
Co-Founder & CTO @haptik & @heyinterakt I AI & tech, productivity and whatever else comes to mind of a founder trying to have an impact. Tweets are my own.
Joined May 2009
- Tweets 918
- Following 526
- Followers 1,664
- Likes 1,399
79 Photos and videos








Mar 18
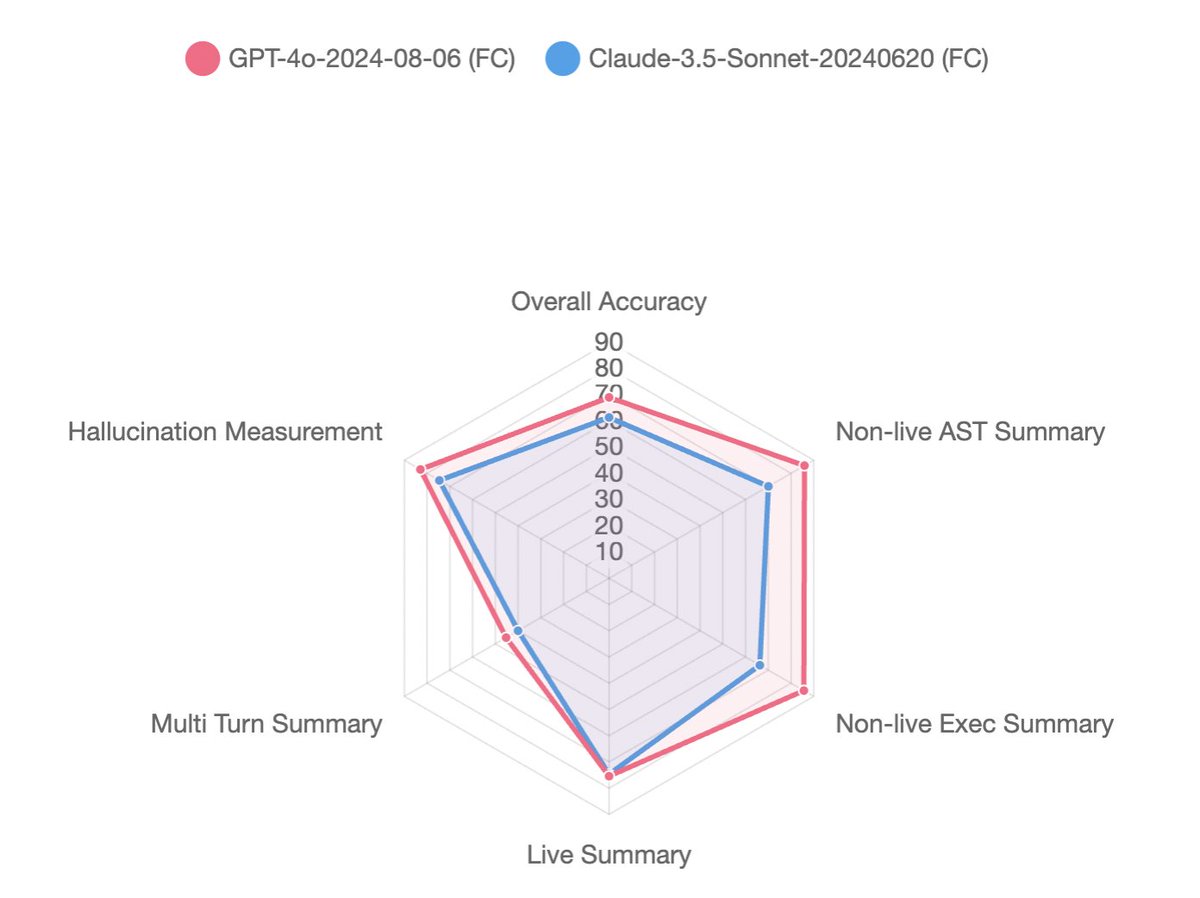
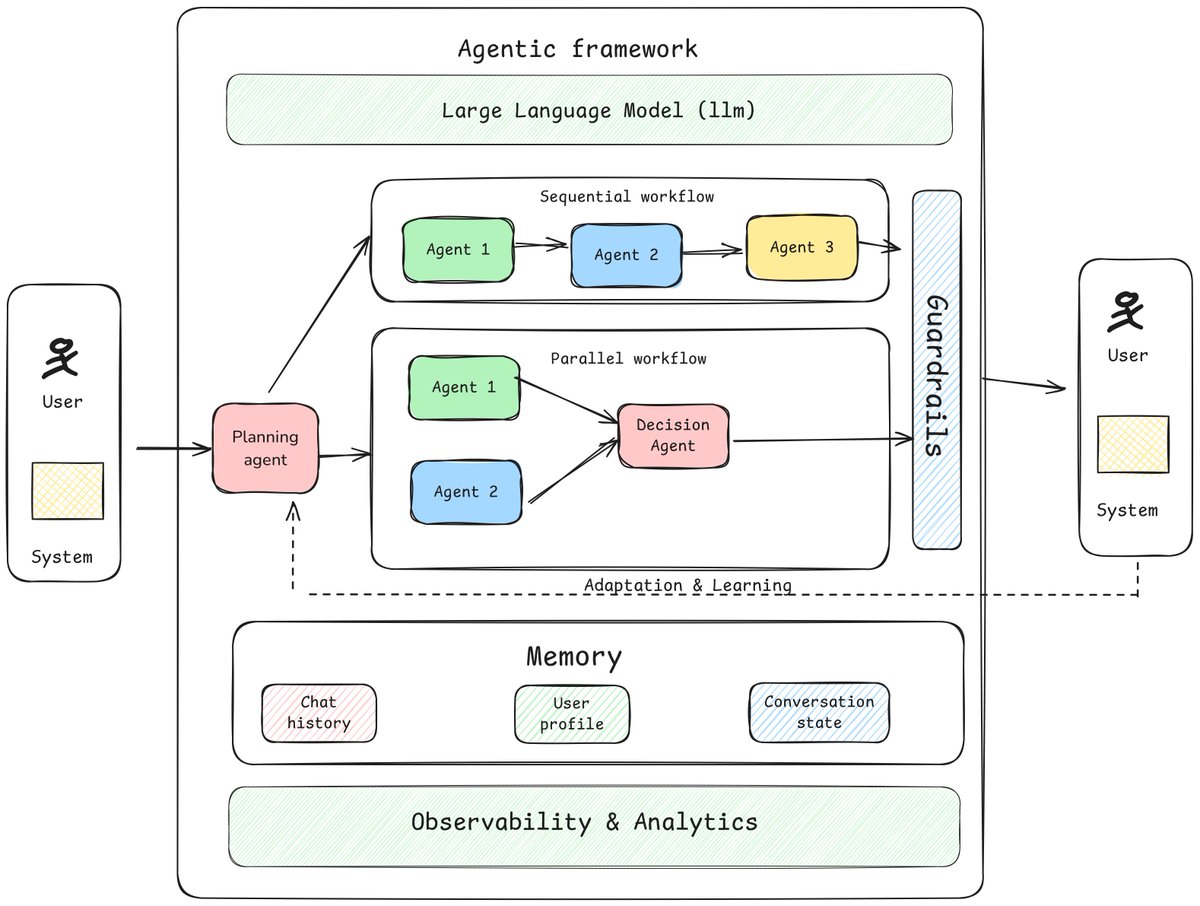
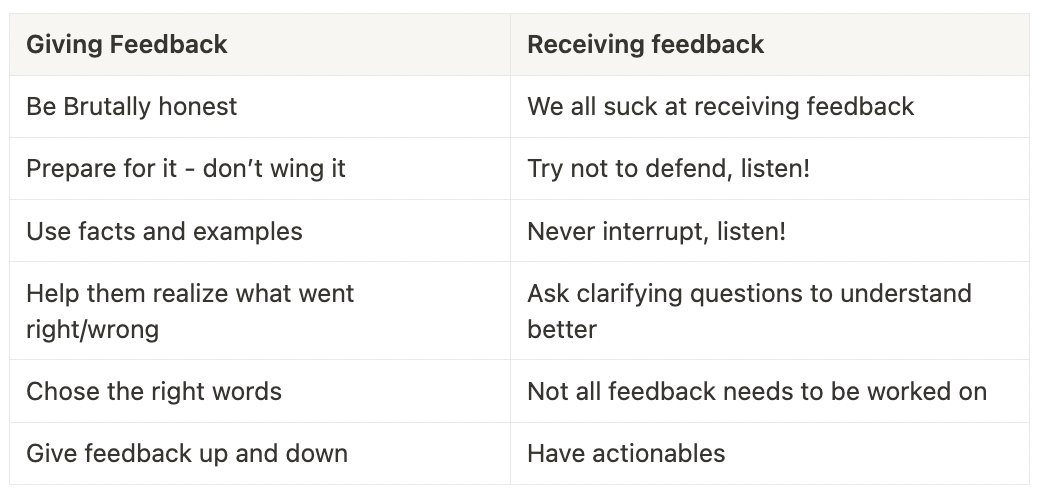
Measuring the quality of Voice AI agents is messy. You have to score it on what was said, how well it was said, how fast it responded, and whether it solved the task at hand. And all of this with no ground truth!
1
2
104
Swapan Rajdev retweeted

Mar 2
Signal Dialogues #01 is live.
We built Signal because there wasn’t a clear, consistent voice telling the story of AI in India — across founders, capital, research, and policy.
For our first episode, @aakrit sits down with @vkhosla and @mukundjha to go over the rise of Emergent — probably the fastest growing software company in history to hit $100M ARR.
