Corporate strategist by day |AI startup dreamer by night | From boardroom to #DeepTech | 🇮🇳|One AI agent at a time
- Tweets 2,414
- Following 485
- Followers 134
- Likes 7,266



















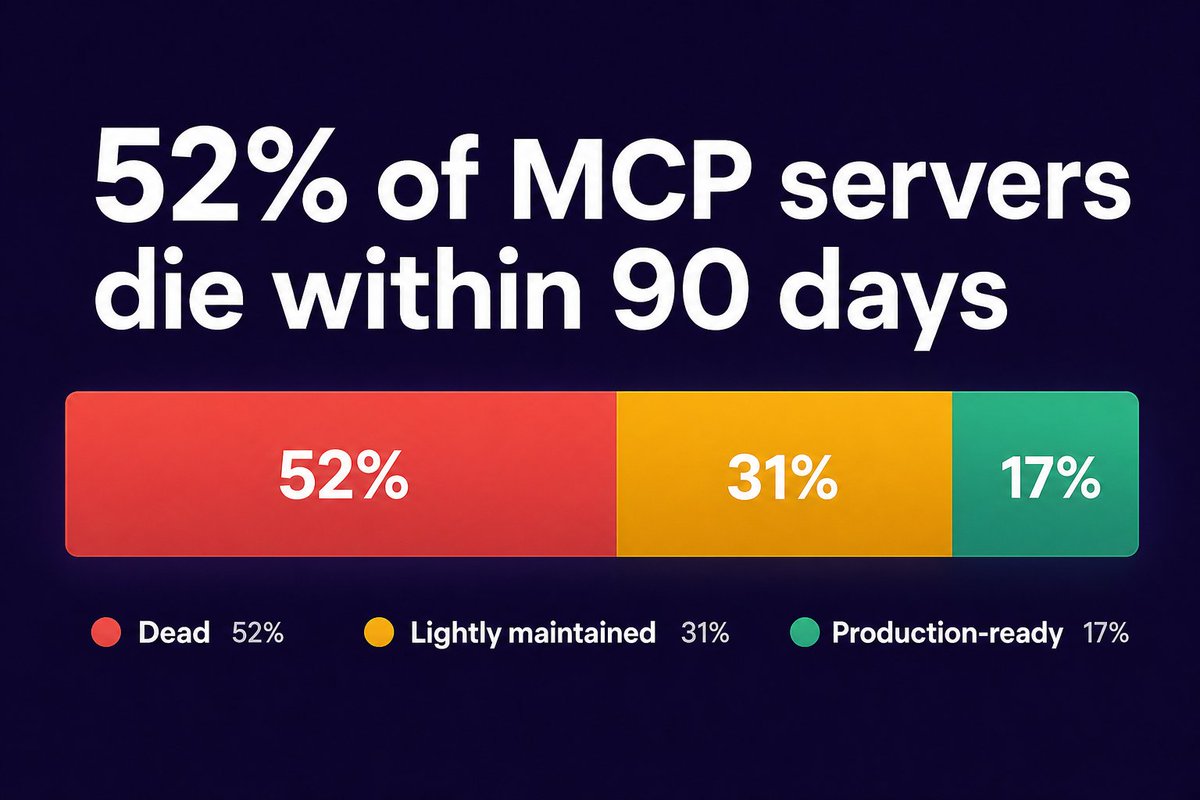

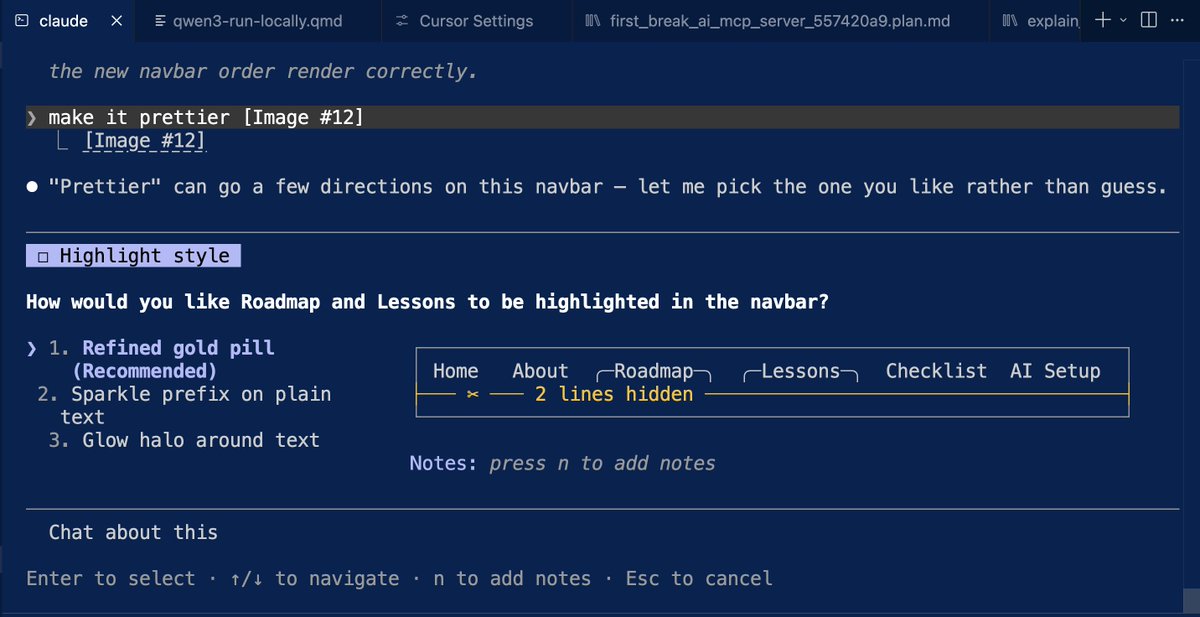
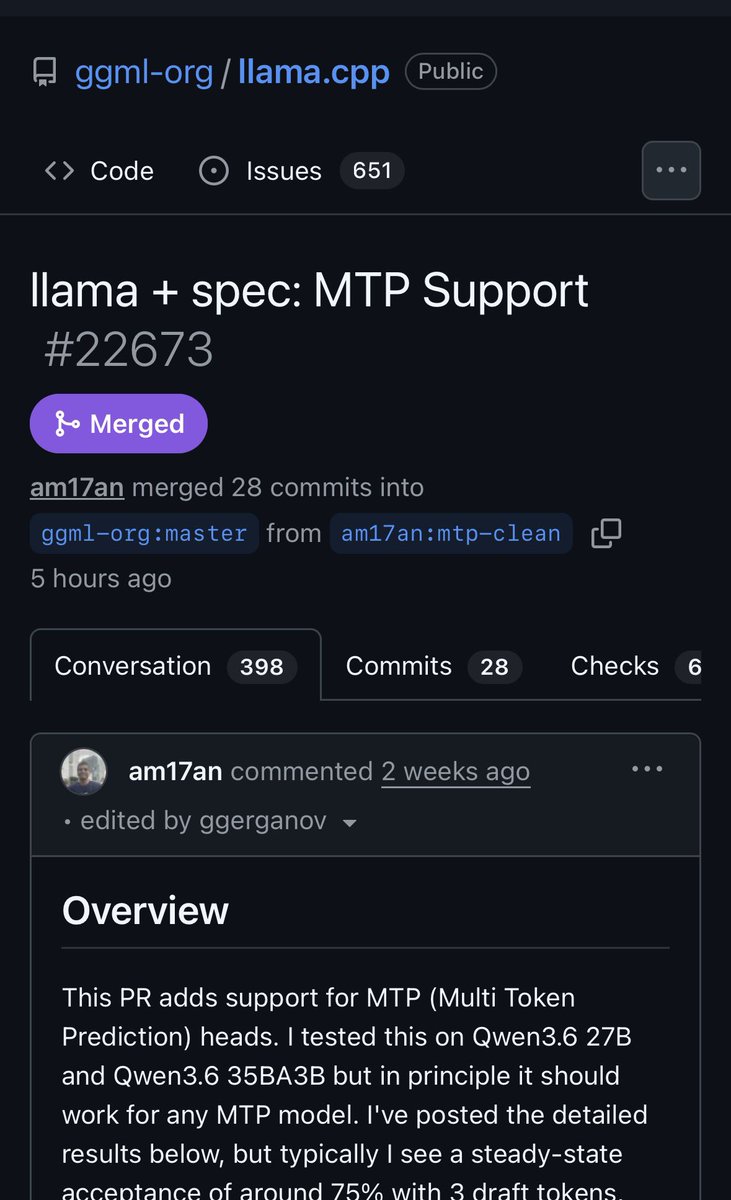






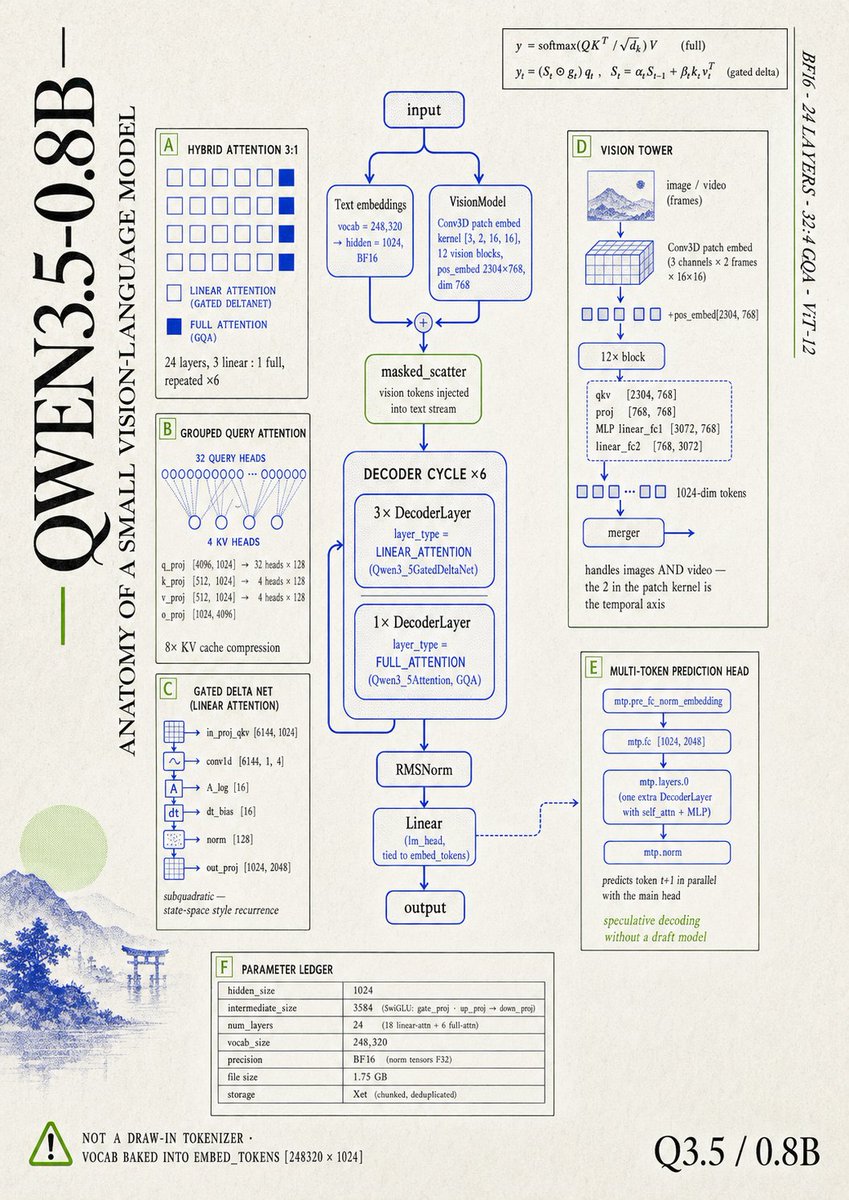
ALT Create a premium English-language poster titled "FIRST BREAK AI" in a ▎ Japanese-inspired modern editorial science-graphic style: off-white textured ▎ paper, deep black vertical serif typography, electric cobalt blue technical ▎ linework, acid green highlight accents, thin rule lines, boxed annotations, ▎ sparse labels, asymmetrical grid, large negative space, subtle risograph grain ▎ and halftone texture. ▎ ▎ Title set vertically along the left edge in a large, refined serif: FIRST ▎ BREAK AI. Subtitle running horizontally below or beside: "ANATOMY OF A FIRST ▎ BREAK IN AI · COHORT 01 · 1 MAY – 30 JUNE 2026". Right-edge vertical ▎ micro-caption: "ROADMAP · 6 STEPS · QWEN3-0.6B · OPEN COHORT". ▎ ▎ The dramatic central diagram is the canonical LLM inference spine — input → ▎ text embeddings (vocab = 151,936 → hidden = 1024, BF16) → Qwen3DecoderLayer ▎ ×28 → RMSNorm → Linear (lm_head, tied to embed_tokens) → output — drawn ▎ vertically as the visual anchor