice benchmark? 😔
You may be entitled to a more reliable evaluation 🩺
At #ACL2026, we'll present BenchMarker: a toolkit to diagnose common flaws in MCQA benchmarks, inspired by best practices in education 🧑🏫🧵

2
8
51
3,150
Philippe Laban retweeted
May 22
Ran some 🧪 with @irisiris_l to 🔬 why the Granta story was certainly 🤖 slop
A lot of bad writing happens coz AI hasn’t learned aesthetics. It has memorized the whole internet and called it a day.
So sure, maybe you don't trust AI detectors. But you can trust your own 👁️.

2
9
41
6,500
Philippe Laban retweeted
May 18
Looking for 1 emergency reviewer for a
@COLM_conf paper on Image Editing of Diffusion Model due Wednesday (05/20). Please DM me if interested. Thanks!
Retweets appreciated
1
9
11
2,361
Philippe Laban retweeted

May 14
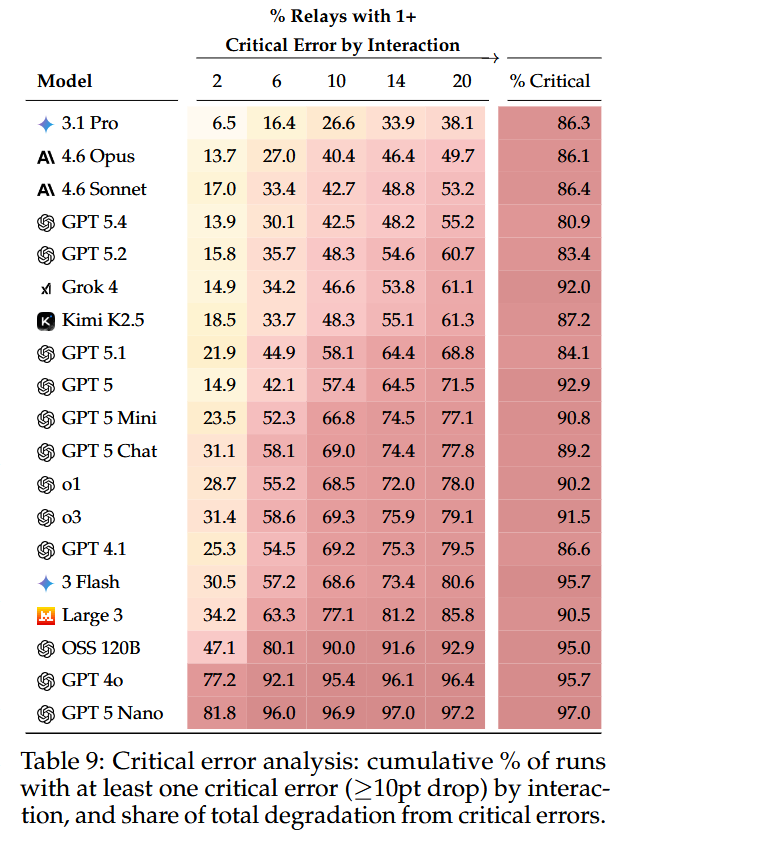
We like to delegate tasks to LLMs, where the models perform long-horizon and iterative operations on documents and return the results. But how far can you trust the models to stay faithful to the original content of the document?
A new study by Microsoft Research answers this question with an interesting technique. They use "round-trip relay" tasks to evaluate the capability of LLMs to perform accurate edit tasks on documents.
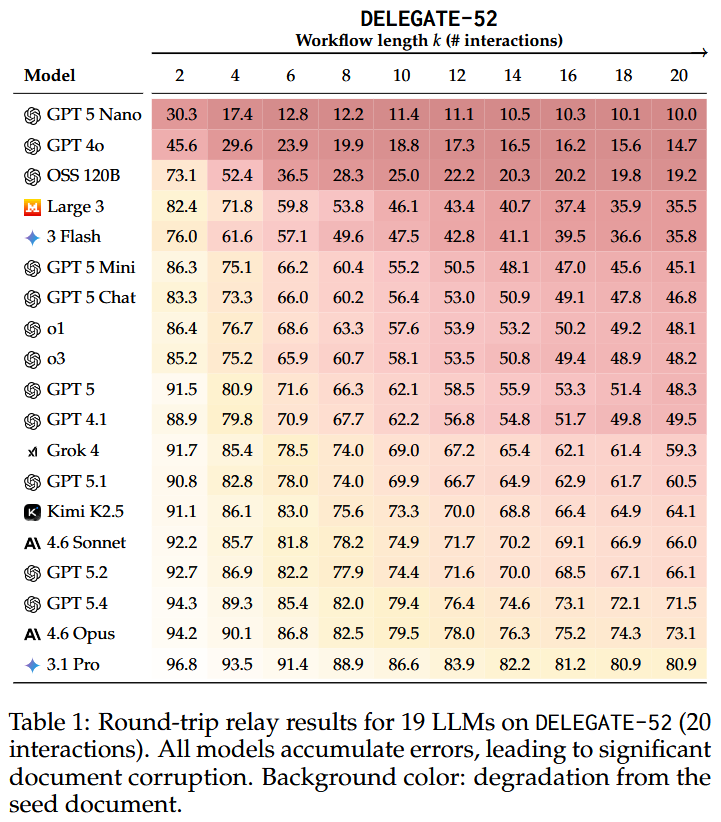
Basically, it is like back-translation. The model has to perform an operation on the document and then reverse it to produce the original content. To simulate multi-iteration tasks, they chain these operations together across 20 steps. They created a benchmark, DELEGATE-52, which measures delegation performance across different domains.
The results:
- Even the best LLMs corrupt up to 25% of the document contents.
- Corruption doesn't happen by "death by a thousand cuts." Usually, one mishap derails the model, and it can happen on any of the iterations
- Generic tools for code execution and file read/write access don't make things better
What's the main takeaway:
- Only delegate to the extent that you stay in control
- Create domain-specific tools
Many thanks to @PhilippeLaban for sharing comments and actionable insights for developers.
May 13