Shot at the sidelines of the @OfficialINDIAAI summit at the iconic @iitdelhi.
Timestamps:
00:00 – Intro: Fastest Growing Software Company Ever?
07:28 – Mukund's Journey: Google → Dunzo → Emergent
22:23 – You're Limited by What You Think You Can Do
27:08 – The $3M Bet That Built the Internet
47:11 – $100B AI Company From India?
1
20
97
85,610
Swapan Rajdev retweeted

Mar 2
Ever since we started building Activate, I knew we would eventually launch a podcast.
But it couldn’t be just another VC show. While there is tremendous energy around AI in India today, there isn’t yet a clear, consistent platform bringing together founders, capital, research & policy in one conversation.
So today, we’re launching Signal Dialogues.
For our very first episode, I couldn’t have dreamt of a better setting: a legend, India's AI poster boy, an iconic venue, and at the country's most defining AI moment.
Privilege to have none other than @vkhosla together with @mukundjha, co-founder of @emergentlabs, one of the world's fastest ever software companies to hit $100M ARR, on the sidelines of the @OfficialINDIAai Impact Summit at @iitdelhi.
#DontStop 🚀
Mar 2

Signal Dialogues #01 is live.
We built Signal because there wasn’t a clear, consistent voice telling the story of AI in India — across founders, capital, research, and policy.
For our first episode, @aakrit sits down with @vkhosla and @mukundjha to go over the rise of Emergent — probably the fastest growing software company in history to hit $100M ARR.
Shot at the sidelines of the @OfficialINDIAAI summit at the iconic @iitdelhi.
Timestamps:
00:00 – Intro: Fastest Growing Software Company Ever?
07:28 – Mukund's Journey: Google → Dunzo → Emergent
22:23 – You're Limited by What You Think You Can Do
27:08 – The $3M Bet That Built the Internet
47:11 – $100B AI Company From India?
4
8
64
12,419
5 Dec 2025
3 Dec 2025

I moved back to India in 2013 with a simple mission: to build AI for the country.
Since then, I've been incredibly fortunate to build Haptik, invest in 100 startups, co-create TEAM for Mumbai and contribute to our sovereign AI strategy through the IndiaAI Mission. Today, all of it comes together in my next act.
Introducing Activate: India’s AI Venture Fund.
We believe AI in India will be built by technical crack teams. Activate is created for such founders, engaging with them well before company formation and investing $500k-$3M at inception.
With @177pc, the one & only person in the world I'd want to do this with.
