
I ape memecoins that catch my attention.
Joined August 2020
- Tweets 12,988
- Following 874
- Followers 11,236
- Likes 9,955
1,752 Photos and videos












Jose retweeted

May 2
It’s not hard to be a good person.
With that being said stop playing with good people.
59
28
142
3,835

Jose retweeted

Apr 29
My current agent stack model ratings:
4 @NousResearch Hermes agents
- 3 on GPT 5.5 (xhigh)
- 1 on Qwen 3.6 (Local)
2 @openclaw agents
- 1 on GPT 5.5 (xhigh)
- 1 on Claude Opus 4.7
This is after ditching GLM, Kimi, and Minimax agents based on their coding / agentic work (see below)
------------Ratings-------------
@OpenAI Gpt 5.5 - 9.5 coding / 9 agent
@claudeai Opus 4.7 - 9 coding / 9.5 agent
@Alibaba_Qwen 3.6 - 8.5 coding / 8 agent
@MiniMax_AI - 7 coding / 6 agent
@Kimi_Moonshot - 7.5 Coding / 6.5 agent
@Zai_org GLM 5.1 - 8 Coding / 8 agent
My token usage: one $200 max plan gives me 4 agents on Gpt 5.5 xhigh vs 1 Claude agent for $200 max plan
49
14
266
21,159

Jose retweeted

Apr 20
got into memecoins to grow ur personal brand?
This is like saying you joined isis to grow your personal brand
60
14
394
30,848
Jose retweeted

Mar 22
Funniest thing I’ve seen in a bit.
Mar 21

🚨 NEW: There was a terrible accident during the women's Milan-San Remo one-day classic in Italy. Holy moly!!! 😮
65
124
3,822
779,460
Jose retweeted

Me earning a $9 dividend after losing $3k in the market
61
421
9,521
297,575

Feb 28
LMAOOOO


2
996
Feb 16
I think @jasonkneen got some sensational tek here
one of best open claw narratives I've seen and Github is stacked
HkmwJUU8zwyBSiktJ9udeHAG6YmpmdxC6NB3DpWNpump
2
1
21
1,295
Feb 13
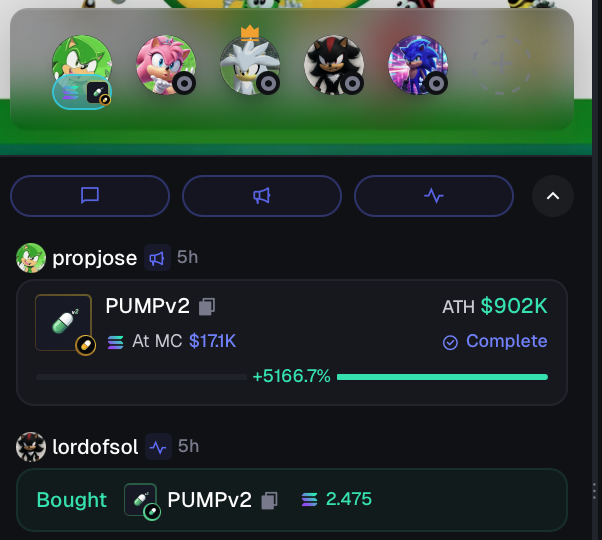
the alpha is right there infront of you but you still can't see it, sigh
E7Xfasv5CRTNc6Xb16w36BZk3HRSogh8T4ZFimSnpump

