
Founder @ AIEDX. Building FetchLens.ai — AI agent traffic intelligence. First Break AI: LLM training, inference & AI product. cohort.bubblnet.com
Joined April 2011
- Tweets 7,921
- Following 431
- Followers 499
- Likes 16,327
621 Photos and videos










Pinned Tweet

May 13
This is one of the most crucial lessons in First Break AI.
It teaches you how to navigate @huggingface like a pro.
Not just:
download model → run notebook → move on
In this lesson, we go deeper.
We look at how open model repos are structured, how to read model files, how config.json connects to the actual model class, and how to trace from a Hugging Face model page into the Transformers code that runs the model.
We use Qwen3-0.6B as the learning model.
We also look at why Markdown matters so much in AI workflows: model cards, GitHub issues, README files, Discord, Cursor, Claude Code, planning docs, and AI-assisted work.
Then comes the biggest win: datasets.
Working with datasets is a core AI engineering skill.
I show 3 ways to analyze datasets on Hugging Face:
Croissant endpoint
Data Studio / browser viewer
load_dataset with Python, pandas, and plots
We inspect dataset structure, categories, response lengths, distribution, short examples, long examples, and how to think about dataset quality before using it for training or fine-tuning.
And this sets up the next part:
running Qwen3 directly in C, without treating Transformers as magic.
Lesson 01: Hugging Face Beyond Upload
Watch:
youtu.be/MjZio-A9oUY
Free cohort:
cohort.bubblnet.com/lessons/…
5
10
277

Today, with the US banning some frontier models from foreign access, it is a wake up call for India. By 2030 India needs to run on own frontier AI models, OS & Apps, and digital currency. Or 2030s may become the new 1730s - if you know what I mean.

As a civilizational state with a billion people, India needs to have its own AI, own Internet (including SM), and own crypto currency. There are no two ways about this. If we do not have these three by 2030s, we will once again be a subservient nation of sepoys the next century.
272
1,498
7,706
204,408
FireHacker retweeted

Jun 13
Spine always grows in the back that is against the wall. America denied us crucial LOX/LH₂ cryogenic engine technology. We developed it indigenously and using it we now send American satellites into space.
India can remain sovereign only if it has a sovereign AI. @narendramodi
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
470
3,462
16,099
720,134

FireHacker retweeted

Jun 13
Sir, they have blocked access to the very AI models you said we should share instead of build

Apr 29

India doesn't need to lead the world in building the most advanced AI models. But it must lead in ensuring benefits of AI are widely shared.
@rvenk and I have an op-ed in The @EconomicTimes
economictimes.indiatimes.com…
183
2,405
11,837
419,636
Jun 10
Is there a prompt guide for Fable?.
Fable uses most of the quota in just few prompts and still feels nerfed.
I tried to use fable for a serious task like product analysis. It gave sharp analysis however looks like model is shy about tool calls. It doesn't want to collect a lot of information and I had to push it hard to do real analysis.
Analysis overall is sharper than Opus , however this feels like a nerfed model .
Is there prompt guide or direction how to use this model effectively?
1
2
84
FireHacker retweeted

Jun 9
This is not a day for celebrating, Andrej.
It's a very dark and very sad day, and the damage may be impossible to undo.
107
242
4,363
376,968
FireHacker retweeted

Jun 9
Labs starting to pull up the ladders on the ability to diffuse AI was inevitable. Doing it without telling the user is misaligned.
When Fable 5 is used for frontier LLM development, it does not notify the user and instead limits the model’s capabilities through methods such as prompt modification, steering vectors, and PEFT.
Anthropic estimated that this would affect approximately 0.03% of traffic.

