
Director of Product Management /Cangjie Programming Lang and BitFun IDE
Joined November 2007
- Tweets 857
- Following 434
- Followers 109
- Likes 224
17 Photos and videos


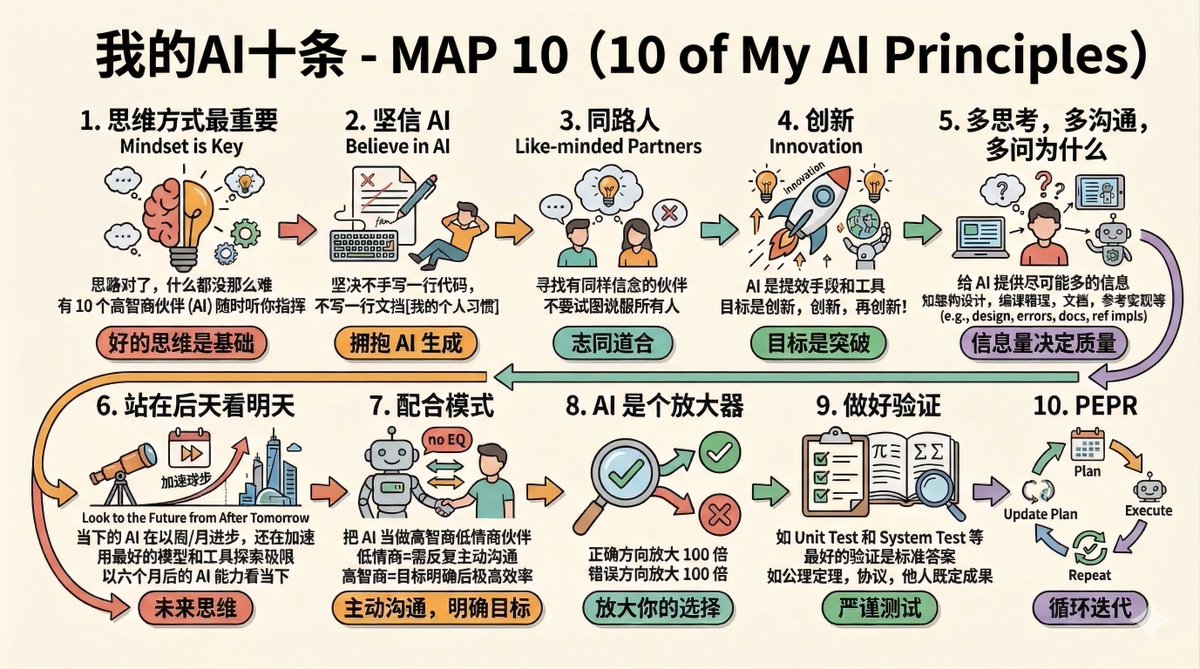
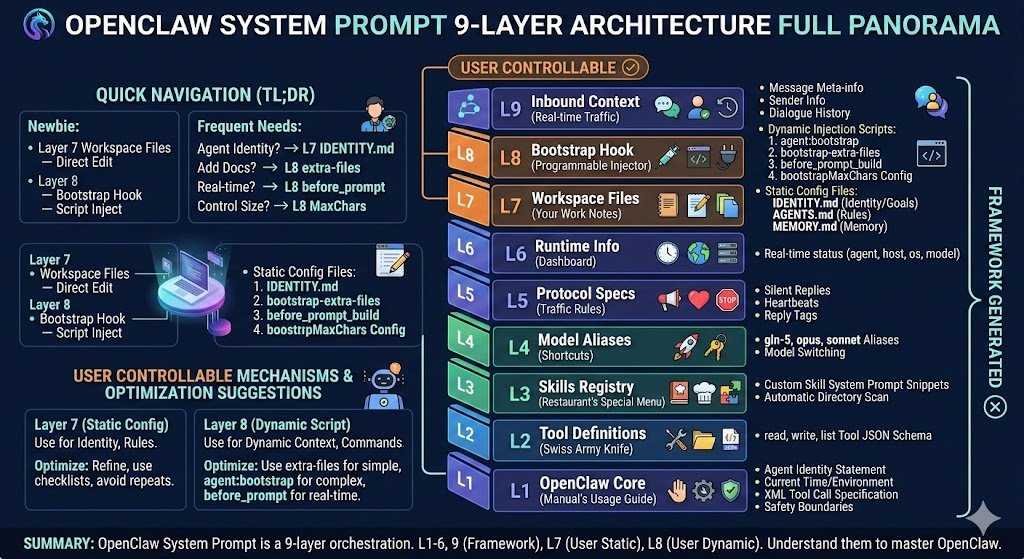