3
2
7
1,011
Jose retweeted

Feb 13
E7Xfasv5CRTNc6Xb16w36BZk3HRSogh8T4ZFimSnpump
its 100% real

4
8
24
7,124
Jose retweeted

Feb 12
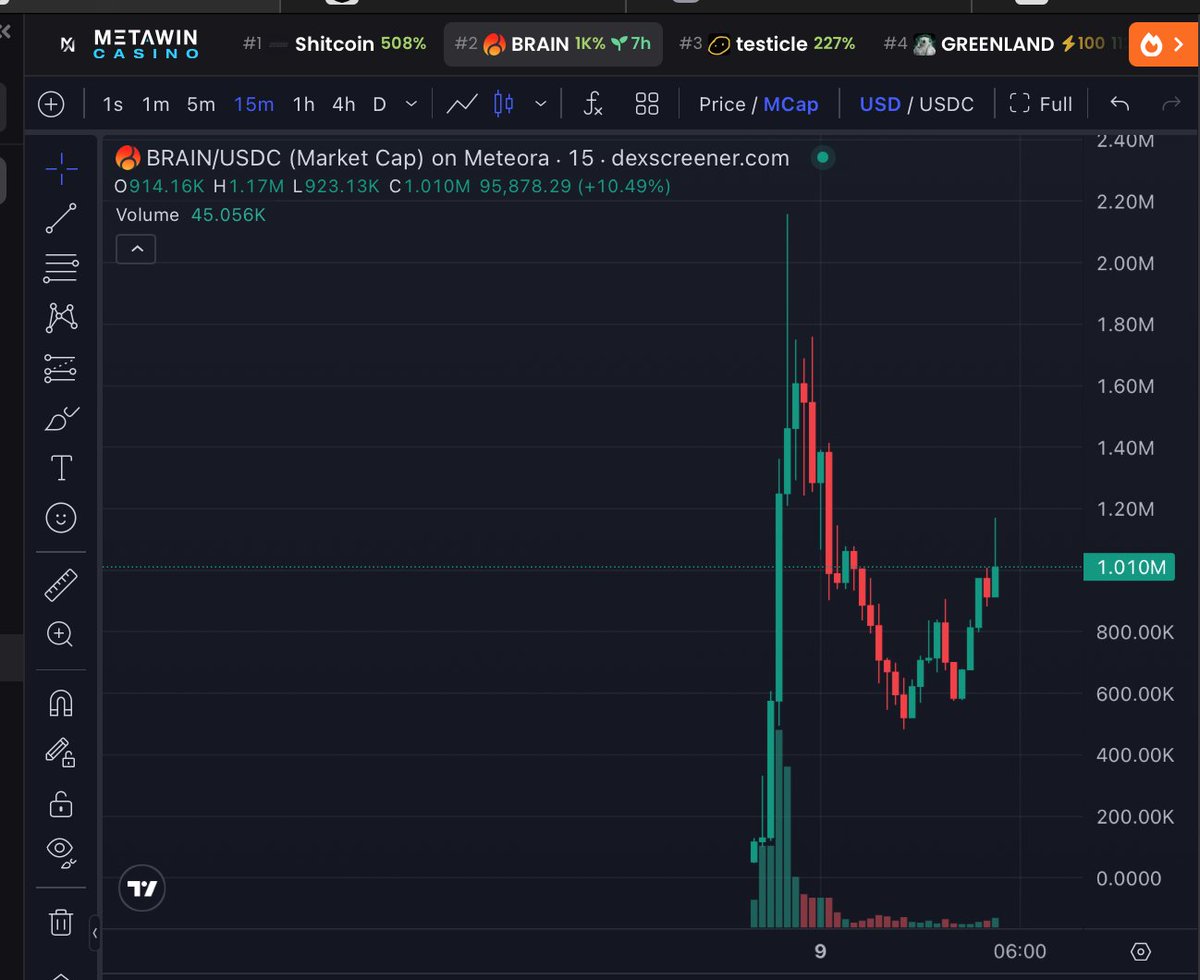
Mcdonalds stock outperforming everything atm.
8yCGQT6mw2Ga3YxpSMCLWB73FwGN6mDPjoLLtPeopump
Hold $WAGIE and receive @McDonalds stocks to your wallet.
How it works:
1. Auto claims creator fund
2. Swaps SOL to USDC
3. Buys McDonald stock via @OndoFinance
4. Distributes to $WAGIE holders
Cycles run every 5 minutes.
13
9
65
8,394
Jose retweeted