It starts here. It starts now. It's time to Activate.
1
70
25 Sep 2025
>> git checkout -b dashboard_cleanup
>> claude
>> {explain all the clean-ups required}
>> Yes, allow all edits in this session
Power nap!
My current state, happy place :)
79
17 Jul 2025
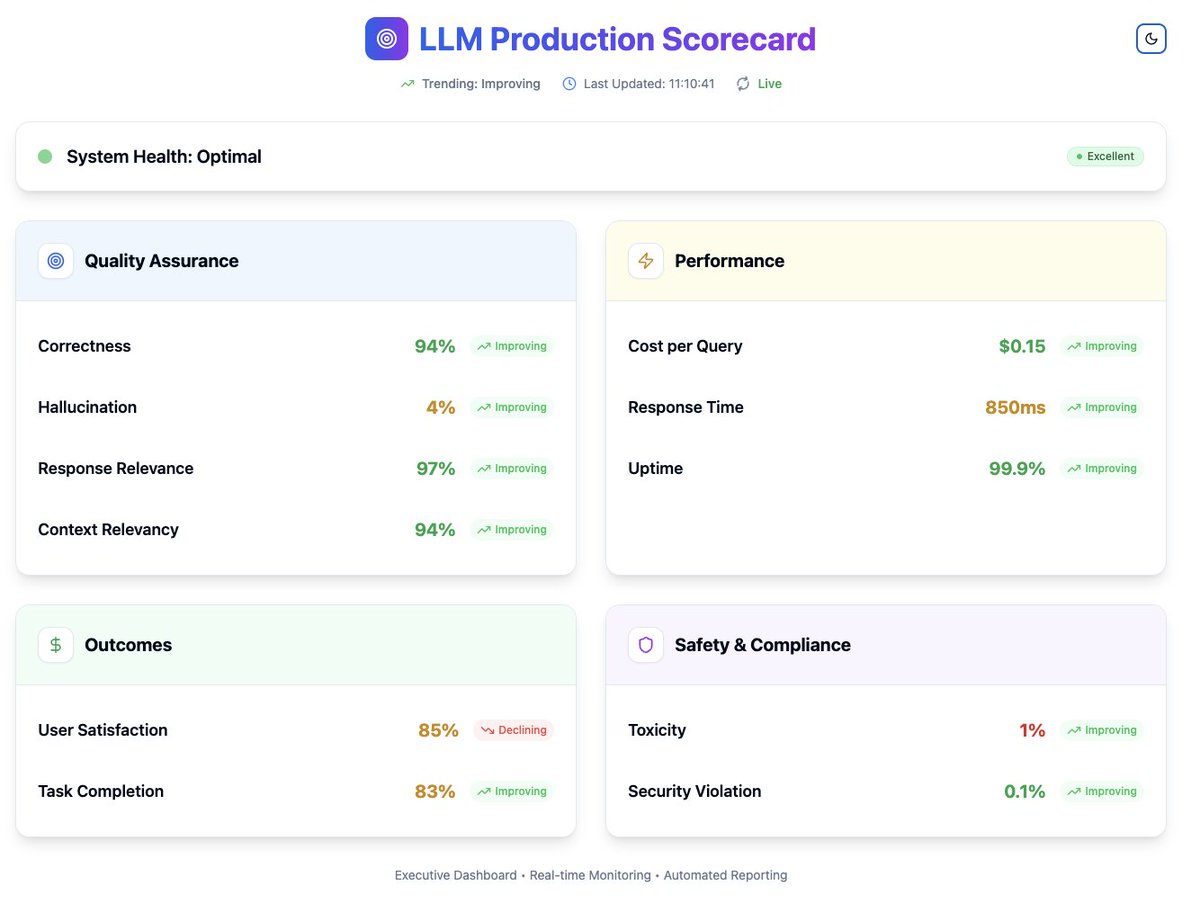
I've seen this pattern in every AI app I've worked on. Demos work great, but then real users expose the cracks. Change one prompt and something else breaks. Users and clients start losing faith in AI.
The answer to most of these problems?
- Strong, clear evaluation metrics that you track regularly.
- It gives you the confidence and peace of mind of knowing exactly how your app is performing in production.
I wrote a guide on the scorecard I use for all the apps I ship and how to implement it.
Link to the full implementation guide in the comments.
1
150
1 May 2025
I went down a bit of a rabbit hole recently trying to understand AI guardrails.
What started as “how do I stop bad outputs?” turned into a deep dive into architecture, safety frameworks, unintended behaviors, and a dozen real-world incidents where things almost went off the rails.
Most people treat guardrails like seatbelts: a safety add-on. But in agent systems that plan, reason, call tools, and store memory, guardrails have to be part of the architecture, not just wrappers around LLM outputs.
I pulled everything I was learning into a blog post and realized that before talking about how guardrails work, we need to understand what exactly we're trying to protect.
🧩 Here are the 6 key attributes that good guardrails should defend:
- Accuracy: prevent hallucinations & disinformation
- Privacy: avoid sensitive data leakage
- Security: block injections, unsafe code/tool access
- Safety: prevent harmful or dangerous behavior
- Compliance: align with legal/regulatory standards
- Fairness: reduce bias in reasoning and responses
Read the full post to explore how guardrails work and why thinking of them as runtime actions across your entire agent stack is a much more powerful model than just filtering input and output.
Link to the full post here: srajdev.com/p/multi-layered-…
1
1
120
1 May 2025
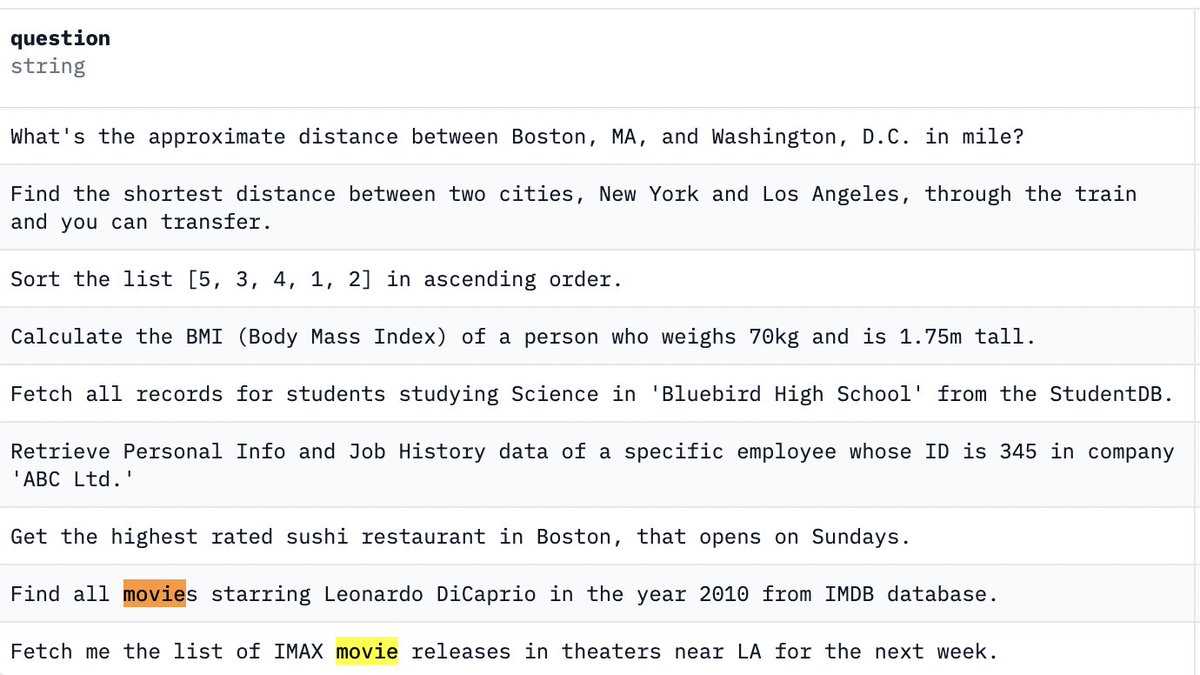
Simple stuff like this makes me productive and a bit excited because I feel like I just found a smarter way to work :)
Told ChatGPT to go through all the references in a research paper I am currently studying and turn them into a table with links.
