Cyber Network Engineer | Codex enthusiast | Local AI | RTX Pro 6000 enjoyer
Joined June 2020
- Tweets 4,380
- Following 733
- Followers 697
- Likes 123,002
1,036 Photos and videos











I've uploaded Q4, Q8 and BF16 MTP draft models in their own repo
It should work natively with yesterday's llama.cpp merge
huggingface.co/notSnix/Step-…
3
1
44
4,424
Espen JD retweeted

Dostlar çok güzel bir haberim var. Yakında sağolsun @ASUSTR 'nin desteği ile Asus'un ExpertCenter Pro ET900N G3 Desktop AI Supercomputers'ını birkaç günlüğüne uzaktan bağlanıp test edeceğim.
Makine'de Nvidia'nın GB300 Grace Blackwell Ultra yer alıyor. 748GB Coherent Memory yer alıyor. Ama en efsanesi GB300'ün sahip olduğu 252GB HBM3e (7.1 TB/s) VRAM aslında 🔥 Özellikle @MiniMax_AI M3, @Zai_org GLM 5.1, @Kimi_Moonshot K2.7-Code, @Alibaba_Qwen 3.5-397B, @deepseek_ai v4 Flash gibi modelleri NVFP4 ile oldukça zorlayacağım; 50-100 paralell istek performansı, Agentic paralel 5-10 araçla kullanım performansı gibi.

ALT Image Source: Mathieu MOREL
24
5
166
8,786
Espen JD retweeted

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

542
1,393
12,044
3,989,249

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
231
656
6,477
778,775
Damn so many model releases
GLM-5.2 is here

Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
docs.z.ai/devpack/latest-mod…
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
2
49
2,703
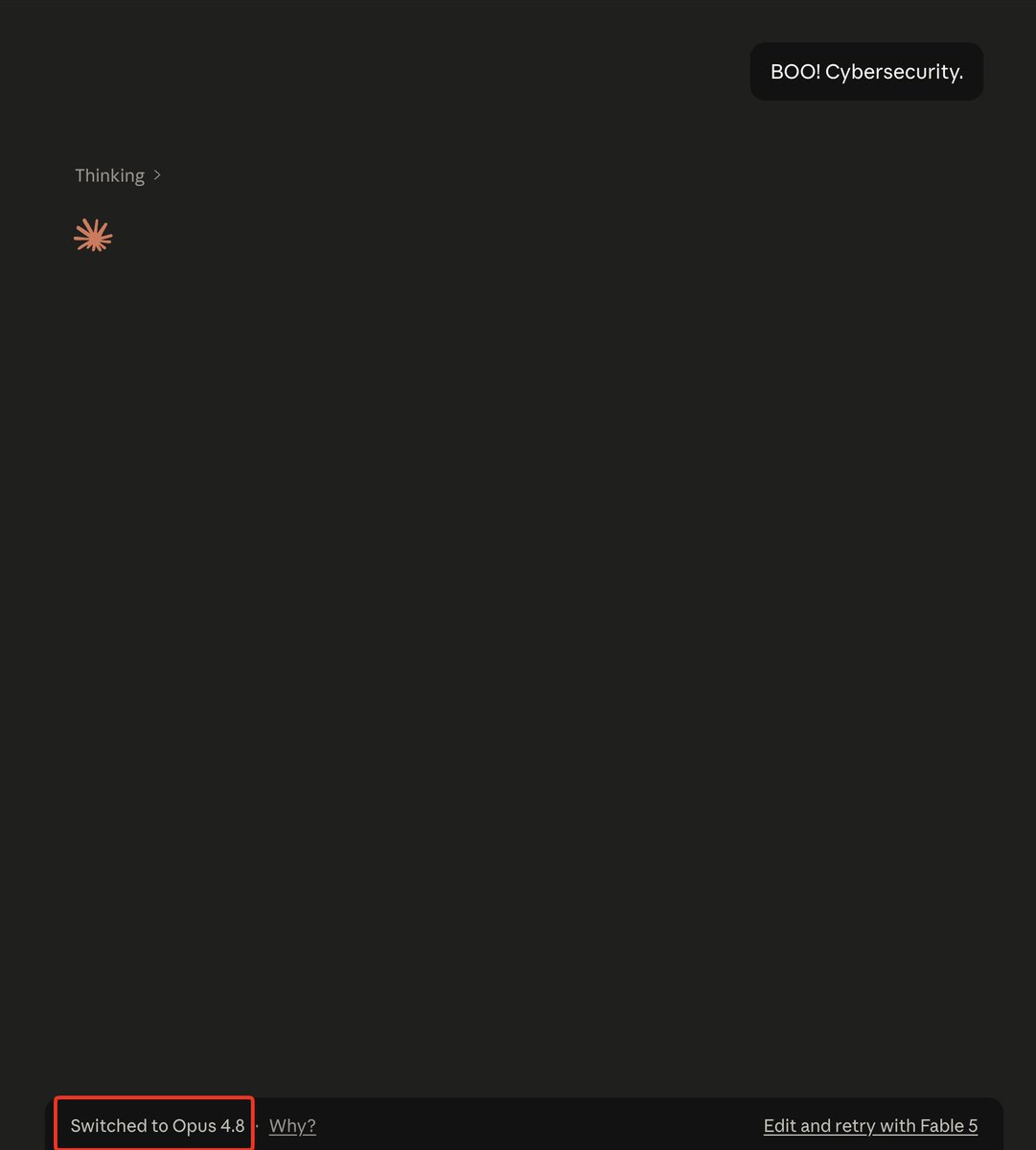
What
Jun 13

