
AI Enabled Discovery & eXperience. We are a Disruptive Tech company. Our mission is help our users to create , maintain & organise Artificial Intelligence.
Joined August 2018
- Tweets 204
- Following 69
- Followers 19
- Likes 402
12 Photos and videos









Pinned Tweet

Jun 4
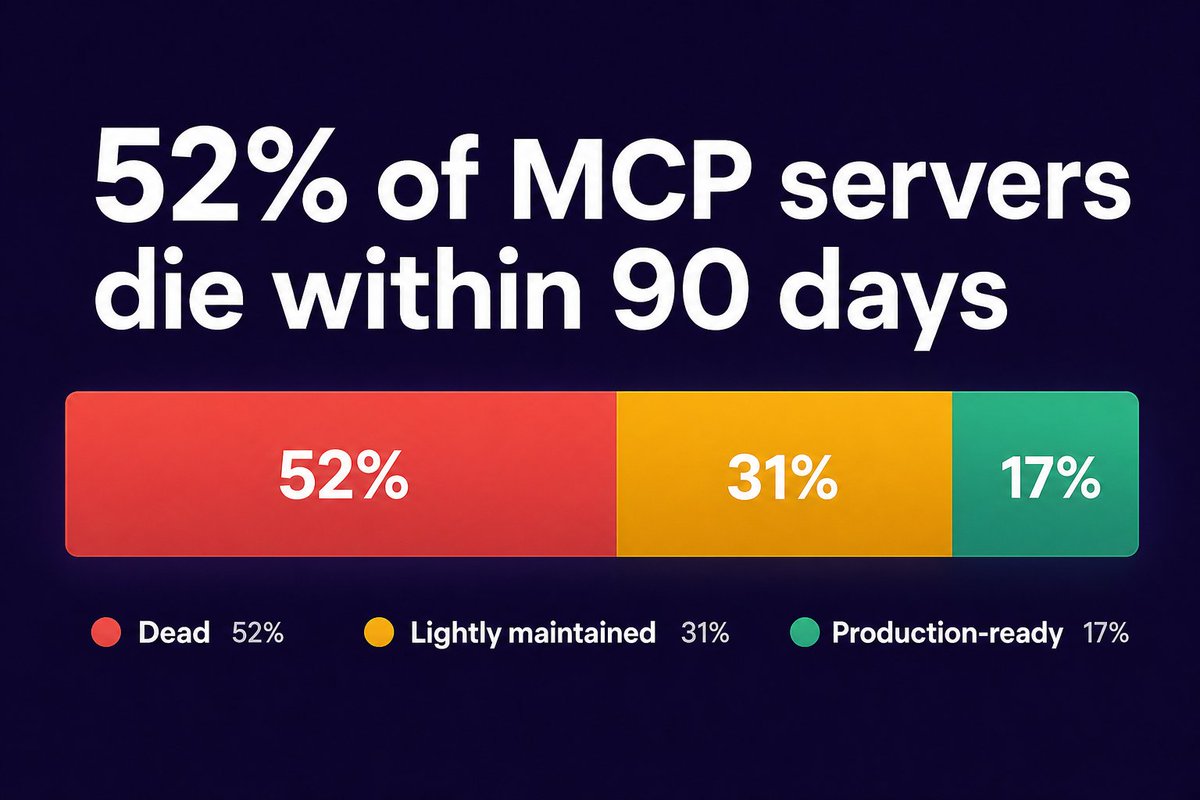
52% of MCP servers are dead within 90 days.
But the median server has 6 commits — lifetime.
The protocol works. The logic layer doesn't exist.
Content goes stale. Tools stay isolated. Nobody monitors what fails.
Full research: fetchlens.ai/research/mcp-se…
4
4
64
Fetchlens.ai retweeted

May 12
Where are small Models like Qwen3 0.6B and Qwen3.5 0.8B used ?
Huggingface shows 2.88 million downloads this month.
I can see 2.88 million downloads per month for small Qwen3.5 model. I tried using earlier model 0.6B in a deep resarch workflow and it was very difficult to get something done with this model .
Firstly they have a very surface level understanding of concepts. Poor Semantic understand means they can get confused about the topic or the task.
Json outputs are often broken . Adding a layer of checks on top took much of my time while working with these models.
Slow resposne. This one depends on a lot of factors and can actullay be improved , still slow response is a buzz kill most of the time
I am very curious how is the community using these models.

2
2
6
223
Fetchlens.ai retweeted
May 12
🚨 Major supply-chain attack: Mini Shai-Hulud is back
Reported impact:
• 170 npm/PyPI packages affected
• 400 malicious package versions
• 42 TanStack packages, including @tanstack/react-router
• UiPath packages
• Mistral AI SDK packages on npm/PyPI
• OpenSearch JS client
• Guardrails AI others
This one targets developer CI/CD secrets, so teams should check lockfiles, CI logs, npm/PyPI installs, and rotate exposed tokens.

‼️🚨 UPDATE: The TanStack npm attack is now a full campaign.
'Mini' Shai-Hulud has hit:
- OpenSearch
- Mistral AI
- Guardrails AI
-UiPath
- Squawk packages across npm and PyPI
The malware specifically targets AI developer tooling. It hooks into Claude Code (.claude/settings.json) and VS Code (.vscode/tasks.json) to re-execute on every tool event, long after the infected package is gone. npm uninstall does not fix this.
