
Joined November 2013
- Tweets 471
- Following 114
- Followers 330
- Likes 97
68 Photos and videos









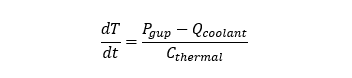





May 15
Keep operational data locked on-premises with Cortex’s closed control loop to achieve zero data exfiltration for your Sovereign AI deployments.
#SovereignAI #DataSecurity #AIFactory
reurl.cc/xWXn21
3
7
76
May 14
Compress your AI Factory deployment from 12 months to 3 and unlock a $130M speed-to-market advantage.
#TimeToMarket #AIInfrastructure #NVIDIA
reurl.cc/xWXn21
6
8
83
May 13
Sync IT workloads with cooling in real-time to eliminate thermal throttling and achieve PUE ≤ 1.15.
#LiquidCooling #DataCenter #SustainableAI
reurl.cc/xWXn21
4
8
92
May 12
Double your GPU yield and stop leaking billions in stranded silicon with Cortex's perfect workload packing. #GPUUtilization #AIFactory #ROI
reurl.cc/xWXn21
5
9
82
May 11
Predict GPU crashes 72 hours in advance and seamlessly migrate workloads to achieve zero downtime.
#ZeroDowntime #AIOps #SelfHealing
reurl.cc/xWXn21
5
9
71
Apr 29
In the AI gold rush, "Time-to-Market" isn't just a buzzword—it's a financial weapon.
A typical AI data center takes 12–18 months to go from contract to "Live." In that time, the market moves, and revenue is lost.
(1/6) #AIFactory #TimeToMarket
1
5
7
70
Apr 29
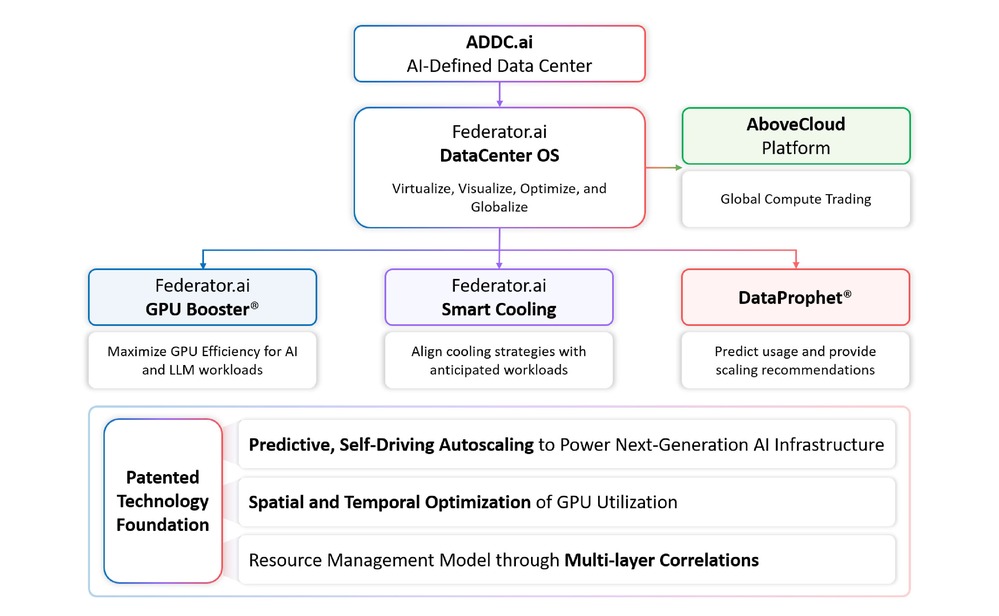
Building Sovereign or Enterprise AI? Federator.ai Cortex provides:
✅ SOC2/HIPAA Readiness
✅ Native NVIDIA NIM/vLLM Support
✅ Modular DCOO Lifecycle Management
Get your ROI before the competition even finishes their blueprints.
(5/6) #SovereignAI #NVIDIA
1
1
71
Apr 29
Stop building from scratch. Start operating at scale.
Download the full datasheet to see how 𝗙𝗲𝗱𝗲𝗿𝗮𝘁𝗼𝗿.𝗮𝗶 𝗖𝗼𝗿𝘁𝗲𝘅 accelerates the future of AI: reurl.cc/qpVj4n
(6/6) #NCP #AIInfrastructure #FinTech #HealthTech #TechNews
ALT Compressing the AI Timeline: How Federator.ai Cortex Cuts Deployment from Years to Months
4
54
Apr 27
Liquid cooling is no longer "optional"—it's the lifeblood of the AI Factory.
But here’s the problem: In most data centers, the GPUs and the Cooling Systems don't talk to each other. When they lose sync, your $40k GPUs throttle and slow down.
(1/6) #AIFactory #LiquidCooling
1
5
10
72
Apr 27
When things go wrong, Federator.ai Cortex’s 𝗕𝗮𝘆𝗲𝘀𝗶𝗮𝗻 𝗗𝗔𝗚 identifies the root cause across 16 failure modes in seconds.
Is it a pump failure or a workload spike? Cortex knows, so your SREs don't have to guess.
(5/6) #Observability #SRE #FaultDetection
1
2
54
Apr 27
Next-gen AI Factories require next-gen Orchestration. Stop managing silos and start managing the full stack.
Read the specs on how we bridge IT & OT: reurl.cc/qpVj4n
(6/6) #FullStack #GPU #Blackwell #GB200 #DataCenter #NVIDIA
ALT The Thermal-Compute Nexus: Why Next-Gen AI Factories Require Vertical IT/OT Integration
5
54
Apr 23
But the real game-changer is 𝗸𝗠𝗼𝘁𝗶𝗼𝗻.
kMotion performs a 𝗦𝗲𝗮𝗺𝗹𝗲𝘀𝘀 𝗣𝗼𝗱 𝗠𝗶𝗴𝗿𝗮𝘁𝗶𝗼𝗻, moving your training job to a healthy node without stopping the clock.
Zero downtime. Zero lost progress. Total continuity.
(5/6) #AIInfrastructure #ZeroDowntime
1
2
52
Apr 23
Stop firefighting and start training. With 𝗪𝗶𝗻𝗴𝗺𝗮𝗻 𝗔𝗜, our NLP assistant, you can manage cluster health with a simple chat.
Check out the full datasheet to see how we’re making AI factories self-healing: reurl.cc/qpVj4n
(6/6) #AIFactory #SelfHealing #NVIDIA
ALT Beyond the MTBF Cliff: How Federator.ai Cortex Achieves Predictive Resilience in Massive GPU Clusters
1
4
63