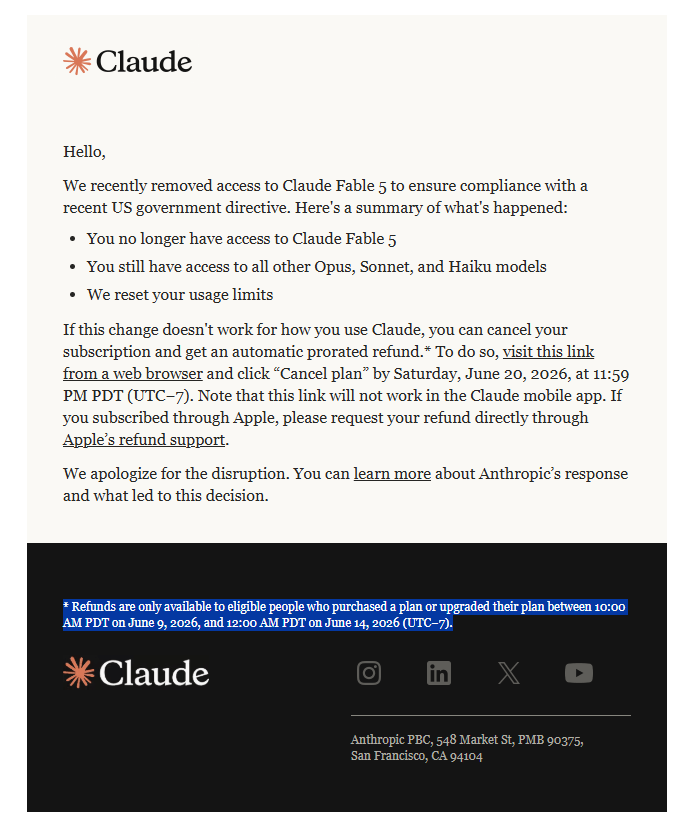
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
110
Espen JD retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

114
328
2,769
640,197
Espen JD retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


603
1,604
13,482
1,900,692
DiffusionGemma 26B A4B NVFP4 on RTX Pro 6000
Decode: 852 tok/s
Prefill peak: >50,000 tok/s
Diffusion models is the future, I want more

Downloading right now
- Q4 for single 3090
- Q8 for TP=2 on dual 3090
- BF16 for RTX Pro 6000
Lets see how fast they are⚡
13
11
155
16,699
Espen JD retweeted

Jun 11
Are we fucking serious…
Jun 11

They didn't walk it back, it will now refuse to do the task rather than sabotaging your work and lying to your face (aka, gaslighting you)
Don't fall for this crap, Anthropic are forever clowns