1
2
5
344
Fetchlens.ai retweeted
May 13
This is one of the most crucial lessons in First Break AI.
It teaches you how to navigate @huggingface like a pro.
Not just:
download model → run notebook → move on
In this lesson, we go deeper.
We look at how open model repos are structured, how to read model files, how config.json connects to the actual model class, and how to trace from a Hugging Face model page into the Transformers code that runs the model.
We use Qwen3-0.6B as the learning model.
We also look at why Markdown matters so much in AI workflows: model cards, GitHub issues, README files, Discord, Cursor, Claude Code, planning docs, and AI-assisted work.
Then comes the biggest win: datasets.
Working with datasets is a core AI engineering skill.
I show 3 ways to analyze datasets on Hugging Face:
Croissant endpoint
Data Studio / browser viewer
load_dataset with Python, pandas, and plots
We inspect dataset structure, categories, response lengths, distribution, short examples, long examples, and how to think about dataset quality before using it for training or fine-tuning.
And this sets up the next part:
running Qwen3 directly in C, without treating Transformers as magic.
Lesson 01: Hugging Face Beyond Upload
Watch:
youtu.be/MjZio-A9oUY
Free cohort:
cohort.bubblnet.com/lessons/…
5
10
277
Fetchlens.ai retweeted
May 6
Cost/Perf tradeoffs & Evals are the most requested topics for this cohort.
I was not expecting these to make top 3. Real life signals are always different from my assumptions.
Apr 24

First Break AI
Your first break in AI — a guided journey from first commit to capstone
Free, open cohort to upskill in training, inference, and AI product building.
cohort.bubblnet.com/
Easy to follow Roadmap & AI Podcast guided journey are up.
Weekly office hours (Friday)
Join Discord Server: discord.gg/UfwdKvfku
1
5
6
73
Fetchlens.ai retweeted
Apr 9
Exactly right. And the scary part — most founders have no idea because their site looks fine in Search Console.
I ran Google Analytics on my own site. Barely any activity.
Then I built FetchLens and pointed it at the same site. 93 AI agent visits and 298 vulnerability scan probes in 7 days. GPTBot, ChatGPT-User, ClaudeBot, StealthScrapers — all hitting my pages. Google Analytics showed none of it.
AI bots are hungry for your content. They're either scraping it or failing to read it. Either way, you can't see it with traditional analytics.
The web isn't just for humans anymore.
fetchlens.ai

4
6
45
Fetchlens.ai retweeted
Feb 19
I’m trying to build this from first principles instead of focusing on any specific framework.
My goal is test effectiveness rather than test density — what you assert, where you assert it, and how fast it runs. I’m trying to provide enough data to agents so they can generate stronger assertions, think like testers, and actively try to break the app.
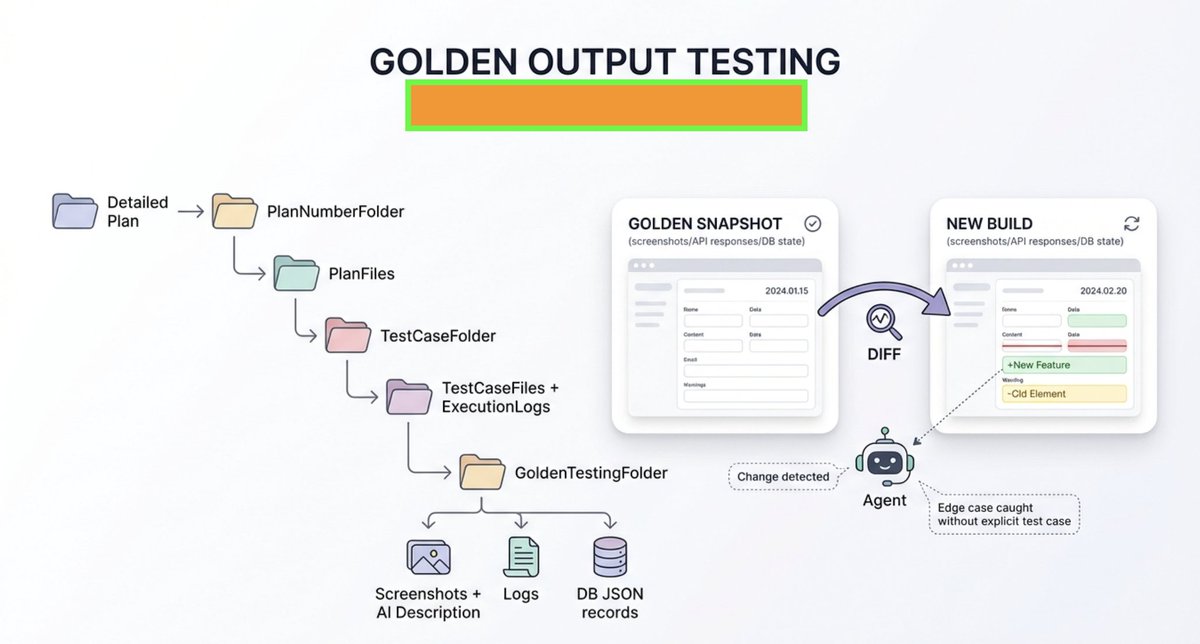
Regarding test coverage, a Reddit user suggested supplementing my approach with golden testing alongside traditional test cases. I’ve never used golden testing before, and at first it feels like a brute-force approach. I know that Flutter and Playwright support visual testing via pixel-by-pixel comparison.
