
technology, gaming and Music
Joined December 2020
- Tweets 8,583
- Following 1,802
- Followers 356
- Likes 60,658
56 Photos and videos



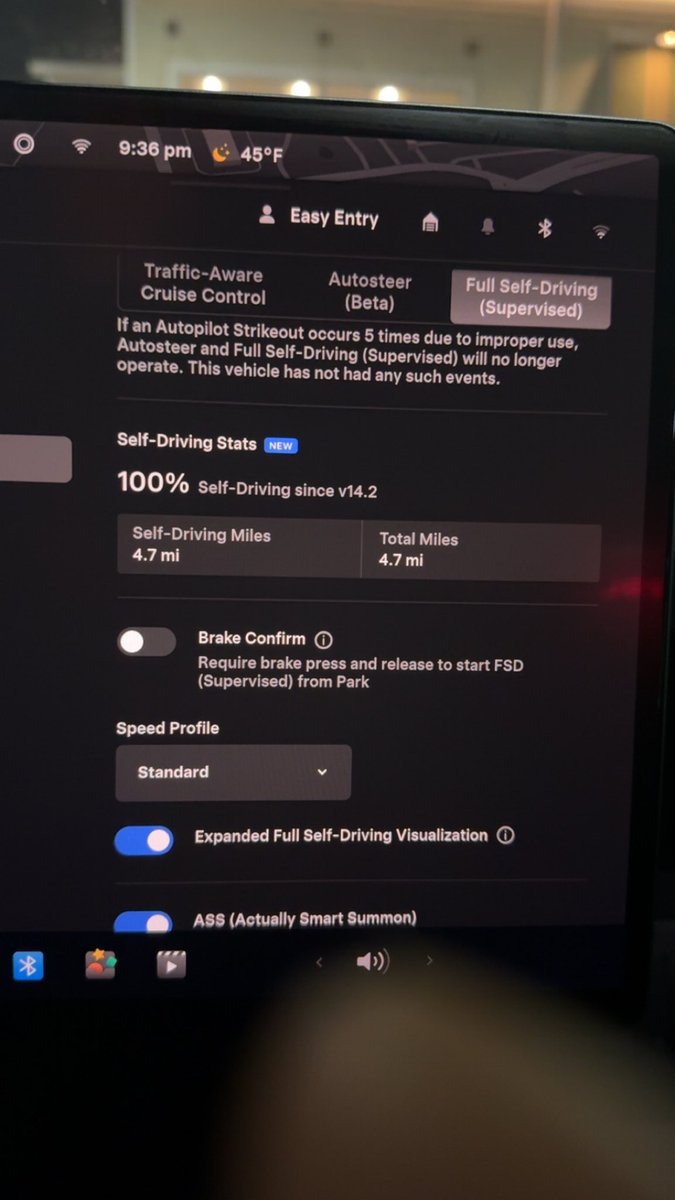


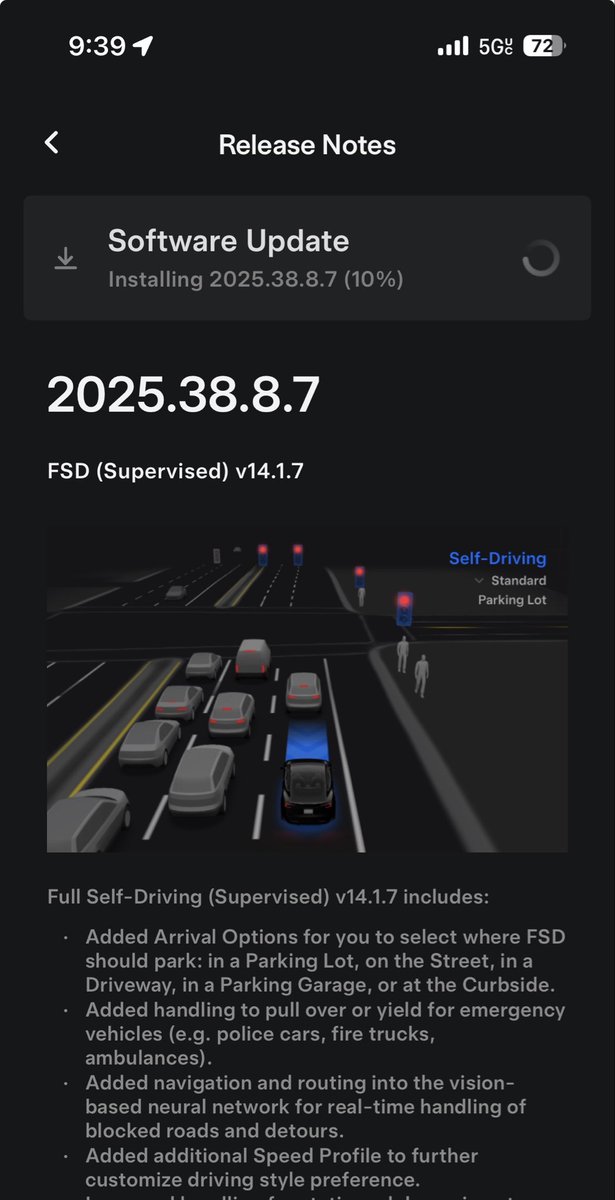







Do yourself a favor
Stop what you're doing.
This is important.
Even if you don't have a GPU.
Go download one of the latest local models and just keep it in storage.
There may come a time when you can no longer access intelligence freely
12-27B is enough.