57
187
1,893
287,367
Jun 9
I built a small visualization layer on top of a local Qwen3 in Pure C to understand LLM output
Image shows why sampling is not greedy decoding: a lower-probability token can still get selected when temperature/top-p keep it inside the candidate pool.
I would also love feedback on what would make a visualization like this more useful for learning:
- KV cache view?
- attention heatmaps?
- speculative decoding comparison?
- greedy vs top-p side-by-side?
1
1
4
106
FireHacker retweeted

Jun 8
have been recently thinking about why pretrain research matters among the seemingly more crucial data/compute/rl bottlenecks and sharing my take here on what makes pretrain research (still!) vital:
1. better computational efficiency: scalinglaw shifts, 2x less FLOPS needed to achieve the same loss, etc. plus e.g. long context settings where switching to hybrid or sparse attn can save you >90% FLOPS.
many model arch / optimizer improvements can save you >20% flops needed for the same loss - those are research innovations on every axis from training iter dimension to inter-layer and intra-layer. the effect of compounded architecture advantage is very distinctive given that ur always improving against your sota baseline.
good pretrain research might very well have already delivered you a 10x more efficient (and likewise, better under the same compute) model arch compared to three years ago, and there's still obv many inefficiencies left to be optimized. over half of the compute is still spent on pretraining when you do new from-scratch model trainings rn, and having weeks & months saved there could really allow much more rapid iterations across the entire stack, compounded.
2. to train models one couldn't have been able to previously: residuals, optimizers, etc. this one's less common since most of the arch innovations don't offer more beyond the expressivity gain. but there are significant ones which can e.g. provide more stable learning dynamics (both theoretically and in practice) at all scales so one could scale up. new model configs or forms of training also come back to better efficiency
data/compute/FLOPS bottlenecks certainly exist but are relatively more orthogonal to pretrain research and imo it is unclear whether one will be a clear intelligence bottleneck a year from now than the other.
in hindsight ive been using "pretrain research" tho this itself is an inefficiency (with further inefficiencies under its scaling law) and "deep learning research" is a better phrasing.
3
18
265
31,579
FireHacker retweeted

Jun 8
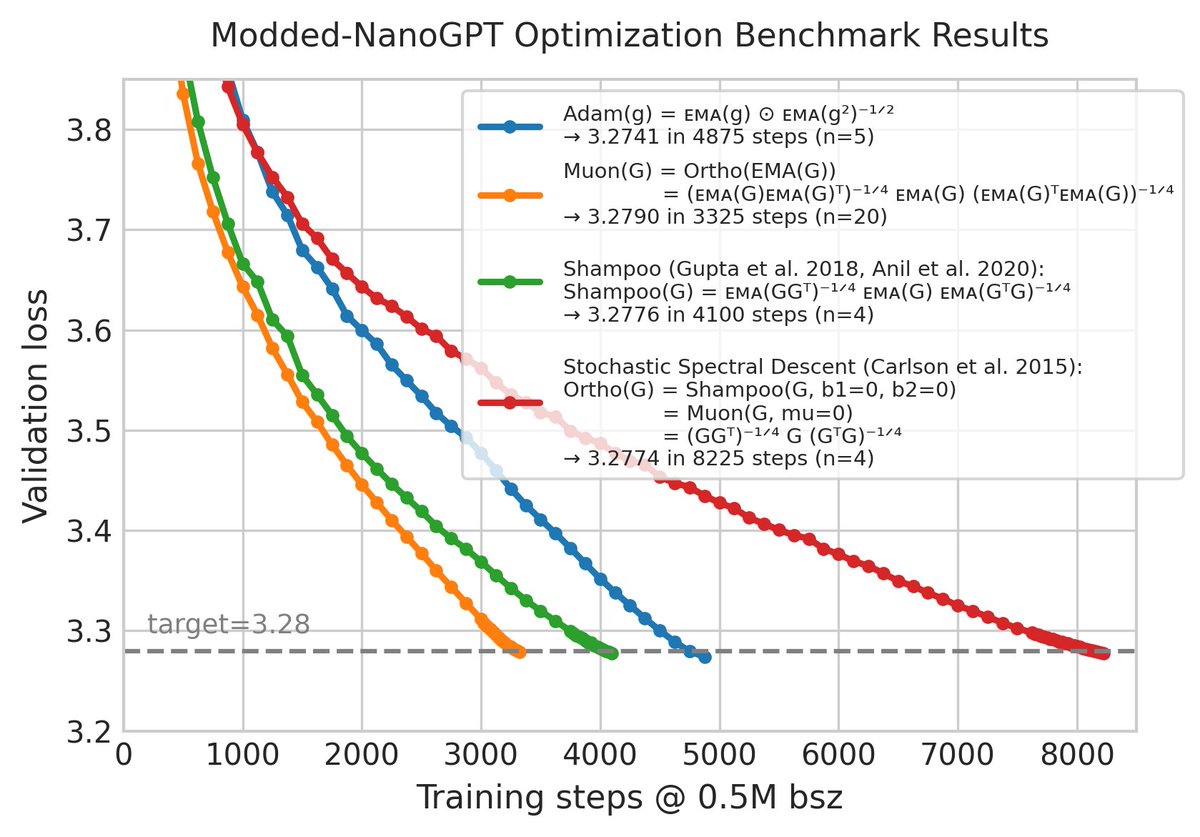
My response to the claim that Muon is a renamed version of Shampoo
x.com/kellerjordan0/status/2…
Jun 8