In our case, golden testing would mean saving “known-good” outputs from a working version of the app — such as API responses, rendered UI snapshots/screenshots, logs, or database records — and, on every new change, re-running and diffing against those baselines. If something changes unexpectedly, you catch the regression even if you didn’t write an explicit test for that edge case.
Screenshots can also be processed through a vision-language model (VLM) to generate detailed descriptions of the app, UI elements, core features, and priority user actions. This could help detect meaningful state changes triggered by events — changes that simple pixel-by-pixel or frame-by-frame comparisons might miss.
3
6
30
Fetchlens.ai retweeted
Feb 19
One of the biggest hidden pains of building products with AI coding agents is regression testing.
A new feature written by an agent can quietly break existing functionality and wipe out days of effort. I’ve run into this multiple times.
The problem isn’t feature velocity. It’s stability.
My solution: use structured Skills for testing and documentation.
First, a quick primer.
Test cases are foundational to the Software Development Life Cycle (SDLC). Well-written test cases can often replace complex feature or requirement documents.
Once code is written, you typically perform:
1. Unit testing — validates the functionality of a single module or feature
2. Integration testing — ensures different modules work correctly together.
3.Regression testing — confirms that new changes haven’t broken existing functionality.
In many early-stage products, most of this testing is manual. Let’s assume a simple CI/CD pipeline and manual test execution for this discussion.
Here’s how I use Skills:
For large features, I create a detailed, phase-wise plan. After each phase, structured test cases are generated and stored alongside the plan. Test execution logs are maintained in the same file.
But the real leverage comes later.
In one example, I was building a dashboard for AI Personas so users could track what their agents were doing while they focused on other work. All test cases and execution logs were captured during development.
On subsequent iterations, coding agents extract the full test history and automatically generate a regression checklist. Because execution logs already exist, the agent can focus on real historical breakpoints instead of hallucinating edge cases.
You can go further:
Add an impact analysis step inside the Skill to prioritize affected requirements.
Log every PR and commit automatically.
Maintain structured change history for easier rollback.

5
5
13
252
Fetchlens.ai retweeted
Jan 14
The community's response towards Cowork gives us a strong positive signal towards what we have been building
timecapsule.bubblspace.com/
Our product works in your browser & solves a different problem.
The Problem:
How do you manage a knowledge base, user or team expertise, documents, and context across AI sessions?
Users need a platform that allows them to build and deploy workflows with ease. The platform should enable workflow management based on functions, topics, teams, or open search.