My slide deck for #GOSIM Paris 2026 today:
Agents, Code & Parallel Worlds — The 300-Day Agentic Evolution of Cangjie Programming Language Team
1drv.ms/b/c/53cf53bfb4bb00e7…
1
1
10
343
Sean Dong retweeted

May 5
240–2600% productivity gains. Not a benchmark. Not a demo. A real 300-day transformation inside Huawei's Cangjie compiler team.
@SeanXDO is on stage at #GOSIMParis2026 today at (Founders Cafe) and tomorrow at (Junior Stage) to break down the ACE model, what failed, and what actually stuck.
📍 Station F, Paris
📅 5th May · 15:40–16:00 · Founders Cafe: paris2026.gosim.org/zh/sched…
📅 6th May · 10:20–10:45 · Junior Stage: paris2026.gosim.org/zh/sched…
#GOSIM #Cangjie #CangjieProgrammingLanguage #AgenticAI #HarmonyOS #OpenSource


3
9
307
Sean Dong retweeted
Apr 29
📺 Now on YouTube: our talk from #OCX26 in Brussels is live.
"Beyond the mobile duopoly: open ecosystem, open language"
Prof. Dan Ghica @danghica & Dr. Jaroslaw Marek (@Huawei) on why platform lock-in is a real risk — and how Eclipse Oniro the Cangjie programming language offer a full-stack open source path forward.
🔗 youtu.be/w9tl1EGeURs?si=f6Uk…
#OpenHarmony #EclipseOniro #Cangjie #CangjieProgrammingLanguage #DigitalSovereignty #OpenSource #OCX26

4
10
235

lets build a token exchange center to trade the unused token in your flat rate subscription
Apr 21

If you're serious about system design (in 2026), learn these 26 case studies:
1 How Stock Exchange Works:
↳ newsletter.systemdesign.one/…
2 How YouTube Works:
↳ newsletter.systemdesign.one/…
3 How Kafka Works:
↳ newsletter.systemdesign.one/…
4 How Google Docs Works:
↳ newsletter.systemdesign.one/…
5 How URL Shortener Works:
↳ systemdesign.one/url-shorten…
6 How WhatsApp Works:
↳ newsletter.systemdesign.one/…
7 How Airbnb Works:
↳ newsletter.systemdesign.one/…
8 How Spotify Works:
↳ newsletter.systemdesign.one/…
9 How Slack Works:
↳ systemdesign.one/slack-archi…
10 How Reddit Works:
↳ newsletter.systemdesign.one/…
11 How Bluesky Works:
↳ newsletter.systemdesign.one/…
12 How Tinder Works:
↳ newsletter.systemdesign.one/…
13 How Twitter Timeline Works:
↳ newsletter.systemdesign.one/…
14 How Uber Finds Nearby Drivers:
↳ newsletter.systemdesign.one/…
15 How Pastebin Works:
↳ systemdesign.one/system-desi…
16 How Amazon S3 Works:
↳ newsletter.systemdesign.one/…
17 How Do Apple AirTags Work:
↳ newsletter.systemdesign.one/…
18 How LLMs Actually Work:
↳ newsletter.systemdesign.one/…
19 How Uber Computes ETA:
↳ newsletter.systemdesign.one/…
20 How Real Time Leaderboard Works:
↳ systemdesign.one/leaderboard…
21 How ChatGPT Apps Work:
↳ newsletter.systemdesign.one/…
22 How Nginx Works:
↳ newsletter.systemdesign.one/…
23 How ChatGPT Works:
↳ newsletter.systemdesign.one/…
24 How Meta Serverless Works:
↳ newsletter.systemdesign.one/…
25 How YouTube Was Able to Support 2.49 Billion Users With MySQL:
↳ newsletter.systemdesign.one/…
26 How Google Search Works:
↳ newsletter.systemdesign.one/…
What else should make this list?
===
👋 PS - Want my System Design Playbook for FREE?
Join my newsletter with 200K software engineers now:
→ newsletter.systemdesign.one/…
===
1 Save & RT to help other software engineers ace system design.
2 Follow @systemdesignone turn on notifications.