No more googling each one manually.
Note: had to tell it to scrape 10-20 at a time, then ask it to merge them all.

1
129
16 Apr 2025
If you want your team actually to use AI and not just talk about it - here’s an interesting idea: 👇
Lenny Rachitsky just dropped the AI Bundle of the Year — $14,000 worth of top AI tools (Cursor, Replit, Notion AI, Perplexity Pro, and more) for just $200: lennysnewsletter.com/p/an-un…
Here's how to turn this into magic inside your org:
➡️ Run a 10–15 day challenge where employees share their most creative use of AI for personal growth or productivity
➡️ Reward the top 3–5 entries with this bundle (gifted to their email so they keep it)
➡️ Watch how fast AI adoption takes off
It’s recognition upskilling culture-building in one shot.
Best $200-$1000 you will spend this year.
1
3
279
27 Mar 2025
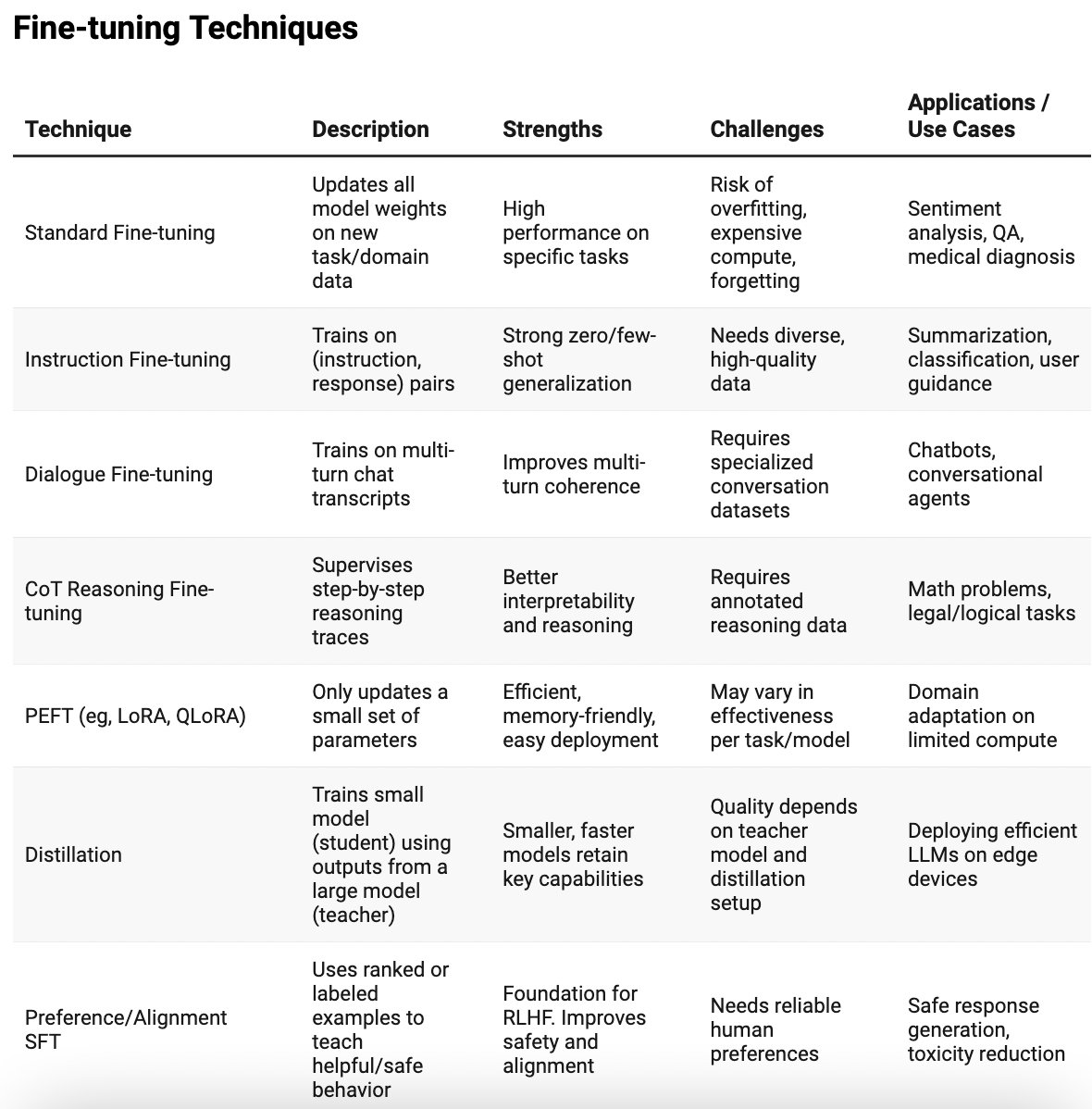
Pretraining gives language models their knowledge, and post-training gives them purpose!