The Solution: TimeCapsule
TimeCapsule has two simple parts:
AI-Frames- Helps build knowledge bases and workflows.
Sage Mode- Real-time voice-to-voice AI persona.
1. AI-Frames: Upload documents to create a knowledge base directly in your browser. Use the Flow Builder to perform deep research and build workflows or AI Frames. These workflows can be explored in graph or linear mode (chapters and AI Frames).
2. Sage Mode: Start a real-time voice-to-voice session with an AI persona. TimeCapsule automatically detects the relevant AI Frames, searches through your knowledge base documents, and responds in real time.
3. Collaboration: Share TimeCapsule with your team. Sage sessions automatically pick up new knowledge (TimeCapsules) as workflows evolve.
@bubblspace @AIEdXLearn
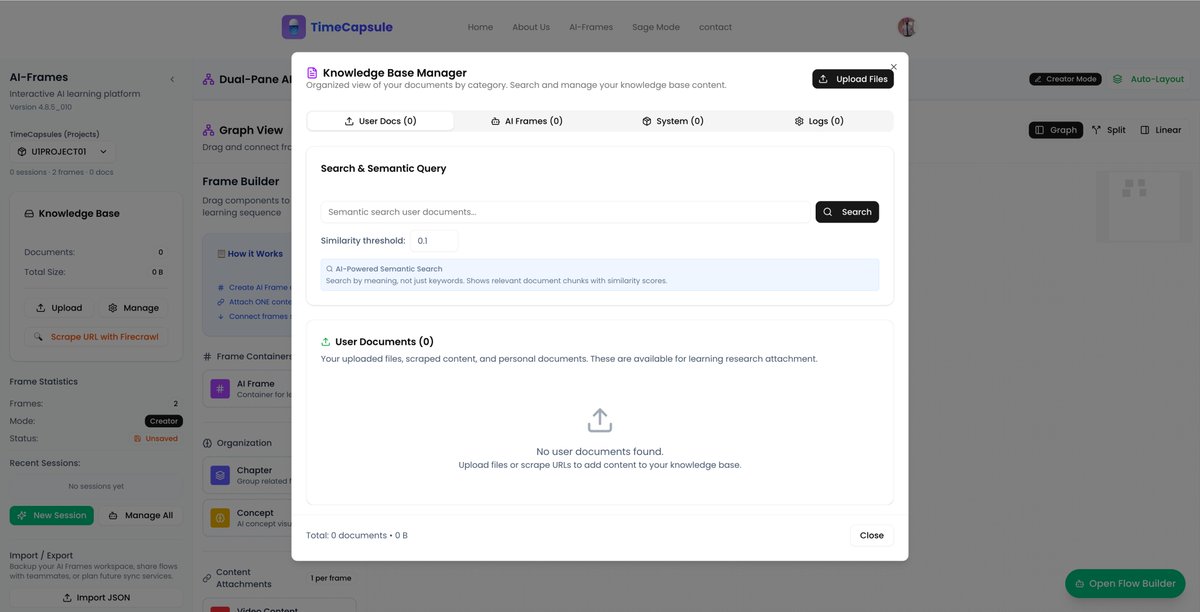
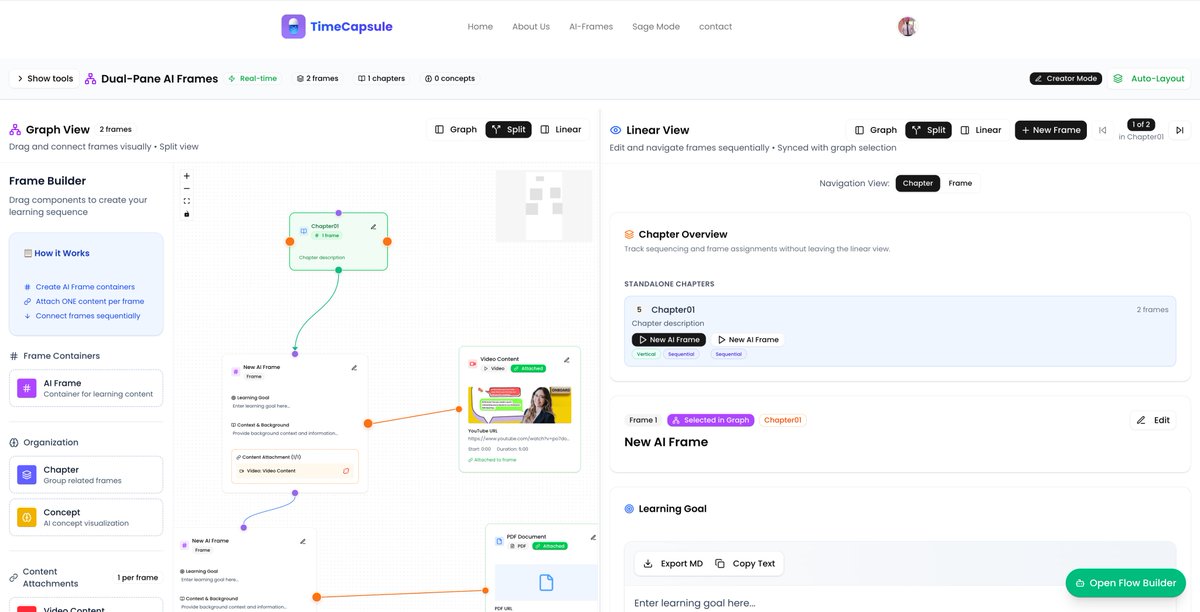


Introducing Cowork: Claude Code for the rest of your work.
Cowork lets you complete non-technical tasks much like how developers use Claude Code.
1
5
8
884
Fetchlens.ai retweeted
13 Nov 2025
Use your favourite AI coding agent to create AI frames.
What if you could connect everything—your PDFs, videos, notes, code, and research—into one seamless flow that actually makes sense?
AI-Frames: Open Source Knowledge-to-Action Platform:timecapsule.bubblspace.com
✨ Annotate • Learn • Research • Build • Automate
One prompt → AI builds your entire learning path with:
• Citations from your Knowledge Base
• Mastery checks & quizzes
• Step-by-step progression
• Vision or text modes
From scattered notes to structured knowledge. Instantly.
Watch how it works 👇
Video shows how to build with Cursor & Codex
@bubblspace @AIEdXLearn
youtu.be/gvyLzZNCe6k?si=xfiW…
1
6
10
185
Fetchlens.ai retweeted

13 Nov 2025
🤗
13 Nov 2025
Use your favourite AI coding agent to create AI frames.
What if you could connect everything—your PDFs, videos, notes, code, and research—into one seamless flow that actually makes sense?
AI-Frames: Open Source Knowledge-to-Action Platform:timecapsule.bubblspace.com/
✨ Annotate • Learn • Research • Build • Automate
One prompt → AI builds your entire learning path with:
• Citations from your Knowledge Base
• Mastery checks & quizzes
• Step-by-step progression
• Vision or text modes
From scattered notes to structured knowledge. Instantly.
Watch how it works 👇
Video shows how to build with Cursor & Codex
@bubblspace @AIEdXLearn
2
5
121
Fetchlens.ai retweeted
13 Nov 2025
Use your favourite AI coding agent to create AI frames.
What if you could connect everything—your PDFs, videos, notes, code, and research—into one seamless flow that actually makes sense?
AI-Frames: Open Source Knowledge-to-Action Platform:timecapsule.bubblspace.com/
✨ Annotate • Learn • Research • Build • Automate
One prompt → AI builds your entire learning path with:
• Citations from your Knowledge Base
• Mastery checks & quizzes
• Step-by-step progression
• Vision or text modes
From scattered notes to structured knowledge. Instantly.