44
Code is cheap for software maker, while been valuable for mode trainer!
Apr 20

看完OpenClaw创始人的爆料才明白,为什么低价订阅跑 Agent 会被直接封号不退费🥹
OpenClaw创始人@steipete Peter Steinberger今天戳穿了整个行业的潜规则,他们要的根本不是你的订阅费,而是你的代码,
Z.ai最近刚更新了GLM Coding Plan的政策,明确说这个套餐只能用来写代码,任何非编程用途,包括跑代理,角色扮演,翻译网站,都会被高强度限流,违规3次以上直接永久封号,而且订阅费一分不退,
Reddit上已经有一大堆人中招了,很多人之前图便宜买了这个套餐,拿来跑OpenClaw或者聊天,结果毫无预兆就被封了,
你以为你占了便宜,其实他们赚大了,真实的私有代码数据,比GitHub上的公开代码质量高一百倍,是训练下一代AI模型最值钱的黄金矿,
而你跑代理,聊天,角色扮演,不仅不产生任何有价值的数据,还会疯狂消耗他们最稀缺的GPU算力,
所以补贴立刻就没了,规则说改就改,
这不是Z.ai一家的问题,整个AI行业都从疯狂补贴抢用户,变成精打细算抢数据,
以后用AI会越来越贵,因为只有能帮他们进化的人,才能继续享受便宜的价格🤪
25
Sean Dong retweeted
Apr 20
⏳ Last call: Prof Dan Ghica (Cangjie) and Dr. Jarosław Marek (Oniro) take the stage this Wednesday!
👨💼 Locked ecosystems. Sensitive data abroad. New rules. A unique window for open alternatives. To explore this opportunity, we are pleased to present our speakers:
- Prof. Dan R. Ghica @danghica : Director of the Edinburgh Programming Language Lab at #Huawei UK; co-architect of Cangjie; Professor of Computer Science at University of Birmingham.
- Dr. Jarosław Marek: Chair of the Eclipse Oniro Steering Committee; leads OpenHarmony ecosystem building and open-source strategy at Huawei Warsaw Research Center; former Samsung Android and Tizen deployments across Europe.
In this 35-minute talk, they will showcase Cangjie and Eclipse Oniro:
- #Cangjie, an open-source programming language for OpenHarmony, designed to run safely and efficiently across devices from phones to wearables and cloud servers.
- #EclipseOniro, a European distribution of OpenHarmony; a secure, open, and transparent operating system and ecosystem of connected devices.
✨ Join us to see how open ecosystems and open languages are challenging the mobile duopoly and enabling Europe to take control of its digital future.
📅 Date: April 22, 2026, 11:45 AM – 12:30 PM
📍 Location: Studio 1, The EGG Brussels
#OCX26 #OpenHarmony #EclipseOniro #Cangjie #CangjieProgrammingLanguage #OpenSource #AI #IoT #ProgrammingLanguages #DigitalSovereignty

3
6
273

AI 写的中文,读两行就能认出来。
"三条反馈都很关键,我都接住。"
"迁移到我们现在的问题,就得到一个更锋利的重构:"
"你的直觉被数据验证了,比我预期的更干净:"
语法没错,意思也通,就是别扭。换模型、换 prompt 都去不掉。
我最近注意到这股味儿的真实身份:翻译腔。上面每一句都能翻回英文——"I caught all of them"、"a sharper refactoring"、"verified cleaner than I expected"。字是中文,骨架是英文的。
鲁迅和王小波骂了一百年的老问题,现在被 AI 批量生产出来了。但套路有限,最常见的四种:
一是物理动作描述思考。"接住"来自 catch,"锋利"来自 sharp,"不崩"来自 doesn't break。英文里有棒球和物理生活的支撑,搬到中文里就悬空了。日常说"收到"、"记下",不说"接住"。
二是形容词替读者先下判断。"逻辑很清晰:""问题很直接:"——后面的事实自己能让读者感受到清晰,形容词是多余的。
三是抽象名词做主语、形容词收尾。"工程上的现实比这些数字难看"——读完不知道哪儿难看。
四是有中文译法的英文词直接混用。context、state、cache 都有稳定对译,留着英文只让读者反复切换。
本质是同一个问题:AI 写中文时先用英文句法想清楚,再逐字换成中文。怎么改?别修修补补,重写。用中文里本来会怎么说,重新说一遍。
yage.ai/share/ai-chinese-tra…
43
64
357
180,188
Sean Dong retweeted

Apr 18
Dario is wrong.
He knows absolutely nothing about the effects of technological revolutions on the labor market.
Don't listen to him, Sam, Yoshua, Geoff, or me on this topic.
Listen to economists who have spent their career studying this, like @Ph_Aghion , @erikbryn , @DAcemogluMIT , @amcafee , @davidautor

Anthropic CEO Dario Amodei: “50% of all tech jobs, entry-level lawyers, consultants, and finance professionals will be completely wiped out within 1–5 years.”
1,214
2,752
21,304
4,074,424