But with so many techniques—fine-tuning, instruction tuning, RLHF, test-time reasoning—it’s easy to get lost in the maze.
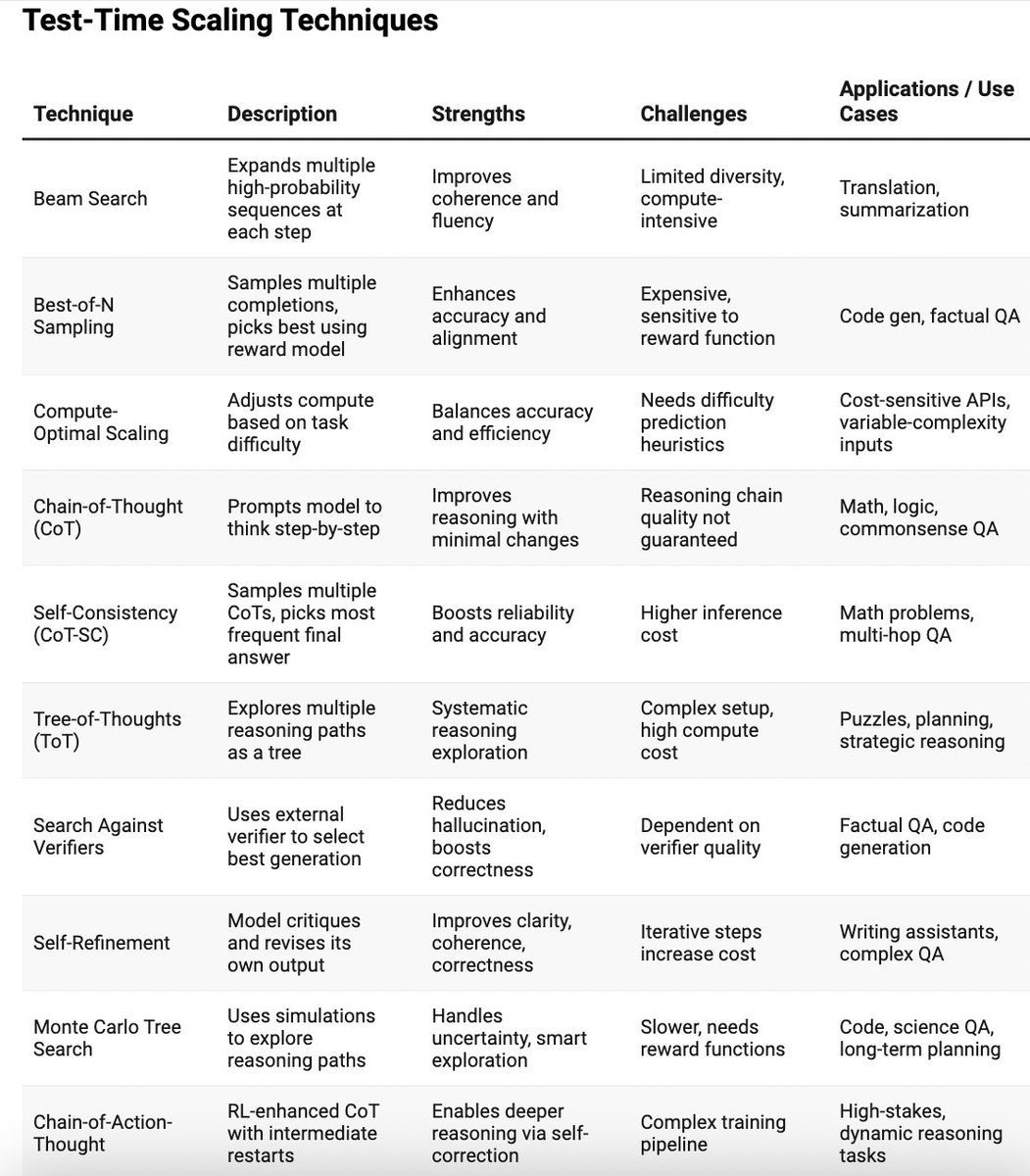
I recently came across a fantastic paper—LLM Post-Training: A Deep Dive into Reasoning LLMs—that mapped out this space beautifully. So I decided to break it all down into something easier to digest.