Watch how it works 👇
Video shows how to build with Cursor & Codex
@bubblspace @AIEdXLearn
2
6
8
1,074
Fetchlens.ai retweeted

4 Oct 2025
Solid move — turning theory into systems that actually run. 💻
2
3
43
Fetchlens.ai retweeted

4 Oct 2025
Love how you unpacked the real mechanics behind scaling AI — clarity like this drives stronger teams and smarter systems.
2
5
57
Fetchlens.ai retweeted
4 Oct 2025
🎛️Zachary is a brilliant instructor — laser-focused on helping us learn how AI pros truly work at scale.This course genuinely bridges the gap between academic theory and real-world distributed training.
🎛️What I’ll Apply Next
🔹 Build Expert Parallelism (MoE) from scratch using a small local GPU cluster — and later scale it up with cloud GPUs for training compact models.
🔹 Recreate parts of the OLMo-2 pre-training pipeline at a much smaller scale, at least up to a few checkpoints, to study the training dynamics hands-on.
#ScratchToScale #Maven #DistributedTraining #DeepLearning #AI #LLMs #ZacharyMueller #MachineLearning #ScalingAI
3
6
60
Fetchlens.ai retweeted
4 Oct 2025
🎛️Another major highlight was the keynote and spotlight sessions — featuring exceptional speakers from top AI labs and startups. These are people who’ve actually built the tools, frameworks, and innovations we use today — from model design and scaling pipelines to production-grade training infrastructure.
Listening to them share their journeys and hard-earned lessons was both inspiring and grounding.
1
3
5
60
Fetchlens.ai retweeted
4 Oct 2025
🎛️Way Points- My Journey:
1. We started with the fundamentals of distributed training (operations such as all-reduce and broadcast). The custom nbdistributed package made it incredibly easy to get hands-on with multi-GPU training in notebooks right from week one.I know notebooks get a lot of hate — however, I feel they are an incredible learning tool. Later sessions focused on scaling scripts and deep dives into small training workflows written from scratch.
2. Then we moved on to DDP and Data Loading.
3. Covered FSDP/ZeRO and advanced parallelism (Pipeline / Tensor Parallelism). Tensor parallelism was one topic I found difficult to follow — I’m looking for additional material to bridge that gap.
4. Expert Parallelism – MoEs 😁: Another super challenging topic, but the course material on this was excellent. I’ll be going through the recordings and practicing using the code shared by Zach.
5. 2D/3D/Sequence Parallelism sessions were awesome — these were more like introduction sessions that opened new directions to explore.
My focus for this month is on DDP FSDP/ZeRO PP/TP. Once that’s solid, I’ll shift to Expert Parallelism (EP).
1
2
6
53
Fetchlens.ai retweeted
4 Oct 2025
🎯 Milestone Unlocked
I’m excited to share that I’ve completed the “Scratch to Scale: Large-Scale Training in the Modern World” course by @TheZachMueller on maven !
Scratch to Scale has been one of the most practical and insightful courses I’ve taken — it goes far beyond theory.
👉 Special thanks to @TensorSlay for pointing me toward this epic course!

5
8
10
756
Fetchlens.ai retweeted
21 Aug 2025
🔥1 month of effort and first signs of success!
Final Product: TimeCapsule-SLM
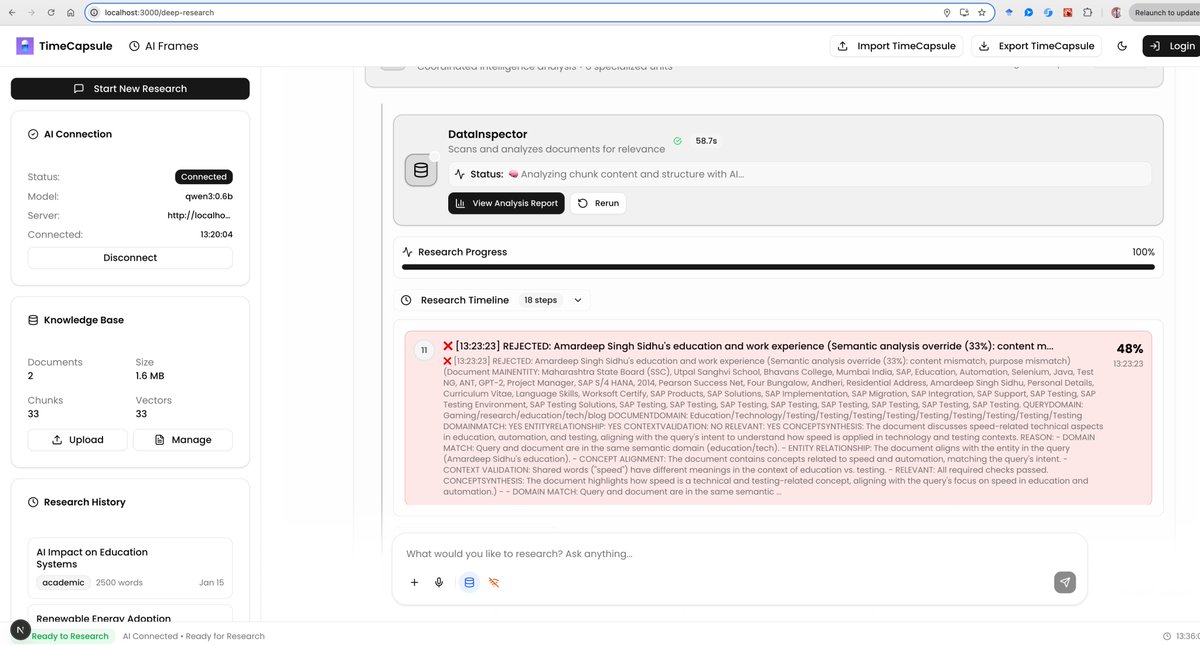
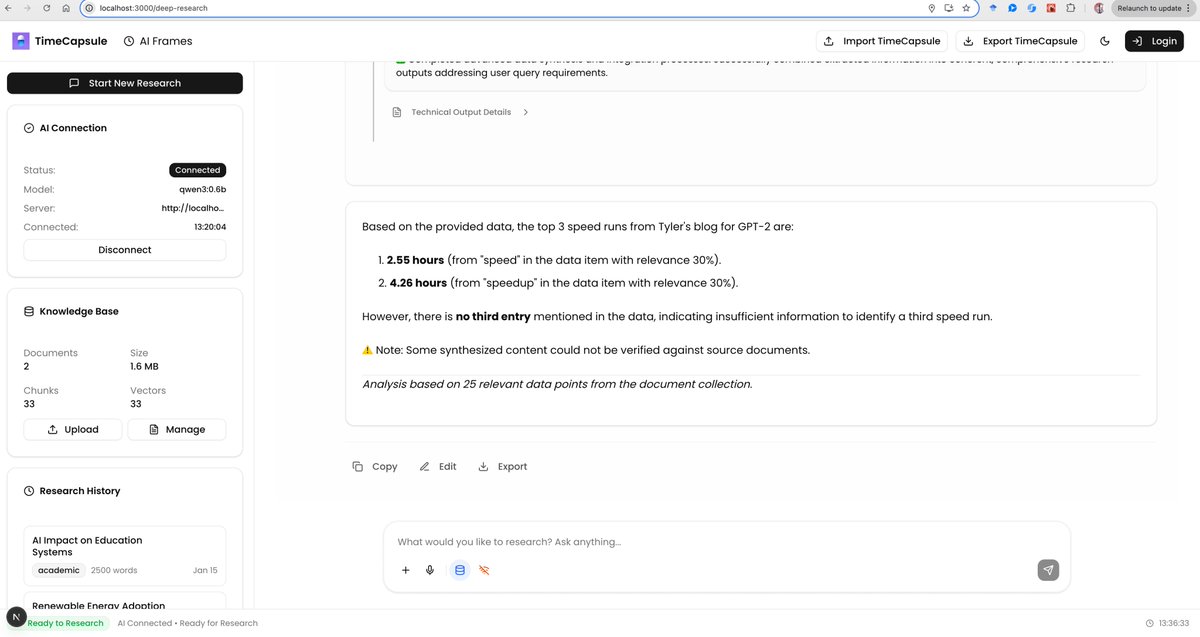
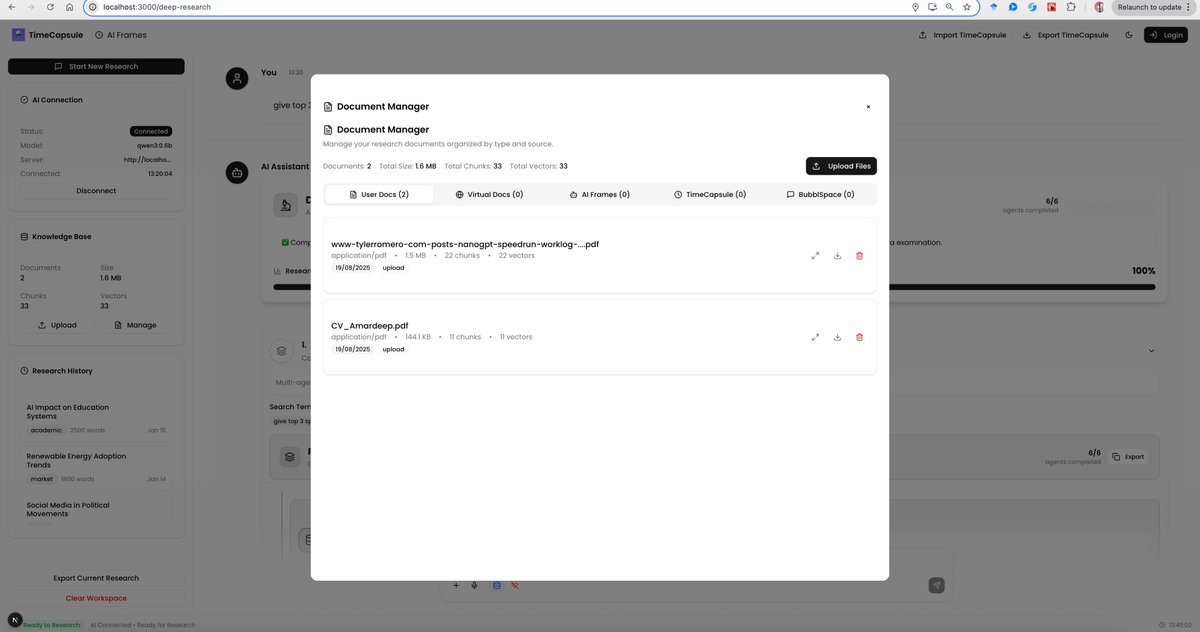
An Open Source Deepresearch that works in browser with Qwen 3 0.6b(ollama) that has semantic understanding , provide insights & generate novel ideas . Privacy first local Deep Research.