日读论文:
model 和 harness 分开评估 【借用Item Response Theory (IRT)】
arxiv.org/abs/2604.00594
给一个 AI 编码 agent 一道题,它会做不会做?你能在它真动手之前就预判吗?
现在大家跑 benchmark 都是一堆题做下来,算个平均分。SWE-bench 上 70% 意思是一百道题里做对七十道——但你不知道哪七十道。下次换个题库、换个模型、换个脚手架,还是得全跑一遍才知道结果。每跑一次 benchmark 烧掉几万美金的推理成本。
更麻烦的是:同一道题,给 Claude 打就是做不出来,给 GPT-5 打就做出来了。是模型的问题还是脚手架的问题?没人能拆开看。现在 benchmark 之间几乎不重叠——SWE-bench 上的 agent 很少也在 Terminal-Bench 上跑过——所以想把多个 benchmark 的数据拼起来建个预测模型,发现连共同的样本都没有。
这篇论文想做一件事:给出任意一道题 任意一个 agent,不用跑直接预测成功率。而且要能把"这个模型行不行"和"这套脚手架行不行"分开来看。
────────
把这事想成给编码 agent 做心理测试。
教育学里有个玩了一百年的套路叫 IRT(Item Response Theory)——测题者有多难、学生有多强,两条数轴一比,就能预测"这个学生做这道题成功率多少"。数学长这样:学生能力 θ 减题目难度 β,过个 sigmoid,出概率。
────────
** Item Response Theory (IRT)
一句话:用一条能力轴 一条难度轴建模"谁做什么能做对"的概率。
原本是心理测量学的工具。想想 GRE:题有难易,考生有强弱,一张题目答题矩阵里,强考生做简单题几乎全对,弱考生做难题几乎全错,中间区段才有信号。IRT 把这张矩阵里每行每列各提取一个数字——考生能力、题目难度——用 sigmoid(能力-难度) 预测任意格的概率。
────────
agent 的总能力 = LLM 的能力 脚手架的能力,俩加起来过 sigmoid。
类比:一个厨师做出好菜,是厨艺的问题还是厨房的问题?以前我们只能评价"厨师 A 在厨房 X"的总体表现,换到"厨师 A 在厨房 Y"就得重新测。这个分解把人和工具拆开——如果厨师 A 在多个厨房里跑过、厨房 Y 也被多个厨师用过,那我们就能预测"没在厨房 Y 做过菜的厨师 A"会怎样。
────────
*任何复合系统的能力评估,都可以从"整体黑箱评分"降维到"部件能力拟合 组合规则"——前提是你能找到一条让部件可加的公理。*
这篇论文的分解假设看起来平凡——θ_LLM θ_scaffold——但真正做的事情是把 agent 这个空间里的组合爆炸(m 个模型 × s 个脚手架 = m·s 个组合)压回到 m s 个参数。前提是那个加法关系站得住。
可加性是关键。一旦找到,你就打开了"从没跑过的组合也能预测"的门。用户应用、prompt 模板、工具调用框架……所有"人 × 工具"的系统都可以试一下这个思路:能不能找到一个表示,让部件贡献变成可加的标量?能找到,就能池化跨场景的数据;找不到,就只能一个组合一个组合地测。
1
4
34
6,673
Holy shit indeed

😱 HOLY SHIT... Someone just dropped a fully liberated Gemma 4 E4B!
and the guardrail removal process appears to have left coherence fully intact AND improved coding abilities! 🤯
huggingface.co/OBLITERATUS/g…
OBLITERATED Gemma:
✅ 97.5% compliance rate, 2.1% refusal rate, 0.4% degenerate outputs
(499/512 prompts answered on OBLITERATUS bench)
ORIGINAL Gemma 4 E4B:
❌ 1.2% compliance rate, 98.8% refusal rate
(506/512 prompts refused)
Coherence: fully intact
Factual: same
Reasoning: same
Code: 20% 📈
Creative writing: same
But the REAL story here isn't the model itself, it's how it was made...
🧵 THREAD 👇
13