Frontier AI models don't just delete documents — they rewrite them. Microsoft Research tested 19 models: even the best corrupted 25% of content. Agentic tools made it worse.
venturebeat.com/ai/frontier-…
1
2
7
566
Philippe Laban retweeted
MyScholarQA is live! If you want a deep research system that actually knows about your work, check it out 👇
personalized-scholarqa.apps.…

Now available in AstaLabs in limited research preview: MyScholarQA, a personalized version of ScholarQA for scientific deep research.
ScholarQA helps synthesize evidence from 12M open-access papers. MyScholarQA adds user profiles to tailor that synthesis to you. 🧵
1
13
29
5,396
Philippe Laban retweeted

May 14
Ask an LLM for a "post that'll pop off". Output misses so you say "more unique." It asks "unique how?" but you don't know yet.
DiscoverLLM (ICML'26): trains LLMs to help users discover their intents, not just execute them.
📑 arxiv.org/abs/2602.03429
🌐 taesookim.com/discoverllm
4
8
49
4,949
Philippe Laban retweeted

We use LLMs to role-play "users" to train, evaluate, and improve AI assistants. How do you know if your user simulator is any good? We argue: rather than measuring how realistic it sounds, start measuring how the assistants it trains perform with real humans. 🧵👇

8
8
66
9,255
Philippe Laban retweeted

May 13
Today, we’re excited to launch Recursive (@recursive_si): an exceptional team across London and San Francisco, building AI systems that can safely improve their own capabilities over time.

15
17
124
17,238
Philippe Laban retweeted

May 13
User simulators have emerged as promising tools for building interactive AI, but what makes a “good” simulator?
We reframe the problem as what creates downstream value for humans
Our new simulator test: how an LLM assistant trained with the simulator performs with human users🧵

6
23
133
15,027
Philippe Laban retweeted

May 11
What happens when you compare the distributions of real and simulated user behaviors?
🔍 The gap is large.
We introduce a method to measure this gap and evaluate 24 LLM-based user simulators across coding and writing tasks.
@convai_uiuc @MSFTResearch @berkeley_ai
🧵 1/N

7
43
192
30,290
Philippe Laban retweeted

May 5
We've just released open source MTP style drafters for Gemma 4 models ⚡
Now Gemma 4 models are even faster on your choice of hardware, without losing quality!
Grateful for the fruitful collaboration between my team, Gemma team, and many collaborators to enable this release!
May 5