Gemma 4 12B Coder is here and it's a game changer for local code generation. This GGUF model packs Google's latest gemma-4 architecture into a compact 12B size, perfect for running on consumer hardware. It's optimized for reasoning and thinking, making it ideal for developers who want fast, private coding assistance without the cloud.
67
92
1,809
235,405

GLM-5.2 is now fully available for GLM Coding Plan users.
ZCode 3.0 is deeply optimized for GLM-5.2, bringing stronger Agent task execution, better long-context coding, and the new Goal feature for managing larger development objectives from planning to completion.
Coding Plan subscribers get 150% usage quota inside ZCode. New users get 5 days free with 5M tokens per day.
Download: zcode.z.ai/

81
110
1,252
114,964

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
342
969
8,106
2,194,991

SK retweeted

Jun 1
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:qwen.ai/blog?id=qwen3.7-plus
Qwen Studio:chat.qwen.ai/?models=qwen3.7…
API:modelstudio.console.alibabac…
271
457
3,949
489,438
SK retweeted

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

562
1,154
10,966
4,948,308

SK retweeted

May 29
llama.cpp now has an official website: llama.app
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
96
483
2,980
164,121

May 29
Seems Qwen is testing a new model on their chat platform. Some type of A/B testing. Also, 3.7 max is telling me it’s multi-modal, even though it doesn’t take images attachment yet. Interesting 🤔
@Ali_TongyiLab @Alibaba_Qwen @TeksEdge @teortaxesTex
3
243
SK retweeted

May 28
Claude Opus 4.8 beats Opus 4.7, GPT-5.5, and Gemini 3.1 Pro !!
We ran a multimodal gaming comparison across these four closed source models.
Opus 4.8 took the longest to generate, but it came out ahead, capturing the most elements from the prompt and successfully hitting the rival cars.
GPT 5.5 is still good, but Gemini is no longer the best multimodal model now
24
55
744
115,961
SK retweeted

May 28
I had early access to Opus 4.8. Was impressed by it.
Here is Opus 4.8's one shot of "create a visually interesting shader that can run in twigl, make it like an infinite city of neo-gothic towers partially drowned in a stormy ocean with large waves" (this is all done with math)
11 Dec 2025

Had early access to GPT-5.2. Its an impressive model.
Here is GPT 5.2 Pro's version of "create a visually interesting shader that can run in twigl-dot-app make it like an infinite city of neo-gothic towers partially drowned in a stormy ocean with large waves," single shot.
60
96
2,312
435,554

SK retweeted

May 21
Qwen 3.7-max beats Opus 4.7 and GPT-5.5
We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head.
Qwen 3.7-Max: training cost $1.32, bot improvement 56%
Claude Opus 4.7: training cost $12.15, bot improvement 28%
GPT-5.5: training cost $2.85, bot improvement 7%
Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
186
471
4,561
857,997

SK retweeted

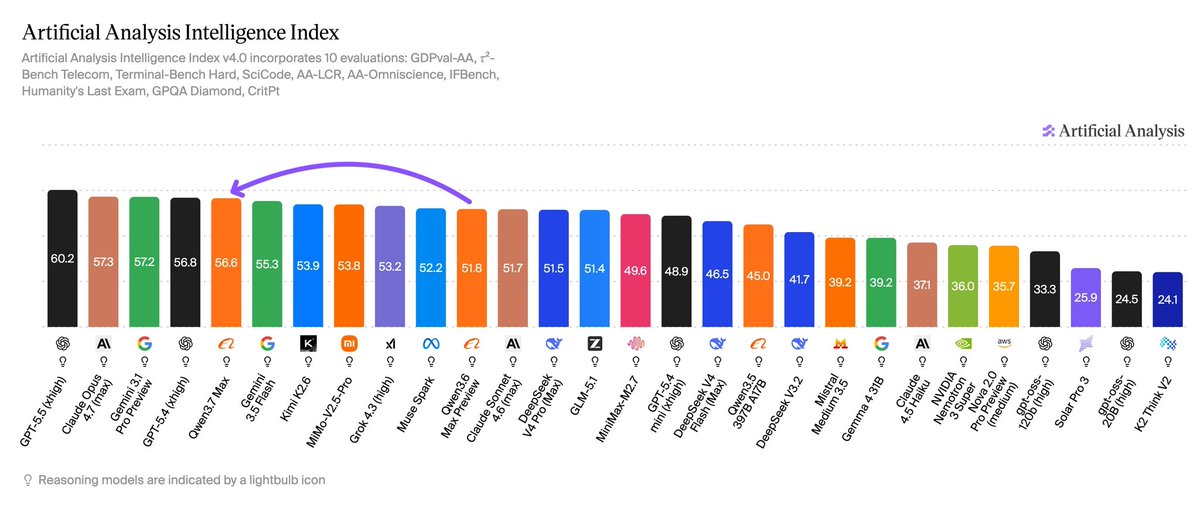
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier
Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026
Key takeaways for the reasoning variant:
➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt 9.7 p.p (3.7% to 13.4%), HLE 9.2 p.p (28.9% to 38.1%), TerminalBench Hard 6.9 p.p (43.9% to 50.8%) and GDPval-AA 42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview
➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the 4.8 point gain on the Intelligence Index
➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M)
Key model details:
➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview)
➤ Multimodality: Text input and output only
➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API)
➤ Licensing: Proprietary, closed weights
47
118
1,063
324,345
May 21
chat.qwen.ai/s/t_aeae73f5-f3…
Take a look at this beautiful animated SVG of a pelican riding on a Bicycle generated by @Alibaba_Qwen #Qwen3.7-max preview.
#LLM #ai
1
146
May 20
Alibaba #Qwen3.7-max is really good, really great improvements in just a month. @AlibabaGroup @Alibaba_Qwen
#llm #AI
1
1
236