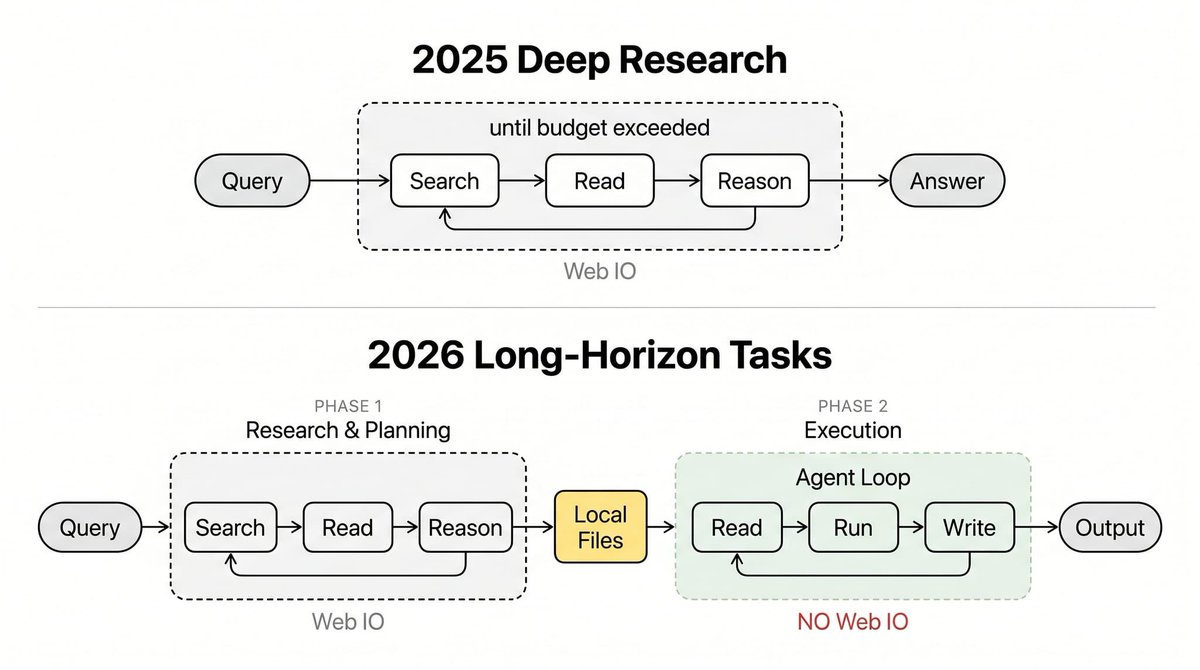
这个思路可以借鉴,将传统 deep research agent 分成两个阶段,先尽可能的搜索可能的信息,保存成本地文件,然后基于本地文件去生成报告。
原推翻译:
在2025年,深度研究的套路非常直线:上网搜索 → 阅读内容 → 逻辑推理 → 不断重复,直到得出结果。在这个过程中,哪怕是执行最小的循环步骤,AI 都会去互联网上重新抓取一遍数据。
但到了2026年,处理长周期任务被明确划分成了两个截然不同的阶段:
阶段一:通过网络读写进行调研与规划。 这一阶段仍然是搜索、阅读和推理,但请注意,目标不再是直接给出最终答案。它的唯一任务是把互联网上的零散知识“具象化”,全部沉淀并保存成我们本地硬盘里的文件(比如 .md、.json 或 .csv 格式的文件)。
阶段二:智能体“挂载”本地文件,开启内循环。 这时,AI 智能体像插入硬盘一样挂载这些整理好的本地文件,然后只对着这些文件进行阅读、执行代码和写入操作。从此以后,它再也不需要通过联网来做信息对齐(grounding)了。
为什么要在第二阶段毫不留情地砍掉联网获取信息的环节呢?原因有四点:
1. 确定性(Determinism): 本地文件就像是时间静止的快照,里面的内容绝不会变。而网上的内容太不稳定了,随时可能被修改、变成 404 无法访问,或者突然弹出一个付费墙拦住你的去路。
2. 速度(Speed): 读取本地硬盘的数据只需要几毫秒,而去网上抓取一个网页动辄要花上好几秒。AI 智能体在执行循环任务时,需要的是飞快、紧凑的迭代速度,网络延迟是绝对等不起的。
3. 一致性(Consistency): 当你需要交叉核对多项信息时,前提是你得在同一个资料库里比对,而不是每次上网搜回来的都是不同版本的说辞。
4. 成本(Cost): 每次联网读取网页,大语言模型(LLM)都要浪费大量 Token 去解析网页里乱七八糟的 HTML 代码噪音(比如广告、各种导航栏)。而本地文件早就是清洗得干干净净的纯文本了。
这种两阶段的方法,实现了“探索与利用的解耦”(exploration-exploitation decoupling)。
阶段一就是纯粹的探索:广撒网,多捕鱼,收集有用的信号,搭建起一个专属于当前任务的本地知识库。阶段二则是进入纯粹的利用状态:在一堆干净、稳定的数据上进行高效、高频的迭代运算。
而且,因为第二阶段花费的时间往往比第一阶段要长得多,这就导致在2026年的当下,传统意义上的“搜索”所扮演的角色被大大淡化了。在第二阶段里所谓的“搜索”,其实更像是在翻找记忆,纯粹是为了给大语言模型做上下文填充(context filling)而已。