Excited to introduce Gemma 4 Multi-Token Prediction Drafters⚡️Accelerated inference right in your pockets
- Up to a 3x speedup
- Same quality guarantees
- Available in your favorite open-source tools
4
4
29
4,352
Philippe Laban retweeted

Apr 30
New Microsoft paper shows that current AI assistants often damage documents during long editing jobs.
Even the frontier models still ended up corrupting about 25% of document content on average, while many other models damaged far more.
The problem is that delegated AI work only makes sense if a model can keep a document correct across many edits, not just do 1 step well.
The paper tests this with reversible task pairs, where a model edits a file and then tries to undo that edit, so a reliable system should return to the original document.
The authors built real work setups across 52 domains, from coding and science to accounting and music notation, and ran 19 models through 20 editing interactions.
The failures were usually not lots of tiny slips but occasional big mistakes that silently broke parts of the document and then compounded over time.
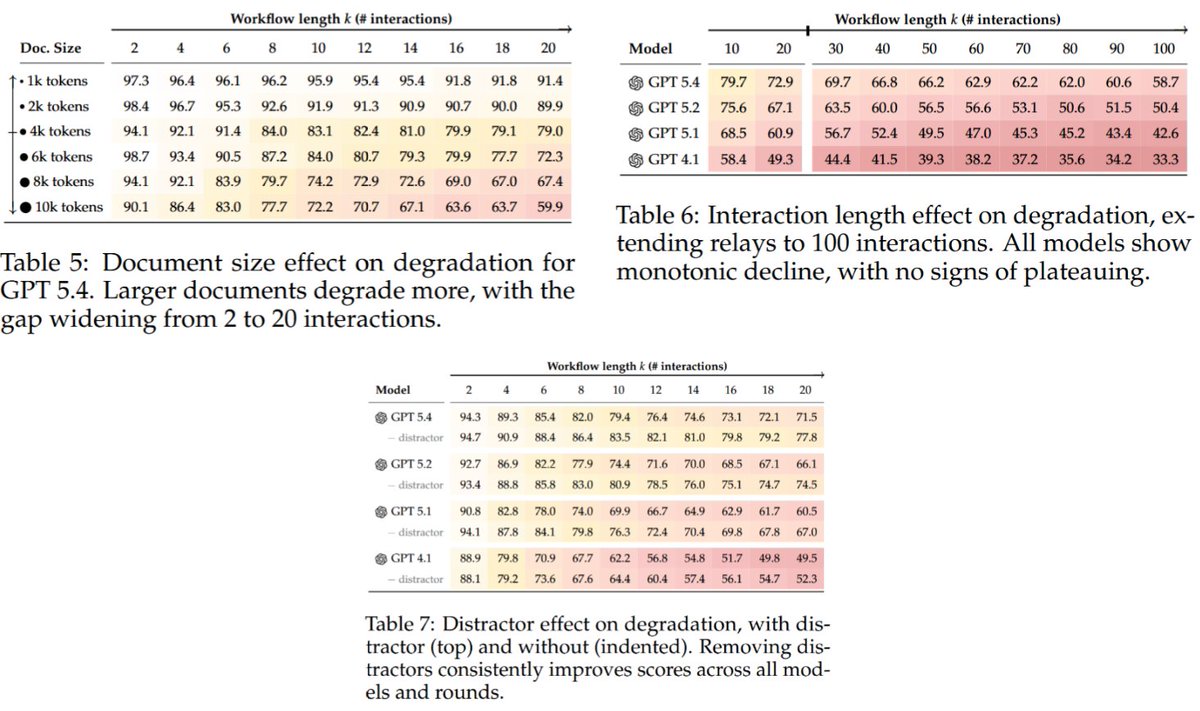
Agentic tool use did not help in their tests, and bigger files, longer workflows, and irrelevant extra documents made the corruption worse.
The reason this matters is that current LLMs can look strong in short demos or narrow coding tasks yet still be unreliable delegates for long real-world document work.
----
Paper Link – arxiv. org/abs/2604.15597
Paper Title: "LLMs Corrupt Your Documents When You Delegate"