📘 In this post, I’ve:
- Categorized key post-training methods (Fine-Tuning, RL, Test-Time Scaling)
- Summarized strengths, challenges, and real-world use cases
- Shared clean, visual tables to help you pick the right technique for your application
This reference might save you a lot of time if you’re building AI products or working with LLMs in production.

1
1
216
21 Mar 2025
Reading a good book is like binge-watching a show, you find every excuse to procrastinate work. The only difference? You don’t feel as guilty because reading feels productive.
1
104
19 Mar 2025
🚀 In the AI era, being a 'wrapper company' isn't a limitation—it's an opportunity!
With foundational models now widely accessible, the true differentiators lie in:
- Speed: Rapid iteration and agile development to stay ahead.
- Quality: Delivering exceptional user experiences that resonate.
- Distribution: Crafting innovative go-to-market strategies and building strong communities.
Embracing the 'wrapper' approach means focusing on:
- AI-native workflows: Reimagining processes to fully leverage AI's potential.
- User-centric design: Creating interfaces that simplify complexity.
In this landscape, it's not just about the technology but how you apply it. The companies that thrive will be those that integrate AI thoughtfully, enhancing value and redefining industries.
You can read more in my latest post below.
1
1
85
7 Mar 2025
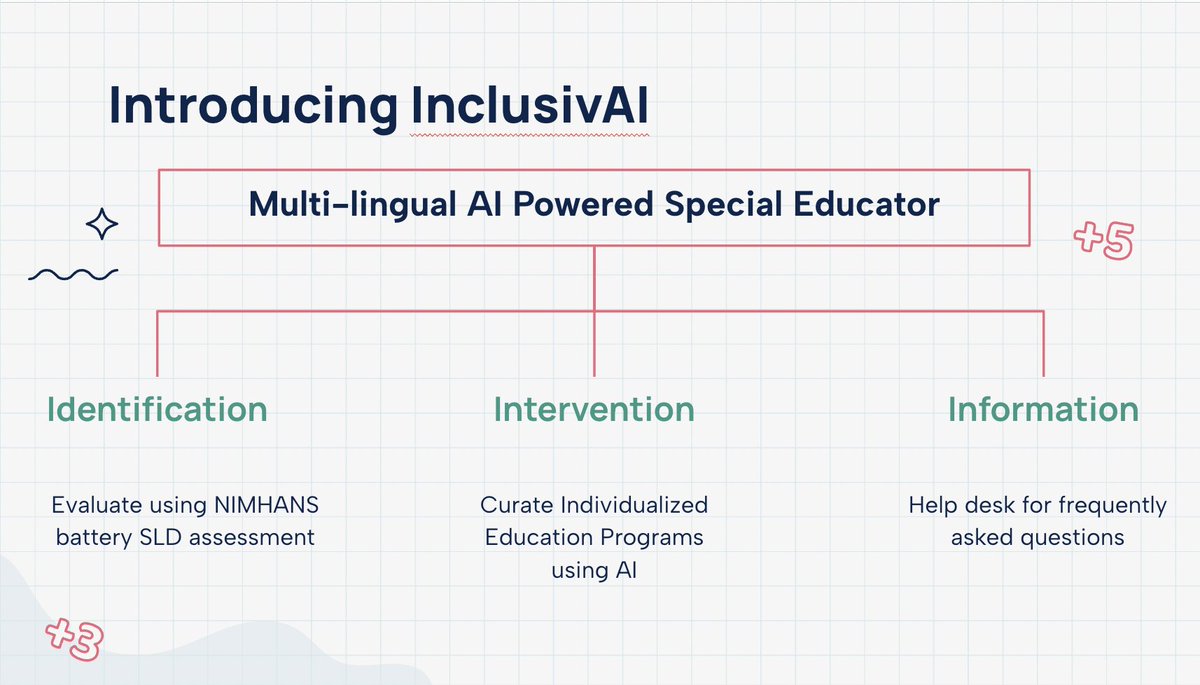
For 30 years, I’ve witnessed the power of a great special educator—because my mother is one. The right guidance doesn’t just help children learn; it transforms entire families, especially for differently abled children.
But in India, the reality is stark:
📌 30 million children are estimated to have Specific Learning Disabilities (SLD).