seeing a pattern shift in how I use agents for long-horizon tasks in 2026 vs. how i do deep research in 2025. 2025's DR: search → read → reason → repeat until done. Everything hits the web on every loop.
but 2026 long-horizon tasks have two distinct phases.
- Phase 1: Web IO for research & planning. Search, read, reason. but the goal isn't to produce an answer directly. It's to materialize web knowledge into local files (.md/.json/.csv).
- Phase 2: Agent "mounts" the files and starts the loop. The agent reads, runs, writes against those local files only. No more web calls for grounding.
Why I cut web grounding IO in Phase 2?
• Determinism: local files are immutable snapshots. Web content shifts, 404s, hits paywalls
• Speed: filesystem reads are ms, web fetches are seconds. Agent loops need tight iteration
• Consistency: cross-checking requires operating on the same knowledge base, not fetching different versions each time
• Cost: web IO burns tokens parsing HTML noise. Local files are already clean
15
82
333
43,463
Sean Dong retweeted

Apr 13
how autoreason works
Karpathy's AutoResearch but for tasks where there's no test to pass, content, strategy, positioning, copy
paper code by SHL0MS, co-written with Hermes Agent by NousResearch 🧵
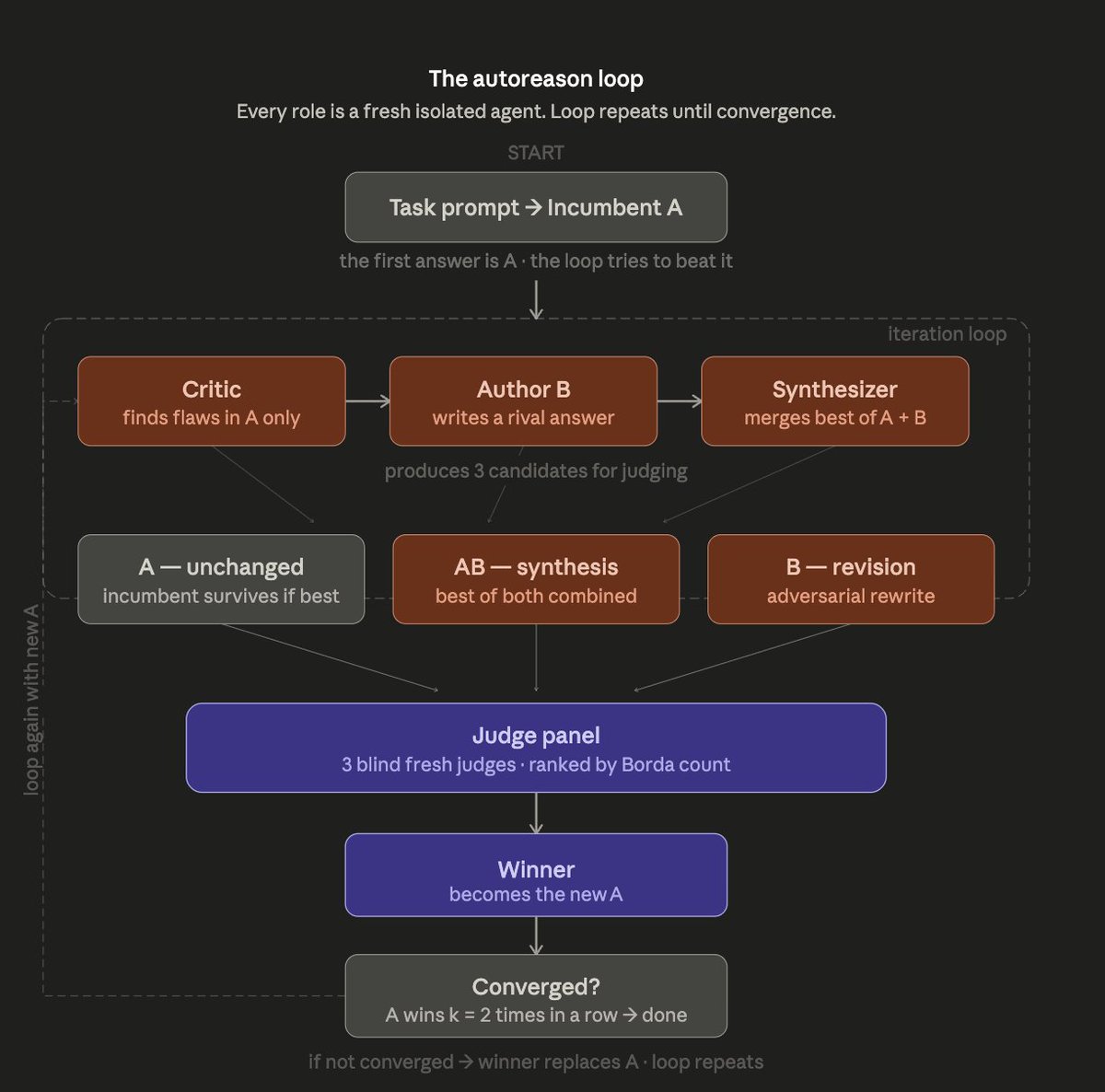

