
The Rahnavard Lab at the George Washington University @GWtweets: Omics Data Science for Public Health and Precision Medicine @GWpublichealth
Joined October 2019
- Tweets 153
- Following 77
- Followers 151
- Likes 372
59 Photos and videos














The Rahnavard Lab | GW retweeted

11 Dec 2025
2026 is off to a great start! 🎉
Honored to present our microbiome immunotherapy work at the @WCM_MeyerCancer next month (joint work with the @RahnavardLab). 🧬🦠🔥
Here’s to a busy and inspiring year ahead! 🚀
#Statistics #Biostatistics #DataScience #Cancer #Microbiome

1
2
107

15 Jul 2025
Antibiotic resistance is outpacing traditional detection methods. Led by Matthew Mollerus, we introduce resLens, a family of genomic language models that learn latent DNA representations to detect and analyze ARGs without rigid reference databases.
12 Jul 2025

resLens: genomic language models to enhance antibiotic resistance gene detection biorxiv.org/content/10.1101/… #biorxiv_bioinfo
50
The Rahnavard Lab | GW retweeted
24 Mar 2025
🧪🦠 𝐓𝐡𝐞 𝐜𝐚𝐧𝐜𝐞𝐫 𝐦𝐢𝐜𝐫𝐨𝐛𝐢𝐨𝐦𝐞 𝐜𝐨𝐧𝐭𝐫𝐨𝐯𝐞𝐫𝐬𝐲 𝐢𝐬 𝐟𝐢𝐧𝐚𝐥𝐥𝐲 𝐛𝐞𝐡𝐢𝐧𝐝 𝐮𝐬 🧠🧬
What began as a side project at @Merck evolved into a full-scale discovery effort — a nearly two-year meta-analysis led by Xinyang Zhang and the @RahnavardLab Lab, culminating in a #preprint and dissertation chapter.
📊 678 melanoma patients
📚 7 independent studies
🧬 Faecalibacterium SGB15346 consistently linked to immune checkpoint inhibitor (ICI) response
🔬 RiPP gene clusters and SCFA pathways reveal new mechanistic insights into treatment efficacy
🛠️ Fully reproducible pipeline built using the latest bioinformatics tools
🔍 A first-of-its-kind integration of microbial species, biosynthetic gene clusters, and functional pathways in the context of ICI — a major step toward microbiome-guided precision immunotherapy.
🎉 Huge congratulations to Xinyang, and sincere thanks to the @RahnavardLab for their collaborative partnership throughout this work!
Link: biorxiv.org/content/10.1101/…
#CancerImmunotherapy #Microbiome #Omics #DataScience #Statistics #Biostatistics