Jan 25
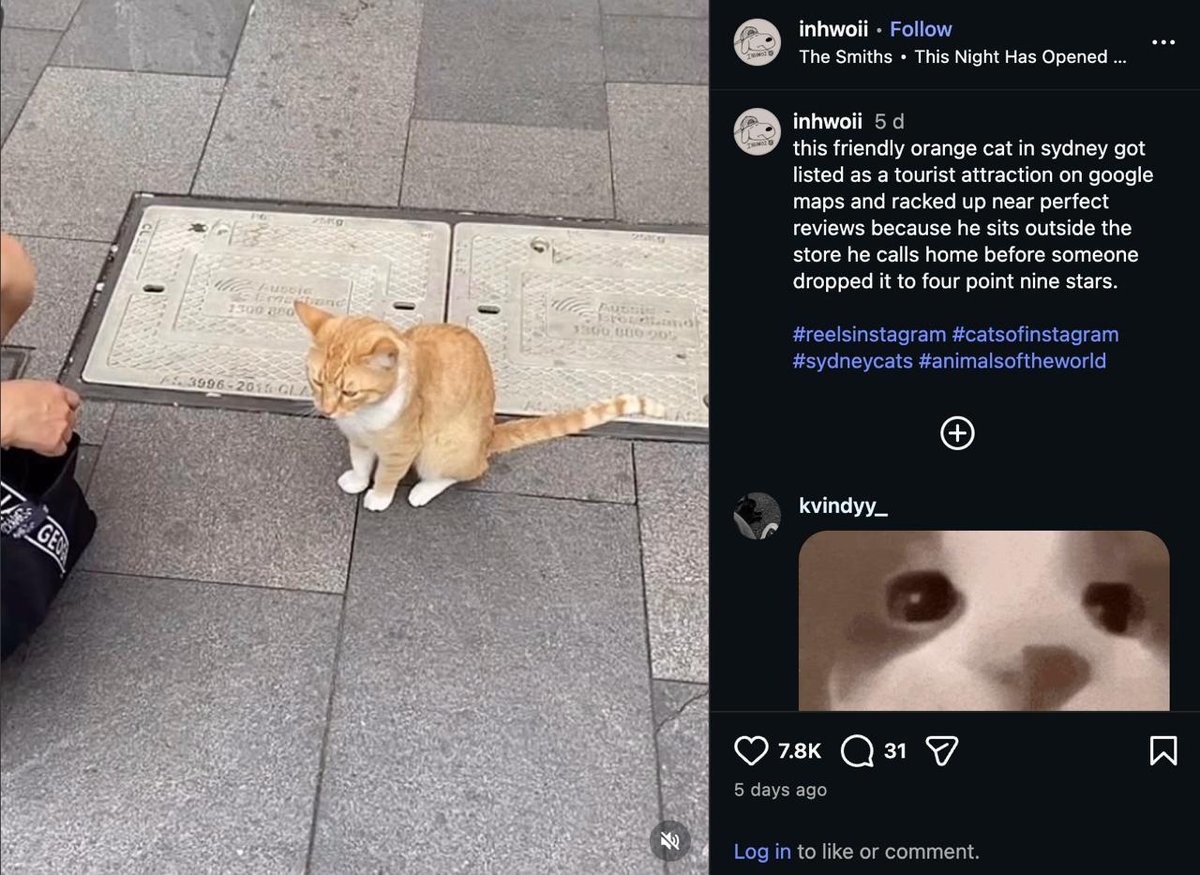
A friendly orange cat became a top tourist attraction after locals listed him on Google Maps.
He's so famous that google has noticed and taken down the review page yet he's built a huge audience on reddit, tiktok and posted by big IG accounts!
Lets not let google censor the $TOPCAT and send this Friendly Orange Cat!
IG: instagram.com/p/DT54dRykvwW/…
Reddit:
reddit.com/r/cats/comments/1…
Tiktok:
tiktok.com/@secret.sydney.sm…

6
6
18
3,004
Jan 21
This gonna be @DavidVujanic when he realises crypto community gonna fund his next content project via @BagsApp
5
1
8
426