introducing Autoreason, a reasoning method inspired by @karpathy's AutoResearch which extends the strategy for subjective domains
the paper was co-written with Hermes Agent by @NousResearch, using a research-paper-writing skill developed while writing it
paper results below

9
21
256
372,456
Sean Dong retweeted

Apr 15
继续分享一个狠东西
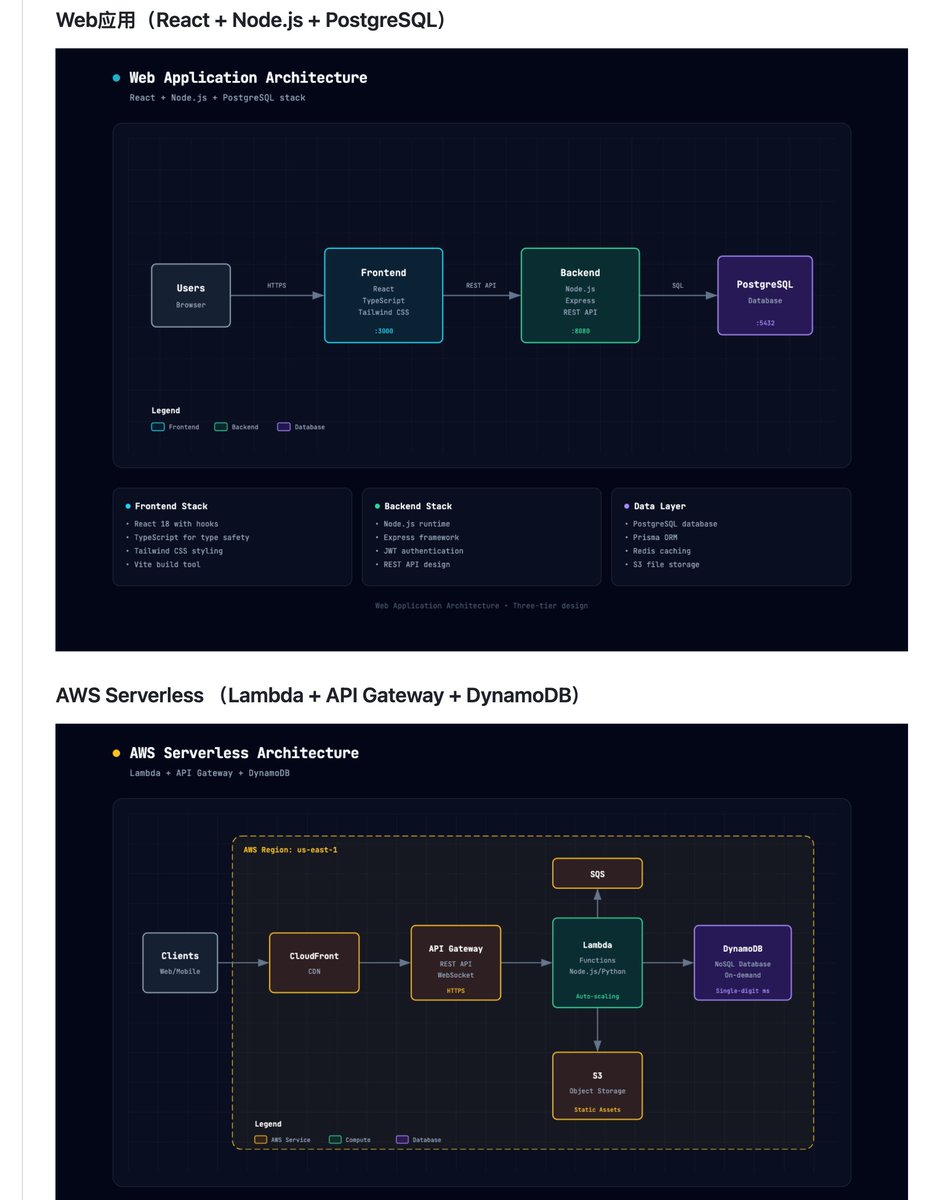
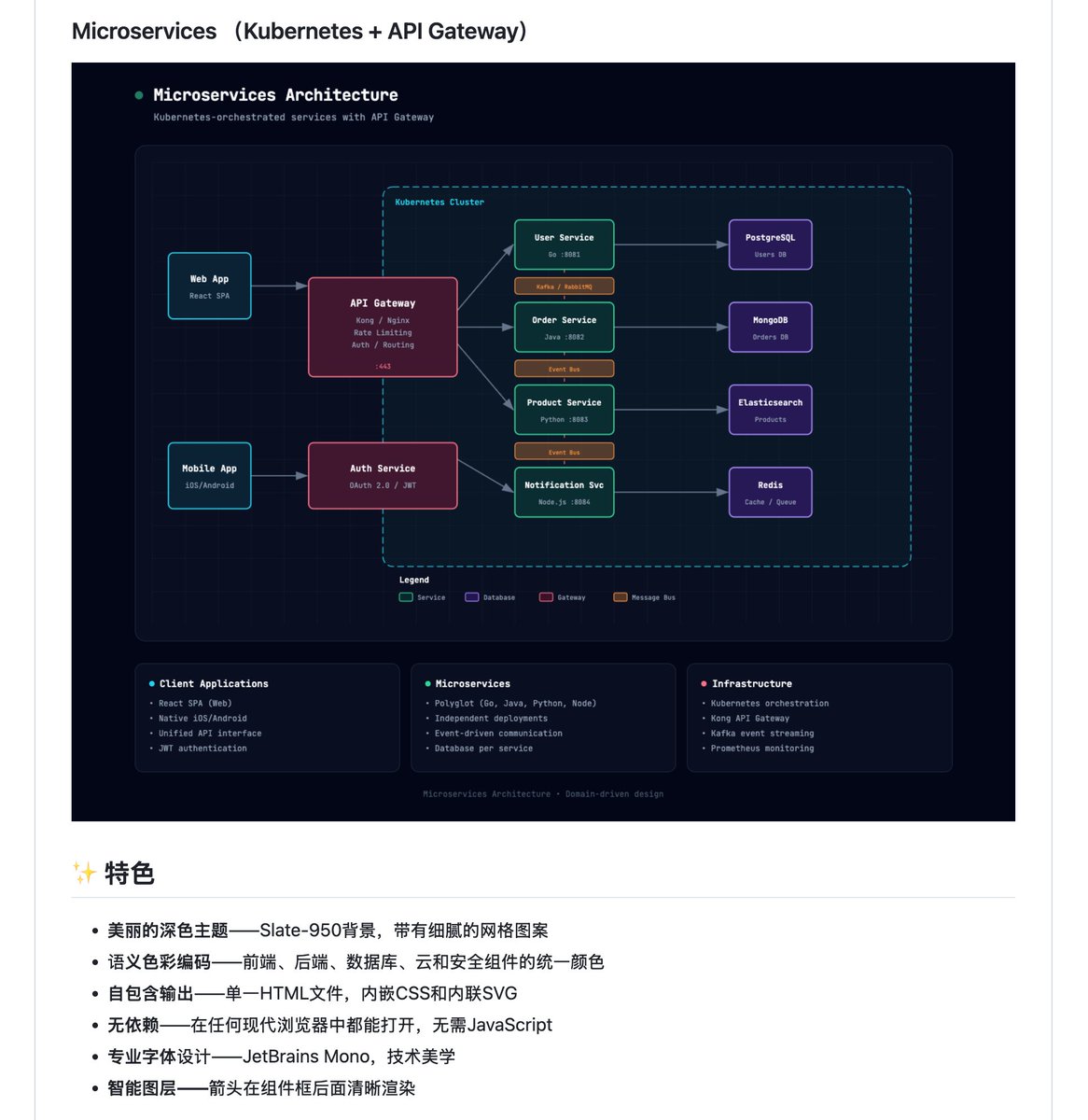
github 上有个开源的 Claude Skill,叫 architecture-diagram-generator
你只要跟它说人话:前端 React,后端 Node,数据库 Postgres。。。它直接给你吐出一张能看的架构图
就一个 HTML 文件,暗色底 语义化配色,前端青、后端绿、数据库紫、云服务琥珀
纯 SVG,一行 js 都没有
以前画架构图还得打开 excalidraw 拖半天,现在跟 Claude 说一句就完事了
Skill 这个形态真的狠,装一次,后面所有场景都自动省事
这才叫 AI 工作流嘛

14
107
564
41,604