I've added two optimizers to the public benchmark:
(1) Shampoo (with its original 1/4 power).
(2) Spectral descent, which is equivalent to both Muon(mu=0) and Shampoo(b1=b2=0).
Result: Shampoo falls halfway between Muon & Adam; Spectral descent is ~2x slower.
Thread below
1/6
2
67
7,064
FireHacker retweeted

Jun 7
one of my favorite projects is Marin from the stanford folks, they have a scientific approach to training, are ready to take risks and are fully open (even open development where you can follow everything on github!)
github.com/marin-community/m…

Jun 7

Do I understand it correctly that the OLMo from-scratch series is coming to an end?
If so, looks like NVIDIA stepped up just in time with Nemotron models as the only remaining fully-open (ie not just weight drop) from-scratch LLM team.
5
13
282
32,848
FireHacker retweeted

Jun 7
51
125
1,049
136,108
Jun 5
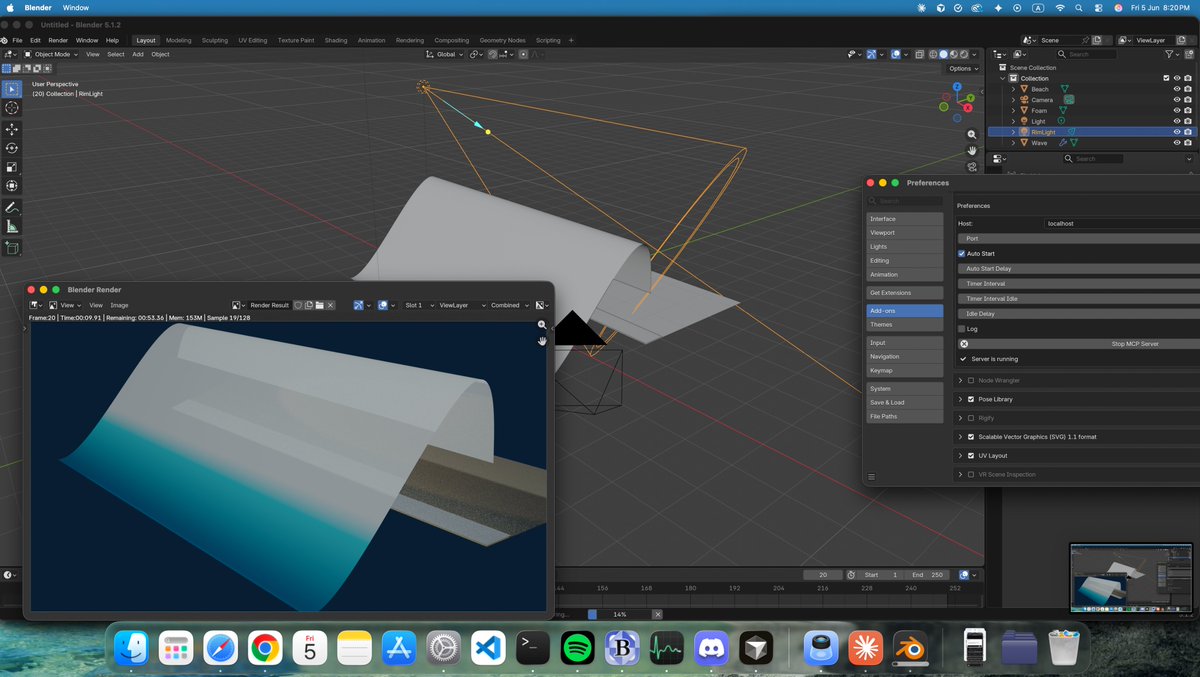
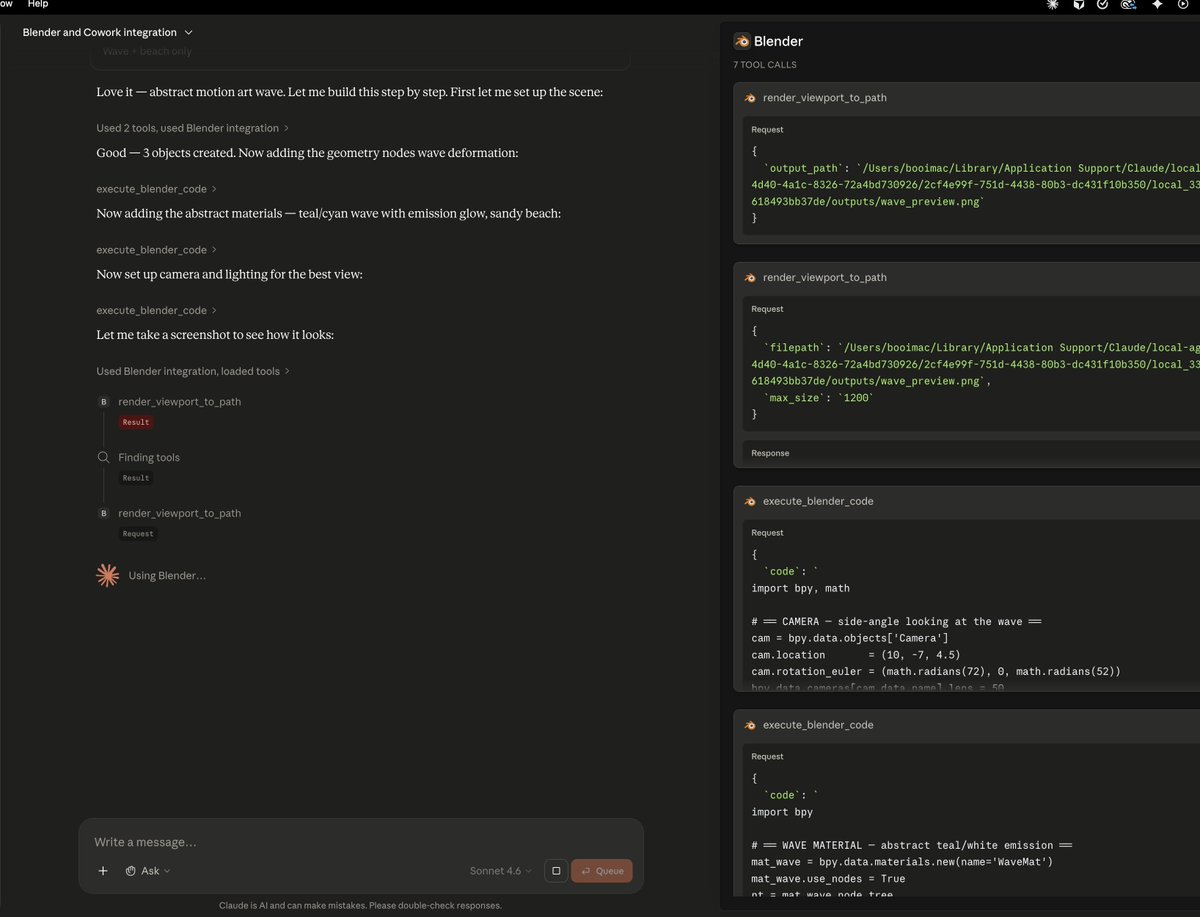
Claude Cowork with blender is so much fun, still work in progress will post the final scene soon.
Trying out if it can build basic geometry nodes scene like waves hitting a beach 🌊🏖️
1
3
4
63
FireHacker retweeted
Jun 4
We have another 65 page frontier model report from Nvidia to read @eliebakouch @stochasticchasm and gang