3
7
228
The Rahnavard Lab | GW retweeted

15 Mar 2025
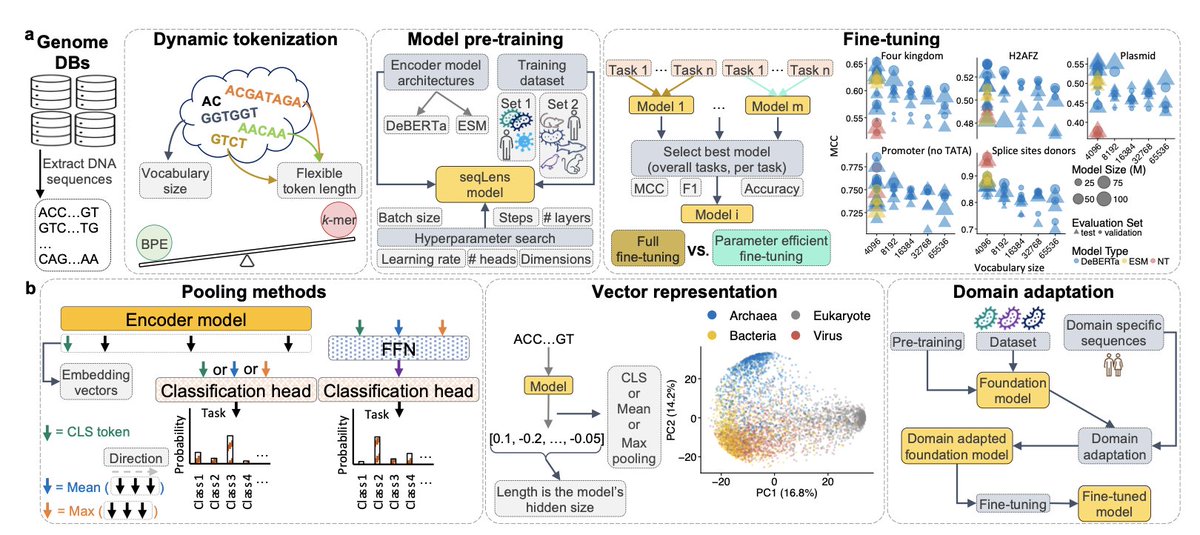
seqLens: Optimizing Language Models for Genomic Predictions
1. The paper introduces seqLens, a family of DNA language models designed for genomic predictions, leveraging disentangled attention with relative positional encoding to enhance performance across multiple genomic tasks.
2. Unlike conventional DNA language models that rely on fixed k-mer tokenization, seqLens employs byte-pair encoding (BPE), allowing dynamic token lengths that improve convergence and reduce computational overhead.
3. The study systematically compares seqLens models to existing state-of-the-art DNA models, demonstrating superior performance in 13 of 19 benchmarking tasks, including phenotype prediction and genome annotation.
4. Two large-scale pretraining datasets were used: one containing 19,551 reference genomes (predominantly bacterial) and another with a broader taxonomic balance, including eukaryotic and archaeal genomes, covering 180 billion nucleotides.
5. seqLens models integrate multiple architectural improvements, including the DeBERTa-inspired disentangled attention mechanism, which separately encodes content and positional information, leading to more efficient DNA sequence modeling.
6. The study explores various fine-tuning strategies, including full fine-tuning and parameter-efficient adaptation methods like LoRA, revealing trade-offs between computational efficiency and predictive accuracy.
7. Domain adaptation through continual pretraining significantly enhances performance on specialized genomic tasks, enabling seqLens models to effectively transfer learned representations across different genomic datasets.
8. Benchmarking results indicate that seqLens models with smaller vocabularies tend to generalize better than those with larger tokenizers, highlighting the importance of balancing vocabulary size and training efficiency.
9. Alternative pooling strategies, including mean and max pooling, are evaluated for classification tasks, with mean pooling outperforming the commonly used CLS token representation in multiple genomic benchmarks.
10. Future work aims to refine seqLens by incorporating multimodal genomic data, exploring reinforcement learning-based optimization, and expanding applications in metagenomics and regulatory sequence modeling.
📜Paper: biorxiv.org/content/10.1101/…
#GenomicAI #LanguageModels #Bioinformatics #ComputationalBiology #MachineLearning
6
14
2,308
The Rahnavard Lab | GW retweeted

15 Mar 2025
seqLens: optimizing language models for genomic predictions biorxiv.org/content/10.1101/… #biorxiv_bioinfo
9
40
3,608
The Rahnavard Lab | GW retweeted
18 Feb 2025
Excited to co-lead this tutorial with @RahnavardLab at #ENAR2025! 🎉
Looking forward to engaging discussions on cutting-edge statistical approaches in metabolomics 🔬📊.
See you on March 24 at 8:30 AM! 🚀🔬
#Omics #DataScience #Metabolomics #Statistics #Biostatistics

1
6
251
13 Nov 2024
On our way to #cshldata24 at @CSHL! Make sure to catch @chiraaggohel's talk on tools for metabolomics based epidemiology, and his poster on software for the integration of large scale metabolomics experiments! #metabolomics #bioinformatics


6
1,090
29 Oct 2024
Time to culture some great connections at the @CSHL's Microbiome meeting! Our lab's gut instinct told us this was the perfect place to share our findings :) 🦠🧬
2
86
22 Oct 2024
Our latest plate-based assay yielded some delicious results 🔬🥞

7
291
7 Aug 2024
Excited about our lab's contribution to #JSM2024, presenting our progress on omics AI: a talk on the dynamics of longitudinal omics using #waveome and a panel on the future of LLMs (omics LLMs for health), organized by @Mallick_Himel and @fraukolos, and moderated by Siyuan Ma 🙏

2
274
The Rahnavard Lab | GW retweeted
7 Aug 2024
📢 Enjoying #JSM2024 so far? Top it off with our exciting invited panel!
Join us today from 10:30 AM - 12:20 PM PDT (**see updated poster**)!
Hope to see you all there! 😊
#Statistics #Biostatistics #DataScience #ChatGPT #LLMs

3
12
1,418
22 Jul 2024
Interested in pursuing a PhD in Health Data Science? Join The George Washington University- Milken Institute School of Public Health for an info session on July 23rd, 12-1pm on Zoom. RSVP today! docs.google.com/forms/d/e/1F…
2
5
263
13 Jul 2024
2
14
832
9 Jul 2024
Our latest collaborative study led by @BarbaraKahn20's team explores how gut microbiota mediates beneficial effects of PAHSAs on metabolism. (1/4)
1
1
71
9 Jul 2024
1
58
9 Jul 2024
showcasing the role of gut microbiota in mediating the beneficial effects of dietary lipids, specifically PAHSAs, on host metabolism.
1
38
9 Jul 2024
The gut microbiota is essential for the insulin-sensitizing effects of PAHSAs, as shown by improved insulin sensitivity in HFD-fed germ-free mice after fecal transfers from PAHSA-treated mice.
37