
Ph.D. student at the University of Georgia. Agents, Machine Reasoning, Large Language Models.
Joined May 2022
- Tweets 35
- Following 1,117
- Followers 79
- Likes 3,698
5 Photos and videos



Many skill-learning papers recently study how to curate and deploy skills throughout the agent lifecycle for self-evolution. But do they really establish a rigorous setting for fair comparison and evaluation?
Happy to share our recent work:
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
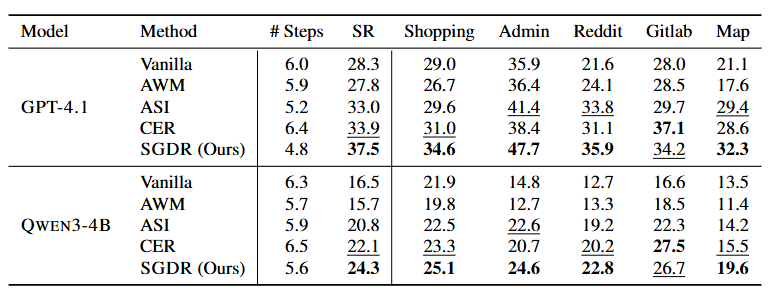
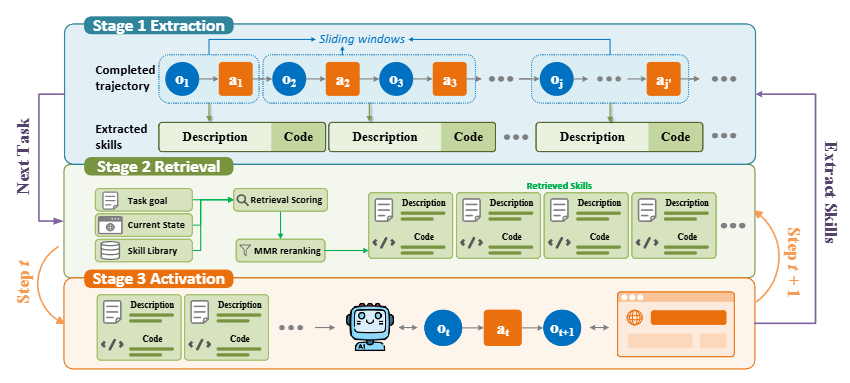
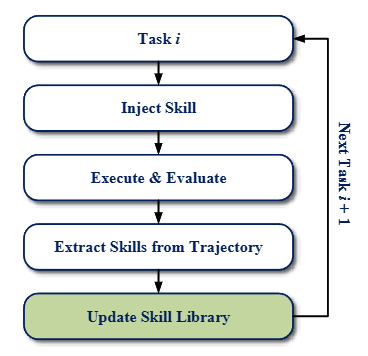
In this paper, we first strictly formulate the setting of online skill learning following prior baseline works, where agents induce skills from past task trajectories on the fly and reuse them for future tasks, without access to ground-truth signals from environments.
Second, we identify a key problem in existing skill methods: curated skills can mismatch the current execution state. To address this, we propose State-Grounded Dynamic Retrieval (SGDR), a simple yet effective approach that retrieves the right skill at the right execution state.
📄 arxiv.org/abs/2606.04391
💻 github.com/plusnli/skill-dyn…
🧵
1
1
3
2,788
Many skill-learning papers recently study how to curate and deploy skills throughout the agent lifecycle for self-evolution. But do they really establish a rigorous setting for fair comparison and evaluation?
Happy to share our recent work:
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
In this paper, we first strictly formulate the setting of online skill learning following prior baseline works, where agents induce skills from past task trajectories on the fly and reuse them for future tasks, without access to ground-truth signals from environments.
Second, we identify a key problem in existing skill methods: curated skills can mismatch the current execution state. To address this, we propose State-Grounded Dynamic Retrieval (SGDR), a simple yet effective approach that retrieves the right skill at the right execution state.
📄 arxiv.org/abs/2606.04391
💻 github.com/plusnli/skill-dyn…
🧵
1
1
3
2,788
6/
Thanks all of my collaborators.
The code (including baseline methods!) is open-sourced.
📄 arxiv.org/abs/2606.04391
💻 github.com/plusnli/skill-dyn…
1
26
Jiaxi Li retweeted

Jun 3
Static datasets give fixed samples.
Code-generated environments give scalable worlds.
For LLM reasoning, executable environments can generate fresh problems and verifiable rewards.
With TRON, we bring this idea to visual reasoning: each code-generated environment samples a latent visual state, renders an image, asks a question, and verifies the answer from the underlying state.
The name is inspired by the sci-fi film TRON: a virtual world created entirely by code, where agents can enter, interact, and evolve.
This is not just about generating more data.
It is about programming the distribution that produces data.
Such environments make visual training data controllable, difficulty-scalable, and online, properties that are hard to obtain from static datasets.