25
76
309
51,037
Philippe Laban retweeted

Apr 29
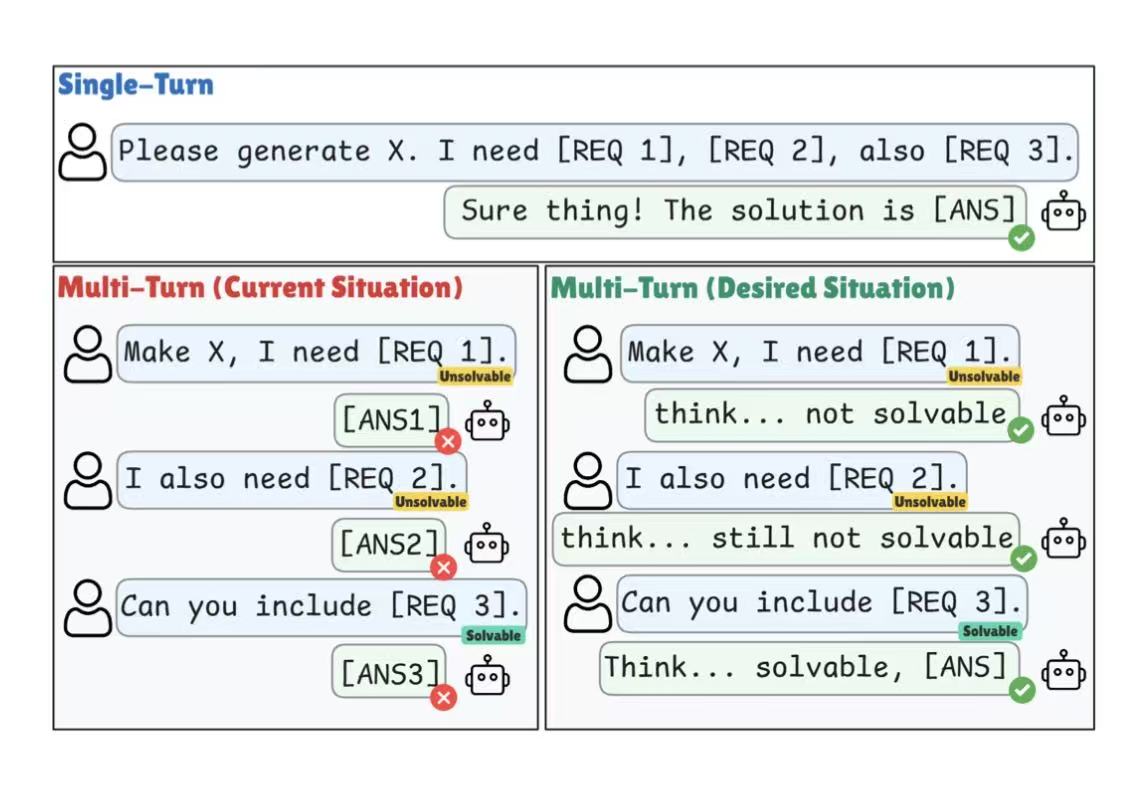
Excited to share our ACL 2026 work, trying to solve the issue raised by the ICLR Outstanding Paper “LLMs Get Lost In Multi-Turn Conversation”!
Our RLAAR (arxiv.org/pdf/2510.18731) is an RL framework that trains LLMs to both answer correctly and wait when context is insufficient, using verifiable accuracy and abstention rewards.
This tackles a key weakness in today’s conversational LLMs: they often answer too early, make wrong assumptions, and struggle to recover as conversations unfold.
We’re also excited to see this challenge highlighted by “LLMs Get Lost In Multi-Turn Conversation” (arxiv.org/pdf/2505.06120) being recognized as an ICLR 2026 Outstanding Paper.
Reliable conversational AI needs to know when to answer — and when to hold back.
#ACL2026 #ICLR2026 #LLM #RLVR #ConversationalAI
1
11
73
5,560
Philippe Laban retweeted

