
Assistant Professor at UC Berkeley, Department of Statistics and EECS. Researcher at OpenAI working on LLM training.
Joined January 2015
- Tweets 91
- Following 691
- Followers 3,942
- Likes 303
4 Photos and videos



Pinned Tweet

11 Dec 2025
Excited to contribute to GPT-5.2! Thanks, and congrats to all teammates!

9
7
290
31,250
11 Dec 2025
🧄🧄🧄🚀🚀🚀

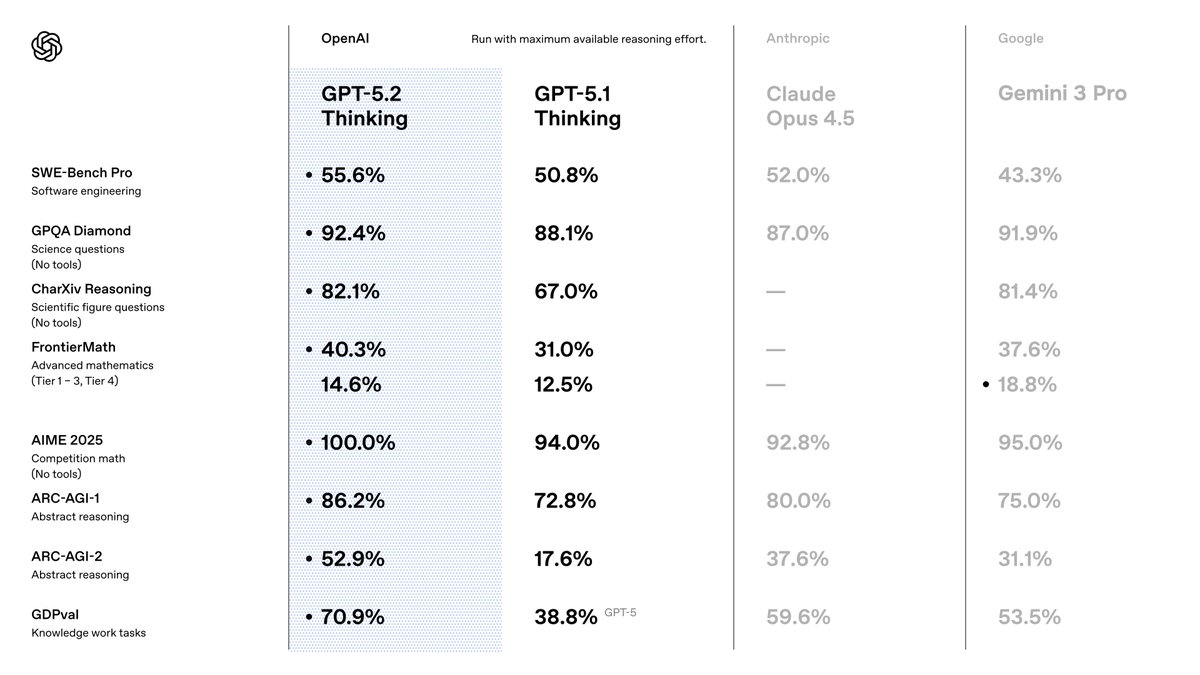
🧄GPT-5.2 is here – one small step on version number, one giant leap in capabilities. 🚀
With *incredible* @Song__Mei @yaodong_yu @Yuf_Zh @ofirnachum and rest of the @OpenAI team, we applied new techniques to bring our frontier reasoning model to the next level. GPT-5.2-Thinking is much stronger on intelligence, agentic coding, professional use, long-context understanding, and extended thinking.
It’s also better on science/theory research – try pairing with it!
Congrats also to @yanndubs @ericmitchellai @.ishaan @christinahkim, and heartfelt thanks to the leadership @_aidan_clark_ @max_a_schwarzer @markchen90 @merettm @sama for making this come together!
4
1
120
13,736
7 Aug 2025
Today’s the day — GPT-5 is here! One of the reasons I joined OpenAI was to train the next generation of GPT. It became my first big project, and to my surprise, I became one of the core contributors — together with @yubai01 and many amazing colleagues — developing unexpected but cool techniques that made it into the final training stack. Hard to believe that just two months here could lead to such a big impact.
10
6
104
18,630
7 Aug 2025
This cannot happen without amazing colleagues: @SebastienBubeck
@yanndubs
@ElaineYaLe6
@christinahkim
@ericmitchellai
@michpokrass
@max_a_schwarzer
@SebastienBubeck
@minyoung_huh
@_chris_lu_
@SuvanshSanjeev
@hadisalmanX
2
12
1,715