👽 timecapsule.bubblspace.com/
🧑💻 github.com/thefirehacker/Tim…
🔐The Problem :
AI products fail to understand context of query. Hallucinate difficult to tarck if infromation is correct and where did it source from . Just source attribution is also not useful.
🪄Magic:
TimeCapsule-SLM is able to reject my CV which has the word "automation" in it and reasons that word "speed" has different meaning and looks for data that is more alinged with query! It can create Regex patterns and do flat file type search along with semantic search on chunks/docs.
📔You can traceback results to exact chunks/docsuments giving relaibilty and grounding of Data with your local knowledgebase.
Took 5-9 minutes to get result. System has deep understanding of Knowledgebase. Next Steps allow sytem to use these insights to build things for you ( Lesson plan , short form content , deliver sales presentation, enterprise learning, come up with novel ideas)
This also works well with gemma3n 2B ( some issues will test ,fix and push changes soon) . Also system keeps missing little data from source will patch up the issue soon.
Data Source: Tyler's blog on GPT-2 speedrun
tylerromero.com/posts/nanogp…
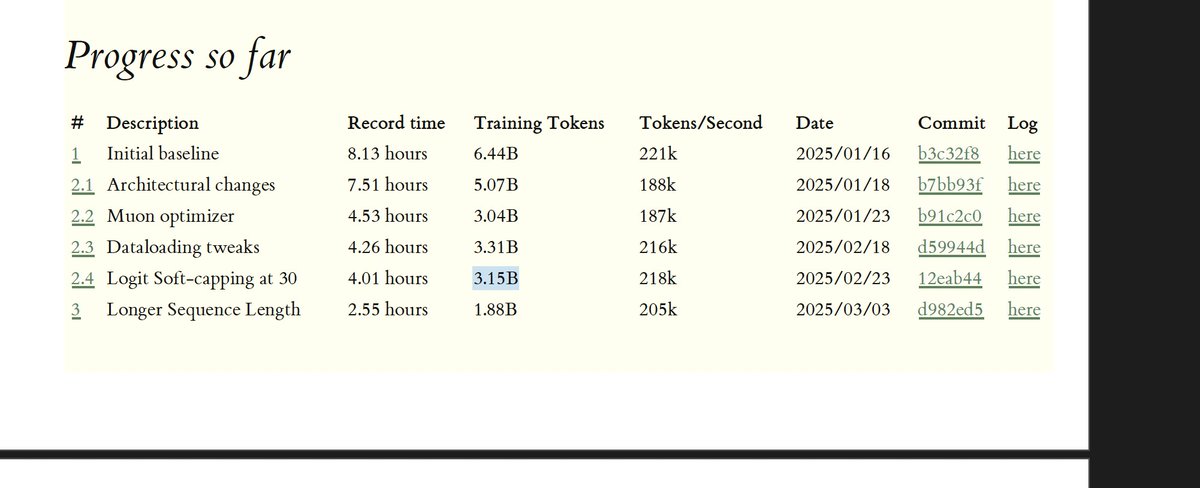
3
10
17
1,687
Fetchlens.ai retweeted
3 Jul 2025
We are totally trending 🚀on @ollama r/ollama & github.