3
6
31
1,746
Cool!!! 🆒 🆒
May 27

AI agents are increasingly deployed as persistent operational systems, but do they remain reliable over time?
Unfortunately no, our new work shows agents can quietly fail after deployment, despite passing day-1 evaluation. We call this "agent aging", akin to human aging.
4
185
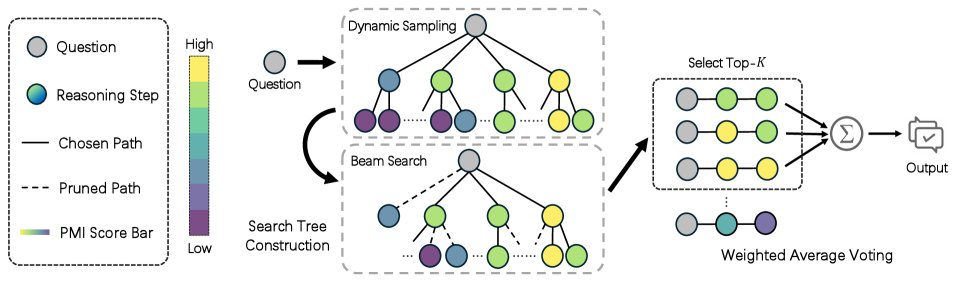
Unlike MCTS methods that explore multiple reasoning paths but struggle with real-time quality assessment, MITS uses informaion-theoretic principles to evaluate steps instantly, with experiments validating its effectiveness!
Welcome upvote our paper!😍
huggingface.co/papers/2510.0…
7 Oct 2025

Introducing MITS: Smarter, more efficient LLM reasoning with information theory
This novel framework guides LLM tree search using Pointwise Mutual Information (PMI) to instantly evaluate reasoning steps. It achieves superior performance with high computational efficiency.
2
8
1,817
Tired of the frequeeent looking-ahead rooollout phase of MCTS? Check out MITS!🚀
Excited to share Mutual Information Tree Search (MITS), which employs pointwise mutual information (PMI) to assess each step effectively and efficiently!
Check it out here!😍huggingface.co/papers/2510.0…
1
130
Jiaxi Li retweeted

8 Sep 2025
BRILLIANT paper.
LLMs get stuck when they think too long in a single line, early tokens steer them into a narrow path and they rarely recover, which the authors call Tunnel Vision.
ParaThinker trains native parallel thinking, it spins up multiple distinct reasoning paths at once and then fuses them into 1 answer, which lifts accuracy a lot with tiny latency cost.
Sensational fact, if you only keep 1 thing: 12.3% average gain for 1.5B, 7.5% for 7B, with only 7.1% extra latency.
ParaThinker shows that training LLMs to think in parallel paths instead of just longer single chains avoids tunnel vision, giving up to 12.3% accuracy gains with only 7.1% extra latency, letting smaller models beat much larger ones.
🧵 Read on 👇

27
148
907
53,463

📢 New paper alert 📢
We introduce MobileGUI-RL, an RL framework advancing mobile GUI agents through trajectory-based rollouts and rewards in 𝗼𝗻𝗹𝗶𝗻𝗲 environments.
With RL, Qwen 2.5-VL achieves 44.8% Success on Android World! ✨
Checkout paper at: arxiv.org/abs/2507.05720

21
72
12,234
Jiaxi Li retweeted

10 Jan 2025
Optimizing LLM Test-Time Compute Involves Solving a Meta-RL Problem – Machine Learning Blog | ML@CMU | Carnegie Mellon University blog.ml.cmu.edu/2025/01/08/o…
4
45
226
18,147
Jiaxi Li retweeted

10 Jan 2025
🧵1/8 Thrilled to share our research work:
Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales? #NeurIPS2024