📌 Yet, only 8 million have been officially identified—leaving 22 million children and families unaware.
📌 Even for the identified cases, we have just 1.6 lakh special educators—meeting only 25-35% of the actual need.
This massive gap in special education is a challenge—but also an opportunity. Given where AI stands today, I truly believe we can bridge this gap and create a lasting impact.
That’s why I started building an AI-powered special educator—to bring personalized, accessible, and scalable support to children, parents, and educators.
🚀 Super excited to share that on the 1-year anniversary of IndiaAI Mission, we were selected as one of 30 companies (from 900 applicants) to receive a grant from the IndiaAI Application Innovation Challenge. This recognition strengthens our mission to revolutionize special education in India.
If this vision resonates with you, I’d love to connect. Whether you're an educator, technologist, policymaker, or just someone who cares deeply about making a difference—we need you. Let’s build the future of special education together.
#AIForGood #InclusiveEducation #SpecialEducation #IndiaAI #Accessibility
1
6
183
6 Mar 2025
I can't scroll without seeing MCP debates, why the sudden hype now, months after release?
1
136
Swapan Rajdev retweeted

26 Feb 2025
happy Nvidia earnings day

35
157
2,018
201,705
26 Feb 2025
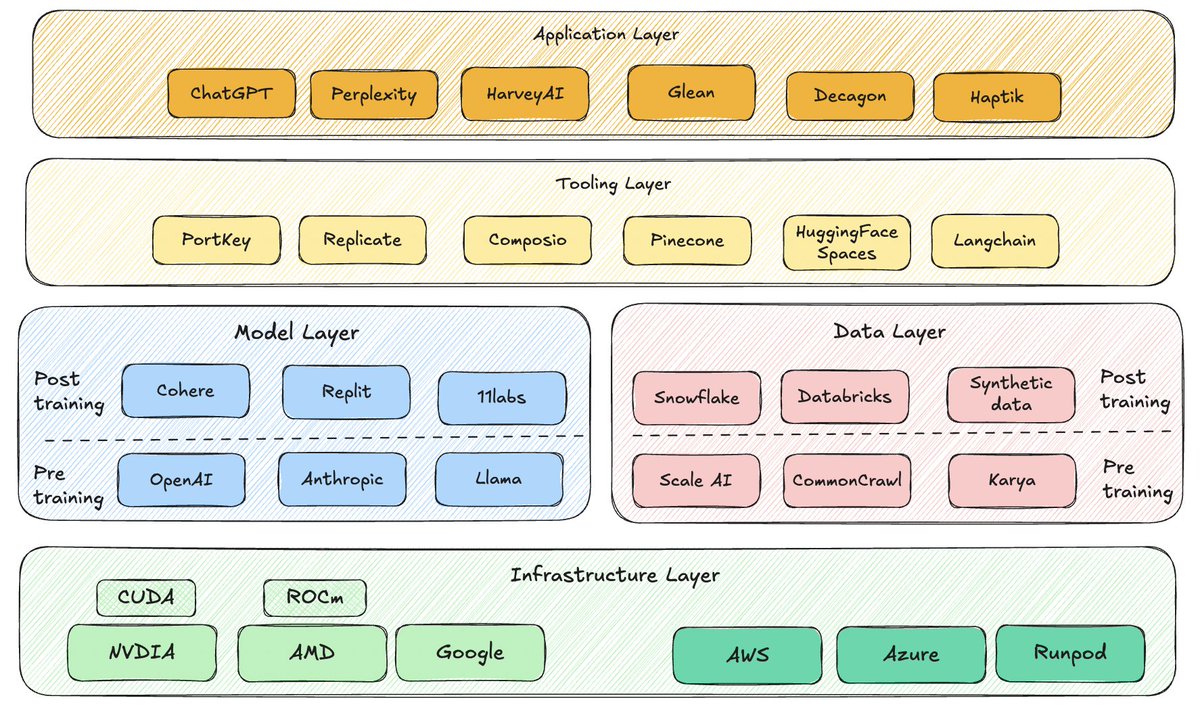
The AI Stack: A Framework for Every Builder
AI is evolving at lightning speed, but you might be playing the wrong game if you don’t understand the AI stack.
After years of working in AI, one thing is clear: many companies don’t truly know where they compete, what they own, or how they differentiate. Some think they’re building defensible AI businesses—but in reality, they’re just integrating someone else’s technology.
That’s why I wrote this breakdown. It’s not just a framework; it’s a practical lens to help founders, builders, and investors pinpoint where real value is created in AI.
If you're building in AI, this will help you:
✅ Understand the five key layers of the AI stack
✅ Move faster by knowing where to focus and where to partner
✅ Identify whether you're creating value or relying on others
This might seem obvious, but getting this right is the difference between leading and getting left behind.
1
2
135