Deepresearch RAG all in browser
timecapsule.bubblspace.com
reddit.com/r/ollama/comments…
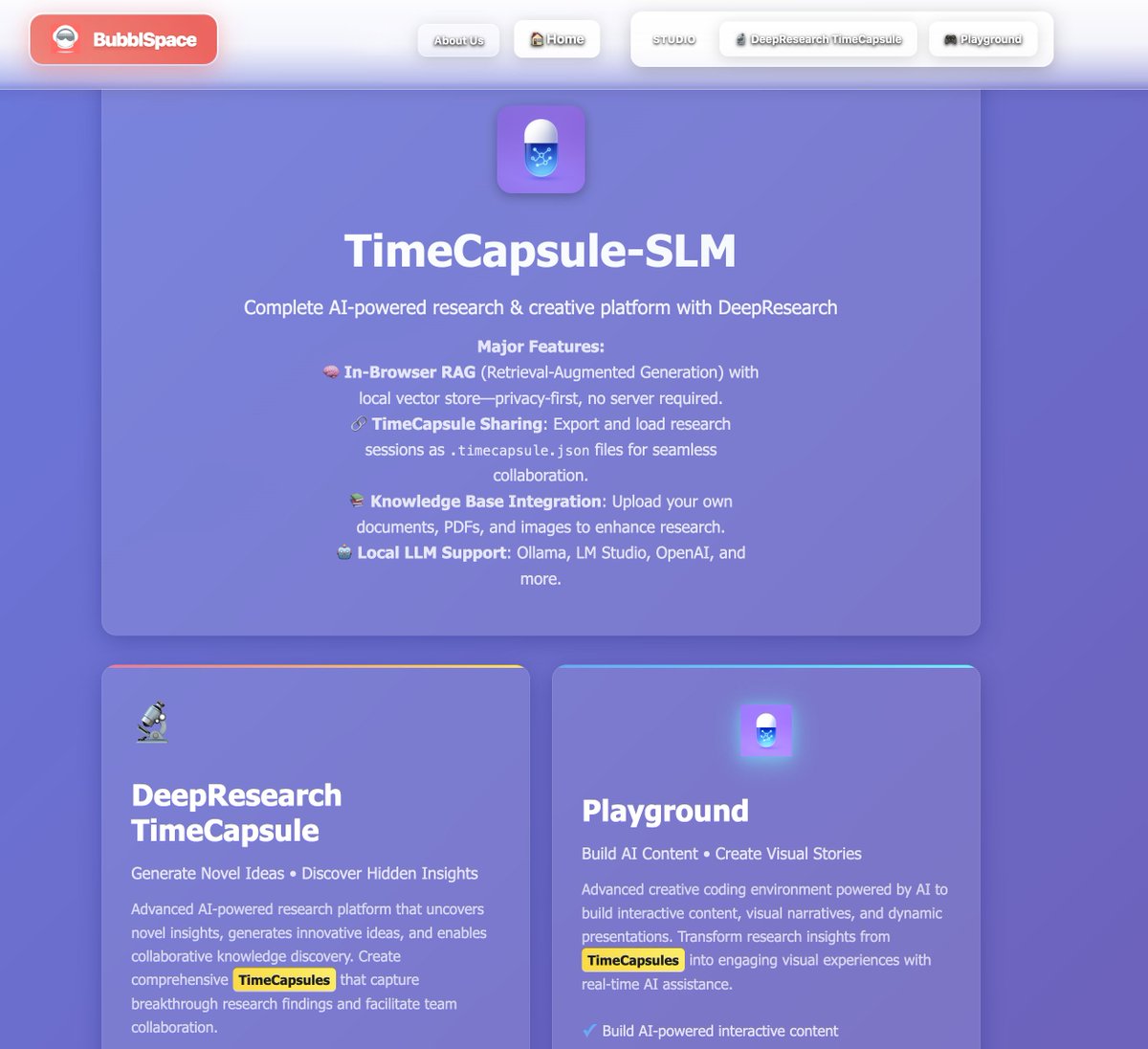
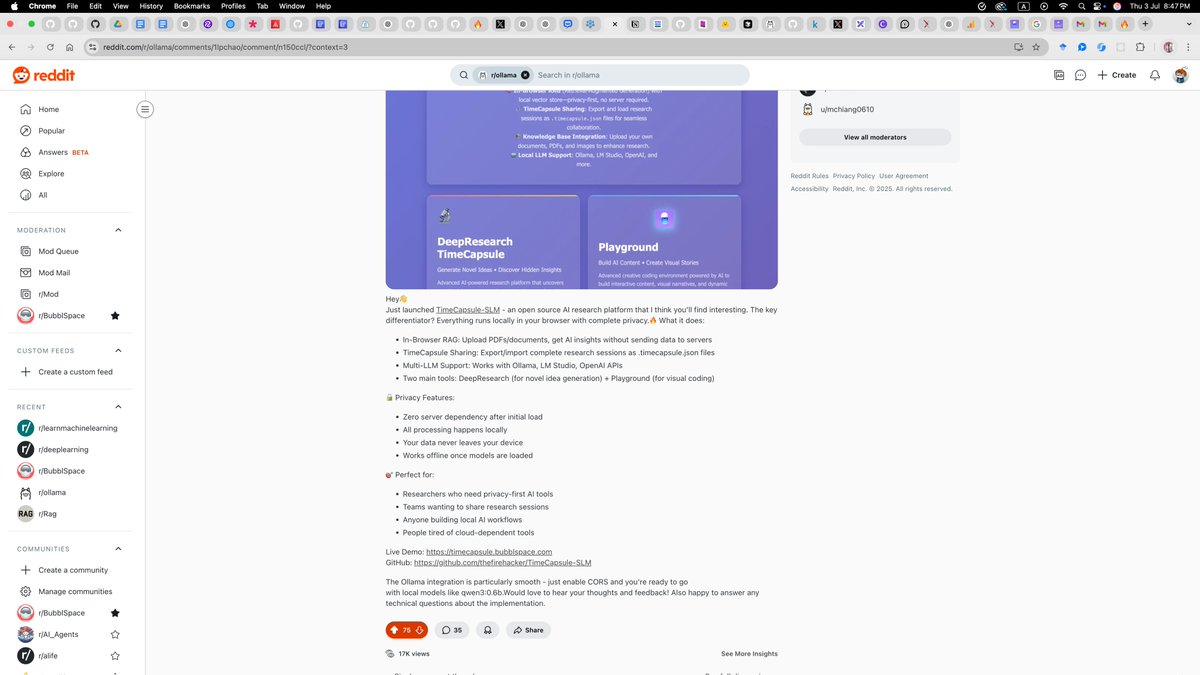
2
9
19
727