2
5
6
465
Jiaxi Li retweeted

12 Sep 2024
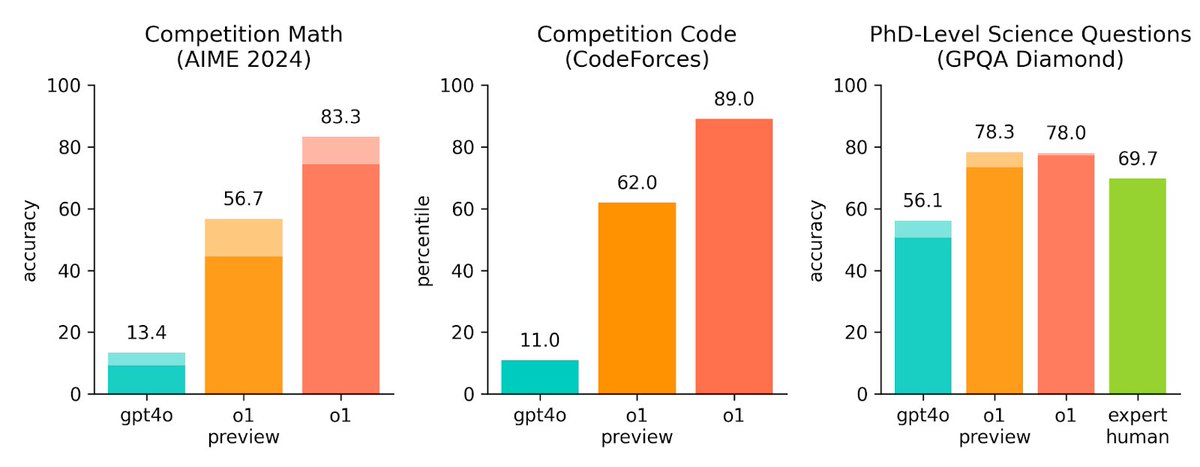
here is o1, a series of our most capable and aligned models yet:
openai.com/index/learning-to…
o1 is still flawed, still limited, and it still seems more impressive on first use than it does after you spend more time with it.
679
2,453
16,956
2,791,104
Jiaxi Li retweeted

4 Sep 2024
🔗 Thoughts on Research Impact in AI.
Grad students often ask: how do I do research that makes a difference in the current, crowded AI space?
This is a blogpost that summarizes my perspective in six guidelines for making research impact via open-source artifacts. Link below.

21
259
1,184
248,194
Jiaxi Li retweeted

28 Aug 2024
Great summary on model merging and mode connectivity. Also adding our work on
1. Mode connectivity and backdoors: openreview.net/forum?id=SJgw…
2. Mode connectivity and adversarial examples: arxiv.org/abs/2009.02439
3. Safety loss landscape exploration for LLMs: arxiv.org/abs/2405.17374
27 Aug 2024

Model merging is a popular research topic with applications to LLM alignment and specialization. But, did you know this technique has been studied since the 90s? Here’s a brief timeline…
(Stage 0) Original work on model merging dates back to the 90s [1], where authors showed that taking an average of neural network parameters yields a model that performs similarly to averaging the output of multiple neural networks (i.e., an ensemble).
(Stage 1) Averaging along the training trajectory. Several works in the mid-to-late 2010s explore the idea of taking an average of model checkpoints throughout the training process. This can be done via an exponential moving average [2] or by just averaging specific checkpoints during training [3] and improves training stability / performance / generalization in certain cases.
(Stage 2) Linear mode connectivity [4, 5] is a research topic–coming from research on neural network pruning / sparsity–that is highly related to model merging. Linear mode connectivity shows us that multiple neural networks (finetuned from the same base model) have a linear path of non-increasing loss between them in the parameter space. Put simply, interpolating between two finetuned models yields another model that also performs well. [6] studies this topic in the context of LLMs.
(Stage 3) Weight averaging. Based on findings in linear mode connectivity research, we began to see several papers that directly average the parameters of several neural networks obtained in separate training runs (i.e., “model soups”) [7, 8, 9]. This strategy–although simple–was found to have several benefits in terms of model performance and generalization capability, somewhat similarly to creating an ensemble of models from several separate finetuning runs.
(Stage 4) Better merging approaches. After initial explorations of model merging, we began to see several research papers that propose more specialized / effective merging techniques, such as:
- Using task vectors to merge models [10].
- The TIES [11] or DARE [12] strategies for reducing interference during merging.
These works show that model merging is highly effective for improving performance and combining the capabilities of multiple models. However, performance depends on the strategy we use for merging, which can be optimized to reduce conflicts / interference.
(Stage 5) LLM-specific research. More recently, we have seen a widespread adoption of model merging within LLM research to combine LLM capabilities [13], improve the alignment process [14], or train better reward models [15]. One especially notable application of model merging in recent research is the use of WARP [14]–a state-of-the-art model merging technique for improving LLM alignment–for aligning Gemma-2 [16].

1
9
56
9,030
.
9 Jul 2024

10 Best ways to lose belly fat in 90 days
(Backed by science)
//Thread//

6
150
Jiaxi Li retweeted

17 Jun 2024
⚡️Chain rule for text!
The key of #TextGrad is to optimize any #AI #agent system by backpropagating text feedback. Autograd for the age of agents🪄
Check out our new hands-on tutorials:
Tutorial github.com/zou-group/textgra…
Paper arxiv.org/abs/2406.07496
8
41
185
19,668