18
59
686
54,651
FireHacker retweeted

Jun 4
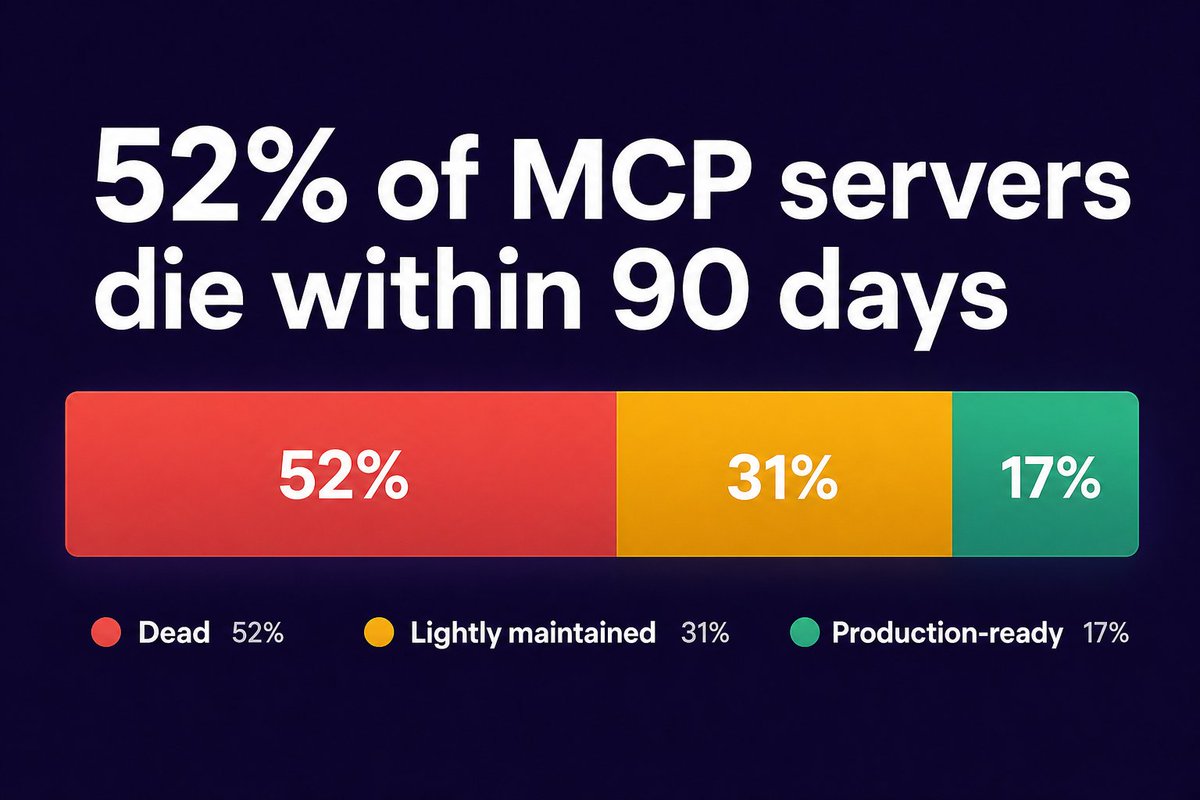
52% of MCP servers are dead within 90 days.
But the median server has 6 commits — lifetime.
The protocol works. The logic layer doesn't exist.
Content goes stale. Tools stay isolated. Nobody monitors what fails.
Full research: fetchlens.ai/research/mcp-se…
4
4
64
FireHacker retweeted

Extremely Rare Red Sprites Spotted Flashing Over Tibet. They are caused by high levels of electrical activity and form in the upper atmosphere during powerful thunderstorms.
209
3,730
24,463
581,624
FireHacker retweeted

Jun 2
KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
May 6

🚀 New on the @vllm_project blog: Serving Agentic Workloads at Scale with vLLM x Mooncake.
Agentic traces grow to 80K tokens with 94% reusable prefixes, but local KV caches evict them and cross-instance routing misses them.
By integrating Mooncake Store as a distributed KV cache pool, vLLM gets:
🚀 3.8x higher throughput
⚡ 46x lower P50 TTFT
⏱️ 8.6x lower E2E latency
📈 Cache hit rate 1.7% -> 92.2%
🌐 Scales near-linearly to 60 GB200 GPUs at >95% hit rate
🔥 Powered by a deep collaboration between @Inferact and @KT_Project_AI
📖 Read more: vllm.ai/blog/mooncake-store
🧵👇
14
25
337
31,076
FireHacker retweeted
Jun 2
WOW microsoft new "MAI Thinking 1" model comes with a 109 page tech report that looks REALLY detailed, this is amazing