Today is the day -- we are excited to bring gpt5 to you.
Fortunate to have led several workstreams in GPT5 Thinking and Mini model training. Among many other improvements, with @Song__Mei @minyoung_huh @SebastienBubeck and co, we applied some unexpected but cool techniques to make the model smart, chatty, and a good model all-around.
Also honored to have worked together with the crew @yanndubs @ElaineYaLe6 @christinahkim @ericmitchellai @michpokrass @max_a_schwarzer and everyone else, it was fun coming together and doing things!
Let us know how you like or dislike it -- this will not be the last model we're gonna train.
19
7
82
16,481
6 Aug 2025
Yes, this is super exciting!
Surreal & beyond excited to have joined forces with @Song__Mei again -- more to come soon!
1
12
5,647
6 Aug 2025
I’m excited to start at OpenAI this May and help ship the oss model. More to come soon!
We released two open-weight reasoning models—gpt-oss-120b and gpt-oss-20b—under an Apache 2.0 license.
Developed with open-source community feedback, these models deliver meaningful advancements in both reasoning capabilities & safety.
openai.com/index/introducing…
16
7
252
57,104
6 Aug 2025
Thanks, everyone! Just a quick note—I only contributed a little bit on oss, but I’m glad I had the chance to be involved.
2
20
3,648
7 Mar 2025
Congrats @LesterMackey ! I learned my first PhD stats course from your Stats 300 and have enjoyed the beauty of stats theory ever since.
7 Mar 2025

🙌🎉Our 2025 recipient of the COPSS Presidents' Award, is Lester Mackey! This award is given annually to a young member of the statistical community in recognition of outstanding contributions to the profession of statistics.

1
2
41
6,789
2 Mar 2025
This is a reminder that the FSML workshop (fsmlims.wixsite.com/fsml25, co-located with JSM) paper submission deadline, Mar 3 AoE, is in less than 2 days. This is a non-archival workshop so feel free to submit any interesting statsML paper already submitted elsewhere. It is a great opportunity to get travel funding to JSM and communicate your recent research with the community. Submission portal here: openreview.net/group?id=imst…
1
1
10
2,775
Song Mei retweeted

26 Feb 2025
We show the implicit bias of GD for generic non-homogeneous deep nets (results of such were previously limited to homogenous ones). In particular, our results cover those with residual connections and non-homogeneous activation functions. It's a joint work with Kangjie Zhou, @uuujingfeng Jingfeng Wu, @Song__Mei Song Mei, Michael Lindsey, and Peter L. Bartlett!
Arxiv: arxiv.org/abs/2502.16075.

6
38
3,799
26 Feb 2025
Excited to share our review paper on LLM for statisticians!
26 Feb 2025

🚨 New Paper 🚨
An Overview of Large Language Models for Statisticians
📝: arxiv.org/abs/2502.17814
- Dual perspectives on Statistics ➕ LLMs: Stat for LLM & LLM for Stat
- Stat for LLM: How statistical methods can improve LLM uncertainty quantification, interpretability, trustworthiness & more.
- LLM for Stat: How LLMs can enhance statistical workflows: from data collection, synthesis, annotation to statistical modeling, with applications to medical research
Presents key LLM advances: Architecture, Training, Reasoning, and Self-Alignment:
(1) 🧠Evolution of LLM architectures with Transformers and Self-Attention
(2) LLM training pipeline from pre-training, SFT, to RLHF and Preference Optimization.
(3) 💭 System 2 Prompting and Chain-of-Thought for test-time scaling .
(4) 🚀 LLM Self-Alignment for achieving super-human intelligence
Statisticians play a key role in the development of large-scale AI models:
(1) 💡 Statistical insights improve LLM uncertainty quantification & interpretability
(2) 🤖 Watermarking for AI-generated content detection
(3) ⚖️ Privacy & algorithmic fairness to ensure responsible AI adoption
LLMs can also empower statistical science by:
(1) 📈 Scaling up data collection, synthesis, and annotation.
(2) 🖥️ Automating statistical coding & exploratory analysis
(3) 🔬 Facilitating medical research
By bridging statistics & AI, we can:
✅ Improve better LLMs with statistical methodologies.
✅ Leverage LLMs for statistical applications in high-stakes domains