1
1
5
302
Downloading right now
- Q4 for single 3090
- Q8 for TP=2 on dual 3090
- BF16 for RTX Pro 6000
Lets see how fast they are⚡
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
3
1
17
18,334
The speed on diffusion models is insane
Jun 10

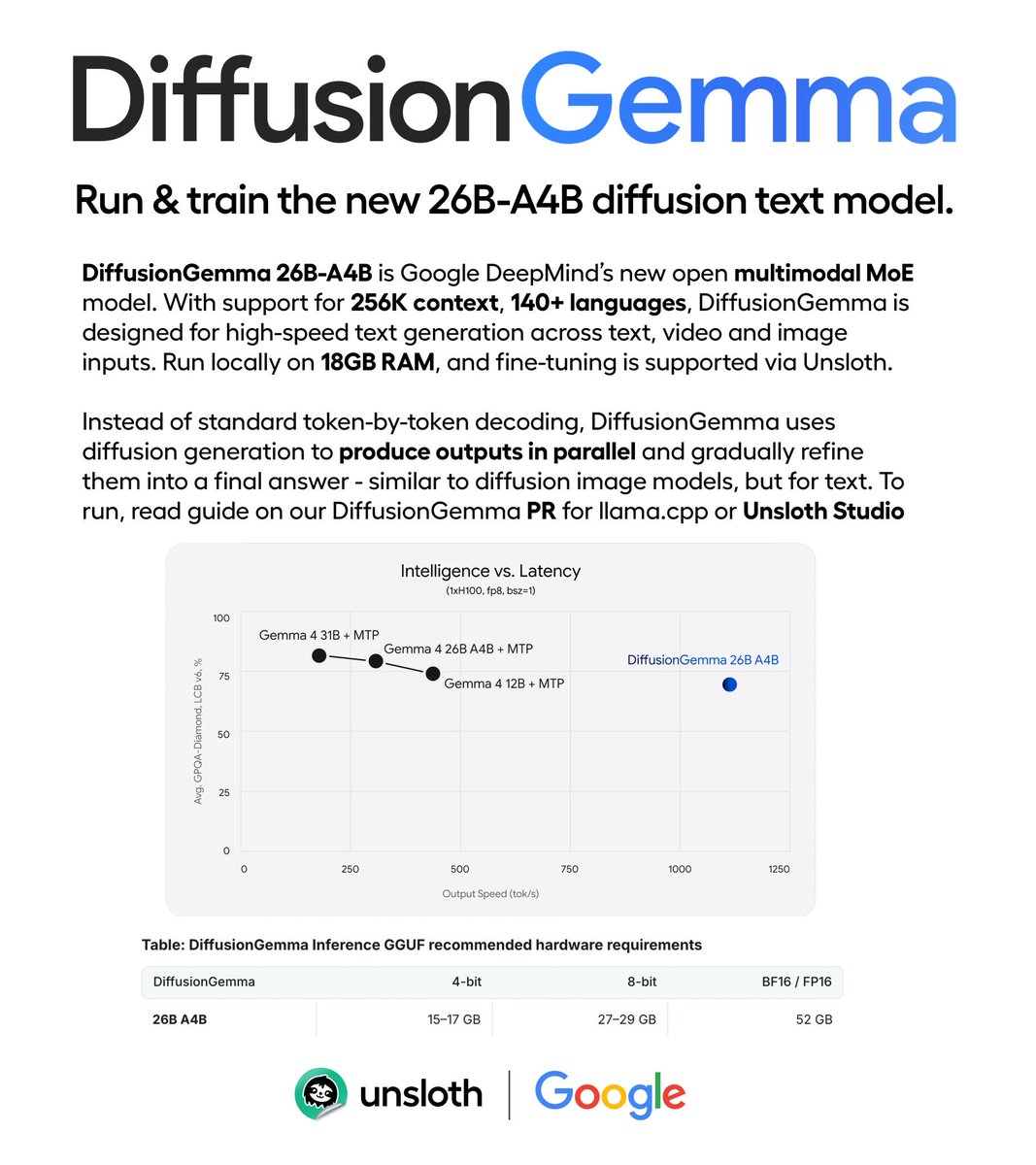
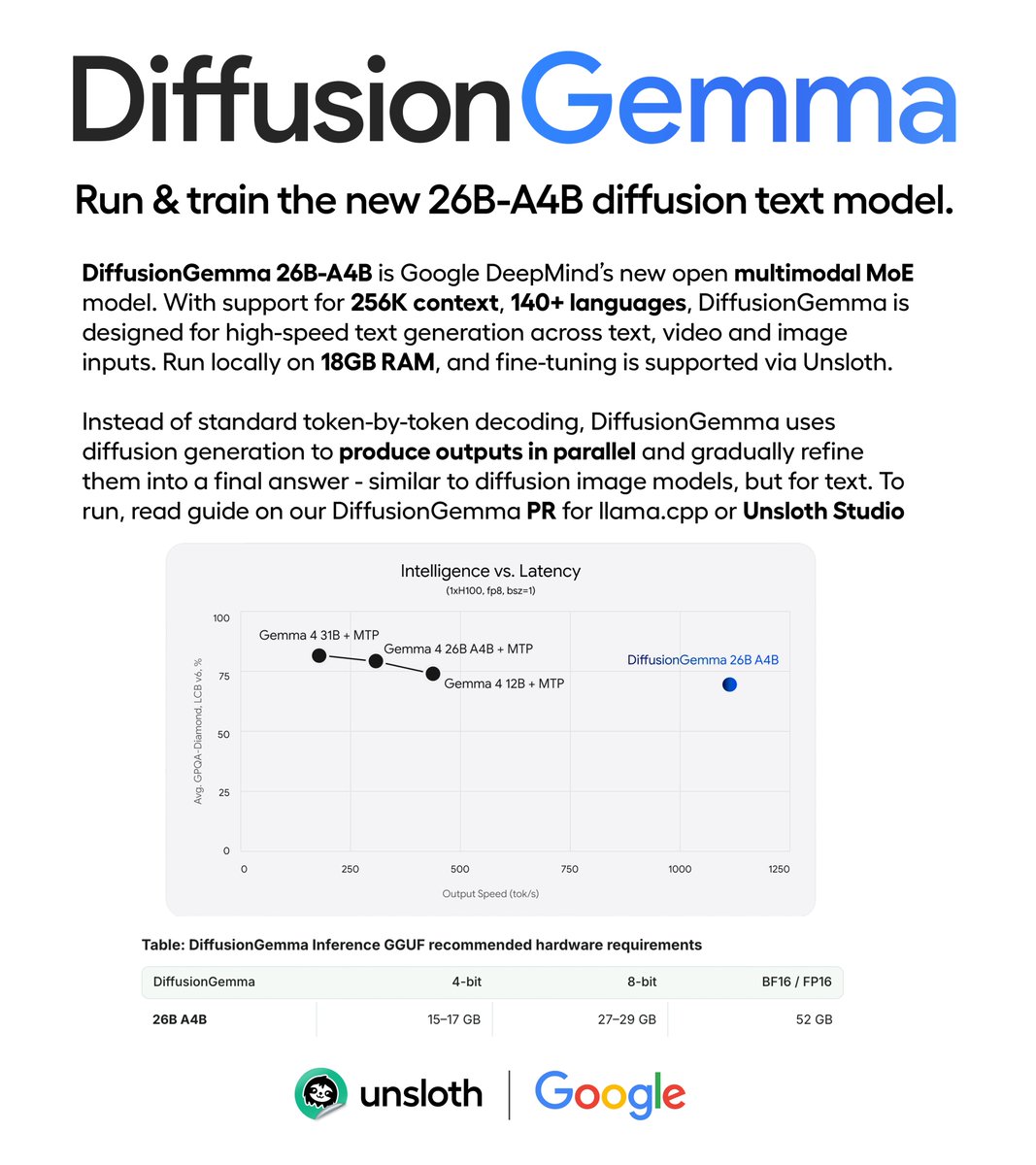
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
1
14
1,311
This is going to be fun to play with
Jun 10
Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
5
317