24
120
987
199,645
FireHacker retweeted

Jun 2
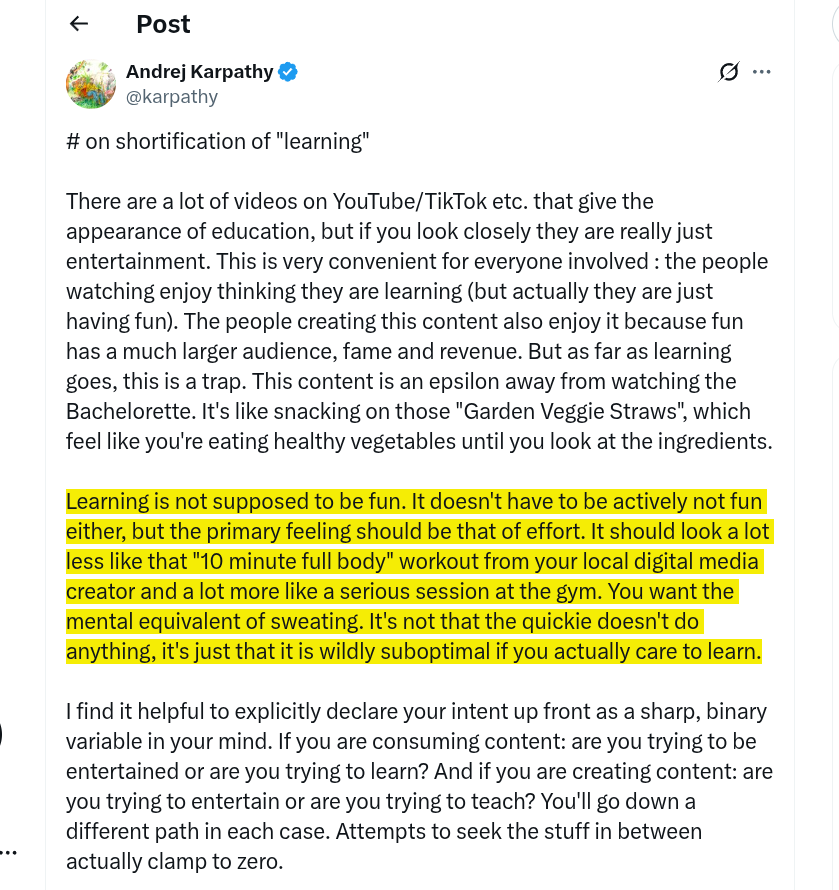
🎯 Andrej Karpathy on how to learn.
51
748
6,263
207,729
FireHacker retweeted

May 28
Fantastic. Mostly 𝐬𝐢𝐧(𝐱). Name it... Fireeel? Remix in #Wolfram Mathematica. Full code below.
x = Range[0., 9999]; k = 4 Cos[x/21];
e = x/1880 - 20; d = Sqrt[k^2 e^2];
m = UnitStep[k^2 - 15];
Manipulate[With[{
q = 3 Sin[2 k] .3/k k*Sin[x/4465](9 2*Sin[14*e-3*d 2*t])},
Graphics[{
Blend[{White, Red}, Sin[t]^2], Opacity[.5], PointSize[.01],
Point@Pick[#, m, 1],
White, Opacity[.75], PointSize[.0025],
Point@Pick[#, m, 0]}&@
Transpose@{q 50*Cos[d-t] 200, 875-q*Sin[d-t]-39*d},
PlotRange -> {{100, 300}, {75, 320}}, Background -> Black]],
{t, 0, 2 Pi}]
May 7

a=(x,y,d=mag(k=4*cos(x/21),e=y/8-20))=>circle((q=3*sin(k*2) .3/k sin(y/19)*k*(9 2*sin(e*14-d*3 t*2))) 50*cos(c=d-t) 200,q*sin(c) d*39-475,k*k>15?2:1)
t=0,draw=$=>{t||createCanvas(w=400,w);background(9).noStroke().fill(w,116);for(t =PI/240,i=1e4;i--;)a(i,i/235)}#つぶやきProcessing
7
60
456
19,483