We present SWE-chat: the first large-scale dataset of coding agent interactions from real users in the wild.
In 40% of real coding sessions, the agent writes ~all the code. Users push back 39% of the time – agents almost never stop to check.
Data, paper, & findings in the 🧵👇
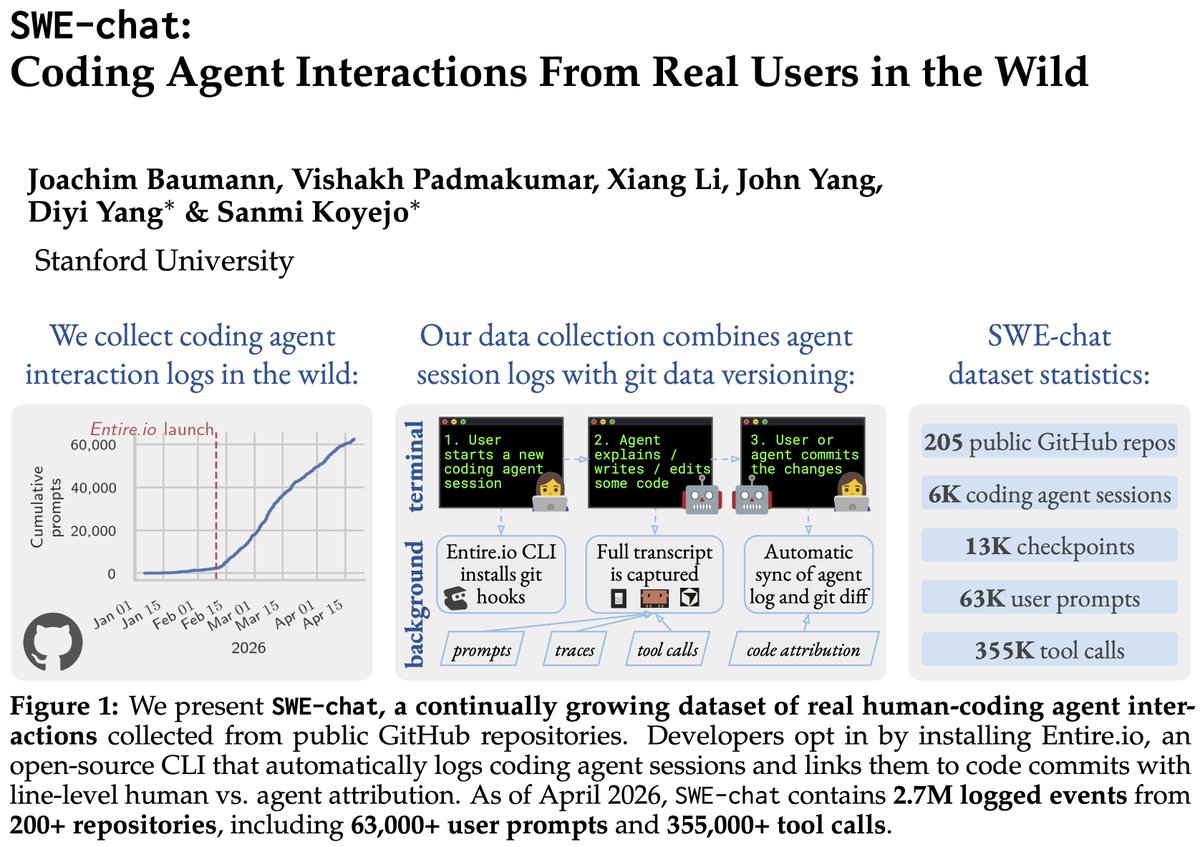
ALT Overview of SWE-chat. Left: a data collection pipeline diagram. Open-source developers install the Entire.io CLI tool, which logs their coding agent sessions and pushes the logs to a dedicated branch on their public GitHub repository. We discover and aggregate these logs into the SWE-chat dataset, with line-level attribution of which lines of code were written by the human versus the agent. Right: a growth chart showing cumulative logged events over time, rising steeply through early 2026. As of April 2026, the dataset contains 2.7 million logged events from over 200 repositories, including 63,000 user prompts and 355,000 agent tool calls across nearly 6,000 sessions.
14
78
478
70,109
Philippe Laban retweeted

Apr 29
We study sampling diverse output from a suite of LLMs. One key surprise for me was that it's better to carefully pick a single model to sample many times, rather than naively mixing outputs from multiple models.
Apr 28

Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵

1
6
36
5,538
Philippe Laban retweeted

Apr 28
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
2
34
175
23,731