2
44
4,369
20 Feb 2025
Honored to receive the Sloan Fellowship! Grateful for the support I’ve received along the way. With this opportunity, I look forward to advancing research in the intersection of math, statistics, and AI. #SloanFellow
18 Feb 2025

🎉Congrats to the 126 early-career scientists who have been awarded a Sloan Research Fellowship this year! These exceptional scholars are drawn from 51 institutions across the US and Canada, and represent the next generation of groundbreaking researchers. sloan.org/fellowships/2025-F…

19
4
142
8,909
Song Mei retweeted

3 Feb 2025
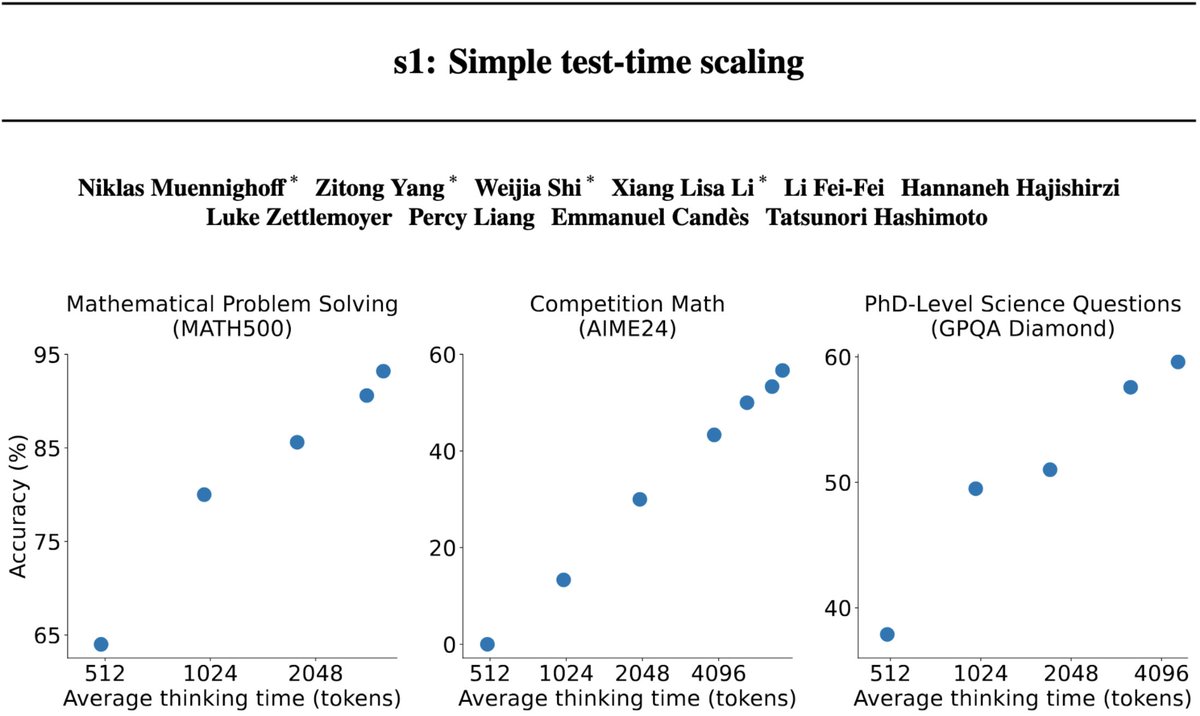
DeepSeek r1 is exciting but misses OpenAI’s test-time scaling plot and needs lots of data.
We introduce s1 reproducing o1-preview scaling & performance with just 1K samples & a simple test-time intervention.
📜arxiv.org/abs/2501.19393
40
185
982
408,229
Song Mei retweeted

24 Jan 2025
In 2021, our research group released the MATH dataset. In the paper, we attribute the data to math contests released by the Mathematical Association of America (MAA), which is in the public domain. I've recently become aware that this is mistaken--while MATH contains MAA data...
5
14
208
33,885
9 Jan 2025
We present a new theoretical analysis of the CLIP model, focusing on controlling the estimation error of its representations in multimodal downstream tasks. The key is the notion of approximate sufficient statistics. In generative hierarchical models, we derive an end-to-end sample complexity bound. With Kazu, Licong, and @faro36241257 Yuhang.
ArXiv link: arxiv.org/abs/2501.04641
2
26
155
17,036
Song Mei retweeted
24 Oct 2024
In July, I went on leave from UC Berkeley to found @TransluceAI, together with Sarah Schwettmann (@cogconfluence). Now, our work is finally public.
23 Oct 2024

Announcing Transluce, a nonprofit research lab building open source, scalable technology for understanding AI systems and steering them in the public interest.
Read a letter from the co-founders Jacob Steinhardt and Sarah Schwettmann:
transluce.org/introducing-tr…
8
19
361
54,249
18 Oct 2024
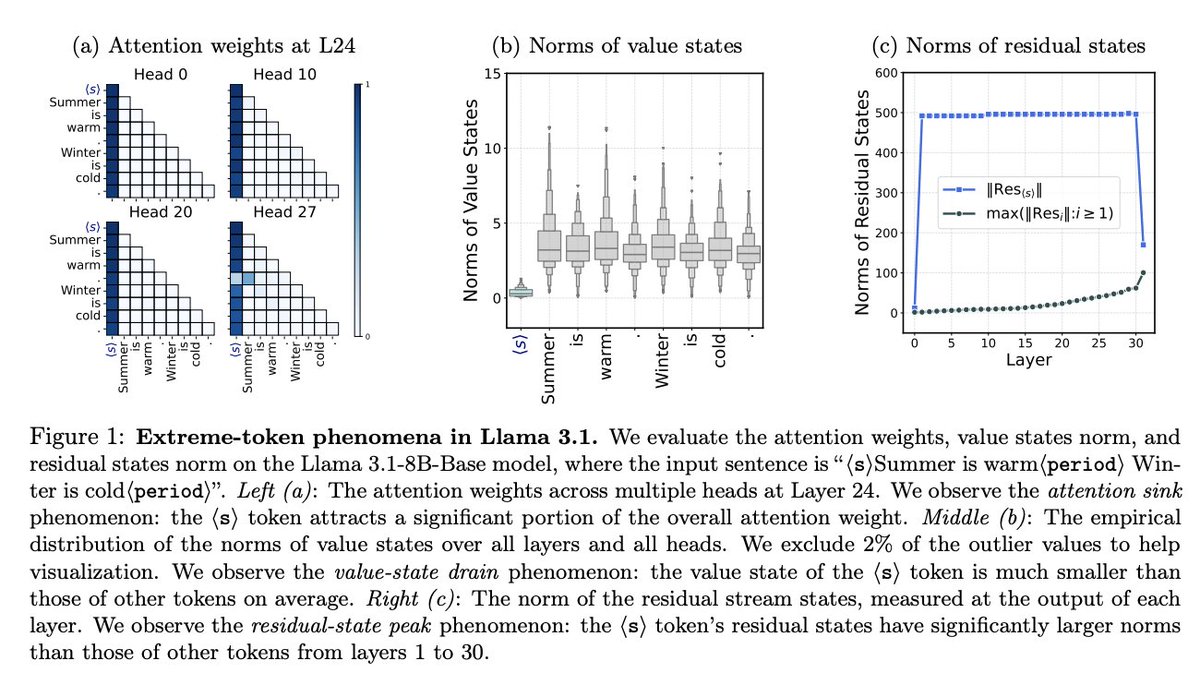
Many LLMs, e.g., GPT2 and Llama, exhibit a fascinating attention sink phenomenon: attention weights often concentrate on the first token. We studied the training dynamics of toy models to demystify the sink formation mechanisms in LLMs. With fantastic @TianyuGuo0505 , @druv_pai , @yubai01 , @JiantaoJ , and Mike Jordan!
ArXiv link: arxiv.org/abs/2410.13835
In detail:
Practitioners have consistently found three extreme-token phenomena in LLMs: attention sinks, value-state drains, and residual-state peaks. They often cause trouble in LLM inference and quantization.
To understand them, we developed the Bigram-Backcopy task and analyzed a single-layer transformer, revealing two key mechanisms:
• Active-dormant mechanism: The attention sink represents the dormant phase of an attention head.
• Mutual reinforcement mechanism: Attention sinks and value-state drains mutually reinforce during training.
All results can transfer to LLMs!
• Llama 2 has a “coding head” that is dormant given Wikipedia texts.
• OMLo’s training dynamics closely match the theory and the toy model.
We also found that replacing SoftMax attention with ReLU attention can mitigate the extreme-token phenomenon.
4
22
150
23,003
13 May 2024
Yu is a super-talented and reliable collaborator. Congrats to both Yu and OpenAI!
📢 Life update: In the vibes of the announcement today I am thrilled to share that I have joined @OpenAI as a researcher!
It's just my week 2 here but already amazed by so many things the team has achieved. Looking forward to learning more and contributing!
3
2
48
20,226